 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Intrinsic Limits of Transformer Image Embeddings in Non-Solvable Spatial Reasoning
Jan 06, 2026Vision Transformers (ViTs) excel in semantic recognition but exhibit systematic failures in spatial reasoning tasks such as mental rotation. While often attributed to data scale, we propose that this limitation arises from the intrinsic circuit complexity of the architecture. We formalize spatial understanding as learning a Group Homomorphism: mapping image sequences to a latent space that preserves the algebraic structure of the underlying transformation group. We demonstrate that for non-solvable groups (e.g., the 3D rotation group $\mathrm{SO}(3)$), maintaining such a structure-preserving embedding is computationally lower-bounded by the Word Problem, which is $\mathsf{NC^1}$-complete. In contrast, we prove that constant-depth ViTs with polynomial precision are strictly bounded by $\mathsf{TC^0}$. Under the conjecture $\mathsf{TC^0} \subsetneq \mathsf{NC^1}$, we establish a complexity boundary: constant-depth ViTs fundamentally lack the logical depth to efficiently capture non-solvable spatial structures. We validate this complexity gap via latent-space probing, demonstrating that ViT representations suffer a structural collapse on non-solvable tasks as compositional depth increases.
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
May 14, 2025Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning. Videos and code are available at https://github.com/Zechao-Guan/TopoDiT-3D.
DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data
Mar 25, 2025The growing adoption of Vision-Language-Action (VLA) models in embodied AI intensifies the demand for diverse manipulation demonstrations. However, high costs associated with data collection often result in insufficient data coverage across all scenarios, which limits the performance of the models. It is observed that the spatial reasoning phase (SRP) in large workspace dominates the failure cases. Fortunately, this data can be collected with low cost, underscoring the potential of leveraging inexpensive data to improve model performance. In this paper, we introduce the DataPlatter method, a framework that decouples training trajectories into distinct task stages and leverages abundant easily collectible SRP data to enhance VLA model's generalization. Through analysis we demonstrate that sub-task-specific training with additional SRP data with proper proportion can act as a performance catalyst for robot manipulation, maximizing the utilization of costly physical interaction phase (PIP) data. Experiments show that through introducing large proportion of cost-effective SRP trajectories into a limited set of PIP data, we can achieve a maximum improvement of 41\% on success rate in zero-shot scenes, while with the ability to transfer manipulation skill to novel targets.
A survey on FPGA-based accelerator for ML models
Dec 20, 2024This paper thoroughly surveys machine learning (ML) algorithms acceleration in hardware accelerators, focusing on Field-Programmable Gate Arrays (FPGAs). It reviews 287 out of 1138 papers from the past six years, sourced from four top FPGA conferences. Such selection underscores the increasing integration of ML and FPGA technologies and their mutual importance in technological advancement. Research clearly emphasises inference acceleration (81\%) compared to training acceleration (13\%). Additionally, the findings reveals that CNN dominates current FPGA acceleration research while emerging models like GNN show obvious growth trends. The categorization of the FPGA research papers reveals a wide range of topics, demonstrating the growing relevance of ML in FPGA research. This comprehensive analysis provides valuable insights into the current trends and future directions of FPGA research in the context of ML applications.
RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Dec 10, 2024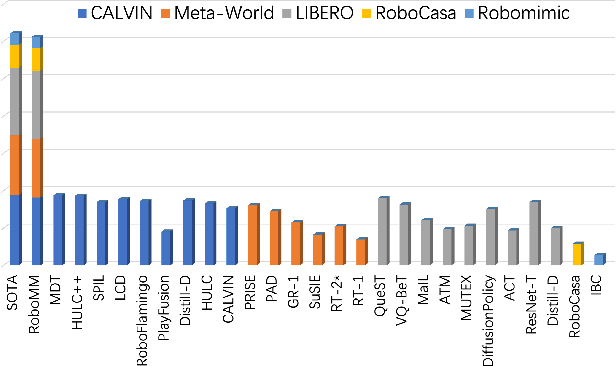
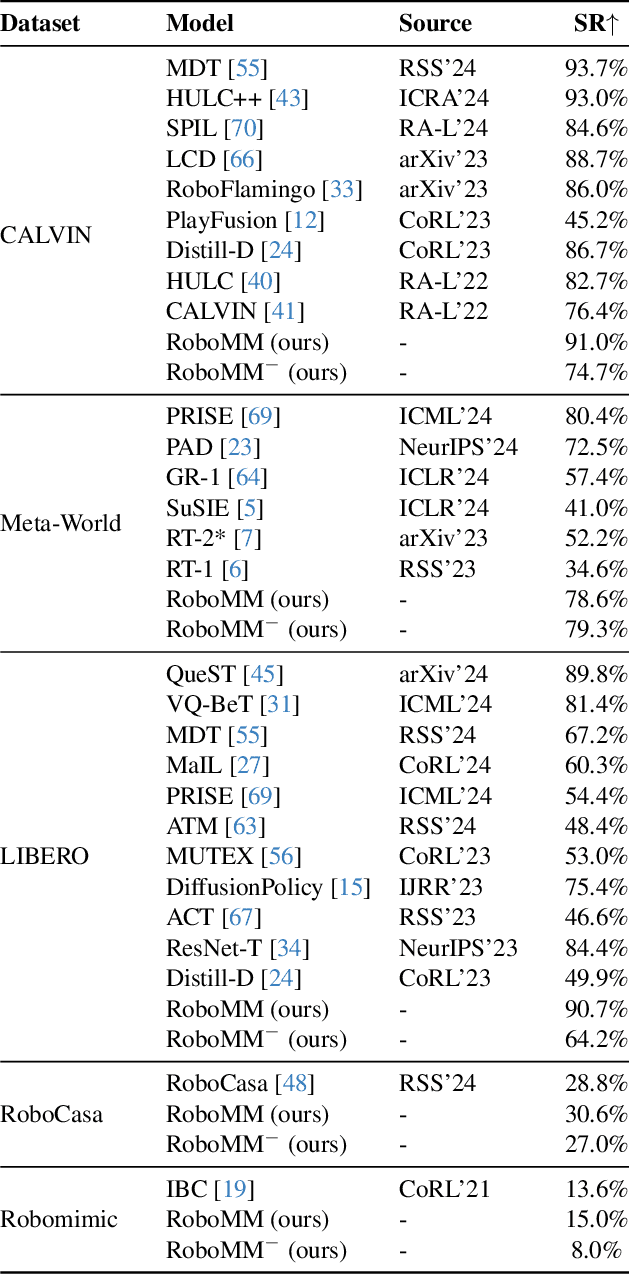

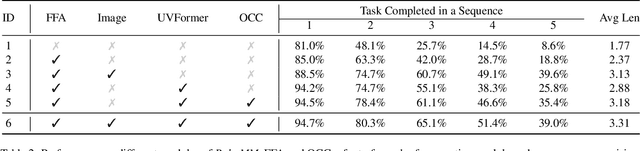
In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
DriveMM: All-in-One Large Multimodal Model for Autonomous Driving
Dec 10, 2024



Large Multimodal Models (LMMs) have demonstrated exceptional comprehension and interpretation capabilities in Autonomous Driving (AD) by incorporating large language models. Despite the advancements, current data-driven AD approaches tend to concentrate on a single dataset and specific tasks, neglecting their overall capabilities and ability to generalize. To bridge these gaps, we propose DriveMM, a general large multimodal model designed to process diverse data inputs, such as images and multi-view videos, while performing a broad spectrum of AD tasks, including perception, prediction, and planning. Initially, the model undergoes curriculum pre-training to process varied visual signals and perform basic visual comprehension and perception tasks. Subsequently, we augment and standardize various AD-related datasets to fine-tune the model, resulting in an all-in-one LMM for autonomous driving. To assess the general capabilities and generalization ability, we conduct evaluations on six public benchmarks and undertake zero-shot transfer on an unseen dataset, where DriveMM achieves state-of-the-art performance across all tasks. We hope DriveMM as a promising solution for future end-toend autonomous driving applications in the real world.
Towards Automated Model Design on Recommender Systems
Nov 12, 2024The increasing popularity of deep learning models has created new opportunities for developing AI-based recommender systems. Designing recommender systems using deep neural networks requires careful architecture design, and further optimization demands extensive co-design efforts on jointly optimizing model architecture and hardware. Design automation, such as Automated Machine Learning (AutoML), is necessary to fully exploit the potential of recommender model design, including model choices and model-hardware co-design strategies. We introduce a novel paradigm that utilizes weight sharing to explore abundant solution spaces. Our paradigm creates a large supernet to search for optimal architectures and co-design strategies to address the challenges of data multi-modality and heterogeneity in the recommendation domain. From a model perspective, the supernet includes a variety of operators, dense connectivity, and dimension search options. From a co-design perspective, it encompasses versatile Processing-In-Memory (PIM) configurations to produce hardware-efficient models. Our solution space's scale, heterogeneity, and complexity pose several challenges, which we address by proposing various techniques for training and evaluating the supernet. Our crafted models show promising results on three Click-Through Rates (CTR) prediction benchmarks, outperforming both manually designed and AutoML-crafted models with state-of-the-art performance when focusing solely on architecture search. From a co-design perspective, we achieve 2x FLOPs efficiency, 1.8x energy efficiency, and 1.5x performance improvements in recommender models.
* Accepted in ACM Transactions on Recommender Systems. arXiv admin note: substantial text overlap with arXiv:2207.07187
RoboCAS: A Benchmark for Robotic Manipulation in Complex Object Arrangement Scenarios
Jul 09, 2024



Foundation models hold significant potential for enabling robots to perform long-horizon general manipulation tasks. However, the simplicity of tasks and the uniformity of environments in existing benchmarks restrict their effective deployment in complex scenarios. To address this limitation, this paper introduces the \textit{RoboCAS} benchmark, the first benchmark specifically designed for complex object arrangement scenarios in robotic manipulation. This benchmark employs flexible and concise scripted policies to efficiently collect a diverse array of demonstrations, showcasing scattered, orderly, and stacked object arrangements within a highly realistic physical simulation environment. It includes complex processes such as target retrieval, obstacle clearance, and robot manipulation, testing agents' abilities to perform long-horizon planning for spatial reasoning and predicting chain reactions under ambiguous instructions. Extensive experiments on multiple baseline models reveal their limitations in managing complex object arrangement scenarios, underscoring the urgent need for intelligent agents capable of performing long-horizon operations in practical deployments and providing valuable insights for future research directions. Project website: \url{https://github.com/notFoundThisPerson/RoboCAS-v0}.
Corki: Enabling Real-time Embodied AI Robots via Algorithm-Architecture Co-Design
Jul 05, 2024



Embodied AI robots have the potential to fundamentally improve the way human beings live and manufacture. Continued progress in the burgeoning field of using large language models to control robots depends critically on an efficient computing substrate. In particular, today's computing systems for embodied AI robots are designed purely based on the interest of algorithm developers, where robot actions are divided into a discrete frame-basis. Such an execution pipeline creates high latency and energy consumption. This paper proposes Corki, an algorithm-architecture co-design framework for real-time embodied AI robot control. Our idea is to decouple LLM inference, robotic control and data communication in the embodied AI robots compute pipeline. Instead of predicting action for one single frame, Corki predicts the trajectory for the near future to reduce the frequency of LLM inference. The algorithm is coupled with a hardware that accelerates transforming trajectory into actual torque signals used to control robots and an execution pipeline that parallels data communication with computation. Corki largely reduces LLM inference frequency by up to 8.0x, resulting in up to 3.6x speed up. The success rate improvement can be up to 17.3%. Code is provided for re-implementation. https://github.com/hyy0613/Corki
MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis
Jul 03, 2024Multimodal Large Language Models (MLLM) have made significant progress in the field of document analysis. Despite this, existing benchmarks typically focus only on extracting text and simple layout information, neglecting the complex interactions between elements in structured documents such as mind maps and flowcharts. To address this issue, we introduce the new benchmark named MindBench, which not only includes meticulously constructed bilingual authentic or synthetic images, detailed annotations, evaluation metrics and baseline models, but also specifically designs five types of structured understanding and parsing tasks. These tasks include full parsing, partial parsing, position-related parsing, structured Visual Question Answering (VQA), and position-related VQA, covering key areas such as text recognition, spatial awareness, relationship discernment, and structured parsing. Extensive experimental results demonstrate the substantial potential and significant room for improvement in current models' ability to handle structured document information. We anticipate that the launch of MindBench will significantly advance research and application development in structured document analysis technology. MindBench is available at: https://miasanlei.github.io/MindBench.github.io/.