 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Corpus Construction and User-Perception-Aligned Metrics for Large-Language-Model Code Completion
May 19, 2025Code completion technology based on large language model has significantly improved the development efficiency of programmers. However, in practical applications, there remains a gap between current commonly used code completion evaluation metrics and users' actual perception. To address this issue, we propose two evaluation metrics for code completion tasks--LCP and ROUGE-LCP, from the perspective of probabilistic modeling. Furthermore, to tackle the lack of effective structural semantic modeling and cross-module dependency information in LLMs for repository-level code completion scenarios, we propose a data processing method based on a Structure-Preserving and Semantically-Reordered Code Graph (SPSR-Graph). Through theoretical analysis and experimental validation, we demonstrate the superiority of the proposed evaluation metrics in terms of user perception consistency, as well as the effectiveness of the data processing method in enhancing model performance.
Temporal-Spectral-Spatial Unified Remote Sensing Dense Prediction
May 18, 2025The proliferation of diverse remote sensing data has spurred advancements in dense prediction tasks, yet significant challenges remain in handling data heterogeneity. Remote sensing imagery exhibits substantial variability across temporal, spectral, and spatial (TSS) dimensions, complicating unified data processing. Current deep learning models for dense prediction tasks, such as semantic segmentation and change detection, are typically tailored to specific input-output configurations. Consequently, variations in data dimensionality or task requirements often lead to significant performance degradation or model incompatibility, necessitating costly retraining or fine-tuning efforts for different application scenarios. This paper introduces the Temporal-Spectral-Spatial Unified Network (TSSUN), a novel architecture designed for unified representation and modeling of remote sensing data across diverse TSS characteristics and task types. TSSUN employs a Temporal-Spectral-Spatial Unified Strategy that leverages meta-information to decouple and standardize input representations from varied temporal, spectral, and spatial configurations, and similarly unifies output structures for different dense prediction tasks and class numbers. Furthermore, a Local-Global Window Attention mechanism is proposed to efficiently capture both local contextual details and global dependencies, enhancing the model's adaptability and feature extraction capabilities. Extensive experiments on multiple datasets demonstrate that a single TSSUN model effectively adapts to heterogeneous inputs and unifies various dense prediction tasks. The proposed approach consistently achieves or surpasses state-of-the-art performance, highlighting its robustness and generalizability for complex remote sensing applications without requiring task-specific modifications.
Highly Undersampled MRI Reconstruction via a Single Posterior Sampling of Diffusion Models
May 13, 2025Incoherent k-space under-sampling and deep learning-based reconstruction methods have shown great success in accelerating MRI. However, the performance of most previous methods will degrade dramatically under high acceleration factors, e.g., 8$\times$ or higher. Recently, denoising diffusion models (DM) have demonstrated promising results in solving this issue; however, one major drawback of the DM methods is the long inference time due to a dramatic number of iterative reverse posterior sampling steps. In this work, a Single Step Diffusion Model-based reconstruction framework, namely SSDM-MRI, is proposed for restoring MRI images from highly undersampled k-space. The proposed method achieves one-step reconstruction by first training a conditional DM and then iteratively distilling this model. Comprehensive experiments were conducted on both publicly available fastMRI images and an in-house multi-echo GRE (QSM) subject. Overall, the results showed that SSDM-MRI outperformed other methods in terms of numerical metrics (PSNR and SSIM), qualitative error maps, image fine details, and latent susceptibility information hidden in MRI phase images. In addition, the reconstruction time for a 320*320 brain slice of SSDM-MRI is only 0.45 second, which is only comparable to that of a simple U-net, making it a highly effective solution for MRI reconstruction tasks.
ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models
May 12, 2025Current diffusion-based text-to-video methods are limited to producing short video clips of a single shot and lack the capability to generate multi-shot videos with discrete transitions where the same character performs distinct activities across the same or different backgrounds. To address this limitation we propose a framework that includes a dataset collection pipeline and architectural extensions to video diffusion models to enable text-to-multi-shot video generation. Our approach enables generation of multi-shot videos as a single video with full attention across all frames of all shots, ensuring character and background consistency, and allows users to control the number, duration, and content of shots through shot-specific conditioning. This is achieved by incorporating a transition token into the text-to-video model to control at which frames a new shot begins and a local attention masking strategy which controls the transition token's effect and allows shot-specific prompting. To obtain training data we propose a novel data collection pipeline to construct a multi-shot video dataset from existing single-shot video datasets. Extensive experiments demonstrate that fine-tuning a pre-trained text-to-video model for a few thousand iterations is enough for the model to subsequently be able to generate multi-shot videos with shot-specific control, outperforming the baselines. You can find more details in https://shotadapter.github.io/
TACFN: Transformer-based Adaptive Cross-modal Fusion Network for Multimodal Emotion Recognition
May 10, 2025The fusion technique is the key to the multimodal emotion recognition task. Recently, cross-modal attention-based fusion methods have demonstrated high performance and strong robustness. However, cross-modal attention suffers from redundant features and does not capture complementary features well. We find that it is not necessary to use the entire information of one modality to reinforce the other during cross-modal interaction, and the features that can reinforce a modality may contain only a part of it. To this end, we design an innovative Transformer-based Adaptive Cross-modal Fusion Network (TACFN). Specifically, for the redundant features, we make one modality perform intra-modal feature selection through a self-attention mechanism, so that the selected features can adaptively and efficiently interact with another modality. To better capture the complementary information between the modalities, we obtain the fused weight vector by splicing and use the weight vector to achieve feature reinforcement of the modalities. We apply TCAFN to the RAVDESS and IEMOCAP datasets. For fair comparison, we use the same unimodal representations to validate the effectiveness of the proposed fusion method. The experimental results show that TACFN brings a significant performance improvement compared to other methods and reaches the state-of-the-art. All code and models could be accessed from https://github.com/shuzihuaiyu/TACFN.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
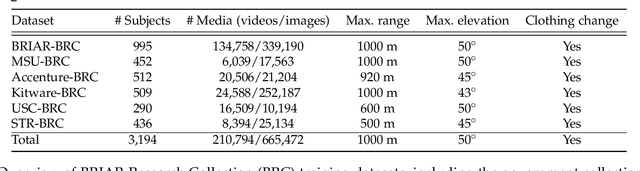

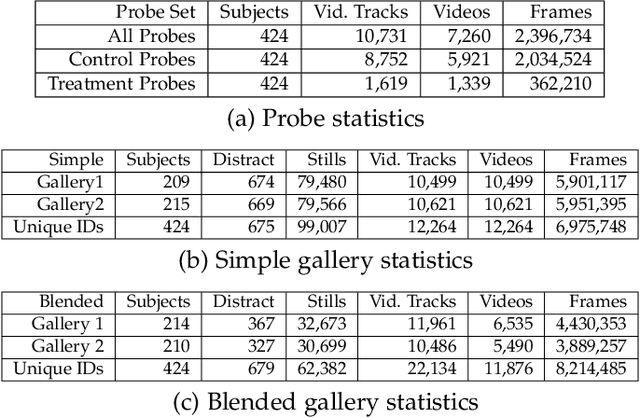
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
CineVerse: Consistent Keyframe Synthesis for Cinematic Scene Composition
Apr 28, 2025We present CineVerse, a novel framework for the task of cinematic scene composition. Similar to traditional multi-shot generation, our task emphasizes the need for consistency and continuity across frames. However, our task also focuses on addressing challenges inherent to filmmaking, such as multiple characters, complex interactions, and visual cinematic effects. In order to learn to generate such content, we first create the CineVerse dataset. We use this dataset to train our proposed two-stage approach. First, we prompt a large language model (LLM) with task-specific instructions to take in a high-level scene description and generate a detailed plan for the overall setting and characters, as well as the individual shots. Then, we fine-tune a text-to-image generation model to synthesize high-quality visual keyframes. Experimental results demonstrate that CineVerse yields promising improvements in generating visually coherent and contextually rich movie scenes, paving the way for further exploration in cinematic video synthesis.
Securing the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
Apr 16, 2025Unmanned Aerial Vehicles (UAVs) are indispensable for infrastructure inspection, surveillance, and related tasks, yet they also introduce critical security challenges. This survey provides a wide-ranging examination of the anti-UAV domain, centering on three core objectives-classification, detection, and tracking-while detailing emerging methodologies such as diffusion-based data synthesis, multi-modal fusion, vision-language modeling, self-supervised learning, and reinforcement learning. We systematically evaluate state-of-the-art solutions across both single-modality and multi-sensor pipelines (spanning RGB, infrared, audio, radar, and RF) and discuss large-scale as well as adversarially oriented benchmarks. Our analysis reveals persistent gaps in real-time performance, stealth detection, and swarm-based scenarios, underscoring pressing needs for robust, adaptive anti-UAV systems. By highlighting open research directions, we aim to foster innovation and guide the development of next-generation defense strategies in an era marked by the extensive use of UAVs.
A Visual Self-attention Mechanism Facial Expression Recognition Network beyond Convnext
Apr 12, 2025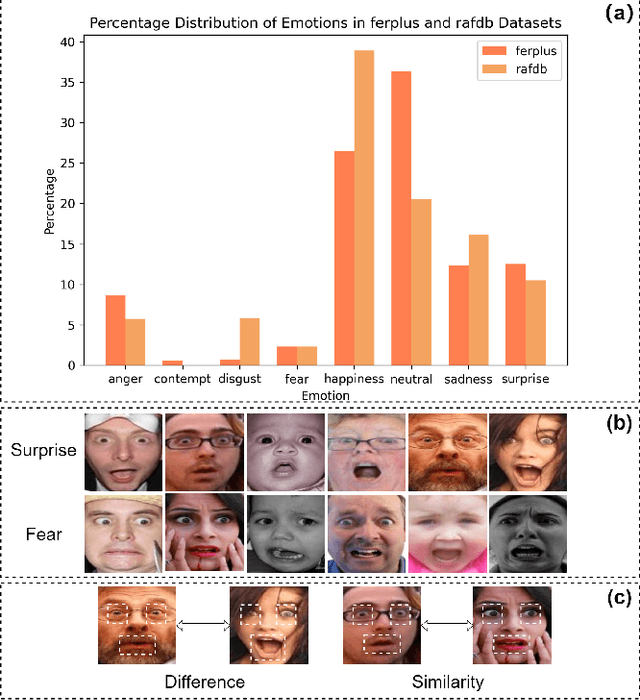
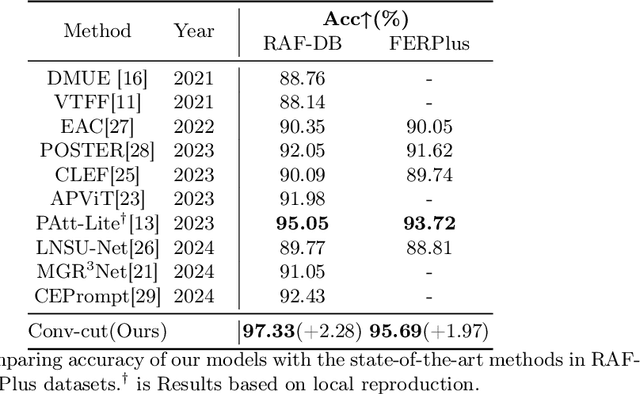
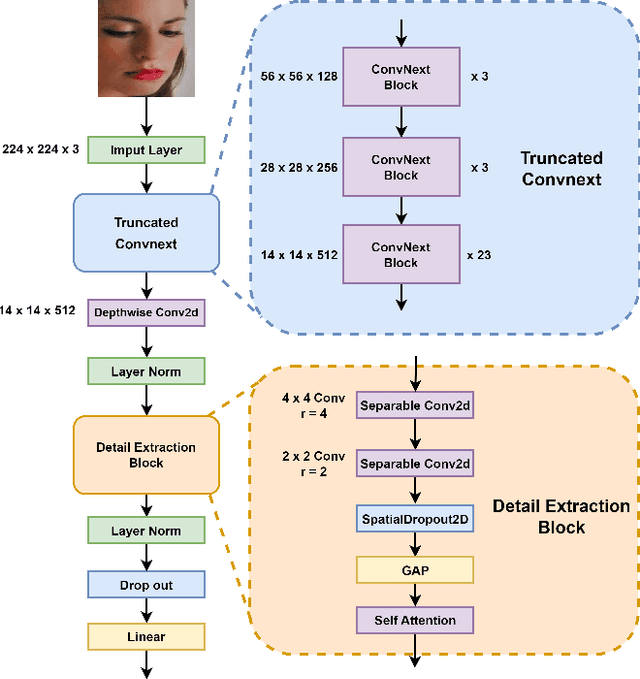

Facial expression recognition is an important research direction in the field of artificial intelligence. Although new breakthroughs have been made in recent years, the uneven distribution of datasets and the similarity between different categories of facial expressions, as well as the differences within the same category among different subjects, remain challenges. This paper proposes a visual facial expression signal feature processing network based on truncated ConvNeXt approach(Conv-cut), to improve the accuracy of FER under challenging conditions. The network uses a truncated ConvNeXt-Base as the feature extractor, and then we designed a Detail Extraction Block to extract detailed features, and introduced a Self-Attention mechanism to enable the network to learn the extracted features more effectively. To evaluate the proposed Conv-cut approach, we conducted experiments on the RAF-DB and FERPlus datasets, and the results show that our model has achieved state-of-the-art performance. Our code could be accessed at Github.
SapiensID: Foundation for Human Recognition
Apr 07, 2025Existing human recognition systems often rely on separate, specialized models for face and body analysis, limiting their effectiveness in real-world scenarios where pose, visibility, and context vary widely. This paper introduces SapiensID, a unified model that bridges this gap, achieving robust performance across diverse settings. SapiensID introduces (i) Retina Patch (RP), a dynamic patch generation scheme that adapts to subject scale and ensures consistent tokenization of regions of interest, (ii) a masked recognition model (MRM) that learns from variable token length, and (iii) Semantic Attention Head (SAH), an module that learns pose-invariant representations by pooling features around key body parts. To facilitate training, we introduce WebBody4M, a large-scale dataset capturing diverse poses and scale variations. Extensive experiments demonstrate that SapiensID achieves state-of-the-art results on various body ReID benchmarks, outperforming specialized models in both short-term and long-term scenarios while remaining competitive with dedicated face recognition systems. Furthermore, SapiensID establishes a strong baseline for the newly introduced challenge of Cross Pose-Scale ReID, demonstrating its ability to generalize to complex, real-world conditions.