 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCal-DETR: Calibrated Detection Transformer
Nov 06, 2023Albeit revealing impressive predictive performance for several computer vision tasks, deep neural networks (DNNs) are prone to making overconfident predictions. This limits the adoption and wider utilization of DNNs in many safety-critical applications. There have been recent efforts toward calibrating DNNs, however, almost all of them focus on the classification task. Surprisingly, very little attention has been devoted to calibrating modern DNN-based object detectors, especially detection transformers, which have recently demonstrated promising detection performance and are influential in many decision-making systems. In this work, we address the problem by proposing a mechanism for calibrated detection transformers (Cal-DETR), particularly for Deformable-DETR, UP-DETR and DINO. We pursue the train-time calibration route and make the following contributions. First, we propose a simple yet effective approach for quantifying uncertainty in transformer-based object detectors. Second, we develop an uncertainty-guided logit modulation mechanism that leverages the uncertainty to modulate the class logits. Third, we develop a logit mixing approach that acts as a regularizer with detection-specific losses and is also complementary to the uncertainty-guided logit modulation technique to further improve the calibration performance. Lastly, we conduct extensive experiments across three in-domain and four out-domain scenarios. Results corroborate the effectiveness of Cal-DETR against the competing train-time methods in calibrating both in-domain and out-domain detections while maintaining or even improving the detection performance. Our codebase and pre-trained models can be accessed at \url{https://github.com/akhtarvision/cal-detr}.
Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization
Nov 02, 2023



The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains -- distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top- 1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves consistently across all datasets compared to the existing state-of-the-art. Our source code and models are available at https://jameelhassan.github.io/promptalign.
Videoprompter: an ensemble of foundational models for zero-shot video understanding
Oct 23, 2023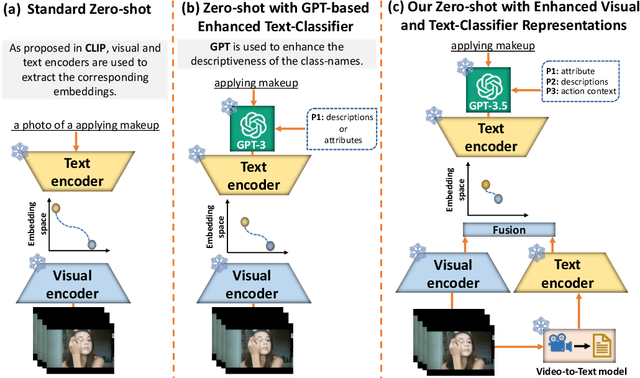


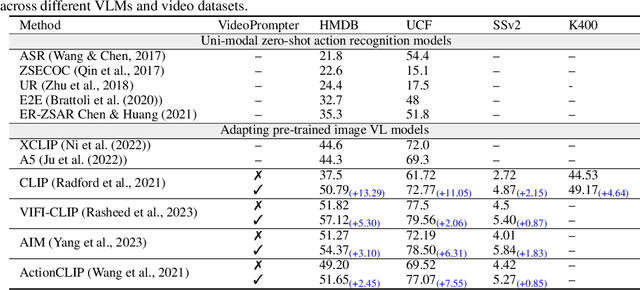
Vision-language models (VLMs) classify the query video by calculating a similarity score between the visual features and text-based class label representations. Recently, large language models (LLMs) have been used to enrich the text-based class labels by enhancing the descriptiveness of the class names. However, these improvements are restricted to the text-based classifier only, and the query visual features are not considered. In this paper, we propose a framework which combines pre-trained discriminative VLMs with pre-trained generative video-to-text and text-to-text models. We introduce two key modifications to the standard zero-shot setting. First, we propose language-guided visual feature enhancement and employ a video-to-text model to convert the query video to its descriptive form. The resulting descriptions contain vital visual cues of the query video, such as what objects are present and their spatio-temporal interactions. These descriptive cues provide additional semantic knowledge to VLMs to enhance their zeroshot performance. Second, we propose video-specific prompts to LLMs to generate more meaningful descriptions to enrich class label representations. Specifically, we introduce prompt techniques to create a Tree Hierarchy of Categories for class names, offering a higher-level action context for additional visual cues, We demonstrate the effectiveness of our approach in video understanding across three different zero-shot settings: 1) video action recognition, 2) video-to-text and textto-video retrieval, and 3) time-sensitive video tasks. Consistent improvements across multiple benchmarks and with various VLMs demonstrate the effectiveness of our proposed framework. Our code will be made publicly available.
Multi-grained Temporal Prototype Learning for Few-shot Video Object Segmentation
Sep 20, 2023Few-Shot Video Object Segmentation (FSVOS) aims to segment objects in a query video with the same category defined by a few annotated support images. However, this task was seldom explored. In this work, based on IPMT, a state-of-the-art few-shot image segmentation method that combines external support guidance information with adaptive query guidance cues, we propose to leverage multi-grained temporal guidance information for handling the temporal correlation nature of video data. We decompose the query video information into a clip prototype and a memory prototype for capturing local and long-term internal temporal guidance, respectively. Frame prototypes are further used for each frame independently to handle fine-grained adaptive guidance and enable bidirectional clip-frame prototype communication. To reduce the influence of noisy memory, we propose to leverage the structural similarity relation among different predicted regions and the support for selecting reliable memory frames. Furthermore, a new segmentation loss is also proposed to enhance the category discriminability of the learned prototypes. Experimental results demonstrate that our proposed video IPMT model significantly outperforms previous models on two benchmark datasets. Code is available at https://github.com/nankepan/VIPMT.
Unsupervised Landmark Discovery Using Consistency Guided Bottleneck
Sep 19, 2023



We study a challenging problem of unsupervised discovery of object landmarks. Many recent methods rely on bottlenecks to generate 2D Gaussian heatmaps however, these are limited in generating informed heatmaps while training, presumably due to the lack of effective structural cues. Also, it is assumed that all predicted landmarks are semantically relevant despite having no ground truth supervision. In the current work, we introduce a consistency-guided bottleneck in an image reconstruction-based pipeline that leverages landmark consistency, a measure of compatibility score with the pseudo-ground truth to generate adaptive heatmaps. We propose obtaining pseudo-supervision via forming landmark correspondence across images. The consistency then modulates the uncertainty of the discovered landmarks in the generation of adaptive heatmaps which rank consistent landmarks above their noisy counterparts, providing effective structural information for improved robustness. Evaluations on five diverse datasets including MAFL, AFLW, LS3D, Cats, and Shoes demonstrate excellent performance of the proposed approach compared to the existing state-of-the-art methods. Our code is publicly available at https://github.com/MamonaAwan/CGB_ULD.
A Spatial-Temporal Deformable Attention based Framework for Breast Lesion Detection in Videos
Sep 09, 2023



Detecting breast lesion in videos is crucial for computer-aided diagnosis. Existing video-based breast lesion detection approaches typically perform temporal feature aggregation of deep backbone features based on the self-attention operation. We argue that such a strategy struggles to effectively perform deep feature aggregation and ignores the useful local information. To tackle these issues, we propose a spatial-temporal deformable attention based framework, named STNet. Our STNet introduces a spatial-temporal deformable attention module to perform local spatial-temporal feature fusion. The spatial-temporal deformable attention module enables deep feature aggregation in each stage of both encoder and decoder. To further accelerate the detection speed, we introduce an encoder feature shuffle strategy for multi-frame prediction during inference. In our encoder feature shuffle strategy, we share the backbone and encoder features, and shuffle encoder features for decoder to generate the predictions of multiple frames. The experiments on the public breast lesion ultrasound video dataset show that our STNet obtains a state-of-the-art detection performance, while operating twice as fast inference speed. The code and model are available at https://github.com/AlfredQin/STNet.
Improving Underwater Visual Tracking With a Large Scale Dataset and Image Enhancement
Aug 31, 2023This paper presents a new dataset and general tracker enhancement method for Underwater Visual Object Tracking (UVOT). Despite its significance, underwater tracking has remained unexplored due to data inaccessibility. It poses distinct challenges; the underwater environment exhibits non-uniform lighting conditions, low visibility, lack of sharpness, low contrast, camouflage, and reflections from suspended particles. Performance of traditional tracking methods designed primarily for terrestrial or open-air scenarios drops in such conditions. We address the problem by proposing a novel underwater image enhancement algorithm designed specifically to boost tracking quality. The method has resulted in a significant performance improvement, of up to 5.0% AUC, of state-of-the-art (SOTA) visual trackers. To develop robust and accurate UVOT methods, large-scale datasets are required. To this end, we introduce a large-scale UVOT benchmark dataset consisting of 400 video segments and 275,000 manually annotated frames enabling underwater training and evaluation of deep trackers. The videos are labelled with several underwater-specific tracking attributes including watercolor variation, target distractors, camouflage, target relative size, and low visibility conditions. The UVOT400 dataset, tracking results, and the code are publicly available on: https://github.com/BasitAlawode/UWVOT400.
How Good is Google Bard's Visual Understanding? An Empirical Study on Open Challenges
Jul 27, 2023Google's Bard has emerged as a formidable competitor to OpenAI's ChatGPT in the field of conversational AI. Notably, Bard has recently been updated to handle visual inputs alongside text prompts during conversations. Given Bard's impressive track record in handling textual inputs, we explore its capabilities in understanding and interpreting visual data (images) conditioned by text questions. This exploration holds the potential to unveil new insights and challenges for Bard and other forthcoming multi-modal Generative models, especially in addressing complex computer vision problems that demand accurate visual and language understanding. Specifically, in this study, we focus on 15 diverse task scenarios encompassing regular, camouflaged, medical, under-water and remote sensing data to comprehensively evaluate Bard's performance. Our primary finding indicates that Bard still struggles in these vision scenarios, highlighting the significant gap in vision-based understanding that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, leading to enhanced capabilities in comprehending and interpreting fine-grained visual data. Our project is released on https://github.com/htqin/GoogleBard-VisUnderstand
Foundational Models Defining a New Era in Vision: A Survey and Outlook
Jul 25, 2023



Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.
Frequency Domain Adversarial Training for Robust Volumetric Medical Segmentation
Jul 20, 2023



It is imperative to ensure the robustness of deep learning models in critical applications such as, healthcare. While recent advances in deep learning have improved the performance of volumetric medical image segmentation models, these models cannot be deployed for real-world applications immediately due to their vulnerability to adversarial attacks. We present a 3D frequency domain adversarial attack for volumetric medical image segmentation models and demonstrate its advantages over conventional input or voxel domain attacks. Using our proposed attack, we introduce a novel frequency domain adversarial training approach for optimizing a robust model against voxel and frequency domain attacks. Moreover, we propose frequency consistency loss to regulate our frequency domain adversarial training that achieves a better tradeoff between model's performance on clean and adversarial samples. Code is publicly available at https://github.com/asif-hanif/vafa.