 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise is an Efficient Learner for Zero-Shot Vision-Language Models
Feb 09, 2025



Recently, test-time adaptation has garnered attention as a method for tuning models without labeled data. The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time primarily focuses on tuning learnable prompts; however, this approach overlooks potential distribution shifts in the visual representations themselves. In this work, we address this limitation by introducing Test-Time Noise Tuning (TNT), a novel method for handling unpredictable shifts in the visual space. TNT leverages, for the first time, a noise adaptation strategy that optimizes learnable noise directly in the visual input space, enabling adaptive feature learning from a single test sample. We further introduce a novel approach for inter-view representation alignment by explicitly enforcing coherence in embedding distances, ensuring consistent feature representations across views. Combined with scaled logits and confident view selection at inference, TNT substantially enhances VLM generalization and calibration, achieving average gains of +7.38% on natural distributions benchmark and +0.80% on cross-dataset evaluations over zero-shot CLIP. These improvements lay a strong foundation for adaptive out-of-distribution handling.
TransResNet: Integrating the Strengths of ViTs and CNNs for High Resolution Medical Image Segmentation via Feature Grafting
Oct 01, 2024



High-resolution images are preferable in medical imaging domain as they significantly improve the diagnostic capability of the underlying method. In particular, high resolution helps substantially in improving automatic image segmentation. However, most of the existing deep learning-based techniques for medical image segmentation are optimized for input images having small spatial dimensions and perform poorly on high-resolution images. To address this shortcoming, we propose a parallel-in-branch architecture called TransResNet, which incorporates Transformer and CNN in a parallel manner to extract features from multi-resolution images independently. In TransResNet, we introduce Cross Grafting Module (CGM), which generates the grafted features, enriched in both global semantic and low-level spatial details, by combining the feature maps from Transformer and CNN branches through fusion and self-attention mechanism. Moreover, we use these grafted features in the decoding process, increasing the information flow for better prediction of the segmentation mask. Extensive experiments on ten datasets demonstrate that TransResNet achieves either state-of-the-art or competitive results on several segmentation tasks, including skin lesion, retinal vessel, and polyp segmentation. The source code and pre-trained models are available at https://github.com/Sharifmhamza/TransResNet.
PALM: Few-Shot Prompt Learning for Audio Language Models
Sep 29, 2024



Audio-Language Models (ALMs) have recently achieved remarkable success in zero-shot audio recognition tasks, which match features of audio waveforms with class-specific text prompt features, inspired by advancements in Vision-Language Models (VLMs). Given the sensitivity of zero-shot performance to the choice of hand-crafted text prompts, many prompt learning techniques have been developed for VLMs. We explore the efficacy of these approaches in ALMs and propose a novel method, Prompt Learning in Audio Language Models (PALM), which optimizes the feature space of the text encoder branch. Unlike existing methods that work in the input space, our approach results in greater training efficiency. We demonstrate the effectiveness of our approach on 11 audio recognition datasets, encompassing a variety of speech-processing tasks, and compare the results with three baselines in a few-shot learning setup. Our method is either on par with or outperforms other approaches while being computationally less demanding. Code is available at https://asif-hanif.github.io/palm/
BAPLe: Backdoor Attacks on Medical Foundational Models using Prompt Learning
Aug 15, 2024



Medical foundation models are gaining prominence in the medical community for their ability to derive general representations from extensive collections of medical image-text pairs. Recent research indicates that these models are susceptible to backdoor attacks, which allow them to classify clean images accurately but fail when specific triggers are introduced. However, traditional backdoor attacks necessitate a considerable amount of additional data to maliciously pre-train a model. This requirement is often impractical in medical imaging applications due to the usual scarcity of data. Inspired by the latest developments in learnable prompts, this work introduces a method to embed a backdoor into the medical foundation model during the prompt learning phase. By incorporating learnable prompts within the text encoder and introducing imperceptible learnable noise trigger to the input images, we exploit the full capabilities of the medical foundation models (Med-FM). Our method, BAPLe, requires only a minimal subset of data to adjust the noise trigger and the text prompts for downstream tasks, enabling the creation of an effective backdoor attack. Through extensive experiments with four medical foundation models, each pre-trained on different modalities and evaluated across six downstream datasets, we demonstrate the efficacy of our approach. BAPLe achieves a high backdoor success rate across all models and datasets, outperforming the baseline backdoor attack methods. Our work highlights the vulnerability of Med-FMs towards backdoor attacks and strives to promote the safe adoption of Med-FMs before their deployment in real-world applications. Code is available at https://asif-hanif.github.io/baple/.
On Evaluating Adversarial Robustness of Volumetric Medical Segmentation Models
Jun 12, 2024



Volumetric medical segmentation models have achieved significant success on organ and tumor-based segmentation tasks in recent years. However, their vulnerability to adversarial attacks remains largely unexplored, raising serious concerns regarding the real-world deployment of tools employing such models in the healthcare sector. This underscores the importance of investigating the robustness of existing models. In this context, our work aims to empirically examine the adversarial robustness across current volumetric segmentation architectures, encompassing Convolutional, Transformer, and Mamba-based models. We extend this investigation across four volumetric segmentation datasets, evaluating robustness under both white box and black box adversarial attacks. Overall, we observe that while both pixel and frequency-based attacks perform reasonably well under white box setting, the latter performs significantly better under transfer-based black box attacks. Across our experiments, we observe transformer-based models show higher robustness than convolution-based models with Mamba-based models being the most vulnerable. Additionally, we show that large-scale training of volumetric segmentation models improves the model's robustness against adversarial attacks. The code and pretrained models will be made available at https://github.com/HashmatShadab/Robustness-of-Volumetric-Medical-Segmentation-Models.
Frequency Domain Adversarial Training for Robust Volumetric Medical Segmentation
Jul 20, 2023



It is imperative to ensure the robustness of deep learning models in critical applications such as, healthcare. While recent advances in deep learning have improved the performance of volumetric medical image segmentation models, these models cannot be deployed for real-world applications immediately due to their vulnerability to adversarial attacks. We present a 3D frequency domain adversarial attack for volumetric medical image segmentation models and demonstrate its advantages over conventional input or voxel domain attacks. Using our proposed attack, we introduce a novel frequency domain adversarial training approach for optimizing a robust model against voxel and frequency domain attacks. Moreover, we propose frequency consistency loss to regulate our frequency domain adversarial training that achieves a better tradeoff between model's performance on clean and adversarial samples. Code is publicly available at https://github.com/asif-hanif/vafa.
Detecting Propaganda Techniques in Code-Switched Social Media Text
May 23, 2023



Propaganda is a form of communication intended to influence the opinions and the mindset of the public to promote a particular agenda. With the rise of social media, propaganda has spread rapidly, leading to the need for automatic propaganda detection systems. Most work on propaganda detection has focused on high-resource languages, such as English, and little effort has been made to detect propaganda for low-resource languages. Yet, it is common to find a mix of multiple languages in social media communication, a phenomenon known as code-switching. Code-switching combines different languages within the same text, which poses a challenge for automatic systems. With this in mind, here we propose the novel task of detecting propaganda techniques in code-switched text. To support this task, we create a corpus of 1,030 texts code-switching between English and Roman Urdu, annotated with 20 propaganda techniques, which we make publicly available. We perform a number of experiments contrasting different experimental setups, and we find that it is important to model the multilinguality directly (rather than using translation) as well as to use the right fine-tuning strategy. The code and the dataset are publicly available at https://github.com/mbzuai-nlp/propaganda-codeswitched-text
Subsampled Fourier Ptychography using Pretrained Invertible and Untrained Network Priors
May 13, 2020
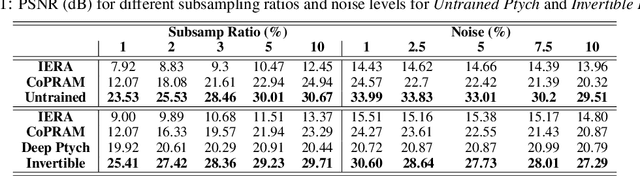
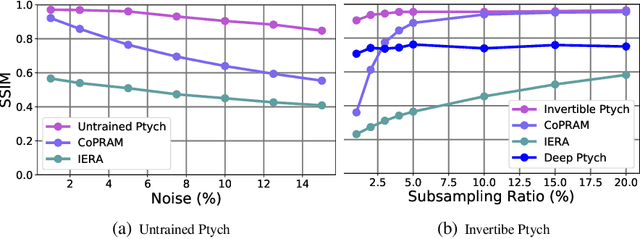
Recently pretrained generative models have shown promising results for subsampled Fourier Ptychography (FP) in terms of quality of reconstruction for extremely low sampling rate and high noise. However, one of the significant drawbacks of these pretrained generative priors is their limited representation capabilities. Moreover, training these generative models requires access to a large number of fully-observed clean samples of a particular class of images like faces or digits that is prohibitive to obtain in the context of FP. In this paper, we propose to leverage the power of pretrained invertible and untrained generative models to mitigate the representation error issue and requirement of a large number of example images (for training generative models) respectively. Through extensive experiments, we demonstrate the effectiveness of proposed approaches in the context of FP for low sampling rates and high noise levels.