 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Logical Reasoning of Language Models via Differentiable Symbolic Programming
May 05, 2023



Pre-trained large language models (LMs) struggle to perform logical reasoning reliably despite advances in scale and compositionality. In this work, we tackle this challenge through the lens of symbolic programming. We propose DSR-LM, a Differentiable Symbolic Reasoning framework where pre-trained LMs govern the perception of factual knowledge, and a symbolic module performs deductive reasoning. In contrast to works that rely on hand-crafted logic rules, our differentiable symbolic reasoning framework efficiently learns weighted rules and applies semantic loss to further improve LMs. DSR-LM is scalable, interpretable, and allows easy integration of prior knowledge, thereby supporting extensive symbolic programming to robustly derive a logical conclusion. The results of our experiments suggest that DSR-LM improves the logical reasoning abilities of pre-trained language models, resulting in a significant increase in accuracy of over 20% on deductive reasoning benchmarks. Furthermore, DSR-LM outperforms a variety of competitive baselines when faced with systematic changes in sequence length.
3D Semantic Segmentation in the Wild: Learning Generalized Models for Adverse-Condition Point Clouds
Apr 03, 2023



Robust point cloud parsing under all-weather conditions is crucial to level-5 autonomy in autonomous driving. However, how to learn a universal 3D semantic segmentation (3DSS) model is largely neglected as most existing benchmarks are dominated by point clouds captured under normal weather. We introduce SemanticSTF, an adverse-weather point cloud dataset that provides dense point-level annotations and allows to study 3DSS under various adverse weather conditions. We study all-weather 3DSS modeling under two setups: 1) domain adaptive 3DSS that adapts from normal-weather data to adverse-weather data; 2) domain generalizable 3DSS that learns all-weather 3DSS models from normal-weather data. Our studies reveal the challenge while existing 3DSS methods encounter adverse-weather data, showing the great value of SemanticSTF in steering the future endeavor along this very meaningful research direction. In addition, we design a domain randomization technique that alternatively randomizes the geometry styles of point clouds and aggregates their embeddings, ultimately leading to a generalizable model that can improve 3DSS under various adverse weather effectively. The SemanticSTF and related codes are available at \url{https://github.com/xiaoaoran/SemanticSTF}.
KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
Mar 30, 2023



Generative Adversarial Networks (GANs) rely heavily on large-scale training data for training high-quality image generation models. With limited training data, the GAN discriminator often suffers from severe overfitting which directly leads to degraded generation especially in generation diversity. Inspired by the recent advances in knowledge distillation (KD), we propose KD-DLGAN, a knowledge-distillation based generation framework that introduces pre-trained vision-language models for training effective data-limited generation models. KD-DLGAN consists of two innovative designs. The first is aggregated generative KD that mitigates the discriminator overfitting by challenging the discriminator with harder learning tasks and distilling more generalizable knowledge from the pre-trained models. The second is correlated generative KD that improves the generation diversity by distilling and preserving the diverse image-text correlation within the pre-trained models. Extensive experiments over multiple benchmarks show that KD-DLGAN achieves superior image generation with limited training data. In addition, KD-DLGAN complements the state-of-the-art with consistent and substantial performance gains.
StyleRF: Zero-shot 3D Style Transfer of Neural Radiance Fields
Mar 24, 2023



3D style transfer aims to render stylized novel views of a 3D scene with multi-view consistency. However, most existing work suffers from a three-way dilemma over accurate geometry reconstruction, high-quality stylization, and being generalizable to arbitrary new styles. We propose StyleRF (Style Radiance Fields), an innovative 3D style transfer technique that resolves the three-way dilemma by performing style transformation within the feature space of a radiance field. StyleRF employs an explicit grid of high-level features to represent 3D scenes, with which high-fidelity geometry can be reliably restored via volume rendering. In addition, it transforms the grid features according to the reference style which directly leads to high-quality zero-shot style transfer. StyleRF consists of two innovative designs. The first is sampling-invariant content transformation that makes the transformation invariant to the holistic statistics of the sampled 3D points and accordingly ensures multi-view consistency. The second is deferred style transformation of 2D feature maps which is equivalent to the transformation of 3D points but greatly reduces memory footprint without degrading multi-view consistency. Extensive experiments show that StyleRF achieves superior 3D stylization quality with precise geometry reconstruction and it can generalize to various new styles in a zero-shot manner.
Memory-adaptive Depth-wise Heterogenous Federated Learning
Mar 08, 2023



Federated learning is a promising paradigm that allows multiple clients to collaboratively train a model without sharing the local data. However, the presence of heterogeneous devices in federated learning, such as mobile phones and IoT devices with varying memory capabilities, would limit the scale and hence the performance of the model could be trained. The mainstream approaches to address memory limitations focus on width-slimming techniques, where different clients train subnetworks with reduced widths locally and then the server aggregates the subnetworks. The global model produced from these methods suffers from performance degradation due to the negative impact of the actions taken to handle the varying subnetwork widths in the aggregation phase. In this paper, we introduce a memory-adaptive depth-wise learning solution in FL called FeDepth, which adaptively decomposes the full model into blocks according to the memory budgets of each client and trains blocks sequentially to obtain a full inference model. Our method outperforms state-of-the-art approaches, achieving 5% and more than 10% improvements in top-1 accuracy on CIFAR-10 and CIFAR-100, respectively. We also demonstrate the effectiveness of depth-wise fine-tuning on ViT. Our findings highlight the importance of memory-aware techniques for federated learning with heterogeneous devices and the success of depth-wise training strategy in improving the global model's performance.
The Impact of Symbolic Representations on In-context Learning for Few-shot Reasoning
Dec 16, 2022Pre-trained language models (LMs) have shown remarkable reasoning performance using explanations (or ``chain-of-thought'' (CoT)) for in-context learning. On the other hand, these reasoning tasks are usually presumed to be more approachable for symbolic programming. To make progress towards understanding in-context learning, we curate synthetic datasets containing equivalent (natural, symbolic) data pairs, where symbolic examples contain first-order logic rules and predicates from knowledge bases (KBs). Then we revisit neuro-symbolic approaches and use Language Models as Logic Programmer (LMLP) that learns from demonstrations containing logic rules and corresponding examples to iteratively reason over KBs, recovering Prolog's backward chaining algorithm. Comprehensive experiments are included to systematically compare LMLP with CoT in deductive reasoning settings, showing that LMLP enjoys more than 25% higher accuracy than CoT on length generalization benchmarks even with fewer parameters.
MixMask: Revisiting Masked Siamese Self-supervised Learning in Asymmetric Distance
Oct 20, 2022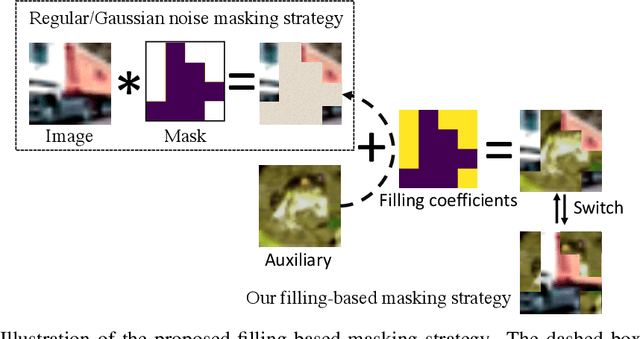
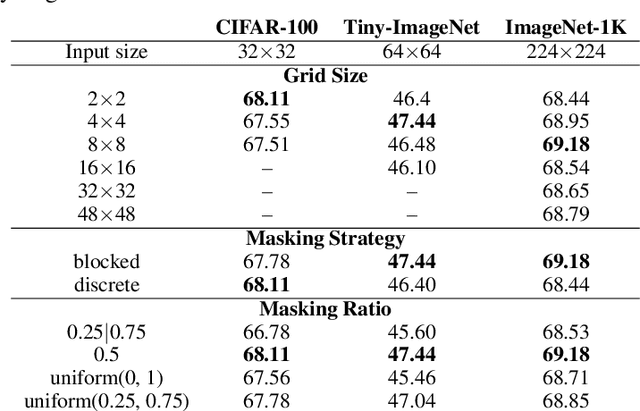
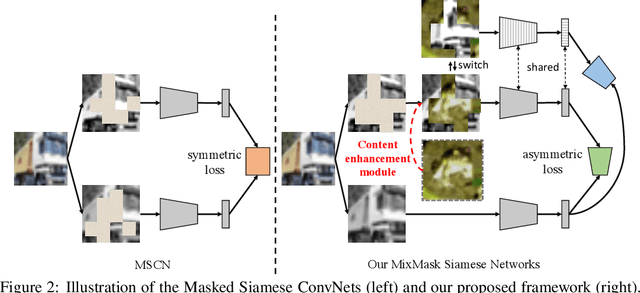

Recent advances in self-supervised learning integrate Masked Modeling and Siamese Networks into a single framework to fully reap the advantages of both the two techniques. However, previous erasing-based masking scheme in masked image modeling is not originally designed for siamese networks. Existing approaches simply inherit the default loss design from previous siamese networks, and ignore the information loss and distance change after employing masking operation in the frameworks. In this paper, we propose a filling-based masking strategy called MixMask to prevent information loss due to the randomly erased areas of an image in vanilla masking method. We further introduce a dynamic loss function design with soft distance to adapt the integrated architecture and avoid mismatches between transformed input and objective in Masked Siamese ConvNets (MSCN). The dynamic loss distance is calculated according to the proposed mix-masking scheme. Extensive experiments are conducted on various datasets of CIFAR-100, Tiny-ImageNet and ImageNet-1K. The results demonstrate that the proposed framework can achieve better accuracy on linear probing, semi-supervised and {supervised finetuning}, which outperforms the state-of-the-art MSCN by a significant margin. We also show the superiority on downstream tasks of object detection and segmentation. Our source code is available at https://github.com/LightnessOfBeing/MixMask.
AMP: Automatically Finding Model Parallel Strategies with Heterogeneity Awareness
Oct 13, 2022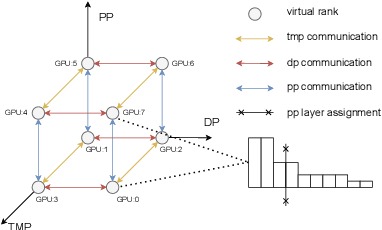


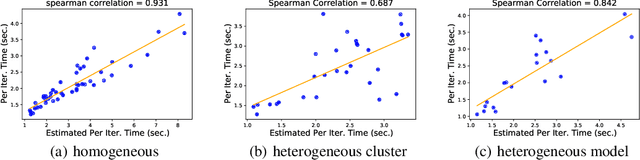
Scaling up model sizes can lead to fundamentally new capabilities in many machine learning (ML) tasks. However, training big models requires strong distributed system expertise to carefully design model-parallel execution strategies that suit the model architectures and cluster setups. In this paper, we develop AMP, a framework that automatically derives such strategies. AMP identifies a valid space of model parallelism strategies and efficiently searches the space for high-performed strategies, by leveraging a cost model designed to capture the heterogeneity of the model and cluster specifications. Unlike existing methods, AMP is specifically tailored to support complex models composed of uneven layers and cluster setups with more heterogeneous accelerators and bandwidth. We evaluate AMP on popular models and cluster setups from public clouds and show that AMP returns parallel strategies that match the expert-tuned strategies on typical cluster setups. On heterogeneous clusters or models with heterogeneous architectures, AMP finds strategies with 1.54x and 1.77x higher throughput than state-of-the-art model-parallel systems, respectively.
Betty: An Automatic Differentiation Library for Multilevel Optimization
Jul 05, 2022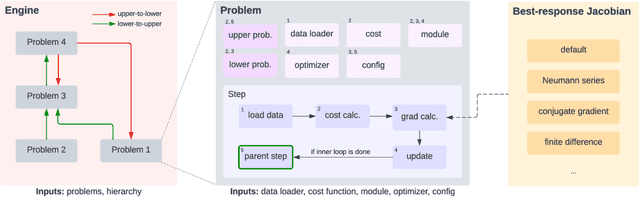
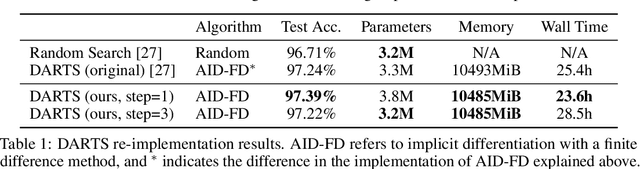
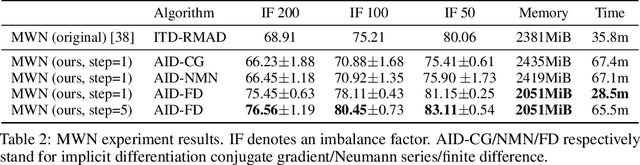

Multilevel optimization has been widely adopted as a mathematical foundation for a myriad of machine learning problems, such as hyperparameter optimization, meta-learning, and reinforcement learning, to name a few. Nonetheless, implementing multilevel optimization programs oftentimes requires expertise in both mathematics and programming, stunting research in this field. We take an initial step towards closing this gap by introducing Betty, a high-level software library for gradient-based multilevel optimization. To this end, we develop an automatic differentiation procedure based on a novel interpretation of multilevel optimization as a dataflow graph. We further abstract the main components of multilevel optimization as Python classes, to enable easy, modular, and maintainable programming. We empirically demonstrate that Betty can be used as a high-level programming interface for an array of multilevel optimization programs, while also observing up to 11\% increase in test accuracy, 14\% decrease in GPU memory usage, and 20\% decrease in wall time over existing implementations on multiple benchmarks. The code is available at http://github.com/leopard-ai/betty .
SDQ: Stochastic Differentiable Quantization with Mixed Precision
Jun 17, 2022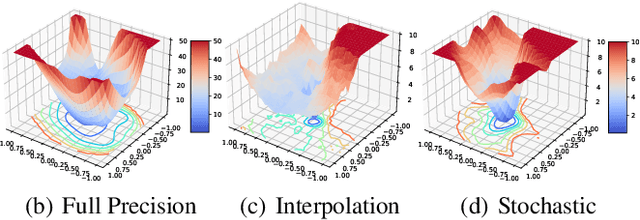
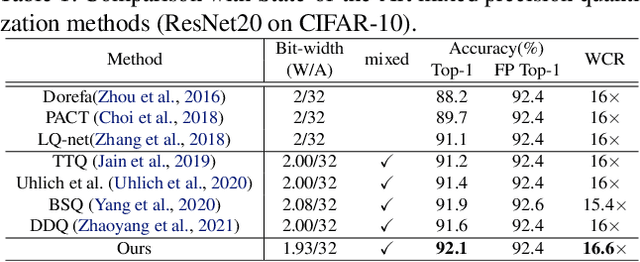
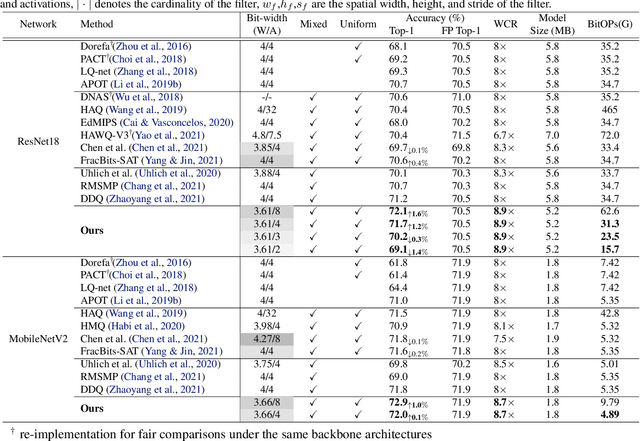
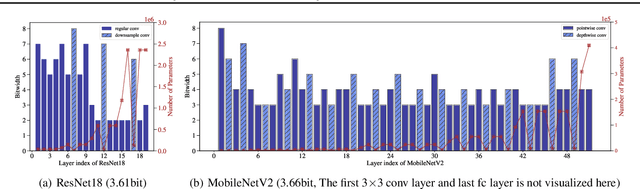
In order to deploy deep models in a computationally efficient manner, model quantization approaches have been frequently used. In addition, as new hardware that supports mixed bitwidth arithmetic operations, recent research on mixed precision quantization (MPQ) begins to fully leverage the capacity of representation by searching optimized bitwidths for different layers and modules in a network. However, previous studies mainly search the MPQ strategy in a costly scheme using reinforcement learning, neural architecture search, etc., or simply utilize partial prior knowledge for bitwidth assignment, which might be biased and sub-optimal. In this work, we present a novel Stochastic Differentiable Quantization (SDQ) method that can automatically learn the MPQ strategy in a more flexible and globally-optimized space with smoother gradient approximation. Particularly, Differentiable Bitwidth Parameters (DBPs) are employed as the probability factors in stochastic quantization between adjacent bitwidth choices. After the optimal MPQ strategy is acquired, we further train our network with entropy-aware bin regularization and knowledge distillation. We extensively evaluate our method for several networks on different hardware (GPUs and FPGA) and datasets. SDQ outperforms all state-of-the-art mixed or single precision quantization with a lower bitwidth and is even better than the full-precision counterparts across various ResNet and MobileNet families, demonstrating the effectiveness and superiority of our method.