 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation
Sep 14, 2021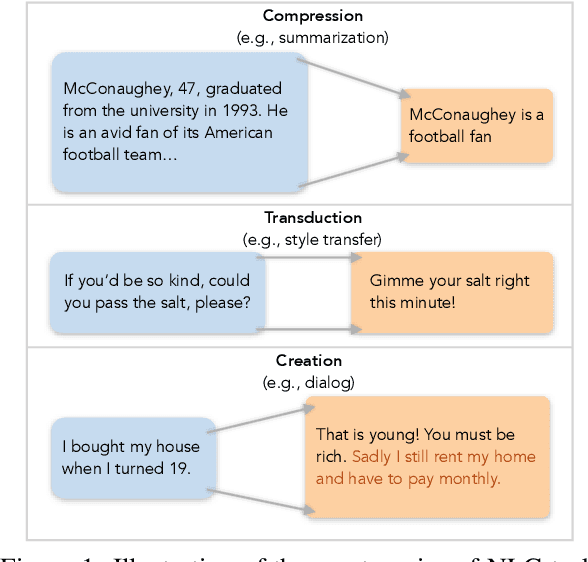
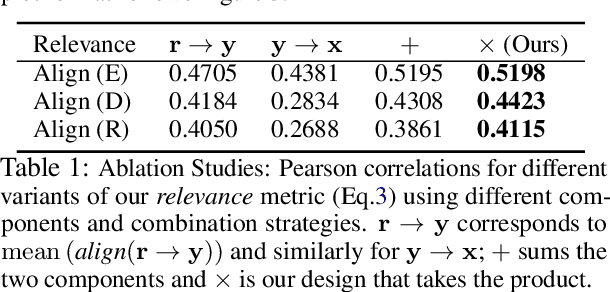
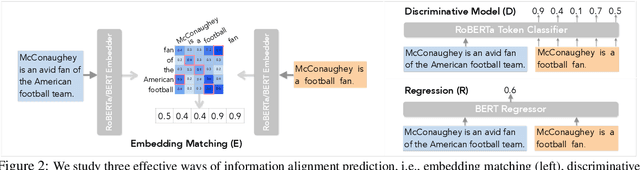

Natural language generation (NLG) spans a broad range of tasks, each of which serves for specific objectives and desires different properties of generated text. The complexity makes automatic evaluation of NLG particularly challenging. Previous work has typically focused on a single task and developed individual evaluation metrics based on specific intuitions. In this paper, we propose a unifying perspective based on the nature of information change in NLG tasks, including compression (e.g., summarization), transduction (e.g., text rewriting), and creation (e.g., dialog). Information alignment between input, context, and output text plays a common central role in characterizing the generation. With automatic alignment prediction models, we develop a family of interpretable metrics that are suitable for evaluating key aspects of different NLG tasks, often without need of gold reference data. Experiments show the uniformly designed metrics achieve stronger or comparable correlations with human judgement compared to state-of-the-art metrics in each of diverse tasks, including text summarization, style transfer, and knowledge-grounded dialog.
Knowledge-Aware Meta-learning for Low-Resource Text Classification
Sep 10, 2021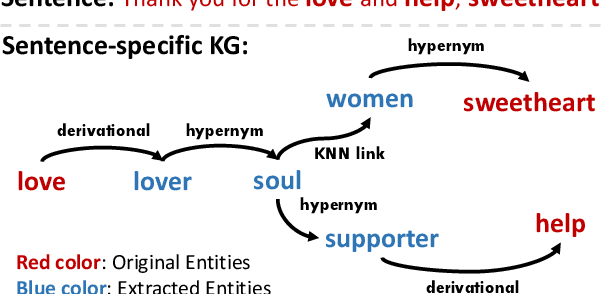
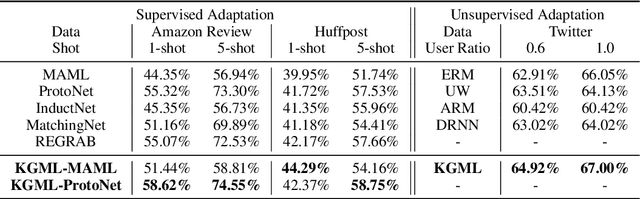
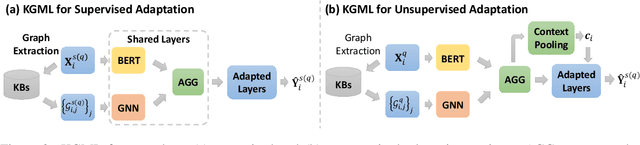
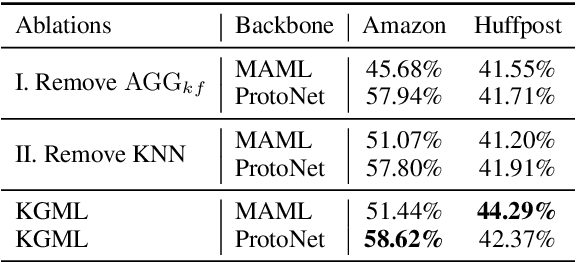
Meta-learning has achieved great success in leveraging the historical learned knowledge to facilitate the learning process of the new task. However, merely learning the knowledge from the historical tasks, adopted by current meta-learning algorithms, may not generalize well to testing tasks when they are not well-supported by training tasks. This paper studies a low-resource text classification problem and bridges the gap between meta-training and meta-testing tasks by leveraging the external knowledge bases. Specifically, we propose KGML to introduce additional representation for each sentence learned from the extracted sentence-specific knowledge graph. The extensive experiments on three datasets demonstrate the effectiveness of KGML under both supervised adaptation and unsupervised adaptation settings.
Panoramic Learning with A Standardized Machine Learning Formalism
Aug 17, 2021Machine Learning (ML) is about computational methods that enable machines to learn concepts from experiences. In handling a wide variety of experiences ranging from data instances, knowledge, constraints, to rewards, adversaries, and lifelong interplay in an ever-growing spectrum of tasks, contemporary ML/AI research has resulted in a multitude of learning paradigms and methodologies. Despite the continual progresses on all different fronts, the disparate narrowly-focused methods also make standardized, composable, and reusable development of learning solutions difficult, and make it costly if possible to build AI agents that panoramically learn from all types of experiences. This paper presents a standardized ML formalism, in particular a standard equation of the learning objective, that offers a unifying understanding of diverse ML algorithms, making them special cases due to different choices of modeling components. The framework also provides guidance for mechanic design of new ML solutions, and serves as a promising vehicle towards panoramic learning with all experiences.
Text Generation with Efficient (Soft) Q-Learning
Jun 17, 2021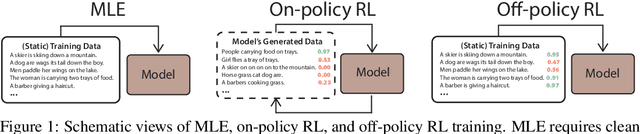
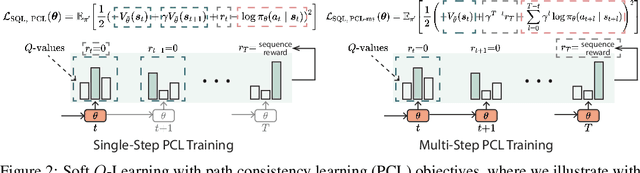
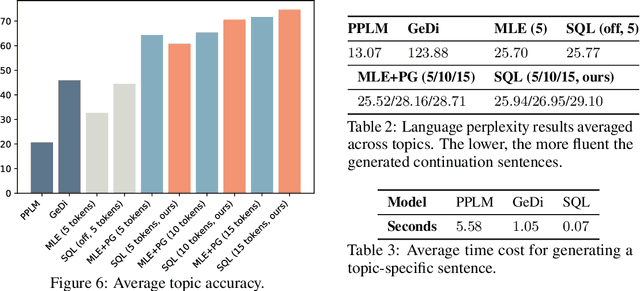
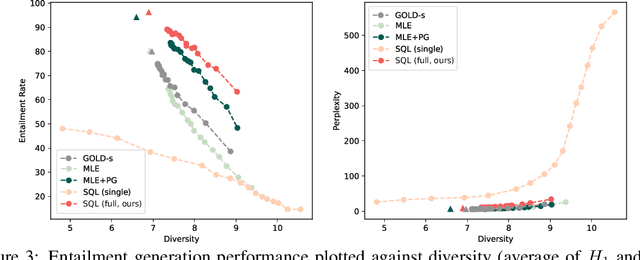
Maximum likelihood estimation (MLE) is the predominant algorithm for training text generation models. This paradigm relies on direct supervision examples, which is not applicable to many applications, such as generating adversarial attacks or generating prompts to control language models. Reinforcement learning (RL) on the other hand offers a more flexible solution by allowing users to plug in arbitrary task metrics as reward. Yet previous RL algorithms for text generation, such as policy gradient (on-policy RL) and Q-learning (off-policy RL), are often notoriously inefficient or unstable to train due to the large sequence space and the sparse reward received only at the end of sequences. In this paper, we introduce a new RL formulation for text generation from the soft Q-learning perspective. It further enables us to draw from the latest RL advances, such as path consistency learning, to combine the best of on-/off-policy updates, and learn effectively from sparse reward. We apply the approach to a wide range of tasks, including learning from noisy/negative examples, adversarial attacks, and prompt generation. Experiments show our approach consistently outperforms both task-specialized algorithms and the previous RL methods. On standard supervised tasks where MLE prevails, our approach also achieves competitive performance and stability by training text generation from scratch.
Amortized Auto-Tuning: Cost-Efficient Transfer Optimization for Hyperparameter Recommendation
Jun 17, 2021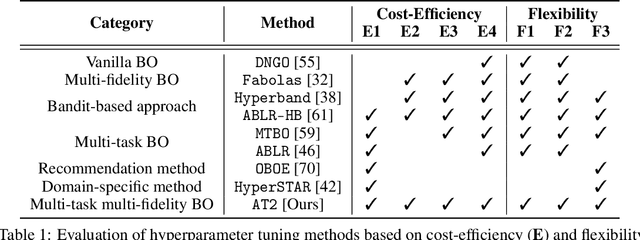
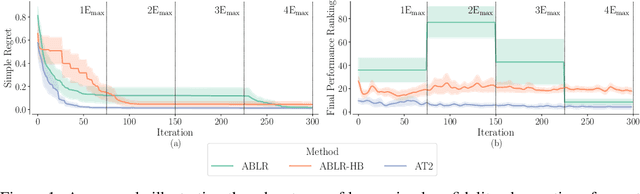
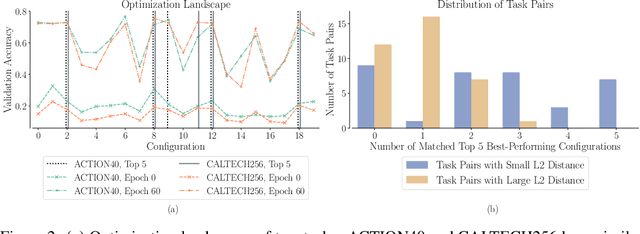

With the surge in the number of hyperparameters and training times of modern machine learning models, hyperparameter tuning is becoming increasingly expensive. Although methods have been proposed to speed up tuning via knowledge transfer, they typically require the final performance of hyperparameters and do not focus on low-fidelity information. Nevertheless, this common practice is suboptimal and can incur an unnecessary use of resources. It is more cost-efficient to instead leverage the low-fidelity tuning observations to measure inter-task similarity and transfer knowledge from existing to new tasks accordingly. However, performing multi-fidelity tuning comes with its own challenges in the transfer setting: the noise in the additional observations and the need for performance forecasting. Therefore, we conduct a thorough analysis of the multi-task multi-fidelity Bayesian optimization framework, which leads to the best instantiation--amortized auto-tuning (AT2). We further present an offline-computed 27-task hyperparameter recommendation (HyperRec) database to serve the community. Extensive experiments on HyperRec and other real-world databases illustrate the effectiveness of our AT2 method.
GeoQA: A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning
Jun 08, 2021
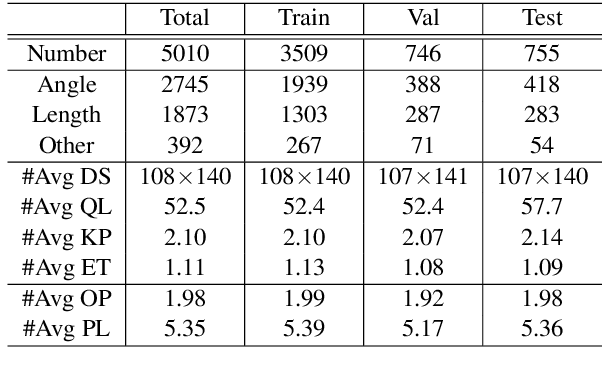

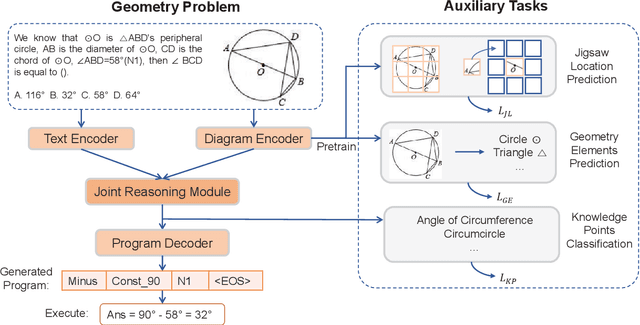
Automatic math problem solving has recently attracted increasing attention as a long-standing AI benchmark. In this paper, we focus on solving geometric problems, which requires a comprehensive understanding of textual descriptions, visual diagrams, and theorem knowledge. However, the existing methods were highly dependent on handcraft rules and were merely evaluated on small-scale datasets. Therefore, we propose a Geometric Question Answering dataset GeoQA, containing 5,010 geometric problems with corresponding annotated programs, which illustrate the solving process of the given problems. Compared with another publicly available dataset GeoS, GeoQA is 25 times larger, in which the program annotations can provide a practical testbed for future research on explicit and explainable numerical reasoning. Moreover, we introduce a Neural Geometric Solver (NGS) to address geometric problems by comprehensively parsing multimodal information and generating interpretable programs. We further add multiple self-supervised auxiliary tasks on NGS to enhance cross-modal semantic representation. Extensive experiments on GeoQA validate the effectiveness of our proposed NGS and auxiliary tasks. However, the results are still significantly lower than human performance, which leaves large room for future research. Our benchmark and code are released at https://github.com/chen-judge/GeoQA .
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021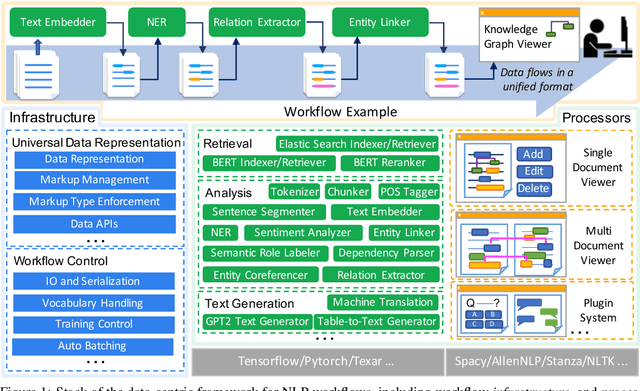
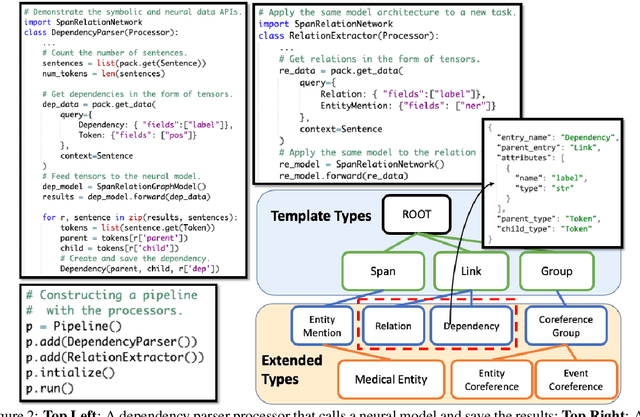
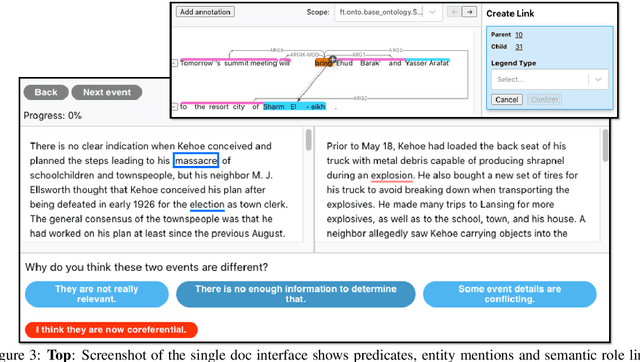
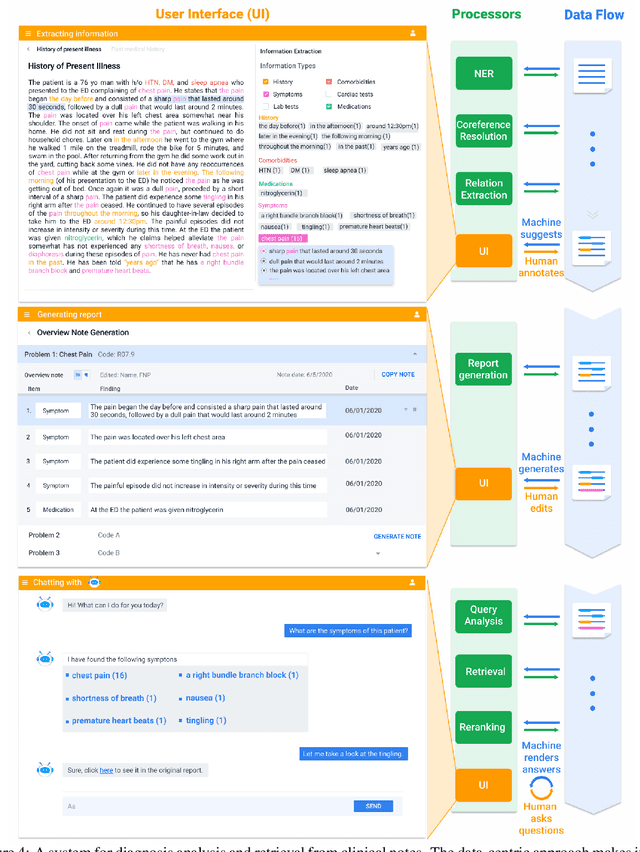
Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
Technology Readiness Levels for Machine Learning Systems
Jan 11, 2021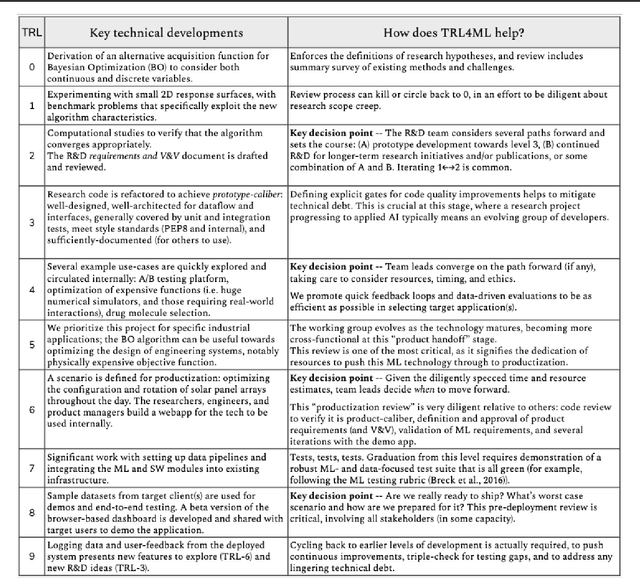

The development and deployment of machine learning (ML) systems can be executed easily with modern tools, but the process is typically rushed and means-to-an-end. The lack of diligence can lead to technical debt, scope creep and misaligned objectives, model misuse and failures, and expensive consequences. Engineering systems, on the other hand, follow well-defined processes and testing standards to streamline development for high-quality, reliable results. The extreme is spacecraft systems, where mission critical measures and robustness are ingrained in the development process. Drawing on experience in both spacecraft engineering and ML (from research through product across domain areas), we have developed a proven systems engineering approach for machine learning development and deployment. Our "Machine Learning Technology Readiness Levels" (MLTRL) framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for ML workflows, including key distinctions from traditional software engineering. Even more, MLTRL defines a lingua franca for people across teams and organizations to work collaboratively on artificial intelligence and machine learning technologies. Here we describe the framework and elucidate it with several real world use-cases of developing ML methods from basic research through productization and deployment, in areas such as medical diagnostics, consumer computer vision, satellite imagery, and particle physics.
Towards Robust Medical Image Segmentation on Small-Scale Data with Incomplete Labels
Nov 28, 2020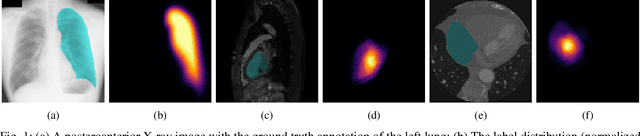

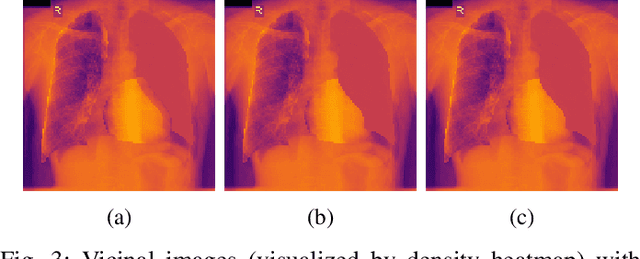
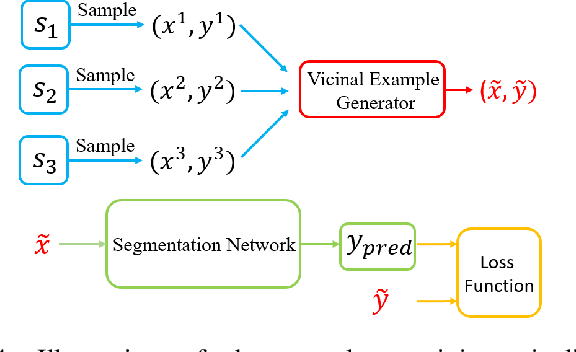
The data-driven nature of deep learning models for semantic segmentation requires a large number of pixel-level annotations. However, large-scale and fully labeled medical datasets are often unavailable for practical tasks. Recently, partially supervised methods have been proposed to utilize images with incomplete labels to mitigate the data scarcity problem in the medical domain. As an emerging research area, the breakthroughs made by existing methods rely on either large-scale data or complex model design, which makes them 1) less practical for certain real-life tasks and 2) less robust for small-scale data. It is time to step back and think about the robustness of partially supervised methods and how to maximally utilize small-scale and partially labeled data for medical image segmentation tasks. To bridge the methodological gaps in label-efficient deep learning with partial supervision, we propose RAMP, a simple yet efficient data augmentation framework for partially supervised medical image segmentation by exploiting the assumption that patients share anatomical similarities. We systematically evaluate RAMP and the previous methods in various controlled multi-structure segmentation tasks. Compared to the mainstream approaches, RAMP consistently improves the performance of traditional segmentation networks on small-scale partially labeled data and utilize additional image-wise weak annotations.
Squared $\ell_2$ Norm as Consistency Loss for Leveraging Augmented Data to Learn Robust and Invariant Representations
Nov 25, 2020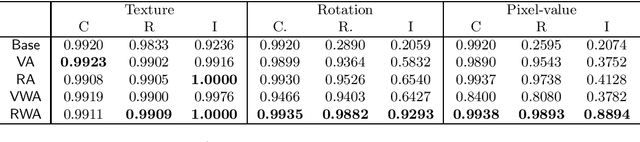
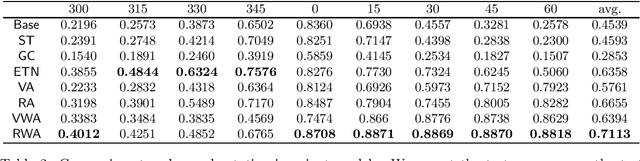


Data augmentation is one of the most popular techniques for improving the robustness of neural networks. In addition to directly training the model with original samples and augmented samples, a torrent of methods regularizing the distance between embeddings/representations of the original samples and their augmented counterparts have been introduced. In this paper, we explore these various regularization choices, seeking to provide a general understanding of how we should regularize the embeddings. Our analysis suggests the ideal choices of regularization correspond to various assumptions. With an invariance test, we argue that regularization is important if the model is to be used in a broader context than the accuracy-driven setting because non-regularized approaches are limited in learning the concept of invariance, despite equally high accuracy. Finally, we also show that the generic approach we identified (squared $\ell_2$ norm regularized augmentation) outperforms several recent methods, which are each specially designed for one task and significantly more complicated than ours, over three different tasks.