 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretically Principled Trade-off between Robustness and Accuracy
Jan 24, 2019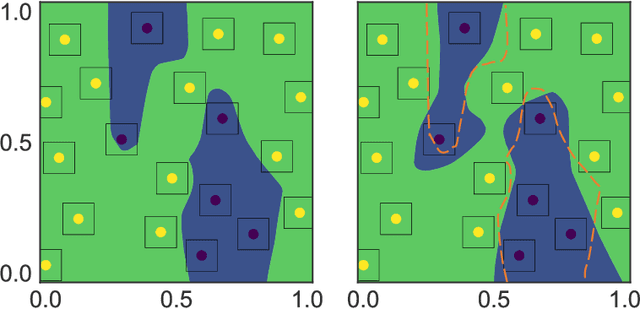

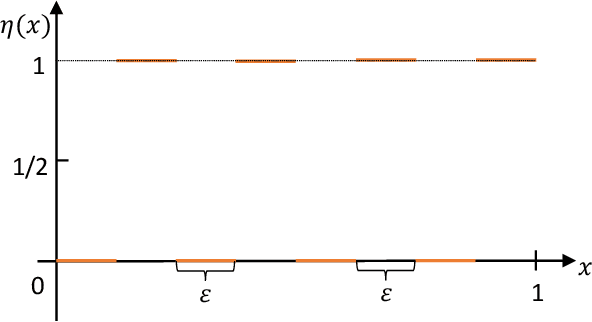
We identify a trade-off between robustness and accuracy that serves as a guiding principle in the design of defenses against adversarial examples. Although the problem has been widely studied empirically, much remains unknown concerning the theory underlying this trade-off. In this work, we quantify the trade-off in terms of the gap between the risk for adversarial examples and the risk for non-adversarial examples. The challenge is to provide tight bounds on this quantity in terms of a surrogate loss. We give an optimal upper bound on this quantity in terms of classification-calibrated loss, which matches the lower bound in the worst case. Inspired by our theoretical analysis, we also design a new defense method, TRADES, to trade adversarial robustness off against accuracy. Our proposed algorithm performs well experimentally in real-world datasets. The methodology is the foundation of our entry to the NeurIPS 2018 Adversarial Vision Challenge in which we won the 1st place out of 1,995 submissions in the robust model track, surpassing the runner-up approach by $11.41\%$ in terms of mean $\ell_2$ perturbation distance.
Stackelberg GAN: Towards Provable Minimax Equilibrium via Multi-Generator Architectures
Nov 19, 2018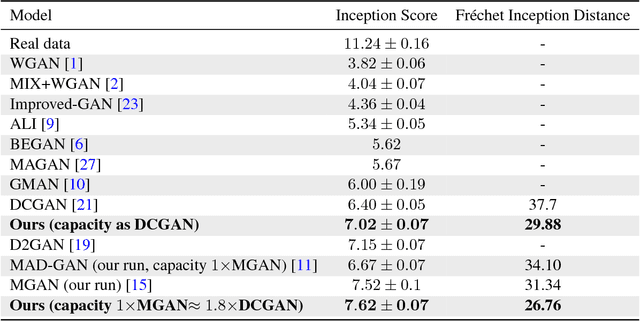
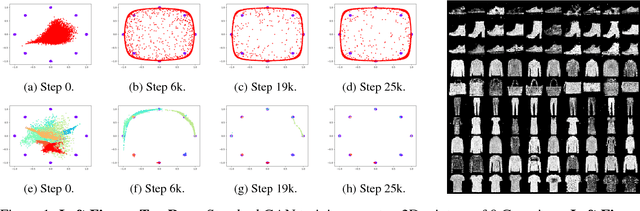
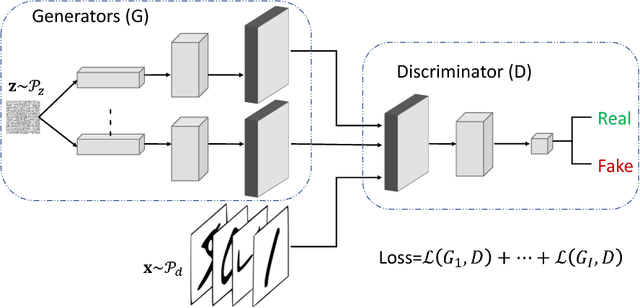
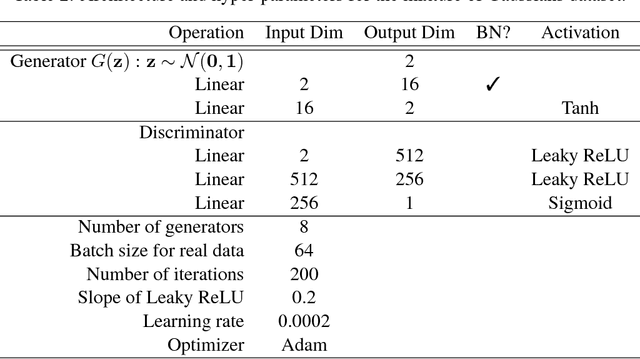
We study the problem of alleviating the instability issue in the GAN training procedure via new architecture design. The discrepancy between the minimax and maximin objective values could serve as a proxy for the difficulties that the alternating gradient descent encounters in the optimization of GANs. In this work, we give new results on the benefits of multi-generator architecture of GANs. We show that the minimax gap shrinks to $\epsilon$ as the number of generators increases with rate $\widetilde{O}(1/\epsilon)$. This improves over the best-known result of $\widetilde{O}(1/\epsilon^2)$. At the core of our techniques is a novel application of Shapley-Folkman lemma to the generic minimax problem, where in the literature the technique was only known to work when the objective function is restricted to the Lagrangian function of a constraint optimization problem. Our proposed Stackelberg GAN performs well experimentally in both synthetic and real-world datasets, improving Fr\'echet Inception Distance by $14.61\%$ over the previous multi-generator GANs on the benchmark datasets.
Discourse in Multimedia: A Case Study in Information Extraction
Nov 13, 2018
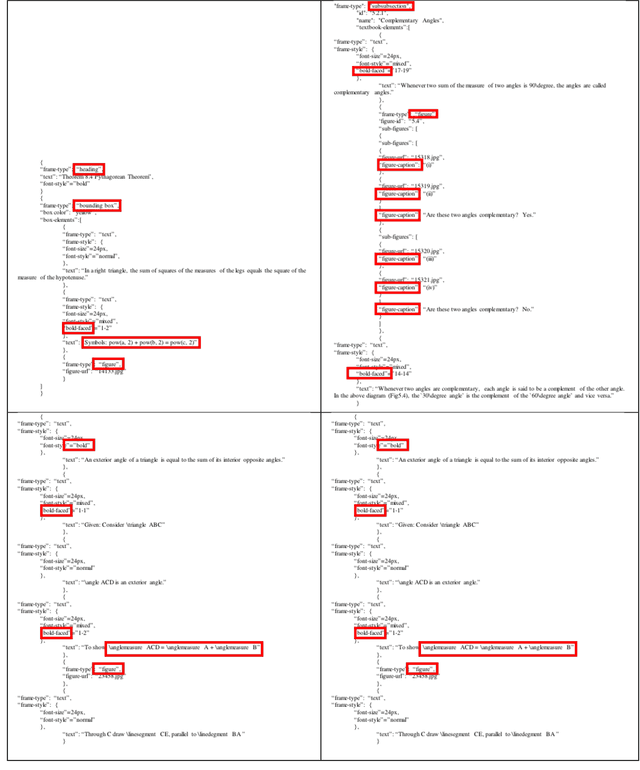
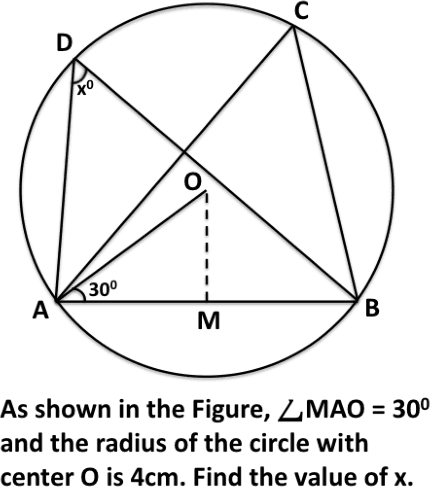
To ensure readability, text is often written and presented with due formatting. These text formatting devices help the writer to effectively convey the narrative. At the same time, these help the readers pick up the structure of the discourse and comprehend the conveyed information. There have been a number of linguistic theories on discourse structure of text. However, these theories only consider unformatted text. Multimedia text contains rich formatting features which can be leveraged for various NLP tasks. In this paper, we study some of these discourse features in multimedia text and what communicative function they fulfil in the context. We examine how these multimedia discourse features can be used to improve an information extraction system. We show that the discourse and text layout features provide information that is complementary to lexical semantic information commonly used for information extraction. As a case study, we use these features to harvest structured subject knowledge of geometry from textbooks. We show that the harvested structured knowledge can be used to improve an existing solver for geometry problems, making it more accurate as well as more explainable.
DAGs with NO TEARS: Continuous Optimization for Structure Learning
Nov 03, 2018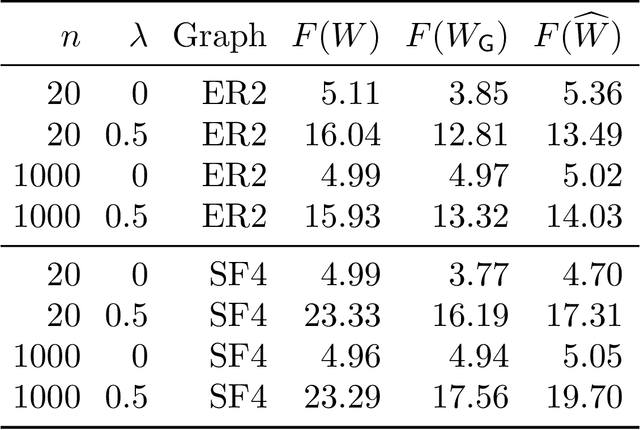
Estimating the structure of directed acyclic graphs (DAGs, also known as Bayesian networks) is a challenging problem since the search space of DAGs is combinatorial and scales superexponentially with the number of nodes. Existing approaches rely on various local heuristics for enforcing the acyclicity constraint. In this paper, we introduce a fundamentally different strategy: We formulate the structure learning problem as a purely \emph{continuous} optimization problem over real matrices that avoids this combinatorial constraint entirely. This is achieved by a novel characterization of acyclicity that is not only smooth but also exact. The resulting problem can be efficiently solved by standard numerical algorithms, which also makes implementation effortless. The proposed method outperforms existing ones, without imposing any structural assumptions on the graph such as bounded treewidth or in-degree. Code implementing the proposed algorithm is open-source and publicly available at https://github.com/xunzheng/notears.
Transformation Autoregressive Networks
Oct 23, 2018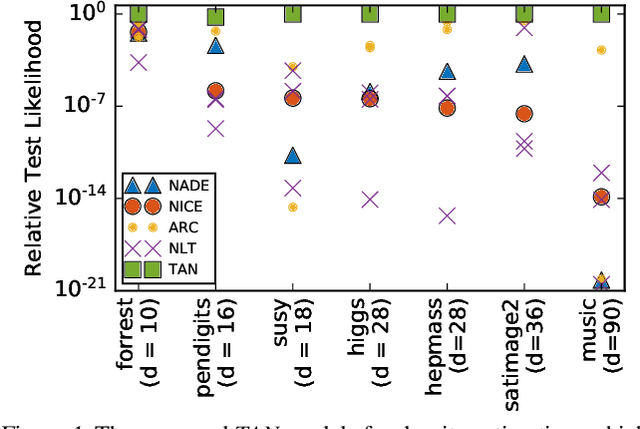
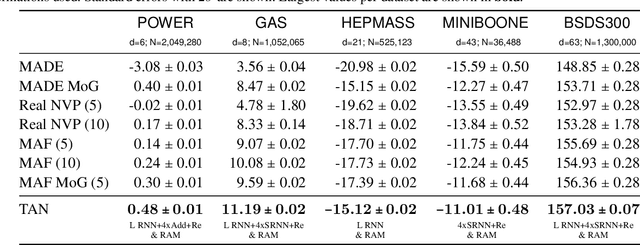
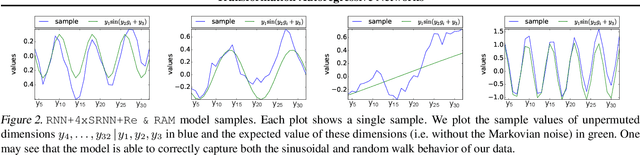
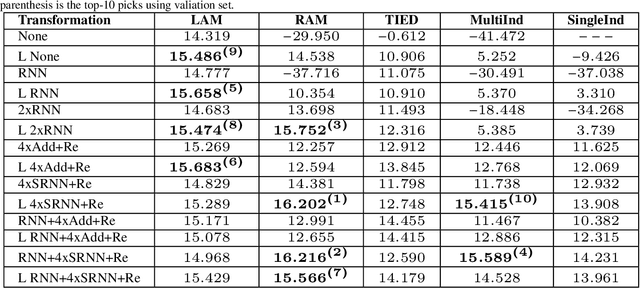
The fundamental task of general density estimation $p(x)$ has been of keen interest to machine learning. In this work, we attempt to systematically characterize methods for density estimation. Broadly speaking, most of the existing methods can be categorized into either using: \textit{a}) autoregressive models to estimate the conditional factors of the chain rule, $p(x_{i}\, |\, x_{i-1}, \ldots)$; or \textit{b}) non-linear transformations of variables of a simple base distribution. Based on the study of the characteristics of these categories, we propose multiple novel methods for each category. For example we proposed RNN based transformations to model non-Markovian dependencies. Further, through a comprehensive study over both real world and synthetic data, we show for that jointly leveraging transformations of variables and autoregressive conditional models, results in a considerable improvement in performance. We illustrate the use of our models in outlier detection and image modeling. Finally we introduce a novel data driven framework for learning a family of distributions.
Fault Tolerance in Iterative-Convergent Machine Learning
Oct 17, 2018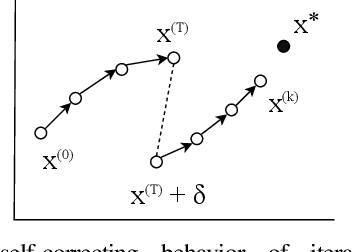
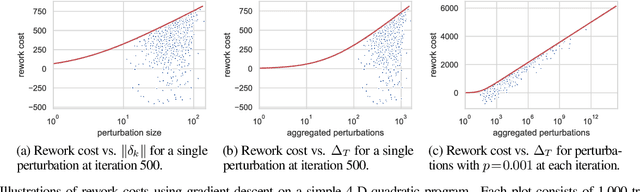
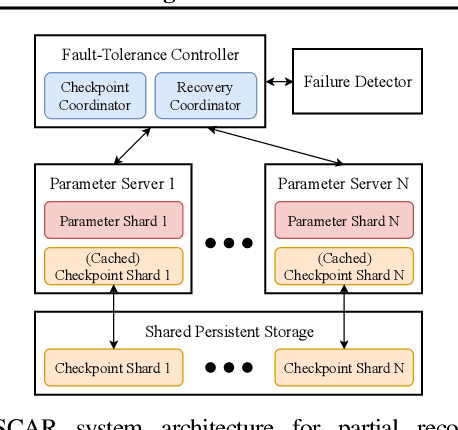
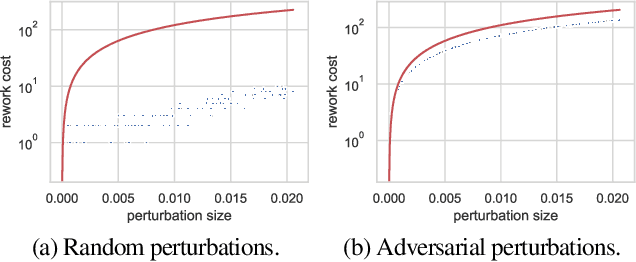
Machine learning (ML) training algorithms often possess an inherent self-correcting behavior due to their iterative-convergent nature. Recent systems exploit this property to achieve adaptability and efficiency in unreliable computing environments by relaxing the consistency of execution and allowing calculation errors to be self-corrected during training. However, the behavior of such systems are only well understood for specific types of calculation errors, such as those caused by staleness, reduced precision, or asynchronicity, and for specific types of training algorithms, such as stochastic gradient descent. In this paper, we develop a general framework to quantify the effects of calculation errors on iterative-convergent algorithms and use this framework to design new strategies for checkpoint-based fault tolerance. Our framework yields a worst-case upper bound on the iteration cost of arbitrary perturbations to model parameters during training. Our system, SCAR, employs strategies which reduce the iteration cost upper bound due to perturbations incurred when recovering from checkpoints. We show that SCAR can reduce the iteration cost of partial failures by 78% - 95% when compared with traditional checkpoint-based fault tolerance across a variety of ML models and training algorithms.
Toward Understanding the Impact of Staleness in Distributed Machine Learning
Oct 08, 2018
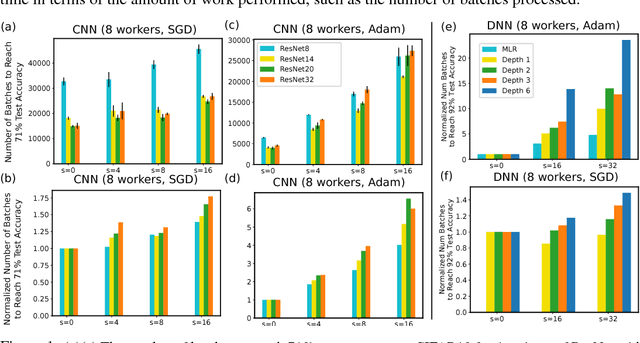
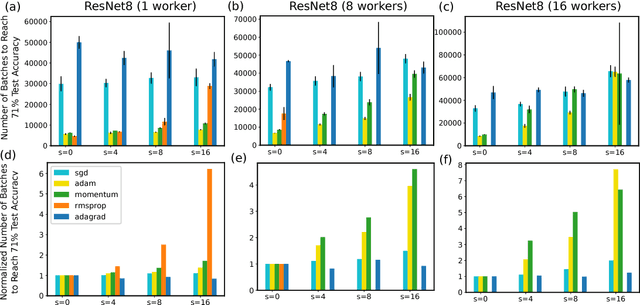
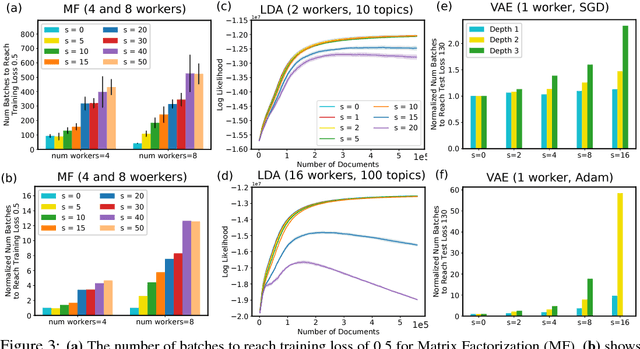
Many distributed machine learning (ML) systems adopt the non-synchronous execution in order to alleviate the network communication bottleneck, resulting in stale parameters that do not reflect the latest updates. Despite much development in large-scale ML, the effects of staleness on learning are inconclusive as it is challenging to directly monitor or control staleness in complex distributed environments. In this work, we study the convergence behaviors of a wide array of ML models and algorithms under delayed updates. Our extensive experiments reveal the rich diversity of the effects of staleness on the convergence of ML algorithms and offer insights into seemingly contradictory reports in the literature. The empirical findings also inspire a new convergence analysis of stochastic gradient descent in non-convex optimization under staleness, matching the best-known convergence rate of O(1/\sqrt{T}).
DiCE: The Infinitely Differentiable Monte-Carlo Estimator
Sep 19, 2018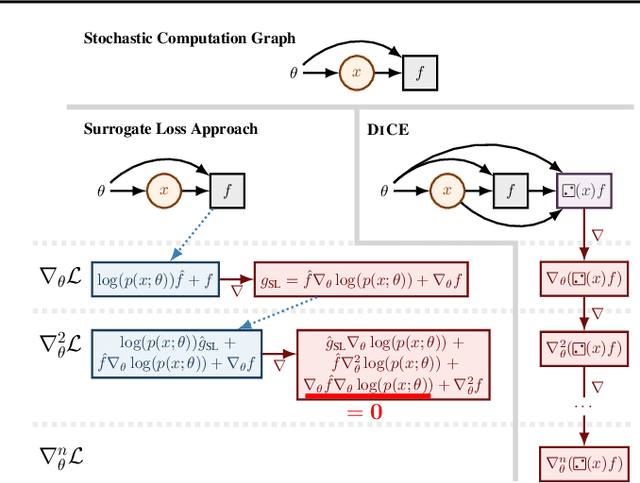
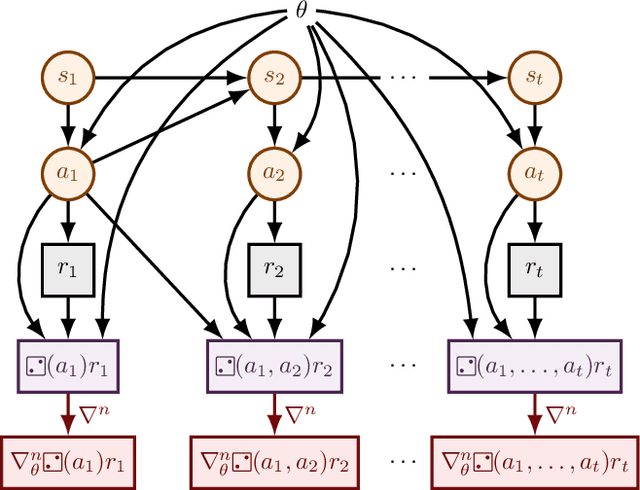
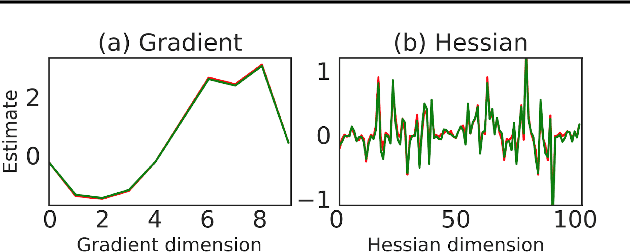
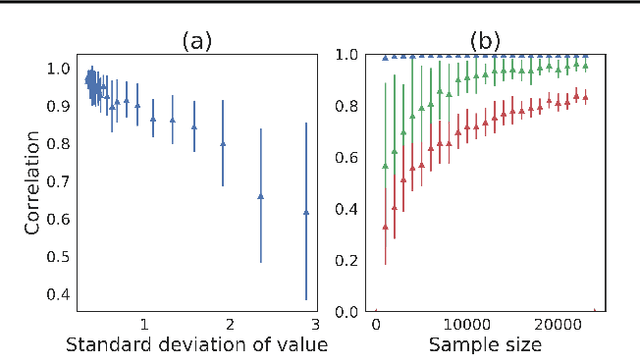
The score function estimator is widely used for estimating gradients of stochastic objectives in stochastic computation graphs (SCG), eg, in reinforcement learning and meta-learning. While deriving the first-order gradient estimators by differentiating a surrogate loss (SL) objective is computationally and conceptually simple, using the same approach for higher-order derivatives is more challenging. Firstly, analytically deriving and implementing such estimators is laborious and not compliant with automatic differentiation. Secondly, repeatedly applying SL to construct new objectives for each order derivative involves increasingly cumbersome graph manipulations. Lastly, to match the first-order gradient under differentiation, SL treats part of the cost as a fixed sample, which we show leads to missing and wrong terms for estimators of higher-order derivatives. To address all these shortcomings in a unified way, we introduce DiCE, which provides a single objective that can be differentiated repeatedly, generating correct estimators of derivatives of any order in SCGs. Unlike SL, DiCE relies on automatic differentiation for performing the requisite graph manipulations. We verify the correctness of DiCE both through a proof and numerical evaluation of the DiCE derivative estimates. We also use DiCE to propose and evaluate a novel approach for multi-agent learning. Our code is available at https://www.github.com/alshedivat/lola.
Toward Controlled Generation of Text
Sep 13, 2018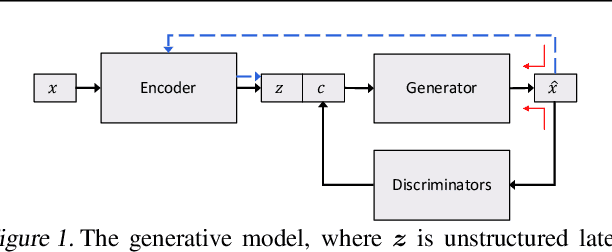
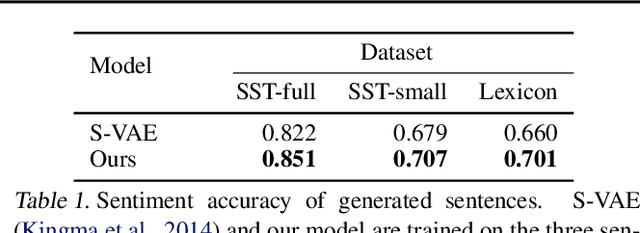
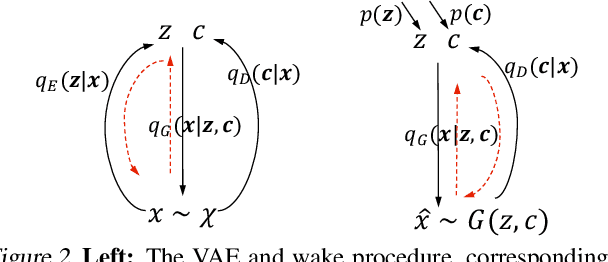
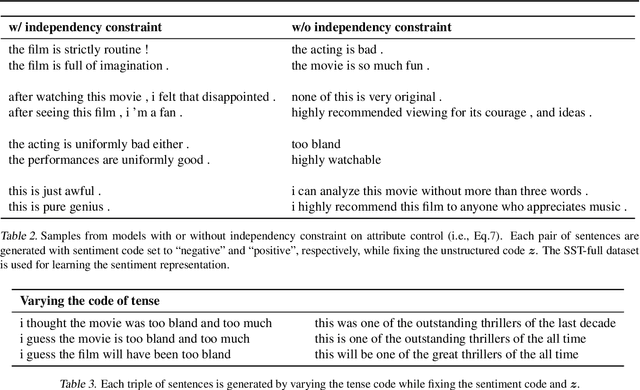
Generic generation and manipulation of text is challenging and has limited success compared to recent deep generative modeling in visual domain. This paper aims at generating plausible natural language sentences, whose attributes are dynamically controlled by learning disentangled latent representations with designated semantics. We propose a new neural generative model which combines variational auto-encoders and holistic attribute discriminators for effective imposition of semantic structures. With differentiable approximation to discrete text samples, explicit constraints on independent attribute controls, and efficient collaborative learning of generator and discriminators, our model learns highly interpretable representations from even only word annotations, and produces realistic sentences with desired attributes. Quantitative evaluation validates the accuracy of sentence and attribute generation.
Sample Complexity of Nonparametric Semi-Supervised Learning
Sep 10, 2018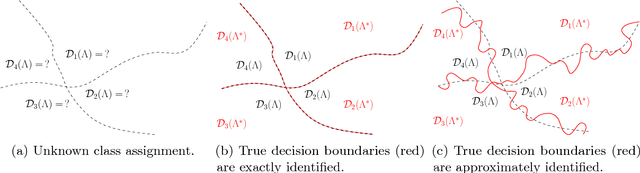
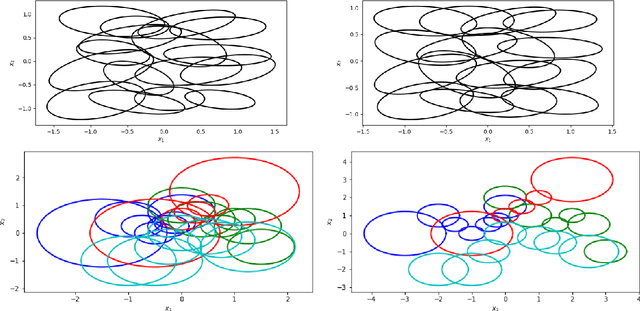
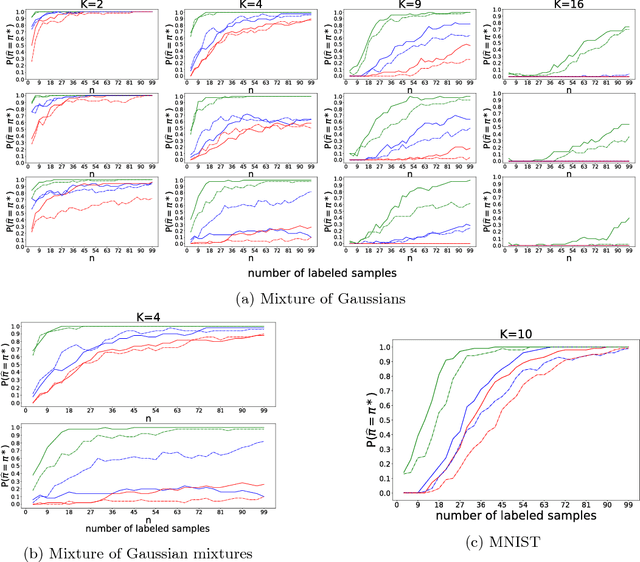
We study the sample complexity of semi-supervised learning (SSL) and introduce new assumptions based on the mismatch between a mixture model learned from unlabeled data and the true mixture model induced by the (unknown) class conditional distributions. Under these assumptions, we establish an $\Omega(K\log K)$ labeled sample complexity bound without imposing parametric assumptions, where $K$ is the number of classes. Our results suggest that even in nonparametric settings it is possible to learn a near-optimal classifier using only a few labeled samples. Unlike previous theoretical work which focuses on binary classification, we consider general multiclass classification ($K>2$), which requires solving a difficult permutation learning problem. This permutation defines a classifier whose classification error is controlled by the Wasserstein distance between mixing measures, and we provide finite-sample results characterizing the behaviour of the excess risk of this classifier. Finally, we describe three algorithms for computing these estimators based on a connection to bipartite graph matching, and perform experiments to illustrate the superiority of the MLE over the majority vote estimator.