 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022



Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Distribution-aware Goal Prediction and Conformant Model-based Planning for Safe Autonomous Driving
Dec 16, 2022The feasibility of collecting a large amount of expert demonstrations has inspired growing research interests in learning-to-drive settings, where models learn by imitating the driving behaviour from experts. However, exclusively relying on imitation can limit agents' generalisability to novel scenarios that are outside the support of the training data. In this paper, we address this challenge by factorising the driving task, based on the intuition that modular architectures are more generalisable and more robust to changes in the environment compared to monolithic, end-to-end frameworks. Specifically, we draw inspiration from the trajectory forecasting community and reformulate the learning-to-drive task as obstacle-aware perception and grounding, distribution-aware goal prediction, and model-based planning. Firstly, we train the obstacle-aware perception module to extract salient representation of the visual context. Then, we learn a multi-modal goal distribution by performing conditional density-estimation using normalising flow. Finally, we ground candidate trajectory predictions road geometry, and plan the actions based on on vehicle dynamics. Under the CARLA simulator, we report state-of-the-art results on the CARNOVEL benchmark.
Coalescing Global and Local Information for Procedural Text Understanding
Aug 26, 2022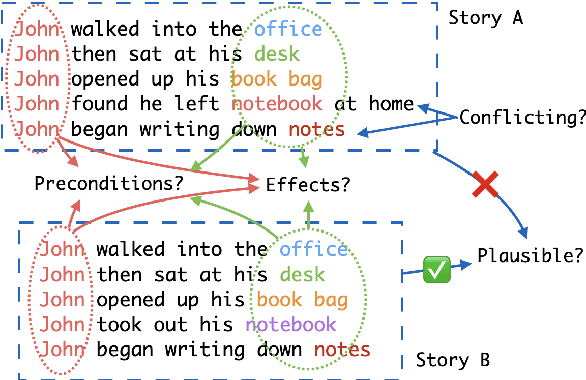
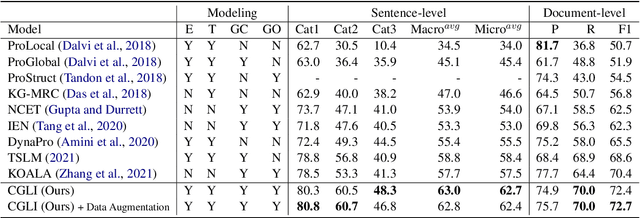
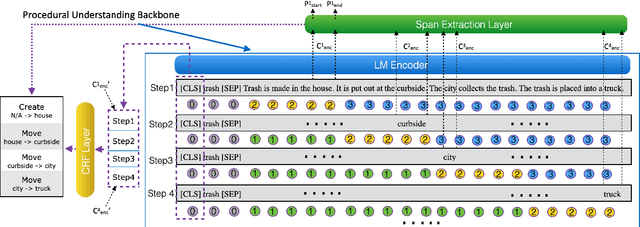
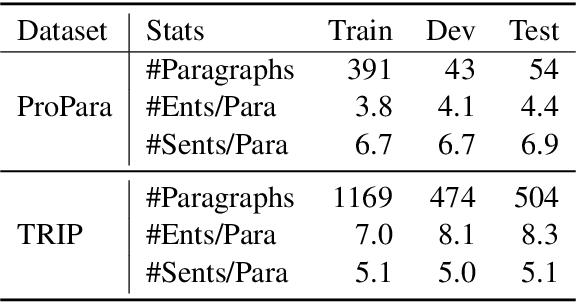
Procedural text understanding is a challenging language reasoning task that requires models to track entity states across the development of a narrative. A complete procedural understanding solution should combine three core aspects: local and global views of the inputs, and global view of outputs. Prior methods considered a subset of these aspects, resulting in either low precision or low recall. In this paper, we propose Coalescing Global and Local Information (CGLI), a new model that builds entity- and timestep-aware input representations (local input) considering the whole context (global input), and we jointly model the entity states with a structured prediction objective (global output). Thus, CGLI simultaneously optimizes for both precision and recall. We extend CGLI with additional output layers and integrate it into a story reasoning framework. Extensive experiments on a popular procedural text understanding dataset show that our model achieves state-of-the-art results; experiments on a story reasoning benchmark show the positive impact of our model on downstream reasoning.
Understanding Performance of Long-Document Ranking Models through Comprehensive Evaluation and Leaderboarding
Jul 04, 2022
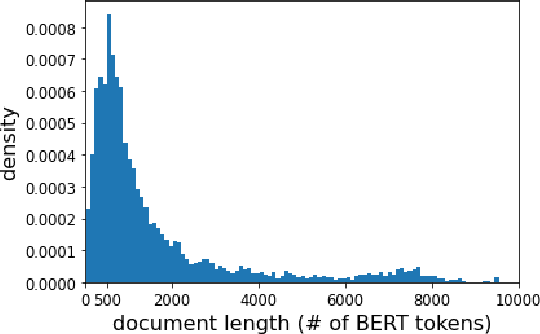
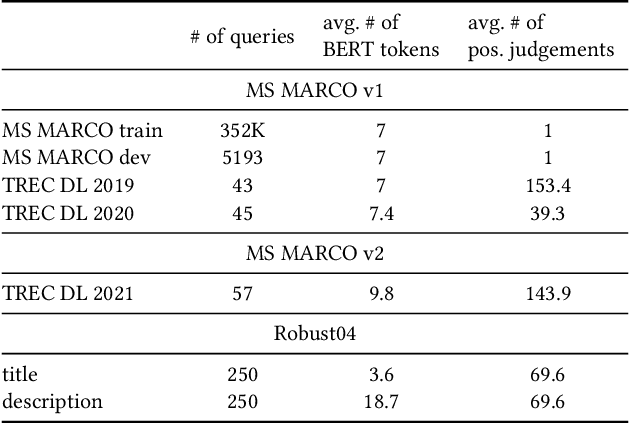
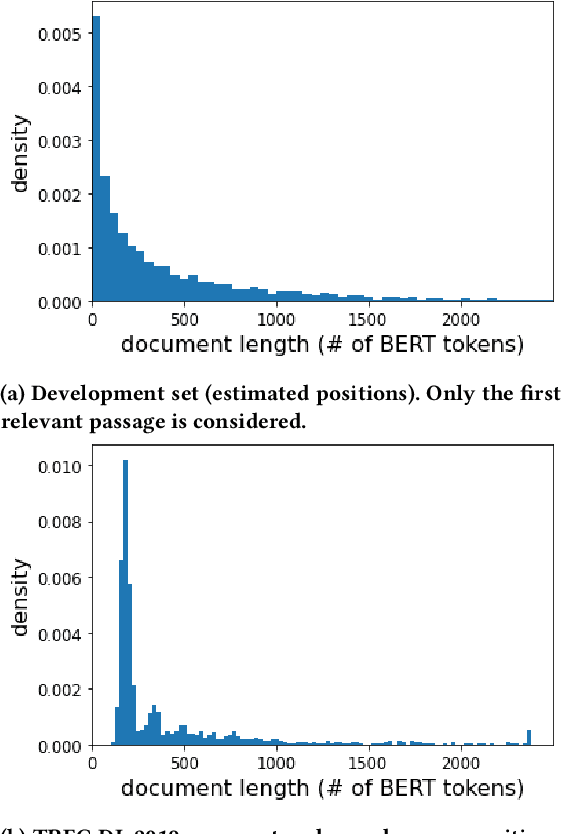
We carry out a comprehensive evaluation of 13 recent models for ranking of long documents using two popular collections (MS MARCO documents and Robust04). Our model zoo includes two specialized Transformer models (such as Longformer) that can process long documents without the need to split them. Along the way, we document several difficulties regarding training and comparing such models. Somewhat surprisingly, we find the simple FirstP baseline (truncating documents to satisfy the input-sequence constraint of a typical Transformer model) to be quite effective. We analyze the distribution of relevant passages (inside documents) to explain this phenomenon. We further argue that, despite their widespread use, Robust04 and MS MARCO documents are not particularly useful for benchmarking of long-document models.
Table Retrieval May Not Necessitate Table-specific Model Design
May 19, 2022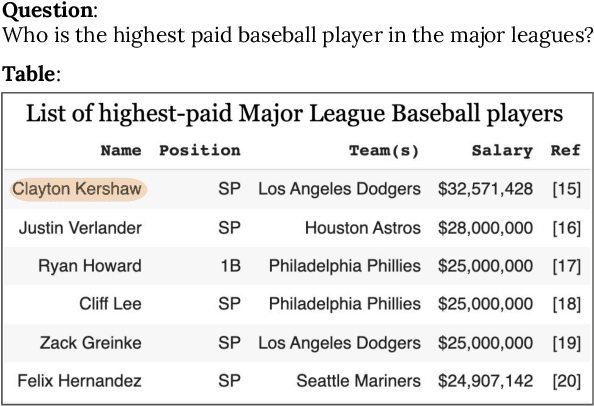

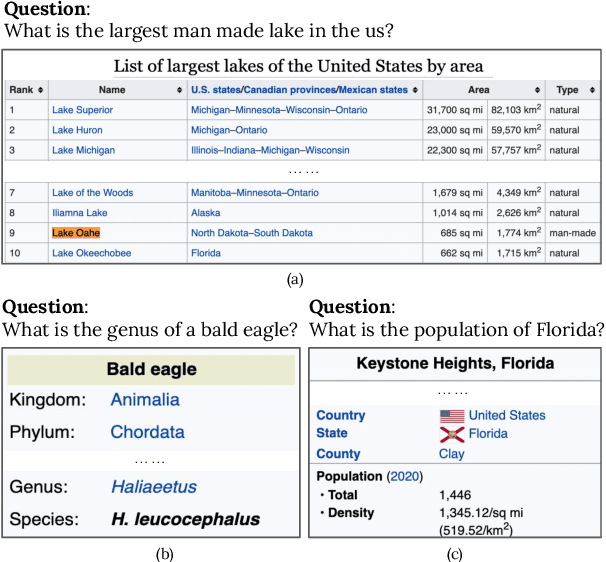

Tables are an important form of structured data for both human and machine readers alike, providing answers to questions that cannot, or cannot easily, be found in texts. Recent work has designed special models and training paradigms for table-related tasks such as table-based question answering and table retrieval. Though effective, they add complexity in both modeling and data acquisition compared to generic text solutions and obscure which elements are truly beneficial. In this work, we focus on the task of table retrieval, and ask: "is table-specific model design necessary for table retrieval, or can a simpler text-based model be effectively used to achieve a similar result?" First, we perform an analysis on a table-based portion of the Natural Questions dataset (NQ-table), and find that structure plays a negligible role in more than 70% of the cases. Based on this, we experiment with a general Dense Passage Retriever (DPR) based on text and a specialized Dense Table Retriever (DTR) that uses table-specific model designs. We find that DPR performs well without any table-specific design and training, and even achieves superior results compared to DTR when fine-tuned on properly linearized tables. We then experiment with three modules to explicitly encode table structures, namely auxiliary row/column embeddings, hard attention masks, and soft relation-based attention biases. However, none of these yielded significant improvements, suggesting that table-specific model design may not be necessary for table retrieval.
Learn-to-Race Challenge 2022: Benchmarking Safe Learning and Cross-domain Generalisation in Autonomous Racing
May 10, 2022
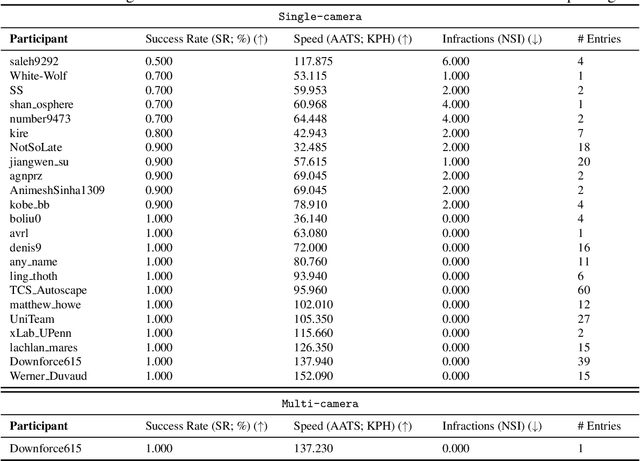

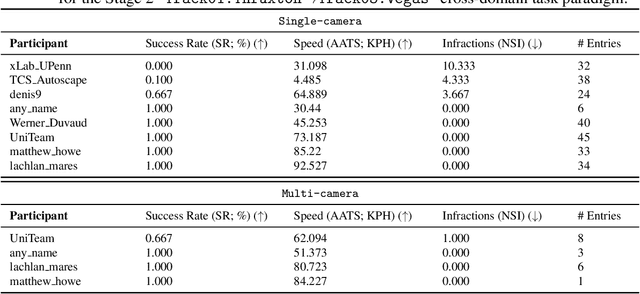
We present the results of our autonomous racing virtual challenge, based on the newly-released Learn-to-Race (L2R) simulation framework, which seeks to encourage interdisciplinary research in autonomous driving and to help advance the state of the art on a realistic benchmark. Analogous to racing being used to test cutting-edge vehicles, we envision autonomous racing to serve as a particularly challenging proving ground for autonomous agents as: (i) they need to make sub-second, safety-critical decisions in a complex, fast-changing environment; and (ii) both perception and control must be robust to distribution shifts, novel road features, and unseen obstacles. Thus, the main goal of the challenge is to evaluate the joint safety, performance, and generalisation capabilities of reinforcement learning agents on multi-modal perception, through a two-stage process. In the first stage of the challenge, we evaluate an autonomous agent's ability to drive as fast as possible, while adhering to safety constraints. In the second stage, we additionally require the agent to adapt to an unseen racetrack through safe exploration. In this paper, we describe the new L2R Task 2.0 benchmark, with refined metrics and baseline approaches. We also provide an overview of deployment, evaluation, and rankings for the inaugural instance of the L2R Autonomous Racing Virtual Challenge (supported by Carnegie Mellon University, Arrival Ltd., AICrowd, Amazon Web Services, and Honda Research), which officially used the new L2R Task 2.0 benchmark and received over 20,100 views, 437 active participants, 46 teams, and 733 model submissions -- from 88+ unique institutions, in 58+ different countries. Finally, we release leaderboard results from the challenge and provide description of the two top-ranking approaches in cross-domain model transfer, across multiple sensor configurations and simulated races.
Open Domain Question Answering over Virtual Documents: A Unified Approach for Data and Text
Oct 16, 2021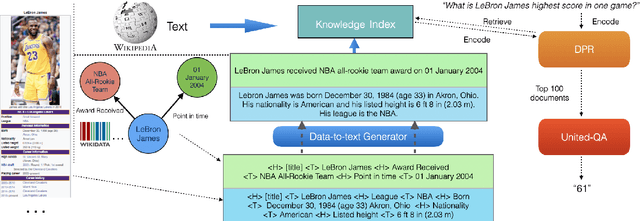
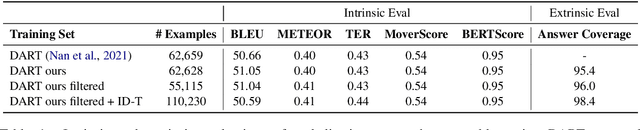

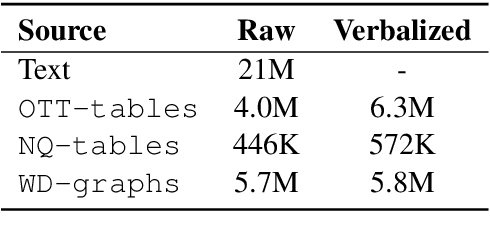
Due to its potential for a universal interface over both data and text, data-to-text generation is becoming increasingly popular recently. However, few previous work has focused on its application to downstream tasks, e.g. using the converted data for grounding or reasoning. In this work, we aim to bridge this gap and use the data-to-text method as a means for encoding structured knowledge for knowledge-intensive applications, i.e. open-domain question answering (QA). Specifically, we propose a verbalizer-retriever-reader framework for open-domain QA over data and text where verbalized tables from Wikipedia and triples from Wikidata are used as augmented knowledge sources. We show that our Unified Data and Text QA, UDT-QA, can effectively benefit from the expanded knowledge index, leading to large gains over text-only baselines. Notably, our approach sets the single-model state-of-the-art on Natural Questions. Furthermore, our analyses indicate that verbalized knowledge is preferred for answer reasoning for both adapted and hot-swap settings.
Safety-aware Policy Optimisation for Autonomous Racing
Oct 14, 2021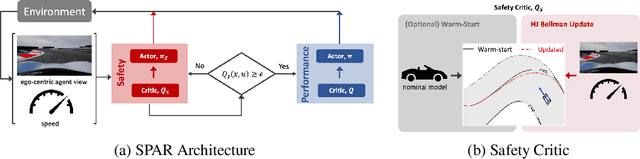
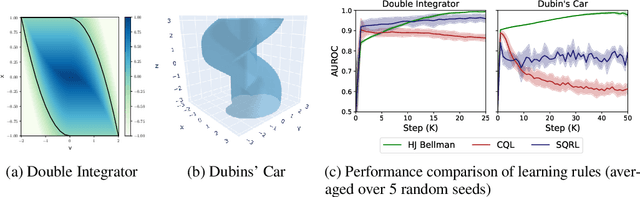
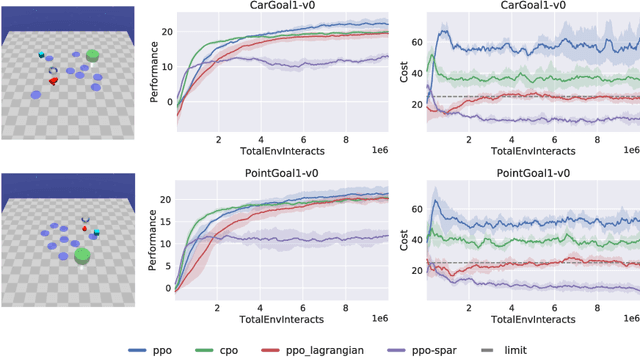

To be viable for safety-critical applications, such as autonomous driving and assistive robotics, autonomous agents should adhere to safety constraints throughout the interactions with their environments. Instead of learning about safety by collecting samples, including unsafe ones, methods such as Hamilton-Jacobi (HJ) reachability compute safe sets with theoretical guarantees using models of the system dynamics. However, HJ reachability is not scalable to high-dimensional systems, and the guarantees hinge on the quality of the model. In this work, we inject HJ reachability theory into the constrained Markov decision process (CMDP) framework, as a control-theoretical approach for safety analysis via model-free updates on state-action pairs. Furthermore, we demonstrate that the HJ safety value can be learned directly on vision context, the highest-dimensional problem studied via the method to-date. We evaluate our method on several benchmark tasks, including Safety Gym and Learn-to-Race (L2R), a recently-released high-fidelity autonomous racing environment. Our approach has significantly fewer constraint violations in comparison to other constrained RL baselines, and achieve the new state-of-the-art results on the L2R benchmark task.
Exploring Strategies for Generalizable Commonsense Reasoning with Pre-trained Models
Sep 07, 2021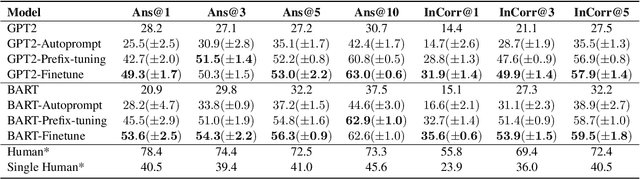
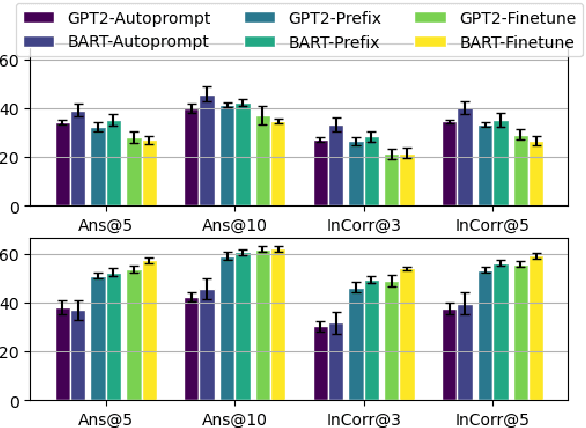
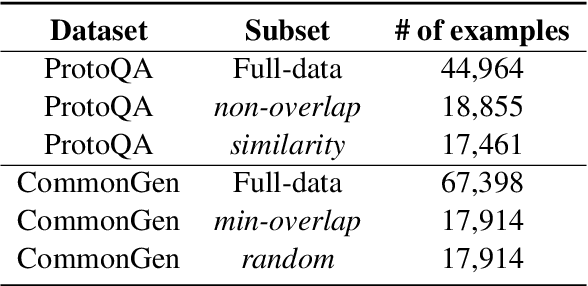
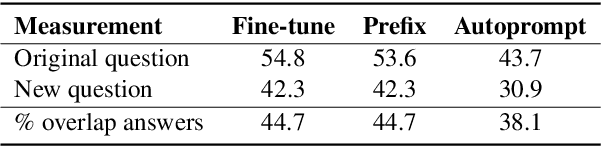
Commonsense reasoning benchmarks have been largely solved by fine-tuning language models. The downside is that fine-tuning may cause models to overfit to task-specific data and thereby forget their knowledge gained during pre-training. Recent works only propose lightweight model updates as models may already possess useful knowledge from past experience, but a challenge remains in understanding what parts and to what extent models should be refined for a given task. In this paper, we investigate what models learn from commonsense reasoning datasets. We measure the impact of three different adaptation methods on the generalization and accuracy of models. Our experiments with two models show that fine-tuning performs best, by learning both the content and the structure of the task, but suffers from overfitting and limited generalization to novel answers. We observe that alternative adaptation methods like prefix-tuning have comparable accuracy, but generalize better to unseen answers and are more robust to adversarial splits.
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
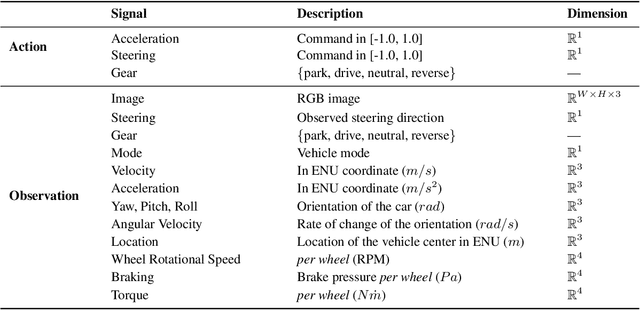
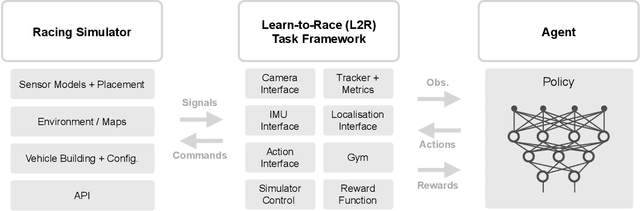

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race