 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
May 29, 2023



While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper, we leverage a mapping between reward functions and optimal policies to show that this constrained reward maximization problem can be optimized exactly with a single stage of policy training, essentially solving a classification problem on the human preference data. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant and computationally lightweight, eliminating the need for fitting a reward model, sampling from the LM during fine-tuning, or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds RLHF's ability to control sentiment of generations and improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Meta-Learning Online Adaptation of Language Models
May 24, 2023Large language models encode surprisingly broad knowledge about the world into their parameters. However, the knowledge in static language models can fall out of date, limiting the model's effective "shelf life." While online fine-tuning can reduce this degradation, we find that fine-tuning on a stream of documents using standard optimizers such as Adam leads to a disappointingly low level of information uptake. We hypothesize that online fine-tuning does not sufficiently 'attend' to important information. That is, the gradient signal from important tokens representing factual information is drowned out by the gradient from inherently noisy tokens, suggesting a dynamic, context-aware learning rate may be beneficial. To test this hypothesis, we meta-train a small, autoregressive model to reweight the language modeling loss for each token during online fine-tuning, with the objective of maximizing the out-of-date base language model's ability to answer questions about a document after a single weighted gradient step. We call this approach Context-aware Meta-learned Loss Scaling (CaMeLS). Across three different distributions of documents, our experiments find that fine-tuning on streams of thousands of documents with CaMeLS substantially improves knowledge retention compared to standard online fine-tuning. Finally, we find that the meta-learned weights are general, and that a single reweighting model can be used to enhance the online adaptation of many LMs.
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
May 24, 2023



A trustworthy real-world prediction system should be well-calibrated; that is, its confidence in an answer is indicative of the likelihood that the answer is correct, enabling deferral to a more expensive expert in cases of low-confidence predictions. While recent studies have shown that unsupervised pre-training produces large language models (LMs) that are remarkably well-calibrated, the most widely-used LMs in practice are fine-tuned with reinforcement learning with human feedback (RLHF-LMs) after the initial unsupervised pre-training stage, and results are mixed as to whether these models preserve the well-calibratedness of their ancestors. In this paper, we conduct a broad evaluation of computationally feasible methods for extracting confidence scores from LLMs fine-tuned with RLHF. We find that with the right prompting strategy, RLHF-LMs verbalize probabilities that are much better calibrated than the model's conditional probabilities, enabling fairly well-calibrated predictions. Through a combination of prompting strategy and temperature scaling, we find that we can reduce the expected calibration error of RLHF-LMs by over 50%.
RECKONING: Reasoning through Dynamic Knowledge Encoding
May 23, 2023



Recent studies on transformer-based language models show that they can answer questions by reasoning over knowledge provided as part of the context (i.e., in-context reasoning). However, since the available knowledge is often not filtered for a particular question, in-context reasoning can be sensitive to distractor facts, additional content that is irrelevant to a question but that may be relevant for a different question (i.e., not necessarily random noise). In these situations, the model fails to distinguish the knowledge that is necessary to answer the question, leading to spurious reasoning and degraded performance. This reasoning failure contrasts with the model's apparent ability to distinguish its contextual knowledge from all the knowledge it has memorized during pre-training. Following this observation, we propose teaching the model to reason more robustly by folding the provided contextual knowledge into the model's parameters before presenting it with a question. Our method, RECKONING, is a bi-level learning algorithm that teaches language models to reason by updating their parametric knowledge through back-propagation, allowing them to then answer questions using the updated parameters. During training, the inner loop rapidly adapts a copy of the model weights to encode contextual knowledge into its parameters. In the outer loop, the model learns to use the updated weights to reproduce and answer reasoning questions about the memorized knowledge. Our experiments on two multi-hop reasoning datasets show that RECKONING's performance improves over the in-context reasoning baseline (by up to 4.5%). We also find that compared to in-context reasoning, RECKONING generalizes better to longer reasoning chains unseen during training, is more robust to distractors in the context, and is more computationally efficient when multiple questions are asked about the same knowledge.
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
Jan 26, 2023The fluency and factual knowledge of large language models (LLMs) heightens the need for corresponding systems to detect whether a piece of text is machine-written. For example, students may use LLMs to complete written assignments, leaving instructors unable to accurately assess student learning. In this paper, we first demonstrate that text sampled from an LLM tends to occupy negative curvature regions of the model's log probability function. Leveraging this observation, we then define a new curvature-based criterion for judging if a passage is generated from a given LLM. This approach, which we call DetectGPT, does not require training a separate classifier, collecting a dataset of real or generated passages, or explicitly watermarking generated text. It uses only log probabilities computed by the model of interest and random perturbations of the passage from another generic pre-trained language model (e.g, T5). We find DetectGPT is more discriminative than existing zero-shot methods for model sample detection, notably improving detection of fake news articles generated by 20B parameter GPT-NeoX from 0.81 AUROC for the strongest zero-shot baseline to 0.95 AUROC for DetectGPT. See https://ericmitchell.ai/detectgpt for code, data, and other project information.
Self-Destructing Models: Increasing the Costs of Harmful Dual Uses in Foundation Models
Nov 27, 2022A growing ecosystem of large, open-source foundation models has reduced the labeled data and technical expertise necessary to apply machine learning to many new problems. Yet foundation models pose a clear dual-use risk, indiscriminately reducing the costs of building both harmful and beneficial machine learning systems. To mitigate this risk, we propose the task blocking paradigm, in which foundation models are trained with an additional mechanism to impede adaptation to harmful tasks while retaining good performance on desired tasks. We call the resulting models self-destructing models, inspired by mechanisms that prevent adversaries from using tools for harmful purposes. We present an algorithm for training self-destructing models leveraging techniques from meta-learning and adversarial learning, showing that it can largely prevent a BERT-based model from learning to perform gender identification without harming the model's ability to perform profession classification. We conclude with a discussion of future directions.
Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference
Nov 21, 2022



While large pre-trained language models are powerful, their predictions often lack logical consistency across test inputs. For example, a state-of-the-art Macaw question-answering (QA) model answers 'Yes' to 'Is a sparrow a bird?' and 'Does a bird have feet?' but answers 'No' to 'Does a sparrow have feet?'. To address this failure mode, we propose a framework, Consistency Correction through Relation Detection, or ConCoRD, for boosting the consistency and accuracy of pre-trained NLP models using pre-trained natural language inference (NLI) models without fine-tuning or re-training. Given a batch of test inputs, ConCoRD samples several candidate outputs for each input and instantiates a factor graph that accounts for both the model's belief about the likelihood of each answer choice in isolation and the NLI model's beliefs about pair-wise answer choice compatibility. We show that a weighted MaxSAT solver can efficiently compute high-quality answer choices under this factor graph, improving over the raw model's predictions. Our experiments demonstrate that ConCoRD consistently boosts accuracy and consistency of off-the-shelf closed-book QA and VQA models using off-the-shelf NLI models, notably increasing accuracy of LXMERT on ConVQA by 5% absolute. See https://ericmitchell.ai/emnlp-2022-concord/ for code and data.
Memory-Based Model Editing at Scale
Jun 13, 2022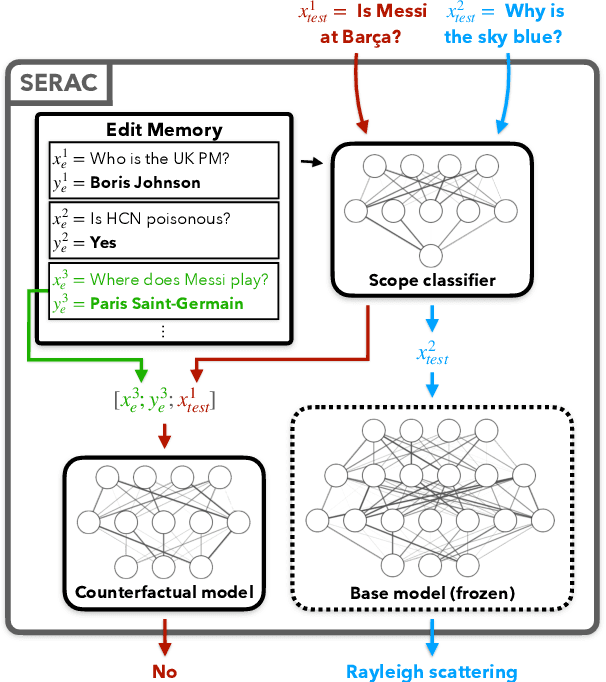



Even the largest neural networks make errors, and once-correct predictions can become invalid as the world changes. Model editors make local updates to the behavior of base (pre-trained) models to inject updated knowledge or correct undesirable behaviors. Existing model editors have shown promise, but also suffer from insufficient expressiveness: they struggle to accurately model an edit's intended scope (examples affected by the edit), leading to inaccurate predictions for test inputs loosely related to the edit, and they often fail altogether after many edits. As a higher-capacity alternative, we propose Semi-Parametric Editing with a Retrieval-Augmented Counterfactual Model (SERAC), which stores edits in an explicit memory and learns to reason over them to modulate the base model's predictions as needed. To enable more rigorous evaluation of model editors, we introduce three challenging language model editing problems based on question answering, fact-checking, and dialogue generation. We find that only SERAC achieves high performance on all three problems, consistently outperforming existing approaches to model editing by a significant margin. Code, data, and additional project information will be made available at https://sites.google.com/view/serac-editing.
Fast Model Editing at Scale
Oct 21, 2021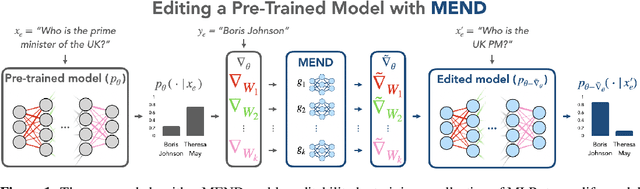

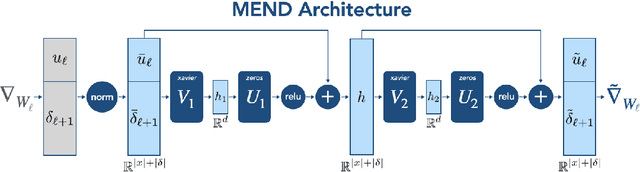

While large pre-trained models have enabled impressive results on a variety of downstream tasks, the largest existing models still make errors, and even accurate predictions may become outdated over time. Because detecting all such failures at training time is impossible, enabling both developers and end users of such models to correct inaccurate outputs while leaving the model otherwise intact is desirable. However, the distributed, black-box nature of the representations learned by large neural networks makes producing such targeted edits difficult. If presented with only a single problematic input and new desired output, fine-tuning approaches tend to overfit; other editing algorithms are either computationally infeasible or simply ineffective when applied to very large models. To enable easy post-hoc editing at scale, we propose Model Editor Networks with Gradient Decomposition (MEND), a collection of small auxiliary editing networks that use a single desired input-output pair to make fast, local edits to a pre-trained model. MEND learns to transform the gradient obtained by standard fine-tuning, using a low-rank decomposition of the gradient to make the parameterization of this transformation tractable. MEND can be trained on a single GPU in less than a day even for 10 billion+ parameter models; once trained MEND enables rapid application of new edits to the pre-trained model. Our experiments with T5, GPT, BERT, and BART models show that MEND is the only approach to model editing that produces effective edits for models with tens of millions to over 10 billion parameters. Implementation available at https://sites.google.com/view/mend-editing.