 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom tests to effect sizes: Quantifying uncertainty and statistical variability in multilingual and multitask NLP evaluation benchmarks
Sep 26, 2025In this paper, we introduce a set of resampling-based methods for quantifying uncertainty and statistical precision of evaluation metrics in multilingual and/or multitask NLP benchmarks. We show how experimental variation in performance scores arises from both model- and data-related sources, and that accounting for both of them is necessary to avoid substantially underestimating the overall variability over hypothetical replications. Using multilingual question answering, machine translation, and named entity recognition as example tasks, we also demonstrate how resampling methods are useful for computing sampling distributions for various quantities used in leaderboards such as the average/median, pairwise differences between models, and rankings.
Evaluating Morphological Compositional Generalization in Large Language Models
Oct 16, 2024Large language models (LLMs) have demonstrated significant progress in various natural language generation and understanding tasks. However, their linguistic generalization capabilities remain questionable, raising doubts about whether these models learn language similarly to humans. While humans exhibit compositional generalization and linguistic creativity in language use, the extent to which LLMs replicate these abilities, particularly in morphology, is under-explored. In this work, we systematically investigate the morphological generalization abilities of LLMs through the lens of compositionality. We define morphemes as compositional primitives and design a novel suite of generative and discriminative tasks to assess morphological productivity and systematicity. Focusing on agglutinative languages such as Turkish and Finnish, we evaluate several state-of-the-art instruction-finetuned multilingual models, including GPT-4 and Gemini. Our analysis shows that LLMs struggle with morphological compositional generalization particularly when applied to novel word roots, with performance declining sharply as morphological complexity increases. While models can identify individual morphological combinations better than chance, their performance lacks systematicity, leading to significant accuracy gaps compared to humans.
Generalization Measures for Zero-Shot Cross-Lingual Transfer
Apr 24, 2024



A model's capacity to generalize its knowledge to interpret unseen inputs with different characteristics is crucial to build robust and reliable machine learning systems. Language model evaluation tasks lack information metrics about model generalization and their applicability in a new setting is measured using task and language-specific downstream performance, which is often lacking in many languages and tasks. In this paper, we explore a set of efficient and reliable measures that could aid in computing more information related to the generalization capability of language models in cross-lingual zero-shot settings. In addition to traditional measures such as variance in parameters after training and distance from initialization, we also measure the effectiveness of sharpness in loss landscape in capturing the success in cross-lingual transfer and propose a novel and stable algorithm to reliably compute the sharpness of a model optimum that correlates to generalization.
Logographic Information Aids Learning Better Representations for Natural Language Inference
Nov 03, 2022



Statistical language models conventionally implement representation learning based on the contextual distribution of words or other formal units, whereas any information related to the logographic features of written text are often ignored, assuming they should be retrieved relying on the cooccurence statistics. On the other hand, as language models become larger and require more data to learn reliable representations, such assumptions may start to fall back, especially under conditions of data sparsity. Many languages, including Chinese and Vietnamese, use logographic writing systems where surface forms are represented as a visual organization of smaller graphemic units, which often contain many semantic cues. In this paper, we present a novel study which explores the benefits of providing language models with logographic information in learning better semantic representations. We test our hypothesis in the natural language inference (NLI) task by evaluating the benefit of computing multi-modal representations that combine contextual information with glyph information. Our evaluation results in six languages with different typology and writing systems suggest significant benefits of using multi-modal embeddings in languages with logograhic systems, especially for words with less occurence statistics.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Quantifying Synthesis and Fusion and their Impact on Machine Translation
May 06, 2022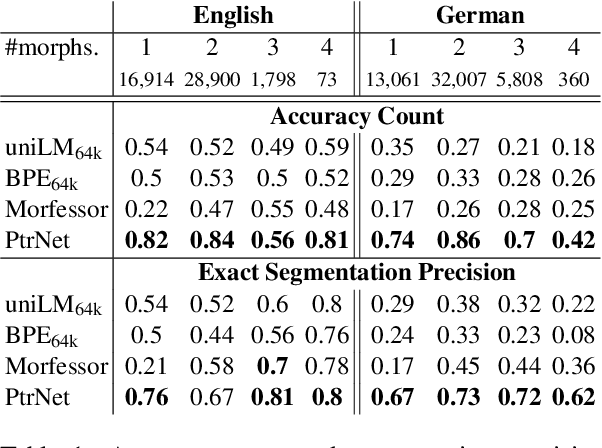
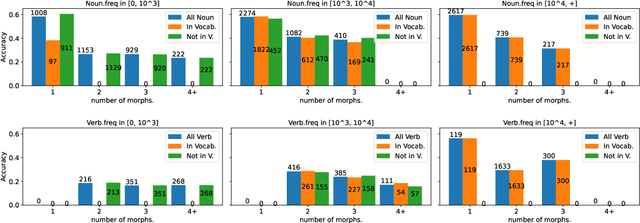

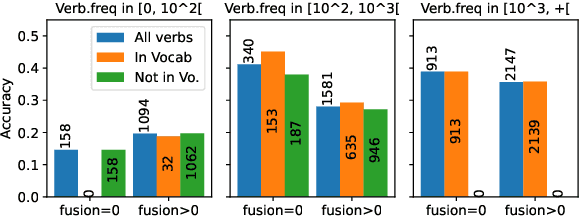
Theoretical work in morphological typology offers the possibility of measuring morphological diversity on a continuous scale. However, literature in Natural Language Processing (NLP) typically labels a whole language with a strict type of morphology, e.g. fusional or agglutinative. In this work, we propose to reduce the rigidity of such claims, by quantifying morphological typology at the word and segment level. We consider Payne (2017)'s approach to classify morphology using two indices: synthesis (e.g. analytic to polysynthetic) and fusion (agglutinative to fusional). For computing synthesis, we test unsupervised and supervised morphological segmentation methods for English, German and Turkish, whereas for fusion, we propose a semi-automatic method using Spanish as a case study. Then, we analyse the relationship between machine translation quality and the degree of synthesis and fusion at word (nouns and verbs for English-Turkish, and verbs in English-Spanish) and segment level (previous language pairs plus English-German in both directions). We complement the word-level analysis with human evaluation, and overall, we observe a consistent impact of both indexes on machine translation quality.
Evaluating Multiway Multilingual NMT in the Turkic Languages
Sep 13, 2021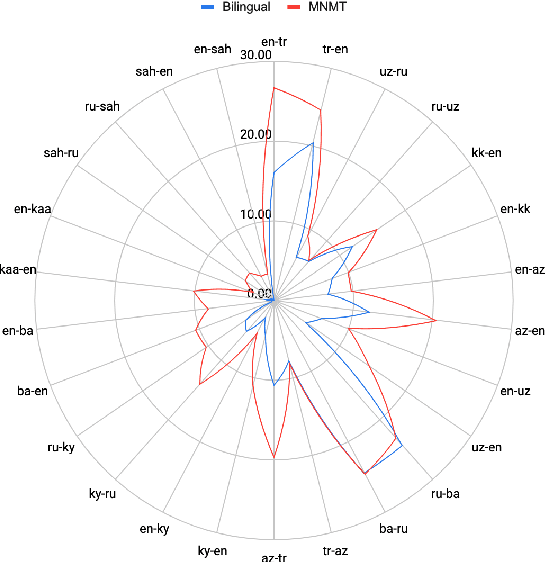
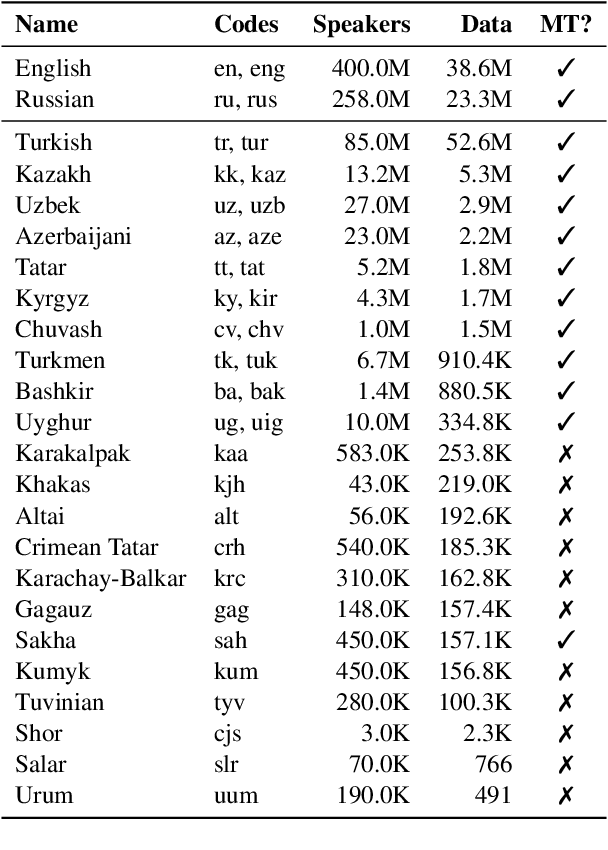

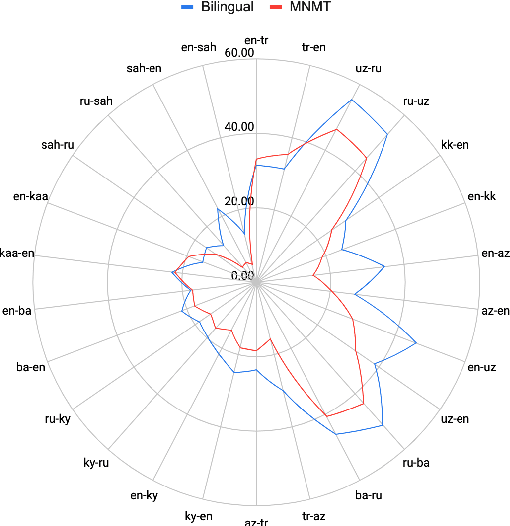
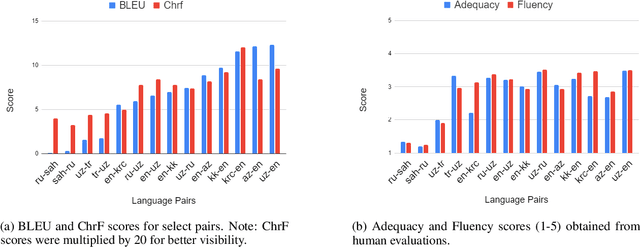
Despite the increasing number of large and comprehensive machine translation (MT) systems, evaluation of these methods in various languages has been restrained by the lack of high-quality parallel corpora as well as engagement with the people that speak these languages. In this study, we present an evaluation of state-of-the-art approaches to training and evaluating MT systems in 22 languages from the Turkic language family, most of which being extremely under-explored. First, we adopt the TIL Corpus with a few key improvements to the training and the evaluation sets. Then, we train 26 bilingual baselines as well as a multi-way neural MT (MNMT) model using the corpus and perform an extensive analysis using automatic metrics as well as human evaluations. We find that the MNMT model outperforms almost all bilingual baselines in the out-of-domain test sets and finetuning the model on a downstream task of a single pair also results in a huge performance boost in both low- and high-resource scenarios. Our attentive analysis of evaluation criteria for MT models in Turkic languages also points to the necessity for further research in this direction. We release the corpus splits, test sets as well as models to the public.
A Large-Scale Study of Machine Translation in the Turkic Languages
Sep 09, 2021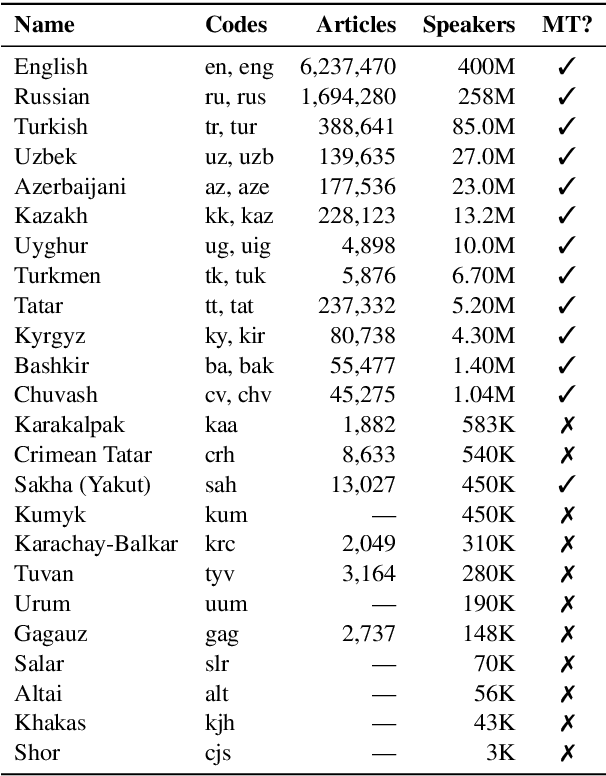
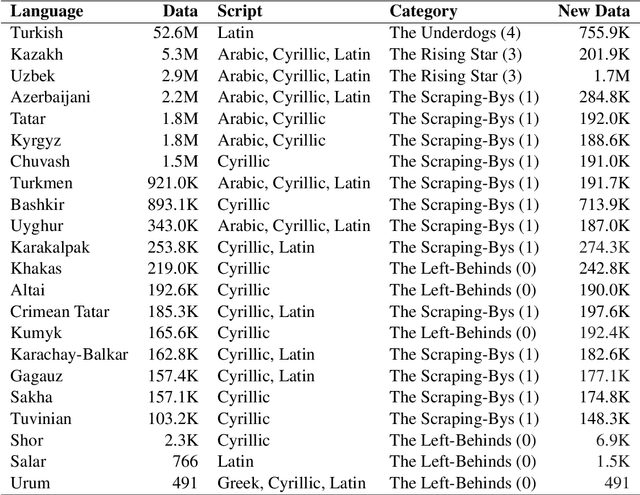

Recent advances in neural machine translation (NMT) have pushed the quality of machine translation systems to the point where they are becoming widely adopted to build competitive systems. However, there is still a large number of languages that are yet to reap the benefits of NMT. In this paper, we provide the first large-scale case study of the practical application of MT in the Turkic language family in order to realize the gains of NMT for Turkic languages under high-resource to extremely low-resource scenarios. In addition to presenting an extensive analysis that identifies the bottlenecks towards building competitive systems to ameliorate data scarcity, our study has several key contributions, including, i) a large parallel corpus covering 22 Turkic languages consisting of common public datasets in combination with new datasets of approximately 2 million parallel sentences, ii) bilingual baselines for 26 language pairs, iii) novel high-quality test sets in three different translation domains and iv) human evaluation scores. All models, scripts, and data will be released to the public.
Vision Matters When It Should: Sanity Checking Multimodal Machine Translation Models
Sep 08, 2021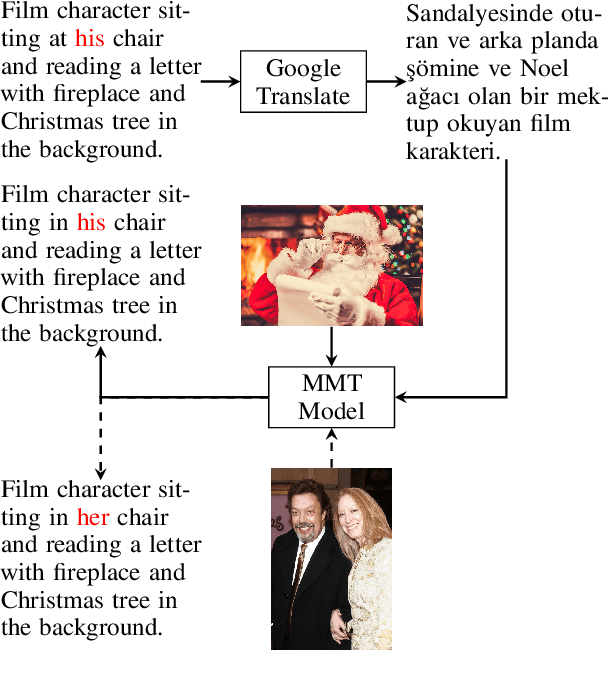
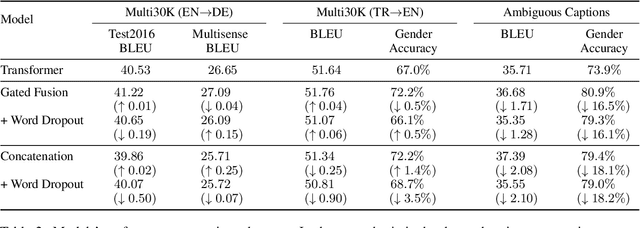
Multimodal machine translation (MMT) systems have been shown to outperform their text-only neural machine translation (NMT) counterparts when visual context is available. However, recent studies have also shown that the performance of MMT models is only marginally impacted when the associated image is replaced with an unrelated image or noise, which suggests that the visual context might not be exploited by the model at all. We hypothesize that this might be caused by the nature of the commonly used evaluation benchmark, also known as Multi30K, where the translations of image captions were prepared without actually showing the images to human translators. In this paper, we present a qualitative study that examines the role of datasets in stimulating the leverage of visual modality and we propose methods to highlight the importance of visual signals in the datasets which demonstrate improvements in reliance of models on the source images. Our findings suggest the research on effective MMT architectures is currently impaired by the lack of suitable datasets and careful consideration must be taken in creation of future MMT datasets, for which we also provide useful insights.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
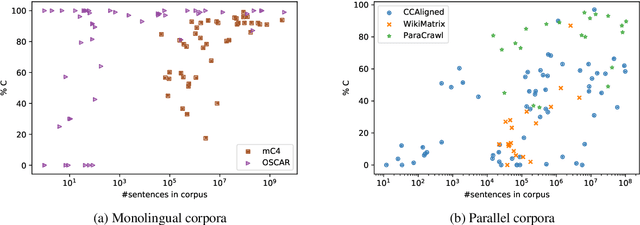

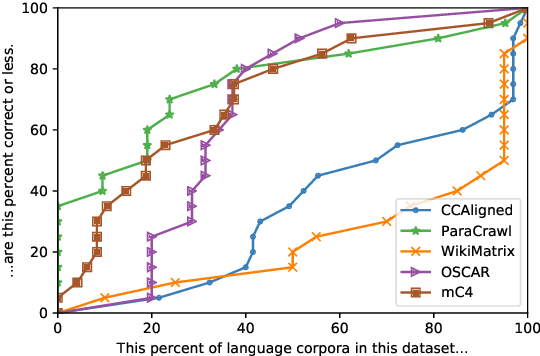
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.