 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability Distributions Computed by Hard-Attention Transformers
Oct 31, 2025

Most expressivity results for transformers treat them as language recognizers (which accept or reject strings), and not as they are used in practice, as language models (which generate strings autoregressively and probabilistically). Here, we characterize the probability distributions that transformer language models can express. We show that making transformer language recognizers autoregressive can sometimes increase their expressivity, and that making them probabilistic can break equivalences that hold in the non-probabilistic case. Our overall contribution is to tease apart what functions transformers are capable of expressing, in their most common use-case as language models.
Characterizing the Expressivity of Transformer Language Models
May 29, 2025



Transformer-based language models (LMs) have achieved widespread empirical success, but their theoretical expressive power remains only partially understood. Prior work often relies on idealized models with assumptions -- such as arbitrary numerical precision and hard attention -- that diverge from real-world transformers. In this work, we provide an exact characterization of fixed-precision transformers with strict future masking and soft attention, an idealization that more closely mirrors practical implementations. We show that these models are precisely as expressive as a specific fragment of linear temporal logic that includes only a single temporal operator: the past operator. We further relate this logic to established classes in formal language theory, automata theory, and algebra, yielding a rich and unified theoretical framework for understanding transformer expressivity. Finally, we present empirical results that align closely with our theory: transformers trained on languages within their theoretical capacity generalize perfectly over lengths, while they consistently fail to generalize on languages beyond it.
Unique Hard Attention: A Tale of Two Sides
Mar 18, 2025

Understanding the expressive power of transformers has recently attracted attention, as it offers insights into their abilities and limitations. Many studies analyze unique hard attention transformers, where attention selects a single position that maximizes the attention scores. When multiple positions achieve the maximum score, either the rightmost or the leftmost of those is chosen. In this paper, we highlight the importance of this seeming triviality. Recently, finite-precision transformers with both leftmost- and rightmost-hard attention were shown to be equivalent to Linear Temporal Logic (LTL). We show that this no longer holds with only leftmost-hard attention -- in that case, they correspond to a \emph{strictly weaker} fragment of LTL. Furthermore, we show that models with leftmost-hard attention are equivalent to \emph{soft} attention, suggesting they may better approximate real-world transformers than right-attention models. These findings refine the landscape of transformer expressivity and underscore the role of attention directionality.
What Do Language Models Learn in Context? The Structured Task Hypothesis
Jun 06, 2024



Large language models (LLMs) exhibit an intriguing ability to learn a novel task from in-context examples presented in a demonstration, termed in-context learning (ICL). Understandably, a swath of research has been dedicated to uncovering the theories underpinning ICL. One popular hypothesis explains ICL by task selection. LLMs identify the task based on the demonstration and generalize it to the prompt. Another popular hypothesis is that ICL is a form of meta-learning, i.e., the models learn a learning algorithm at pre-training time and apply it to the demonstration. Finally, a third hypothesis argues that LLMs use the demonstration to select a composition of tasks learned during pre-training to perform ICL. In this paper, we empirically explore these three hypotheses that explain LLMs' ability to learn in context with a suite of experiments derived from common text classification tasks. We invalidate the first two hypotheses with counterexamples and provide evidence in support of the last hypothesis. Our results suggest an LLM could learn a novel task in context via composing tasks learned during pre-training.
A Transformer with Stack Attention
May 07, 2024



Natural languages are believed to be (mildly) context-sensitive. Despite underpinning remarkably capable large language models, transformers are unable to model many context-free language tasks. In an attempt to address this limitation in the modeling power of transformer-based language models, we propose augmenting them with a differentiable, stack-based attention mechanism. Our stack-based attention mechanism can be incorporated into any transformer-based language model and adds a level of interpretability to the model. We show that the addition of our stack-based attention mechanism enables the transformer to model some, but not all, deterministic context-free languages.
Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of Language Models
Oct 23, 2023



Recent work has shown that language models (LMs) have strong multi-step (i.e., procedural) reasoning capabilities. However, it is unclear whether LMs perform these tasks by cheating with answers memorized from pretraining corpus, or, via a multi-step reasoning mechanism. In this paper, we try to answer this question by exploring a mechanistic interpretation of LMs for multi-step reasoning tasks. Concretely, we hypothesize that the LM implicitly embeds a reasoning tree resembling the correct reasoning process within it. We test this hypothesis by introducing a new probing approach (called MechanisticProbe) that recovers the reasoning tree from the model's attention patterns. We use our probe to analyze two LMs: GPT-2 on a synthetic task (k-th smallest element), and LLaMA on two simple language-based reasoning tasks (ProofWriter & AI2 Reasoning Challenge). We show that MechanisticProbe is able to detect the information of the reasoning tree from the model's attentions for most examples, suggesting that the LM indeed is going through a process of multi-step reasoning within its architecture in many cases.
Probing via Prompting
Jul 04, 2022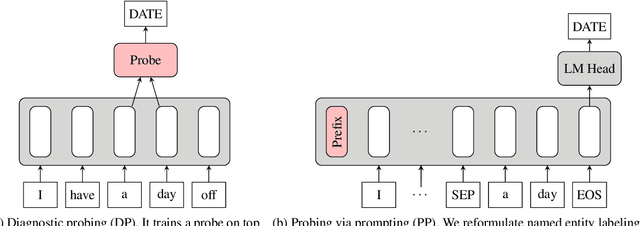

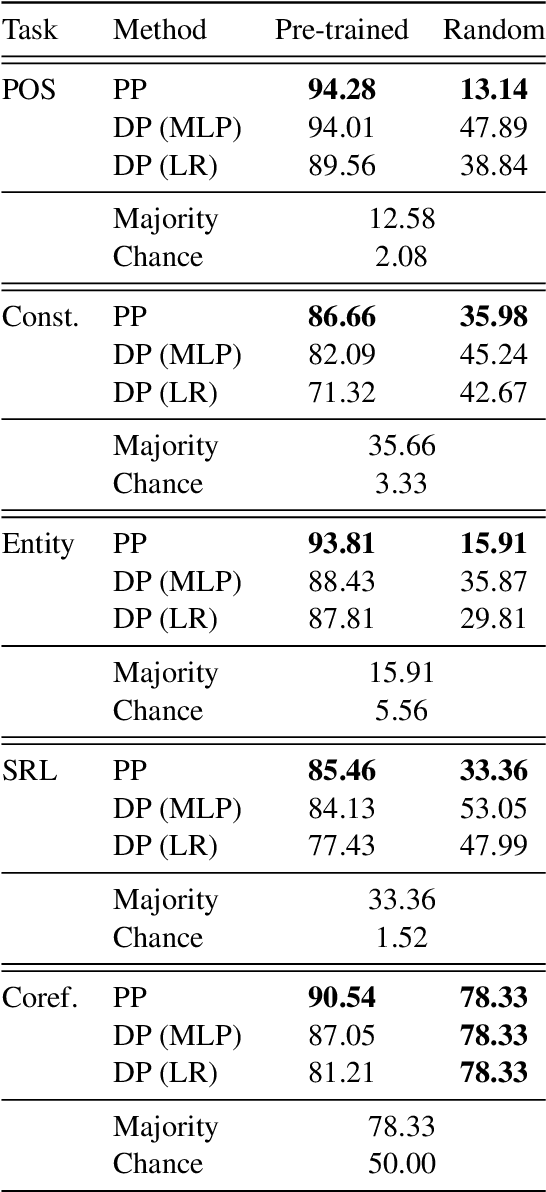
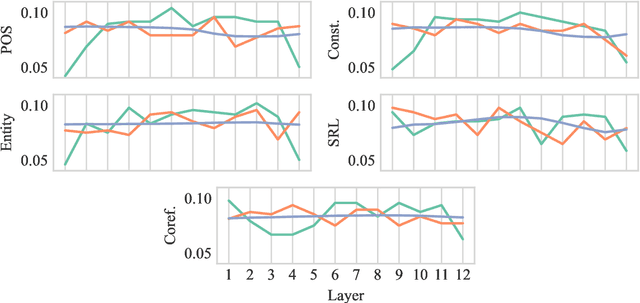
Probing is a popular method to discern what linguistic information is contained in the representations of pre-trained language models. However, the mechanism of selecting the probe model has recently been subject to intense debate, as it is not clear if the probes are merely extracting information or modeling the linguistic property themselves. To address this challenge, this paper introduces a novel model-free approach to probing, by formulating probing as a prompting task. We conduct experiments on five probing tasks and show that our approach is comparable or better at extracting information than diagnostic probes while learning much less on its own. We further combine the probing via prompting approach with attention head pruning to analyze where the model stores the linguistic information in its architecture. We then examine the usefulness of a specific linguistic property for pre-training by removing the heads that are essential to that property and evaluating the resulting model's performance on language modeling.
Vision Matters When It Should: Sanity Checking Multimodal Machine Translation Models
Sep 08, 2021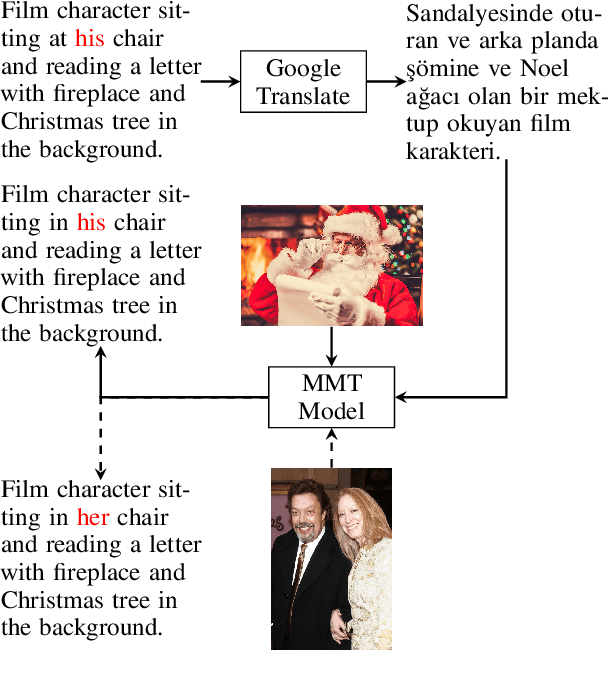
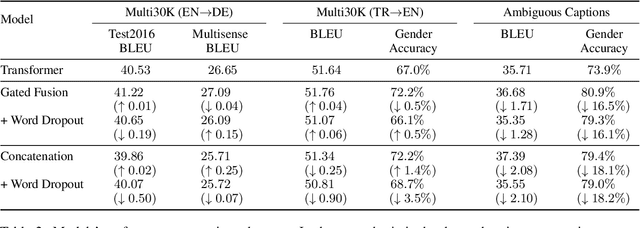
Multimodal machine translation (MMT) systems have been shown to outperform their text-only neural machine translation (NMT) counterparts when visual context is available. However, recent studies have also shown that the performance of MMT models is only marginally impacted when the associated image is replaced with an unrelated image or noise, which suggests that the visual context might not be exploited by the model at all. We hypothesize that this might be caused by the nature of the commonly used evaluation benchmark, also known as Multi30K, where the translations of image captions were prepared without actually showing the images to human translators. In this paper, we present a qualitative study that examines the role of datasets in stimulating the leverage of visual modality and we propose methods to highlight the importance of visual signals in the datasets which demonstrate improvements in reliance of models on the source images. Our findings suggest the research on effective MMT architectures is currently impaired by the lack of suitable datasets and careful consideration must be taken in creation of future MMT datasets, for which we also provide useful insights.
Differentiable Subset Pruning of Transformer Heads
Aug 22, 2021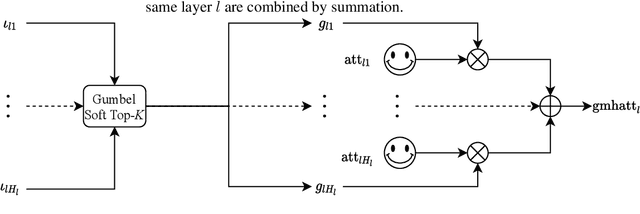
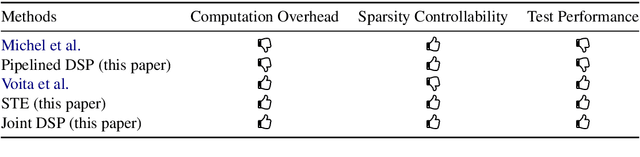
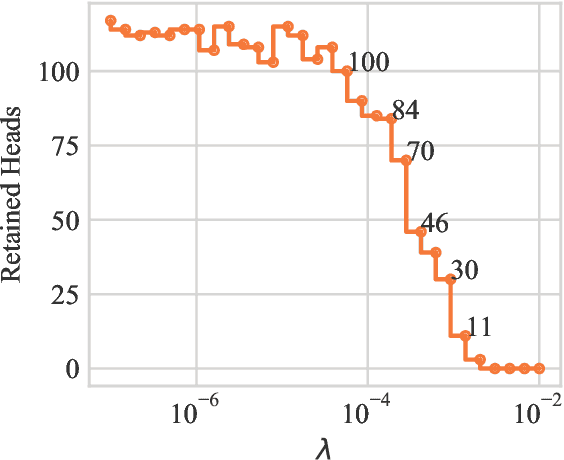
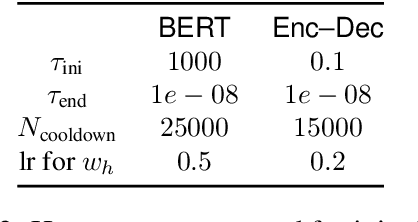
Multi-head attention, a collection of several attention mechanisms that independently attend to different parts of the input, is the key ingredient in the Transformer. Recent work has shown, however, that a large proportion of the heads in a Transformer's multi-head attention mechanism can be safely pruned away without significantly harming the performance of the model; such pruning leads to models that are noticeably smaller and faster in practice. Our work introduces a new head pruning technique that we term differentiable subset pruning. Intuitively, our method learns per-head importance variables and then enforces a user-specified hard constraint on the number of unpruned heads. The importance variables are learned via stochastic gradient descent. We conduct experiments on natural language inference and machine translation; we show that differentiable subset pruning performs comparably or better than previous works while offering precise control of the sparsity level.