 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Uncertainty Estimates in Deep Neural Networks using Noise Contrastive Priors
Oct 31, 2018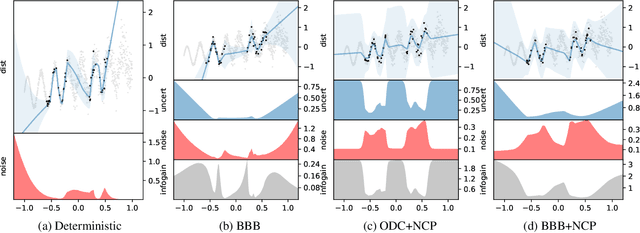
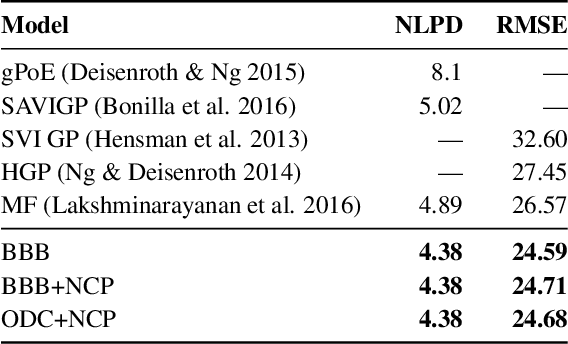

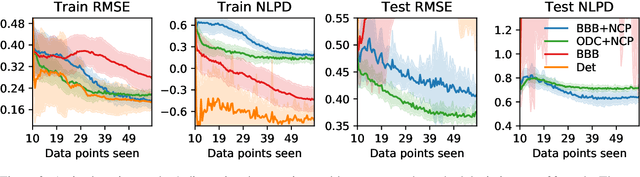
Obtaining reliable uncertainty estimates of neural network predictions is a long standing challenge. Bayesian neural networks have been proposed as a solution, but it remains open how to specify their prior. In particular, the common practice of a standard normal prior in weight space imposes only weak regularities, causing the function posterior to possibly generalize in unforeseen ways on inputs outside of the training distribution. We propose noise contrastive priors (NCPs) to obtain reliable uncertainty estimates. The key idea is to train the model to output high uncertainty for data points outside of the training distribution. NCPs do so using an input prior, which adds noise to the inputs of the current mini batch, and an output prior, which is a wide distribution given these inputs. NCPs are compatible with any model that can output uncertainty estimates, are easy to scale, and yield reliable uncertainty estimates throughout training. Empirically, we show that NCPs prevent overfitting outside of the training distribution and result in uncertainty estimates that are useful for active learning. We demonstrate the scalability of our method on the flight delays data set, where we significantly improve upon previously published results.
Image Transformer
Jun 15, 2018
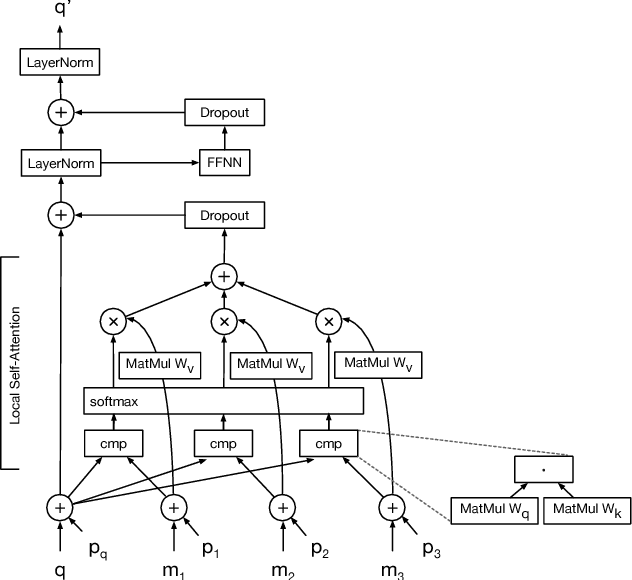

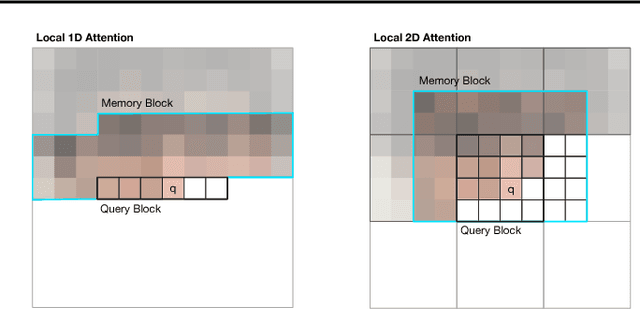
Image generation has been successfully cast as an autoregressive sequence generation or transformation problem. Recent work has shown that self-attention is an effective way of modeling textual sequences. In this work, we generalize a recently proposed model architecture based on self-attention, the Transformer, to a sequence modeling formulation of image generation with a tractable likelihood. By restricting the self-attention mechanism to attend to local neighborhoods we significantly increase the size of images the model can process in practice, despite maintaining significantly larger receptive fields per layer than typical convolutional neural networks. While conceptually simple, our generative models significantly outperform the current state of the art in image generation on ImageNet, improving the best published negative log-likelihood on ImageNet from 3.83 to 3.77. We also present results on image super-resolution with a large magnification ratio, applying an encoder-decoder configuration of our architecture. In a human evaluation study, we find that images generated by our super-resolution model fool human observers three times more often than the previous state of the art.
Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches
Apr 02, 2018
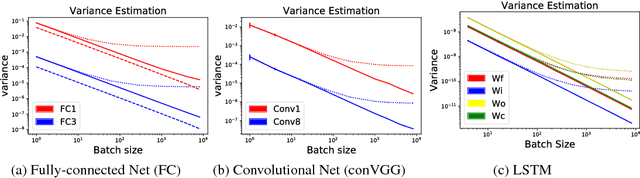
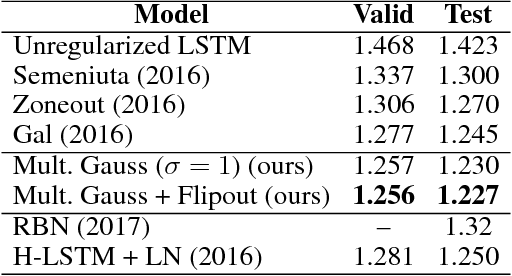
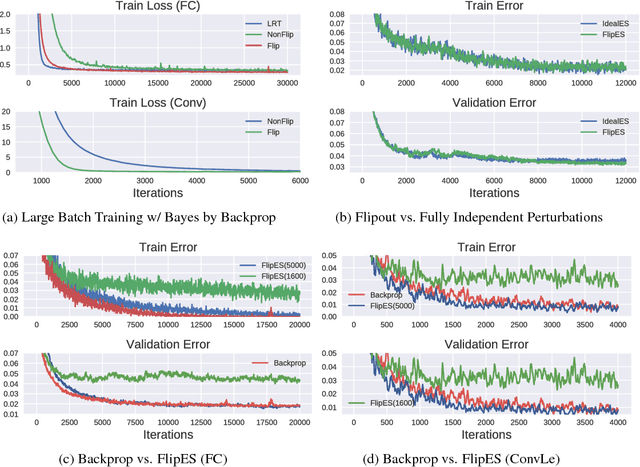
Stochastic neural net weights are used in a variety of contexts, including regularization, Bayesian neural nets, exploration in reinforcement learning, and evolution strategies. Unfortunately, due to the large number of weights, all the examples in a mini-batch typically share the same weight perturbation, thereby limiting the variance reduction effect of large mini-batches. We introduce flipout, an efficient method for decorrelating the gradients within a mini-batch by implicitly sampling pseudo-independent weight perturbations for each example. Empirically, flipout achieves the ideal linear variance reduction for fully connected networks, convolutional networks, and RNNs. We find significant speedups in training neural networks with multiplicative Gaussian perturbations. We show that flipout is effective at regularizing LSTMs, and outperforms previous methods. Flipout also enables us to vectorize evolution strategies: in our experiments, a single GPU with flipout can handle the same throughput as at least 40 CPU cores using existing methods, equivalent to a factor-of-4 cost reduction on Amazon Web Services.
Operator Variational Inference
Mar 15, 2018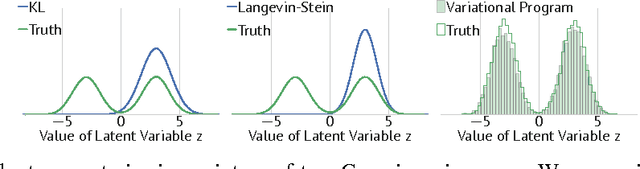

Variational inference is an umbrella term for algorithms which cast Bayesian inference as optimization. Classically, variational inference uses the Kullback-Leibler divergence to define the optimization. Though this divergence has been widely used, the resultant posterior approximation can suffer from undesirable statistical properties. To address this, we reexamine variational inference from its roots as an optimization problem. We use operators, or functions of functions, to design variational objectives. As one example, we design a variational objective with a Langevin-Stein operator. We develop a black box algorithm, operator variational inference (OPVI), for optimizing any operator objective. Importantly, operators enable us to make explicit the statistical and computational tradeoffs for variational inference. We can characterize different properties of variational objectives, such as objectives that admit data subsampling---allowing inference to scale to massive data---as well as objectives that admit variational programs---a rich class of posterior approximations that does not require a tractable density. We illustrate the benefits of OPVI on a mixture model and a generative model of images.
Expectation propagation as a way of life: A framework for Bayesian inference on partitioned data
Mar 10, 2018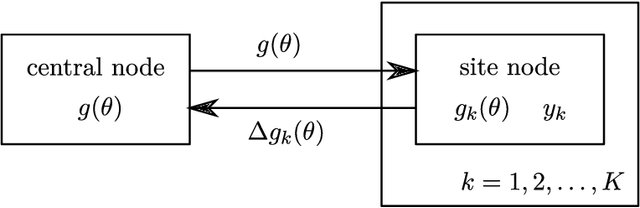
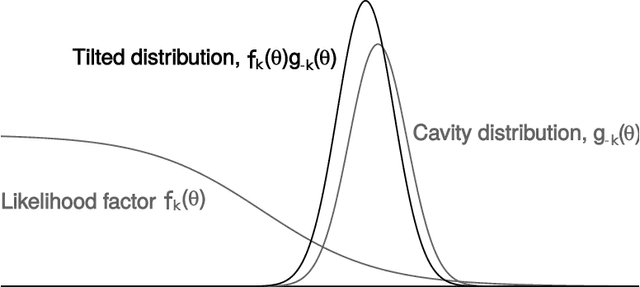
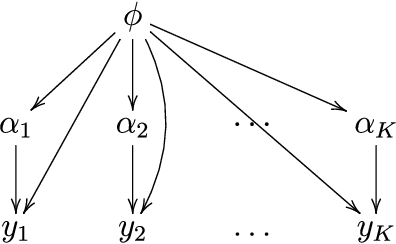
A common approach for Bayesian computation with big data is to partition the data into smaller pieces, perform local inference for each piece separately, and finally combine the results to obtain an approximation to the global posterior. Looking at this from the bottom up, one can perform separate analyses on individual sources of data and then combine these in a larger Bayesian model. In either case, the idea of distributed modeling and inference has both conceptual and computational appeal, but from the Bayesian perspective there is no general way of handling the prior distribution: if the prior is included in each separate inference, it will be multiply-counted when the inferences are combined; but if the prior is itself divided into pieces, it may not provide enough regularization for each separate computation, thus eliminating one of the key advantages of Bayesian methods. To resolve this dilemma, we propose expectation propagation (EP) as a general prototype for distributed Bayesian inference. The central idea is to factor the likelihood according to the data partitions, and to iteratively combine each factor with an approximate model of the prior and all other parts of the data, thus producing an overall approximation to the global posterior at convergence. In this paper, we give an introduction to EP and an overview of some recent developments of the method, with particular emphasis on its use in combining inferences from partitioned data. In addition to distributed modeling of large datasets, our unified treatment also includes hierarchical modeling of data with a naturally partitioned structure. The paper describes a general algorithmic framework, rather than a specific algorithm, and presents an example implementation for it.
TensorFlow Distributions
Nov 28, 2017


The TensorFlow Distributions library implements a vision of probability theory adapted to the modern deep-learning paradigm of end-to-end differentiable computation. Building on two basic abstractions, it offers flexible building blocks for probabilistic computation. Distributions provide fast, numerically stable methods for generating samples and computing statistics, e.g., log density. Bijectors provide composable volume-tracking transformations with automatic caching. Together these enable modular construction of high dimensional distributions and transformations not possible with previous libraries (e.g., pixelCNNs, autoregressive flows, and reversible residual networks). They are the workhorse behind deep probabilistic programming systems like Edward and empower fast black-box inference in probabilistic models built on deep-network components. TensorFlow Distributions has proven an important part of the TensorFlow toolkit within Google and in the broader deep learning community.
Variational Inference via $χ$-Upper Bound Minimization
Nov 12, 2017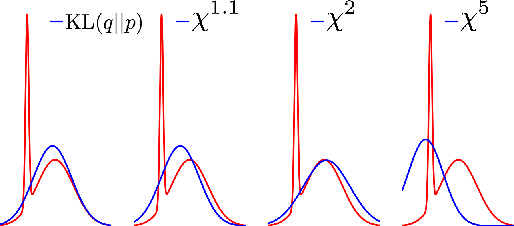
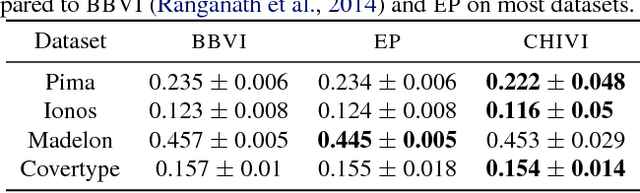
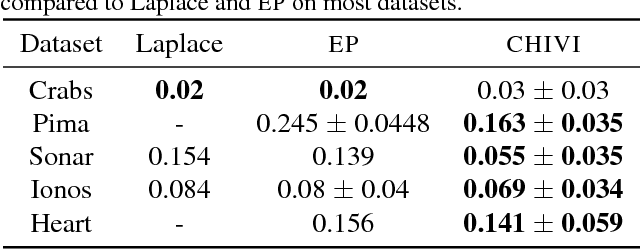

Variational inference (VI) is widely used as an efficient alternative to Markov chain Monte Carlo. It posits a family of approximating distributions $q$ and finds the closest member to the exact posterior $p$. Closeness is usually measured via a divergence $D(q || p)$ from $q$ to $p$. While successful, this approach also has problems. Notably, it typically leads to underestimation of the posterior variance. In this paper we propose CHIVI, a black-box variational inference algorithm that minimizes $D_{\chi}(p || q)$, the $\chi$-divergence from $p$ to $q$. CHIVI minimizes an upper bound of the model evidence, which we term the $\chi$ upper bound (CUBO). Minimizing the CUBO leads to improved posterior uncertainty, and it can also be used with the classical VI lower bound (ELBO) to provide a sandwich estimate of the model evidence. We study CHIVI on three models: probit regression, Gaussian process classification, and a Cox process model of basketball plays. When compared to expectation propagation and classical VI, CHIVI produces better error rates and more accurate estimates of posterior variance.
Hierarchical Implicit Models and Likelihood-Free Variational Inference
Nov 05, 2017
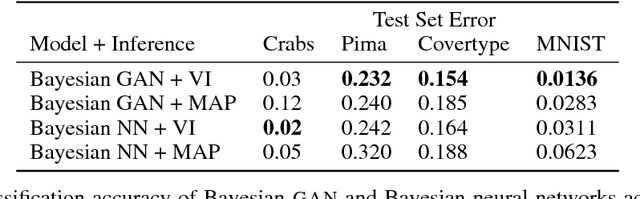
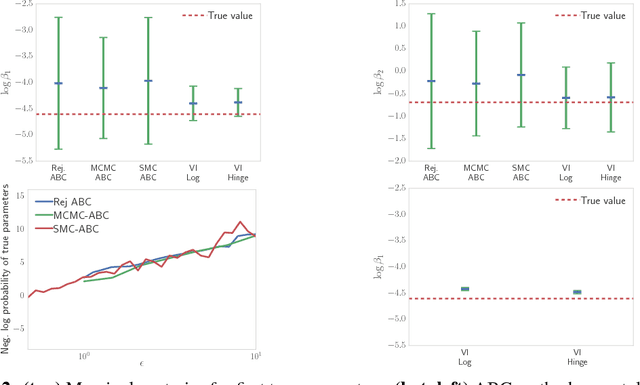
Implicit probabilistic models are a flexible class of models defined by a simulation process for data. They form the basis for theories which encompass our understanding of the physical world. Despite this fundamental nature, the use of implicit models remains limited due to challenges in specifying complex latent structure in them, and in performing inferences in such models with large data sets. In this paper, we first introduce hierarchical implicit models (HIMs). HIMs combine the idea of implicit densities with hierarchical Bayesian modeling, thereby defining models via simulators of data with rich hidden structure. Next, we develop likelihood-free variational inference (LFVI), a scalable variational inference algorithm for HIMs. Key to LFVI is specifying a variational family that is also implicit. This matches the model's flexibility and allows for accurate approximation of the posterior. We demonstrate diverse applications: a large-scale physical simulator for predator-prey populations in ecology; a Bayesian generative adversarial network for discrete data; and a deep implicit model for text generation.
Implicit Causal Models for Genome-wide Association Studies
Oct 30, 2017
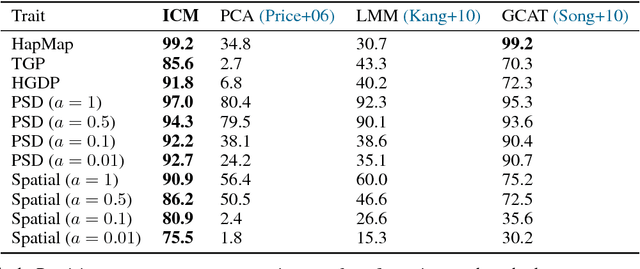
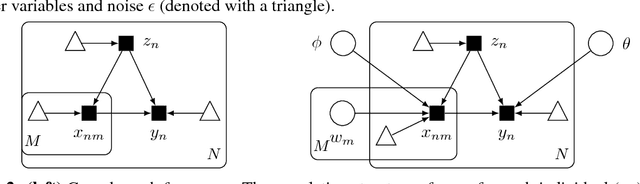
Progress in probabilistic generative models has accelerated, developing richer models with neural architectures, implicit densities, and with scalable algorithms for their Bayesian inference. However, there has been limited progress in models that capture causal relationships, for example, how individual genetic factors cause major human diseases. In this work, we focus on two challenges in particular: How do we build richer causal models, which can capture highly nonlinear relationships and interactions between multiple causes? How do we adjust for latent confounders, which are variables influencing both cause and effect and which prevent learning of causal relationships? To address these challenges, we synthesize ideas from causality and modern probabilistic modeling. For the first, we describe implicit causal models, a class of causal models that leverages neural architectures with an implicit density. For the second, we describe an implicit causal model that adjusts for confounders by sharing strength across examples. In experiments, we scale Bayesian inference on up to a billion genetic measurements. We achieve state of the art accuracy for identifying causal factors: we significantly outperform existing genetics methods by an absolute difference of 15-45.3%.
Deep Probabilistic Programming
Mar 07, 2017



We propose Edward, a Turing-complete probabilistic programming language. Edward defines two compositional representations---random variables and inference. By treating inference as a first class citizen, on a par with modeling, we show that probabilistic programming can be as flexible and computationally efficient as traditional deep learning. For flexibility, Edward makes it easy to fit the same model using a variety of composable inference methods, ranging from point estimation to variational inference to MCMC. In addition, Edward can reuse the modeling representation as part of inference, facilitating the design of rich variational models and generative adversarial networks. For efficiency, Edward is integrated into TensorFlow, providing significant speedups over existing probabilistic systems. For example, we show on a benchmark logistic regression task that Edward is at least 35x faster than Stan and 6x faster than PyMC3. Further, Edward incurs no runtime overhead: it is as fast as handwritten TensorFlow.