 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairwise Relations Discriminator for Unsupervised Raven's Progressive Matrices
Nov 02, 2020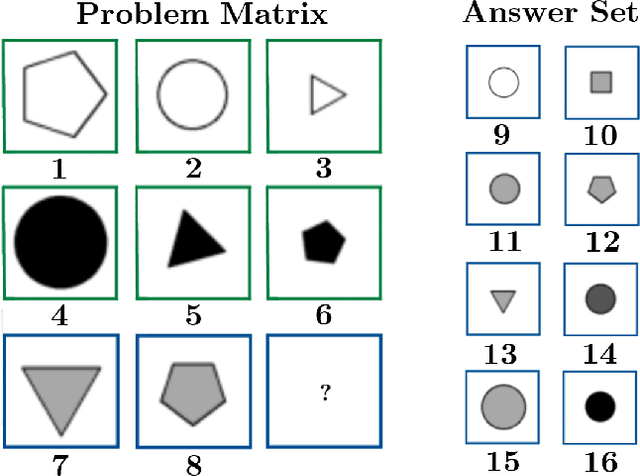

Abstract reasoning is a key indicator of intelligence. The ability to hypothesise, develop abstract concepts based on concrete observations and apply this hypothesis to justify future actions has been paramount in human development. An existing line of research in outfitting intelligent machines with abstract reasoning capabilities revolves around the Raven's Progressive Matrices (RPM), a multiple-choice visual puzzle where one must identify the missing component which completes the pattern. There have been many breakthroughs in supervised approaches to solving RPM in recent years. However, since this process requires external assistance, we cannot claim that machines have achieved reasoning ability comparable to humans. Namely, when the RPM rule that relations can only exist row/column-wise is properly introduced, humans can solve RPM problems without supervision or prior experience. In this paper, we introduce a pairwise relations discriminator (PRD), a technique to develop unsupervised models with sufficient reasoning abilities to tackle an RPM problem. PRD reframes the RPM problem into a relation comparison task, which we can solve without requiring the labelling of the RPM problem. We can identify the optimal candidate by adapting the application of PRD on the RPM problem. The previous state-of-the-art approach "mcpt" in this domain achieved 28.5% accuracy on the RAVEN dataset "drt", a standard dataset for computational work on RPM. Our approach, the PRD, establishes a new state-of-the-art benchmark with an accuracy of 50.74% on the same dataset, presenting a significant improvement and a step forward in equipping machines with abstract reasoning.
Learned Low Precision Graph Neural Networks
Sep 19, 2020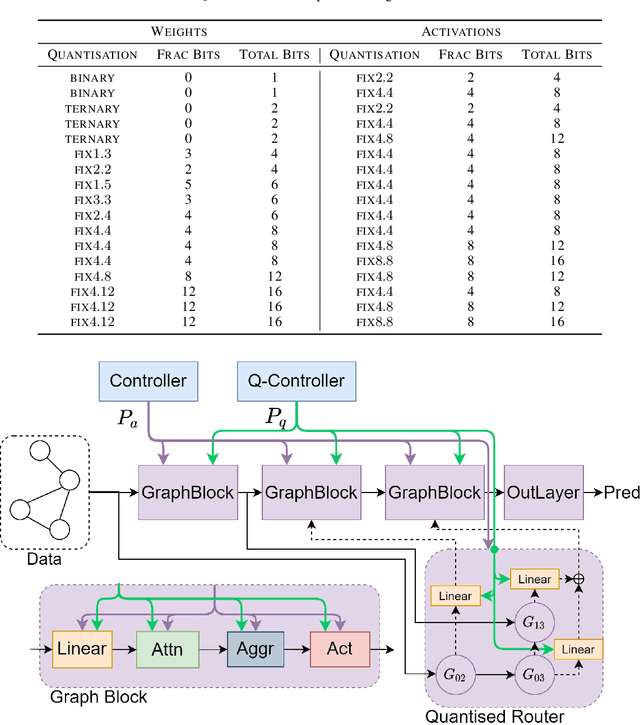


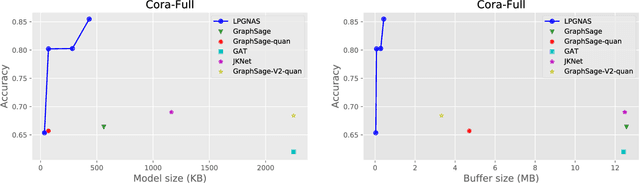
Deep Graph Neural Networks (GNNs) show promising performance on a range of graph tasks, yet at present are costly to run and lack many of the optimisations applied to DNNs. We show, for the first time, how to systematically quantise GNNs with minimal or no loss in performance using Network Architecture Search (NAS). We define the possible quantisation search space of GNNs. The proposed novel NAS mechanism, named Low Precision Graph NAS (LPGNAS), constrains both architecture and quantisation choices to be differentiable. LPGNAS learns the optimal architecture coupled with the best quantisation strategy for different components in the GNN automatically using back-propagation in a single search round. On eight different datasets, solving the task of classifying unseen nodes in a graph, LPGNAS generates quantised models with significant reductions in both model and buffer sizes but with similar accuracy to manually designed networks and other NAS results. In particular, on the Pubmed dataset, LPGNAS shows a better size-accuracy Pareto frontier compared to seven other manual and searched baselines, offering a 2.3 times reduction in model size but a 0.4% increase in accuracy when compared to the best NAS competitor. Finally, from our collected quantisation statistics on a wide range of datasets, we suggest a W4A8 (4-bit weights, 8-bit activations) quantisation strategy might be the bottleneck for naive GNN quantisations.
An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department
Aug 04, 2020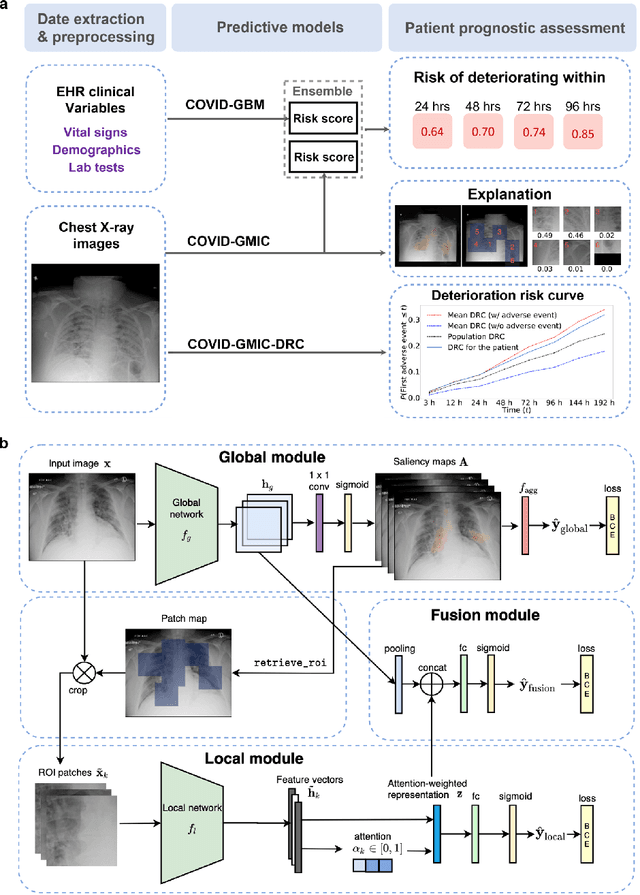
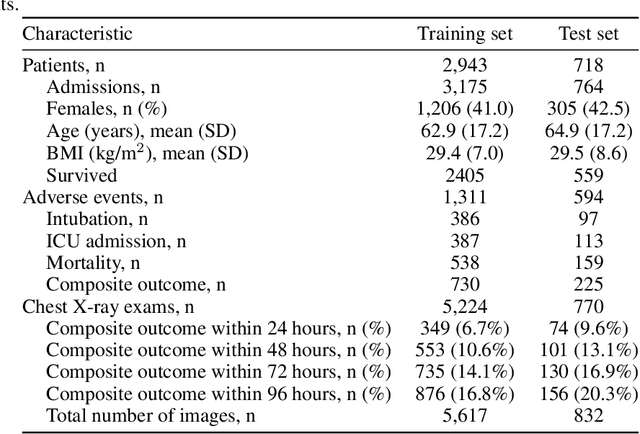
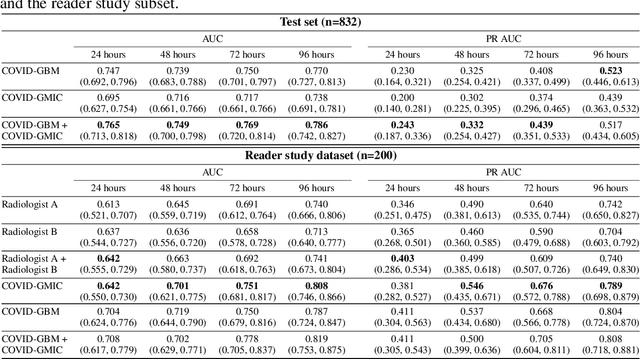
During the COVID-19 pandemic, rapid and accurate triage of patients at the emergency department is critical to inform decision-making. We propose a data-driven approach for automatic prediction of deterioration risk using a deep neural network that learns from chest X-ray images, and a gradient boosting model that learns from routine clinical variables. Our AI prognosis system, trained using data from 3,661 patients, achieves an AUC of 0.786 (95% CI: 0.742-0.827) when predicting deterioration within 96 hours. The deep neural network extracts informative areas of chest X-ray images to assist clinicians in interpreting the predictions, and performs comparably to two radiologists in a reader study. In order to verify performance in a real clinical setting, we silently deployed a preliminary version of the deep neural network at NYU Langone Health during the first wave of the pandemic, which produced accurate predictions in real-time. In summary, our findings demonstrate the potential of the proposed system for assisting front-line physicians in the triage of COVID-19 patients.
Top-Related Meta-Learning Method for Few-Shot Detection
Jul 27, 2020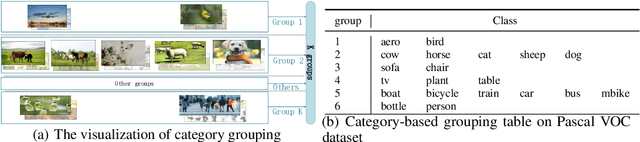
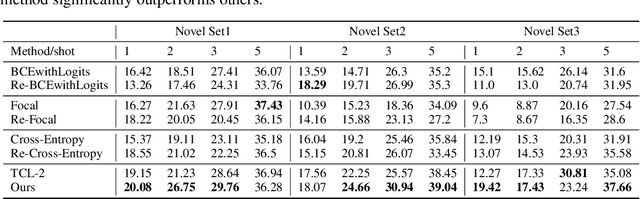
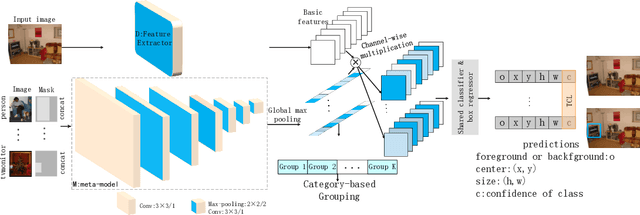

Many meta-learning methods are proposed for few-shot detection. However, previous most methods have two main problems, strong bias between all classes, and poor classification for few-shot classes. Previous works mainly depend on additional datasets and sub-module to alleviate these issues. However, they require more cost. In this paper, we find that the main challenge lies on imbalance between the examples, and poor shared distribution of class-based meta-features. Therefore, we propose a TCL for classification task and a category-based grouping mechanism. The TCL exploits the classification score of true-label class and the classification score of the most similar class to improve detection performance on few-shot classes. According to appearance and environment, the category-based grouping mechanism groups categories into different groupings to promote different similar semantic features more compact, alleviating the strong bias problem and further improving few-shot detection APs. The whole training consists of the base model and the fine-tuning phase. During training detection model, the category-related meta-features are regarded as the weights of the detection layer, exploiting the meta-features with a shared distribution between categories within a group to improve the detection performance. According to grouping mechanism, we group the meta-features vectors, so that the distribution difference between groups is obvious, and the one within each group is less. Experimental results on Pascal VOC dataset demonstrate that ours which combines the TCL with category-based grouping significantly outperforms previous state-of-the-art methods for 1, 2-shot detection, and obtains detection APs of almost 30% for 3-shot detection.
Abstract Diagrammatic Reasoning with Multiplex Graph Networks
Jun 19, 2020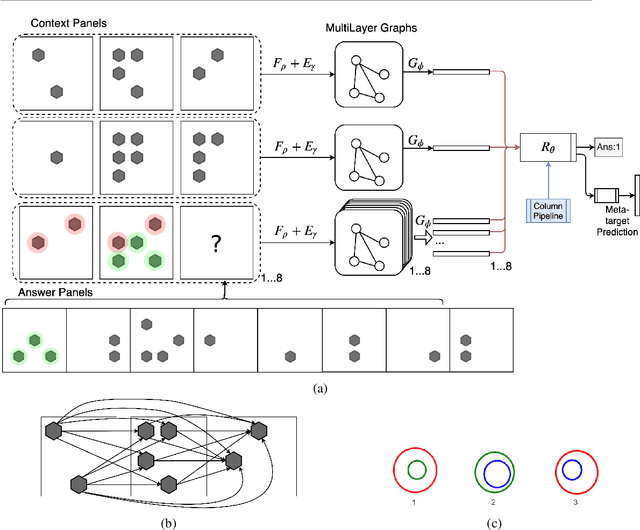
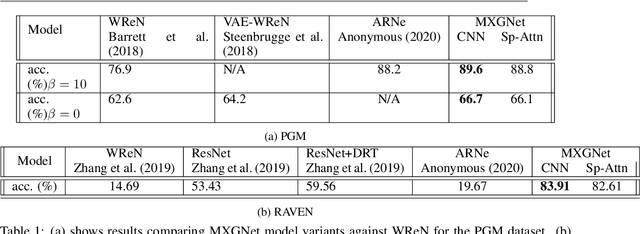
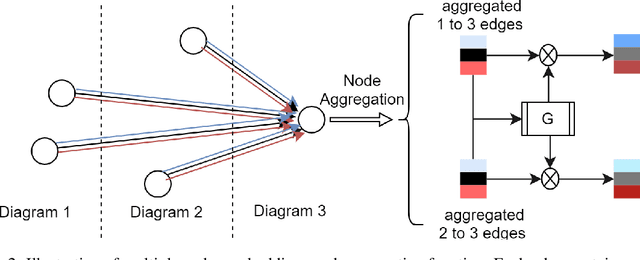
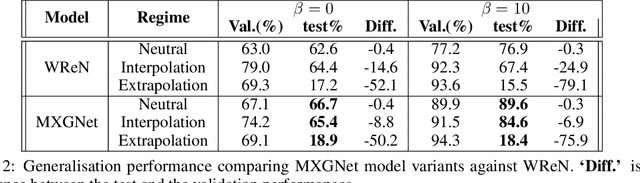
Abstract reasoning, particularly in the visual domain, is a complex human ability, but it remains a challenging problem for artificial neural learning systems. In this work we propose MXGNet, a multilayer graph neural network for multi-panel diagrammatic reasoning tasks. MXGNet combines three powerful concepts, namely, object-level representation, graph neural networks and multiplex graphs, for solving visual reasoning tasks. MXGNet first extracts object-level representations for each element in all panels of the diagrams, and then forms a multi-layer multiplex graph capturing multiple relations between objects across different diagram panels. MXGNet summarises the multiple graphs extracted from the diagrams of the task, and uses this summarisation to pick the most probable answer from the given candidates. We have tested MXGNet on two types of diagrammatic reasoning tasks, namely Diagram Syllogisms and Raven Progressive Matrices (RPM). For an Euler Diagram Syllogism task MXGNet achieves state-of-the-art accuracy of 99.8%. For PGM and RAVEN, two comprehensive datasets for RPM reasoning, MXGNet outperforms the state-of-the-art models by a considerable margin.
Generalisable Relational Reasoning With Comparators in Low-Dimensional Manifolds
Jun 15, 2020
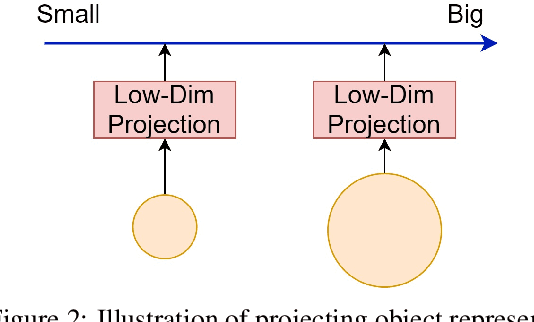

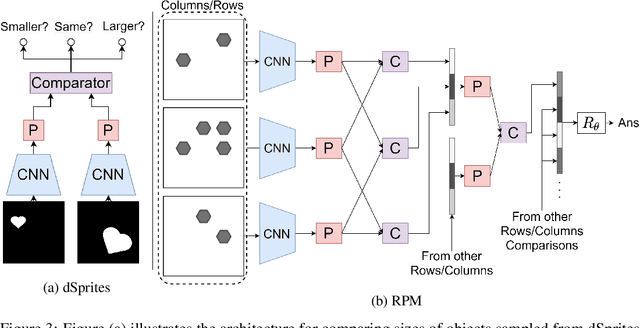
While modern deep neural architectures generalise well when test data is sampled from the same distribution as training data, they fail badly for cases when the test data distribution differs from the training distribution even along a few dimensions. This lack of out-of-distribution generalisation is increasingly manifested when the tasks become more abstract and complex, such as in relational reasoning. In this paper we propose a neuroscience-inspired inductive-biased module that can be readily amalgamated with current neural network architectures to improve out-of-distribution (o.o.d) generalisation performance on relational reasoning tasks. This module learns to project high-dimensional object representations to low-dimensional manifolds for more efficient and generalisable relational comparisons. We show that neural nets with this inductive bias achieve considerably better o.o.d generalisation performance for a range of relational reasoning tasks. We finally analyse the proposed inductive bias module to understand the importance of lower dimension projection, and propose an augmentation to the algorithmic alignment theory to better measure algorithmic alignment with generalisation.
Probabilistic Dual Network Architecture Search on Graphs
Mar 21, 2020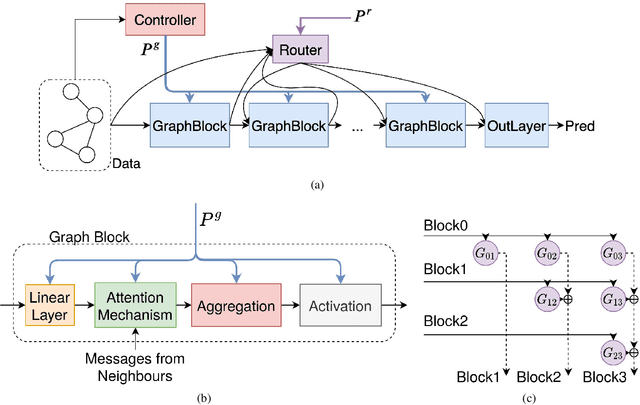

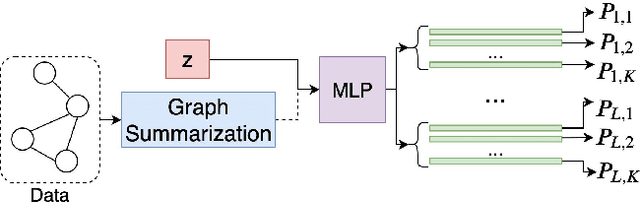
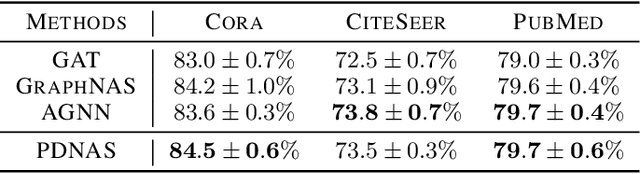
We present the first differentiable Network Architecture Search (NAS) for Graph Neural Networks (GNNs). GNNs show promising performance on a wide range of tasks, but require a large amount of architecture engineering. First, graphs are inherently a non-Euclidean and sophisticated data structure, leading to poor adaptivity of GNN architectures across different datasets. Second, a typical graph block contains numerous different components, such as aggregation and attention, generating a large combinatorial search space. To counter these problems, we propose a Probabilistic Dual Network Architecture Search (PDNAS) framework for GNNs. PDNAS not only optimises the operations within a single graph block (micro-architecture), but also considers how these blocks should be connected to each other (macro-architecture). The dual architecture (micro- and marco-architectures) optimisation allows PDNAS to find deeper GNNs on diverse datasets with better performance compared to other graph NAS methods. Moreover, we use a fully gradient-based search approach to update architectural parameters, making it the first differentiable graph NAS method. PDNAS outperforms existing hand-designed GNNs and NAS results, for example, on the PPI dataset, PDNAS beats its best competitors by 1.67 and 0.17 in F1 scores.
Mixed-Supervised Dual-Network for Medical Image Segmentation
Aug 26, 2019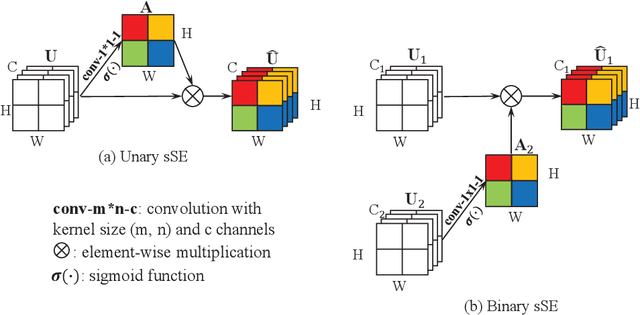
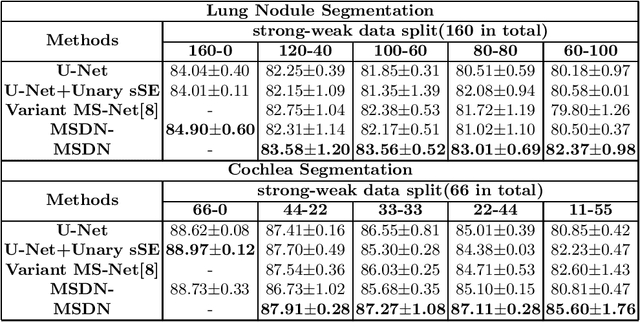
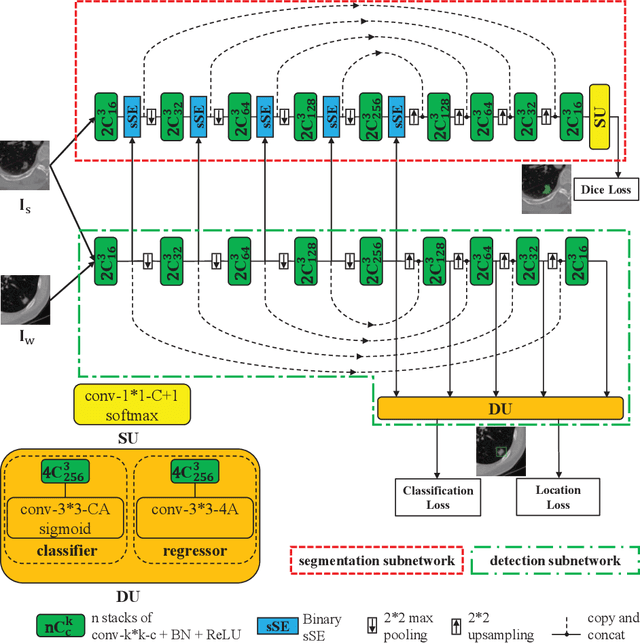
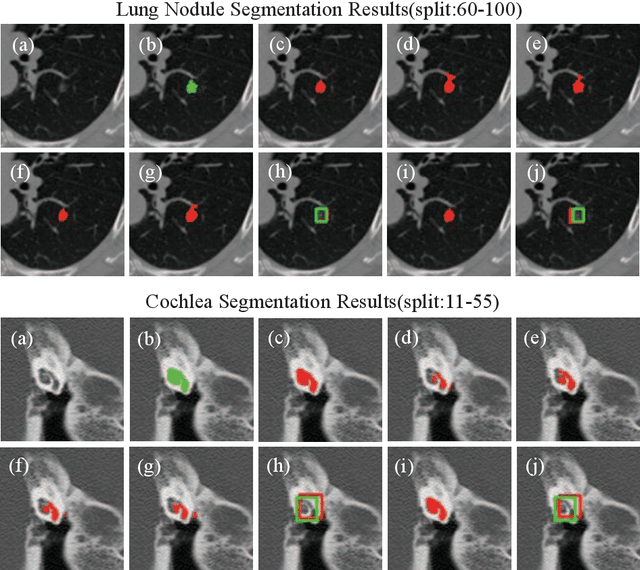
Deep learning based medical image segmentation models usually require large datasets with high-quality dense segmentations to train, which are very time-consuming and expensive to prepare. One way to tackle this challenge is by using the mixed-supervised learning framework, in which only a part of data is densely annotated with segmentation label and the rest is weakly labeled with bounding boxes. The model is trained jointly in a multi-task learning setting. In this paper, we propose Mixed-Supervised Dual-Network (MSDN), a novel architecture which consists of two separate networks for the detection and segmentation tasks respectively, and a series of connection modules between the layers of the two networks. These connection modules are used to transfer useful information from the auxiliary detection task to help the segmentation task. We propose to use a recent technique called "Squeeze and Excitation" in the connection module to boost the transfer. We conduct experiments on two medical image segmentation datasets. The proposed MSDN model outperforms multiple baselines.
A Hybrid Approach with Optimization and Metric-based Meta-Learner for Few-Shot Learning
Apr 04, 2019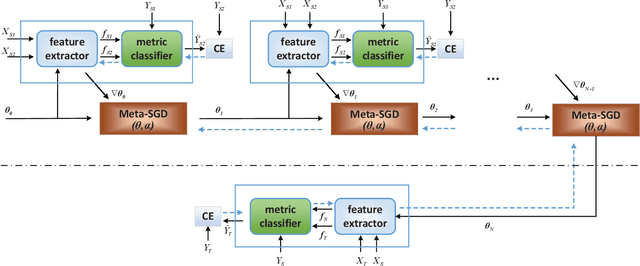
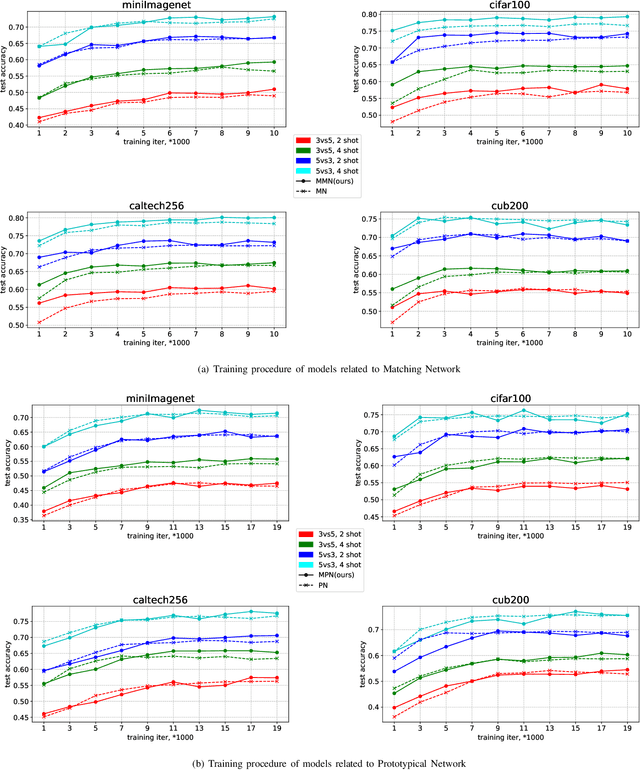
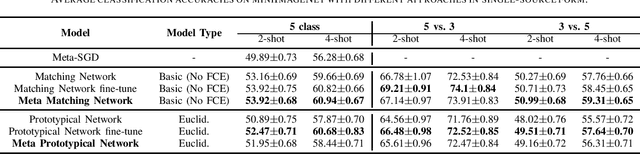
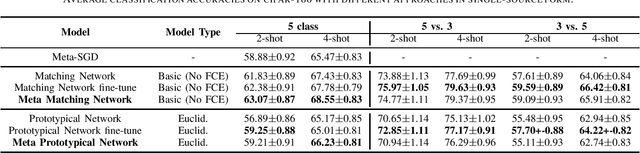
Few-shot learning aims to learn classifiers for new classes with only a few training examples per class. Most existing few-shot learning approaches belong to either metric-based meta-learning or optimization-based meta-learning category, both of which have achieved successes in the simplified "$k$-shot $N$-way" image classification settings. Specifically, the optimization-based approaches train a meta-learner to predict the parameters of the task-specific classifiers. The task-specific classifiers are required to be homogeneous-structured to ease the parameter prediction, so the meta-learning approaches could only handle few-shot learning problems where the tasks share a uniform number of classes. The metric-based approaches learn one task-invariant metric for all the tasks. Even though the metric-learning approaches allow different numbers of classes, they require the tasks all coming from a similar domain such that there exists a uniform metric that could work across tasks. In this work, we propose a hybrid meta-learning model called Meta-Metric-Learner which combines the merits of both optimization- and metric-based approaches. Our meta-metric-learning approach consists of two components, a task-specific metric-based learner as a base model, and a meta-learner that learns and specifies the base model. Thus our model is able to handle flexible numbers of classes as well as generate more generalized metrics for classification across tasks. We test our approach in the standard "$k$-shot $N$-way" few-shot learning setting following previous works and a new realistic few-shot setting with flexible class numbers in both single-source form and multi-source forms. Experiments show that our approach can obtain superior performance in all settings.
Unsupervised and interpretable scene discovery with Discrete-Attend-Infer-Repeat
Mar 14, 2019
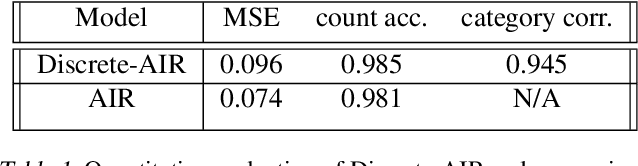
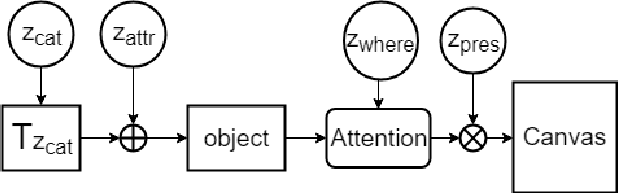
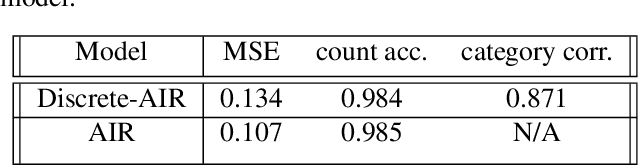
In this work we present Discrete Attend Infer Repeat (Discrete-AIR), a Recurrent Auto-Encoder with structured latent distributions containing discrete categorical distributions, continuous attribute distributions, and factorised spatial attention. While inspired by the original AIR model andretaining AIR model's capability in identifying objects in an image, Discrete-AIR provides direct interpretability of the latent codes. We show that for Multi-MNIST and a multiple-objects version of dSprites dataset, the Discrete-AIR model needs just one categorical latent variable, one attribute variable (for Multi-MNIST only), together with spatial attention variables, for efficient inference. We perform analysis to show that the learnt categorical distributions effectively capture the categories of objects in the scene for Multi-MNIST and for Multi-Sprites.