 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Spiking Neurons for Vision and Language Modeling
Apr 14, 2026Regarded as the third generation of neural networks, Spiking Neural Networks (SNNs) have garnered significant traction due to their biological plausibility and energy efficiency. Recent advancements in large models necessitate spiking neurons capable of high performance, adaptability, and training efficiency. In this work, we first propose a novel functional perspective that provides general guidance for designing the new generation of spiking neurons. Following the insightful guidelines, we propose the Adaptive Spiking Neuron (ASN), which incorporates trainable parameters to learn membrane potential dynamics and enable adaptive firing. ASN adopts an integer training and spike inference paradigm, facilitating efficient SNN training. To further enhance robustness, we propose a specialized variant of ASN, the Normalized Adaptive Spiking Neuron (NASN), which integrates normalization to stabilize training. We evaluate our neuron model on 19 datasets spanning five distinct tasks in both vision and language modalities, demonstrating the effectiveness and versatility of the ASN family. Our ASN family is expected to become the new generation of general-purpose spiking neurons.
Winner-Take-All Spiking Transformer for Language Modeling
Apr 13, 2026Spiking Transformers, which combine the scalability of Transformers with the sparse, energy-efficient property of Spiking Neural Networks (SNNs), have achieved impressive results in neuromorphic and vision tasks and attracted increasing attention. However, existing directly trained spiking transformers primarily focus on vision tasks. For language modeling with spiking transformer, convergence relies heavily on softmax-based spiking self-attention, which incurs high energy costs and poses challenges for neuromorphic deployment. To address this issue, we introduce Winner-Take-All (WTA) mechanisms into spiking transformers and propose two novel softmax-free, spike-driven self-attention modules: WTA Spiking Self-Attention (WSSA) and Causal WTA Spiking Self-Attention (CWSSA). Based on them, we design WTA-based Encoder-only Spiking Transformer (WE-Spikingformer) for masked language modeling and WTA-based Decoder-only Spiking Transformer (WD-Spikingformer) for causal language modeling, systematically exploring softmax-free, spiking-driven Transformer architectures trained end-to-end for natural language processing tasks. Extensive experiments on 16 datasets spanning natural language understanding, question-answering tasks, and commonsense reasoning tasks validate the effectiveness of our approach and highlight the promise of spiking transformers for general language modeling and energy-efficient artificial intelligence.
SpikCommander: A High-performance Spiking Transformer with Multi-view Learning for Efficient Speech Command Recognition
Nov 13, 2025Spiking neural networks (SNNs) offer a promising path toward energy-efficient speech command recognition (SCR) by leveraging their event-driven processing paradigm. However, existing SNN-based SCR methods often struggle to capture rich temporal dependencies and contextual information from speech due to limited temporal modeling and binary spike-based representations. To address these challenges, we first introduce the multi-view spiking temporal-aware self-attention (MSTASA) module, which combines effective spiking temporal-aware attention with a multi-view learning framework to model complementary temporal dependencies in speech commands. Building on MSTASA, we further propose SpikCommander, a fully spike-driven transformer architecture that integrates MSTASA with a spiking contextual refinement channel MLP (SCR-MLP) to jointly enhance temporal context modeling and channel-wise feature integration. We evaluate our method on three benchmark datasets: the Spiking Heidelberg Dataset (SHD), the Spiking Speech Commands (SSC), and the Google Speech Commands V2 (GSC). Extensive experiments demonstrate that SpikCommander consistently outperforms state-of-the-art (SOTA) SNN approaches with fewer parameters under comparable time steps, highlighting its effectiveness and efficiency for robust speech command recognition.
Neural Antidote: Class-Wise Prompt Tuning for Purifying Backdoors in Pre-trained Vision-Language Models
Feb 26, 2025While pre-trained Vision-Language Models (VLMs) such as CLIP exhibit excellent representational capabilities for multimodal data, recent studies have shown that they are vulnerable to backdoor attacks. To alleviate the threat, existing defense strategies primarily focus on fine-tuning the entire suspicious model, yet offer only marginal resistance to state-of-the-art attacks and often result in a decrease in clean accuracy, particularly in data-limited scenarios. Their failure may be attributed to the mismatch between insufficient fine-tuning data and massive parameters in VLMs. To address this challenge, we propose Class-wise Backdoor Prompt Tuning (CBPT) defense, an efficient and effective method that operates on the text prompts to indirectly purify the poisoned VLMs. Specifically, we first employ the advanced contrastive learning via our carefully crafted positive and negative samples, to effectively invert the backdoor triggers that are potentially adopted by the attacker. Once the dummy trigger is established, we utilize the efficient prompt tuning technique to optimize these class-wise text prompts for modifying the model's decision boundary to further reclassify the feature regions of backdoor triggers. Extensive experiments demonstrate that CBPT significantly mitigates backdoor threats while preserving model utility, e.g. an average Clean Accuracy (CA) of 58.86\% and an Attack Success Rate (ASR) of 0.39\% across seven mainstream backdoor attacks. These results underscore the superiority of our prompt purifying design to strengthen model robustness against backdoor attacks.
Human versus Machine Attention in Deep Reinforcement Learning Tasks
Oct 29, 2020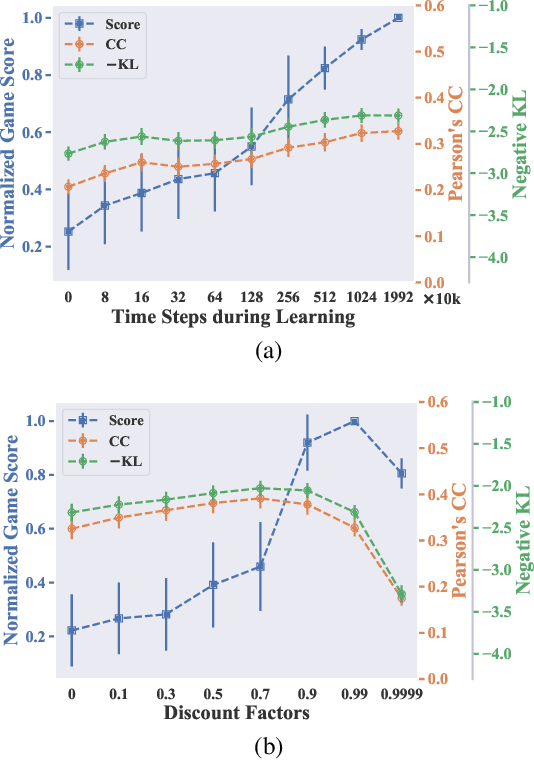

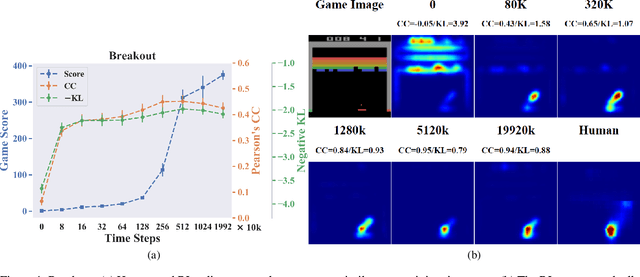
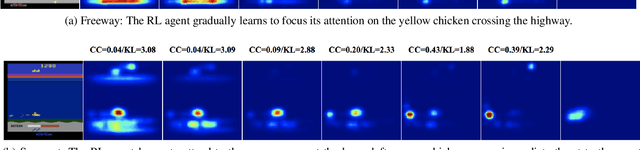
Deep reinforcement learning (RL) algorithms are powerful tools for solving visuomotor decision tasks. However, the trained models are often difficult to interpret, because they are represented as end-to-end deep neural networks. In this paper, we shed light on the inner workings of such trained models by analyzing the pixels that they attend to during task execution, and comparing them with the pixels attended to by humans executing the same tasks. To this end, we investigate the following two questions that, to the best of our knowledge, have not been previously studied. 1) How similar are the visual features learned by RL agents and humans when performing the same task? and, 2) How do similarities and differences in these learned features correlate with RL agents' performance on these tasks? Specifically, we compare the saliency maps of RL agents against visual attention models of human experts when learning to play Atari games. Further, we analyze how hyperparameters of the deep RL algorithm affect the learned features and saliency maps of the trained agents. The insights provided by our results have the potential to inform novel algorithms for the purpose of closing the performance gap between human experts and deep RL agents.