 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisco: Densely-overlapping Cell Instance Segmentation via Adjacency-aware Collaborative Coloring
Feb 05, 2026Accurate cell instance segmentation is foundational for digital pathology analysis. Existing methods based on contour detection and distance mapping still face significant challenges in processing complex and dense cellular regions. Graph coloring-based methods provide a new paradigm for this task, yet the effectiveness of this paradigm in real-world scenarios with dense overlaps and complex topologies has not been verified. Addressing this issue, we release a large-scale dataset GBC-FS 2025, which contains highly complex and dense sub-cellular nuclear arrangements. We conduct the first systematic analysis of the chromatic properties of cell adjacency graphs across four diverse datasets and reveal an important discovery: most real-world cell graphs are non-bipartite, with a high prevalence of odd-length cycles (predominantly triangles). This makes simple 2-coloring theory insufficient for handling complex tissues, while higher-chromaticity models would cause representational redundancy and optimization difficulties. Building on this observation of complex real-world contexts, we propose Disco (Densely-overlapping Cell Instance Segmentation via Adjacency-aware COllaborative Coloring), an adjacency-aware framework based on the "divide and conquer" principle. It uniquely combines a data-driven topological labeling strategy with a constrained deep learning system to resolve complex adjacency conflicts. First, "Explicit Marking" strategy transforms the topological challenge into a learnable classification task by recursively decomposing the cell graph and isolating a "conflict set." Second, "Implicit Disambiguation" mechanism resolves ambiguities in conflict regions by enforcing feature dissimilarity between different instances, enabling the model to learn separable feature representations.
Minimal Semantic Sufficiency Meets Unsupervised Domain Generalization
Sep 19, 2025The generalization ability of deep learning has been extensively studied in supervised settings, yet it remains less explored in unsupervised scenarios. Recently, the Unsupervised Domain Generalization (UDG) task has been proposed to enhance the generalization of models trained with prevalent unsupervised learning techniques, such as Self-Supervised Learning (SSL). UDG confronts the challenge of distinguishing semantics from variations without category labels. Although some recent methods have employed domain labels to tackle this issue, such domain labels are often unavailable in real-world contexts. In this paper, we address these limitations by formalizing UDG as the task of learning a Minimal Sufficient Semantic Representation: a representation that (i) preserves all semantic information shared across augmented views (sufficiency), and (ii) maximally removes information irrelevant to semantics (minimality). We theoretically ground these objectives from the perspective of information theory, demonstrating that optimizing representations to achieve sufficiency and minimality directly reduces out-of-distribution risk. Practically, we implement this optimization through Minimal-Sufficient UDG (MS-UDG), a learnable model by integrating (a) an InfoNCE-based objective to achieve sufficiency; (b) two complementary components to promote minimality: a novel semantic-variation disentanglement loss and a reconstruction-based mechanism for capturing adequate variation. Empirically, MS-UDG sets a new state-of-the-art on popular unsupervised domain-generalization benchmarks, consistently outperforming existing SSL and UDG methods, without category or domain labels during representation learning.
Structure-aware Semantic Discrepancy and Consistency for 3D Medical Image Self-supervised Learning
Jul 03, 20253D medical image self-supervised learning (mSSL) holds great promise for medical analysis. Effectively supporting broader applications requires considering anatomical structure variations in location, scale, and morphology, which are crucial for capturing meaningful distinctions. However, previous mSSL methods partition images with fixed-size patches, often ignoring the structure variations. In this work, we introduce a novel perspective on 3D medical images with the goal of learning structure-aware representations. We assume that patches within the same structure share the same semantics (semantic consistency) while those from different structures exhibit distinct semantics (semantic discrepancy). Based on this assumption, we propose an mSSL framework named $S^2DC$, achieving Structure-aware Semantic Discrepancy and Consistency in two steps. First, $S^2DC$ enforces distinct representations for different patches to increase semantic discrepancy by leveraging an optimal transport strategy. Second, $S^2DC$ advances semantic consistency at the structural level based on neighborhood similarity distribution. By bridging patch-level and structure-level representations, $S^2DC$ achieves structure-aware representations. Thoroughly evaluated across 10 datasets, 4 tasks, and 3 modalities, our proposed method consistently outperforms the state-of-the-art methods in mSSL.
Align Your Rhythm: Generating Highly Aligned Dance Poses with Gating-Enhanced Rhythm-Aware Feature Representation
Mar 21, 2025Automatically generating natural, diverse and rhythmic human dance movements driven by music is vital for virtual reality and film industries. However, generating dance that naturally follows music remains a challenge, as existing methods lack proper beat alignment and exhibit unnatural motion dynamics. In this paper, we propose Danceba, a novel framework that leverages gating mechanism to enhance rhythm-aware feature representation for music-driven dance generation, which achieves highly aligned dance poses with enhanced rhythmic sensitivity. Specifically, we introduce Phase-Based Rhythm Extraction (PRE) to precisely extract rhythmic information from musical phase data, capitalizing on the intrinsic periodicity and temporal structures of music. Additionally, we propose Temporal-Gated Causal Attention (TGCA) to focus on global rhythmic features, ensuring that dance movements closely follow the musical rhythm. We also introduce Parallel Mamba Motion Modeling (PMMM) architecture to separately model upper and lower body motions along with musical features, thereby improving the naturalness and diversity of generated dance movements. Extensive experiments confirm that Danceba outperforms state-of-the-art methods, achieving significantly better rhythmic alignment and motion diversity. Project page: https://danceba.github.io/ .
Band Prompting Aided SAR and Multi-Spectral Data Fusion Framework for Local Climate Zone Classification
Dec 24, 2024



Local climate zone (LCZ) classification is of great value for understanding the complex interactions between urban development and local climate. Recent studies have increasingly focused on the fusion of synthetic aperture radar (SAR) and multi-spectral data to improve LCZ classification performance. However, it remains challenging due to the distinct physical properties of these two types of data and the absence of effective fusion guidance. In this paper, a novel band prompting aided data fusion framework is proposed for LCZ classification, namely BP-LCZ, which utilizes textual prompts associated with band groups to guide the model in learning the physical attributes of different bands and semantics of various categories inherent in SAR and multi-spectral data to augment the fused feature, thus enhancing LCZ classification performance. Specifically, a band group prompting (BGP) strategy is introduced to align the visual representation effectively at the level of band groups, which also facilitates a more adequate extraction of semantic information of different bands with textual information. In addition, a multivariate supervised matrix (MSM) based training strategy is proposed to alleviate the problem of positive and negative sample confusion by completing the supervised information. The experimental results demonstrate the effectiveness and superiority of the proposed data fusion framework.
FastDrag: Manipulate Anything in One Step
May 24, 2024



Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance.
Revisiting AP Loss for Dense Object Detection: Adaptive Ranking Pair Selection
Jul 25, 2022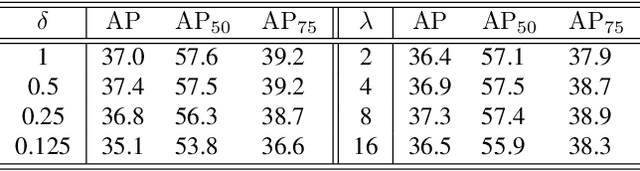
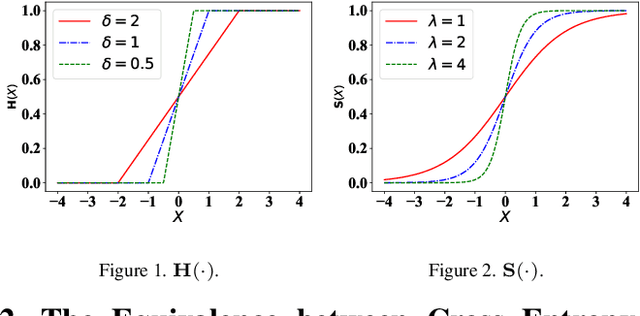
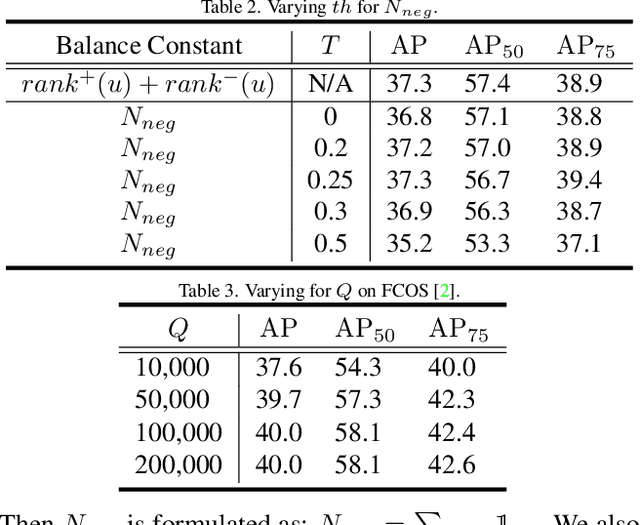
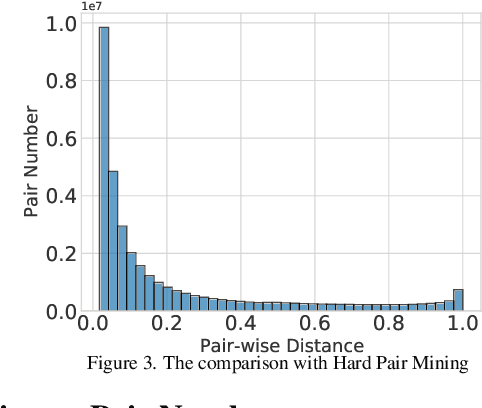
Average precision (AP) loss has recently shown promising performance on the dense object detection task. However,a deep understanding of how AP loss affects the detector from a pairwise ranking perspective has not yet been developed.In this work, we revisit the average precision (AP)loss and reveal that the crucial element is that of selecting the ranking pairs between positive and negative samples.Based on this observation, we propose two strategies to improve the AP loss. The first of these is a novel Adaptive Pairwise Error (APE) loss that focusing on ranking pairs in both positive and negative samples. Moreover,we select more accurate ranking pairs by exploiting the normalized ranking scores and localization scores with a clustering algorithm. Experiments conducted on the MSCOCO dataset support our analysis and demonstrate the superiority of our proposed method compared with current classification and ranking loss. The code is available at https://github.com/Xudangliatiger/APE-Loss.
Adaptive Transfer Learning of Multi-View Time Series Classification
Oct 14, 2019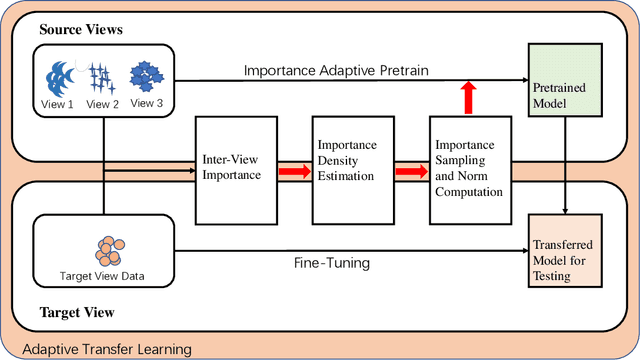


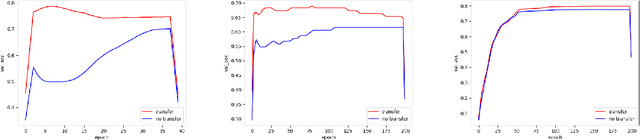
Time Series Classification (TSC) has been an important and challenging task in data mining, especially on multivariate time series and multi-view time series data sets. Meanwhile, transfer learning has been widely applied in computer vision and natural language processing applications to improve deep neural network's generalization capabilities. However, very few previous works applied transfer learning framework to time series mining problems. Particularly, the technique of measuring similarities between source domain and target domain based on dynamic representation such as density estimation with importance sampling has never been combined with transfer learning framework. In this paper, we first proposed a general adaptive transfer learning framework for multi-view time series data, which shows strong ability in storing inter-view importance value in the process of knowledge transfer. Next, we represented inter-view importance through some time series similarity measurements and approximated the posterior distribution in latent space for the importance sampling via density estimation techniques. We then computed the matrix norm of sampled importance value, which controls the degree of knowledge transfer in pre-training process. We further evaluated our work, applied it to many other time series classification tasks, and observed that our architecture maintained desirable generalization ability. Finally, we concluded that our framework could be adapted with deep learning techniques to receive significant model performance improvements.