 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECQED: Emotion-Cause Quadruple Extraction in Dialogs
Jun 10, 2023The existing emotion-cause pair extraction (ECPE) task, unfortunately, ignores extracting the emotion type and cause type, while these fine-grained meta-information can be practically useful in real-world applications, i.e., chat robots and empathic dialog generation. Also the current ECPE is limited to the scenario of single text piece, while neglecting the studies at dialog level that should have more realistic values. In this paper, we extend the ECPE task with a broader definition and scenario, presenting a new task, Emotion-Cause Quadruple Extraction in Dialogs (ECQED), which requires detecting emotion-cause utterance pairs and emotion and cause types. We present an ECQED model based on a structural and semantic heterogeneous graph as well as a parallel grid tagging scheme, which advances in effectively incorporating the dialog context structure, meanwhile solving the challenging overlapped quadruple issue. Via experiments we show that introducing the fine-grained emotion and cause features evidently helps better dialog generation. Also our proposed ECQED system shows exceptional superiority over baselines on both the emotion-cause quadruple or pair extraction tasks, meanwhile being highly efficient.
FACTUAL: A Benchmark for Faithful and Consistent Textual Scene Graph Parsing
Jun 01, 2023



Textual scene graph parsing has become increasingly important in various vision-language applications, including image caption evaluation and image retrieval. However, existing scene graph parsers that convert image captions into scene graphs often suffer from two types of errors. First, the generated scene graphs fail to capture the true semantics of the captions or the corresponding images, resulting in a lack of faithfulness. Second, the generated scene graphs have high inconsistency, with the same semantics represented by different annotations. To address these challenges, we propose a novel dataset, which involves re-annotating the captions in Visual Genome (VG) using a new intermediate representation called FACTUAL-MR. FACTUAL-MR can be directly converted into faithful and consistent scene graph annotations. Our experimental results clearly demonstrate that the parser trained on our dataset outperforms existing approaches in terms of faithfulness and consistency. This improvement leads to a significant performance boost in both image caption evaluation and zero-shot image retrieval tasks. Furthermore, we introduce a novel metric for measuring scene graph similarity, which, when combined with the improved scene graph parser, achieves state-of-the-art (SOTA) results on multiple benchmark datasets for the aforementioned tasks. The code and dataset are available at https://github.com/zhuang-li/FACTUAL .
On the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training
Apr 19, 2023Aspect-based sentiment analysis (ABSA) aims at automatically inferring the specific sentiment polarities toward certain aspects of products or services behind the social media texts or reviews, which has been a fundamental application to the real-world society. Since the early 2010s, ABSA has achieved extraordinarily high accuracy with various deep neural models. However, existing ABSA models with strong in-house performances may fail to generalize to some challenging cases where the contexts are variable, i.e., low robustness to real-world environments. In this study, we propose to enhance the ABSA robustness by systematically rethinking the bottlenecks from all possible angles, including model, data, and training. First, we strengthen the current best-robust syntax-aware models by further incorporating the rich external syntactic dependencies and the labels with aspect simultaneously with a universal-syntax graph convolutional network. In the corpus perspective, we propose to automatically induce high-quality synthetic training data with various types, allowing models to learn sufficient inductive bias for better robustness. Last, we based on the rich pseudo data perform adversarial training to enhance the resistance to the context perturbation and meanwhile employ contrastive learning to reinforce the representations of instances with contrastive sentiments. Extensive robustness evaluations are conducted. The results demonstrate that our enhanced syntax-aware model achieves better robustness performances than all the state-of-the-art baselines. By additionally incorporating our synthetic corpus, the robust testing results are pushed with around 10% accuracy, which are then further improved by installing the advanced training strategies. In-depth analyses are presented for revealing the factors influencing the ABSA robustness.
DiaASQ : A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis
Nov 20, 2022



The rapid development of aspect-based sentiment analysis (ABSA) within recent decades shows great potential for real-world society. The current ABSA works, however, are mostly limited to the scenario of a single text piece, leaving the study in dialogue contexts unexplored. In this work, we introduce a novel task of conversational aspect-based sentiment quadruple analysis, namely DiaASQ, aiming to detect the sentiment quadruple of \emph{target-aspect-opinion-sentiment} in a dialogue. DiaASQ bridges the gap between fine-grained sentiment analysis and conversational opinion mining. We manually construct a large-scale high-quality DiaASQ dataset in both Chinese and English languages. We deliberately develop a neural model to benchmark the task, which advances in effectively performing end-to-end quadruple prediction, and manages to incorporate rich dialogue-specific and discourse feature representations for better cross-utterance quadruple extraction. We finally point out several potential future works to facilitate the follow-up research of this new task.
TOE: A Grid-Tagging Discontinuous NER Model Enhanced by Embedding Tag/Word Relations and More Fine-Grained Tags
Nov 01, 2022So far, discontinuous named entity recognition (NER) has received increasing research attention and many related methods have surged such as hypergraph-based methods, span-based methods, and sequence-to-sequence (Seq2Seq) methods, etc. However, these methods more or less suffer from some problems such as decoding ambiguity and efficiency, which limit their performance. Recently, grid-tagging methods, which benefit from the flexible design of tagging systems and model architectures, have shown superiority to adapt for various information extraction tasks. In this paper, we follow the line of such methods and propose a competitive grid-tagging model for discontinuous NER. We call our model TOE because we incorporate two kinds of Tag-Oriented Enhancement mechanisms into a state-of-the-art (SOTA) grid-tagging model that casts the NER problem into word-word relationship prediction. First, we design a Tag Representation Embedding Module (TREM) to force our model to consider not only word-word relationships but also word-tag and tag-tag relationships. Concretely, we construct tag representations and embed them into TREM, so that TREM can treat tag and word representations as queries/keys/values and utilize self-attention to model their relationships. On the other hand, motivated by the Next-Neighboring-Word (NNW) and Tail-Head-Word (THW) tags in the SOTA model, we add two new symmetric tags, namely Previous-Neighboring-Word (PNW) and Head-Tail-Word (HTW), to model more fine-grained word-word relationships and alleviate error propagation from tag prediction. In the experiments of three benchmark datasets, namely CADEC, ShARe13 and ShARe14, our TOE model pushes the SOTA results by about 0.83%, 0.05% and 0.66% in F1, demonstrating its effectiveness.
Entity-centered Cross-document Relation Extraction
Oct 29, 2022



Relation Extraction (RE) is a fundamental task of information extraction, which has attracted a large amount of research attention. Previous studies focus on extracting the relations within a sentence or document, while currently researchers begin to explore cross-document RE. However, current cross-document RE methods directly utilize text snippets surrounding target entities in multiple given documents, which brings considerable noisy and non-relevant sentences. Moreover, they utilize all the text paths in a document bag in a coarse-grained way, without considering the connections between these text paths.In this paper, we aim to address both of these shortages and push the state-of-the-art for cross-document RE. First, we focus on input construction for our RE model and propose an entity-based document-context filter to retain useful information in the given documents by using the bridge entities in the text paths. Second, we propose a cross-document RE model based on cross-path entity relation attention, which allow the entity relations across text paths to interact with each other. We compare our cross-document RE method with the state-of-the-art methods in the dataset CodRED. Our method outperforms them by at least 10% in F1, thus demonstrating its effectiveness.
Conversational Semantic Role Labeling with Predicate-Oriented Latent Graph
Oct 06, 2022
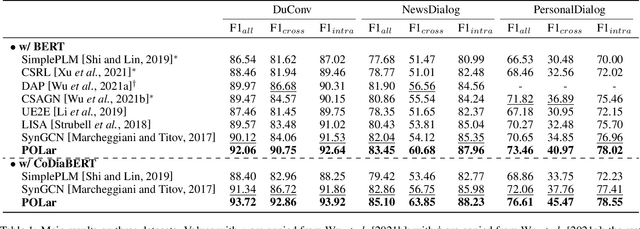
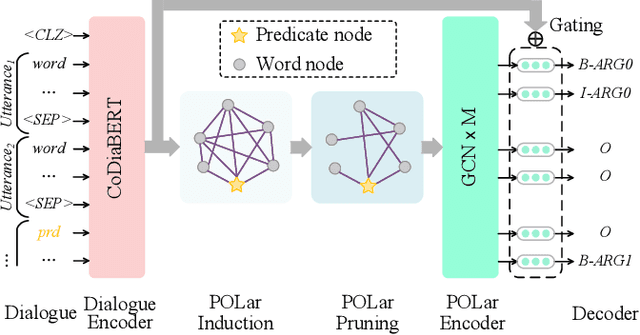
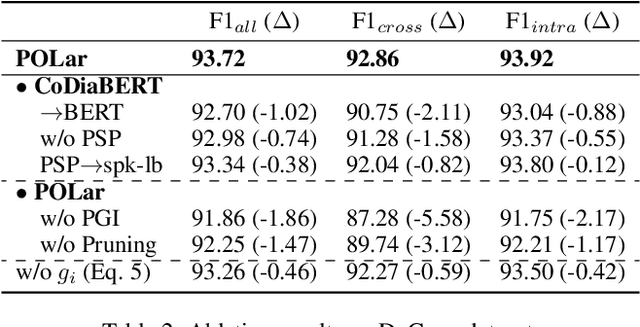
Conversational semantic role labeling (CSRL) is a newly proposed task that uncovers the shallow semantic structures in a dialogue text. Unfortunately several important characteristics of the CSRL task have been overlooked by the existing works, such as the structural information integration, near-neighbor influence. In this work, we investigate the integration of a latent graph for CSRL. We propose to automatically induce a predicate-oriented latent graph (POLar) with a predicate-centered Gaussian mechanism, by which the nearer and informative words to the predicate will be allocated with more attention. The POLar structure is then dynamically pruned and refined so as to best fit the task need. We additionally introduce an effective dialogue-level pre-trained language model, CoDiaBERT, for better supporting multiple utterance sentences and handling the speaker coreference issue in CSRL. Our system outperforms best-performing baselines on three benchmark CSRL datasets with big margins, especially achieving over 4% F1 score improvements on the cross-utterance argument detection. Further analyses are presented to better understand the effectiveness of our proposed methods.
Joint Alignment of Multi-Task Feature and Label Spaces for Emotion Cause Pair Extraction
Sep 09, 2022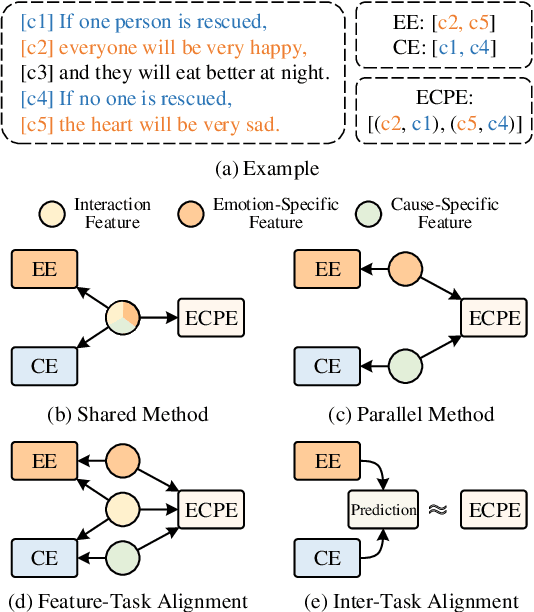
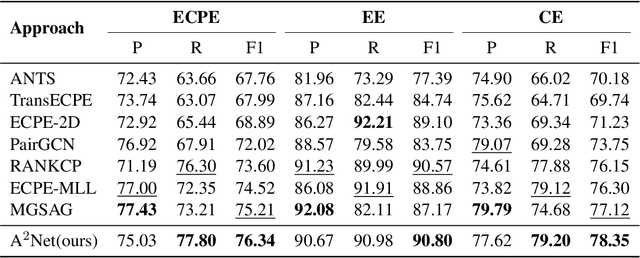
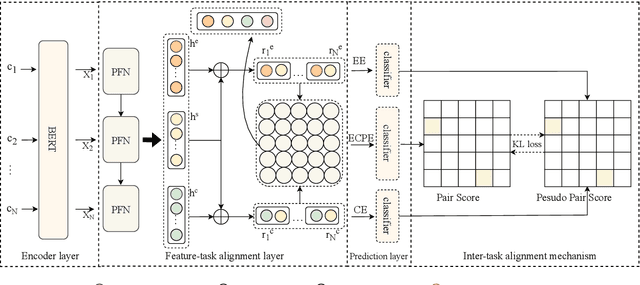
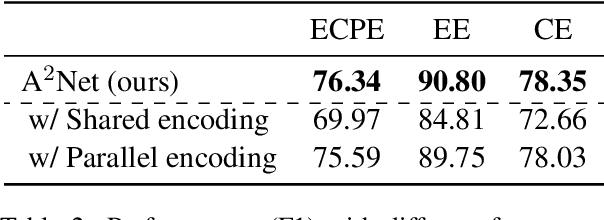
Emotion cause pair extraction (ECPE), as one of the derived subtasks of emotion cause analysis (ECA), shares rich inter-related features with emotion extraction (EE) and cause extraction (CE). Therefore EE and CE are frequently utilized as auxiliary tasks for better feature learning, modeled via multi-task learning (MTL) framework by prior works to achieve state-of-the-art (SoTA) ECPE results. However, existing MTL-based methods either fail to simultaneously model the specific features and the interactive feature in between, or suffer from the inconsistency of label prediction. In this work, we consider addressing the above challenges for improving ECPE by performing two alignment mechanisms with a novel A^2Net model. We first propose a feature-task alignment to explicitly model the specific emotion-&cause-specific features and the shared interactive feature. Besides, an inter-task alignment is implemented, in which the label distance between the ECPE and the combinations of EE&CE are learned to be narrowed for better label consistency. Evaluations of benchmarks show that our methods outperform current best-performing systems on all ECA subtasks. Further analysis proves the importance of our proposed alignment mechanisms for the task.
OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction
Sep 06, 2022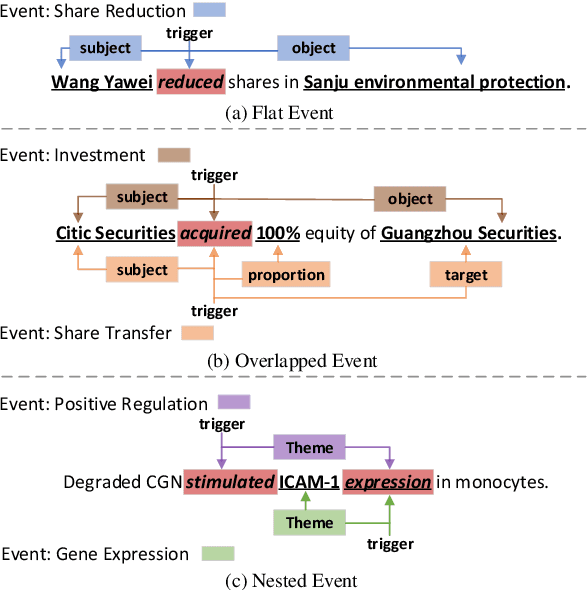
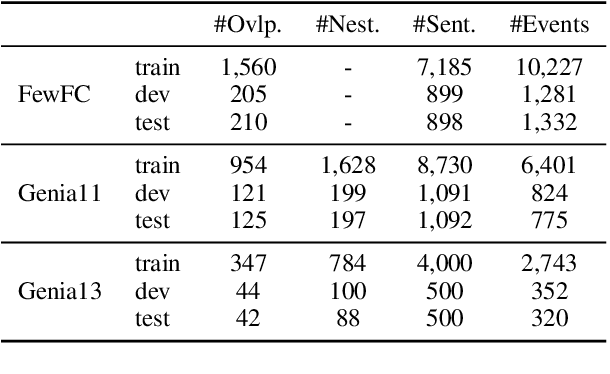
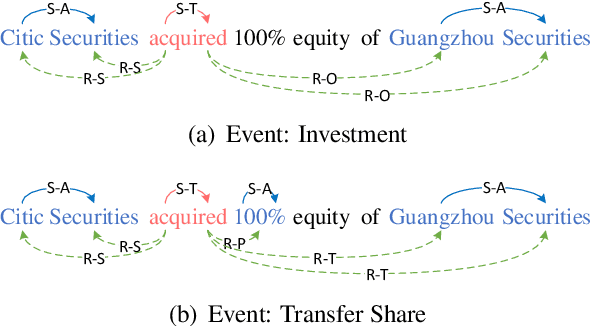
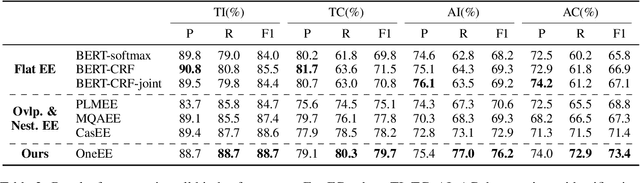
Event extraction (EE) is an essential task of information extraction, which aims to extract structured event information from unstructured text. Most prior work focuses on extracting flat events while neglecting overlapped or nested ones. A few models for overlapped and nested EE includes several successive stages to extract event triggers and arguments,which suffer from error propagation. Therefore, we design a simple yet effective tagging scheme and model to formulate EE as word-word relation recognition, called OneEE. The relations between trigger or argument words are simultaneously recognized in one stage with parallel grid tagging, thus yielding a very fast event extraction speed. The model is equipped with an adaptive event fusion module to generate event-aware representations and a distance-aware predictor to integrate relative distance information for word-word relation recognition, which are empirically demonstrated to be effective mechanisms. Experiments on 3 overlapped and nested EE benchmarks, namely FewFC, Genia11, and Genia13, show that OneEE achieves the state-of-the-art (SOTA) results. Moreover, the inference speed of OneEE is faster than those of baselines in the same condition, and can be further substantially improved since it supports parallel inference.
Effective Token Graph Modeling using a Novel Labeling Strategy for Structured Sentiment Analysis
Mar 21, 2022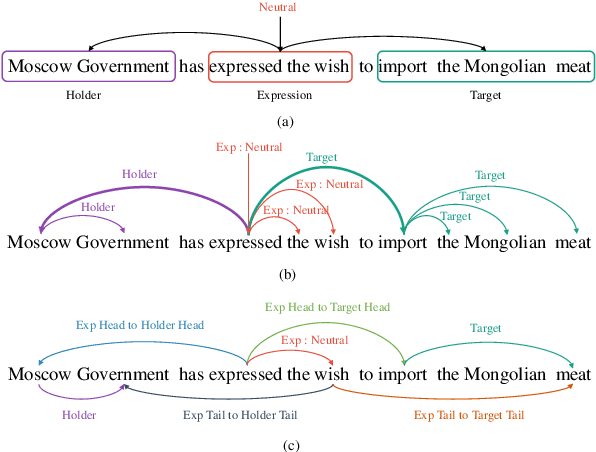
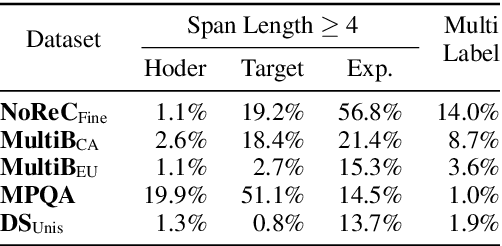

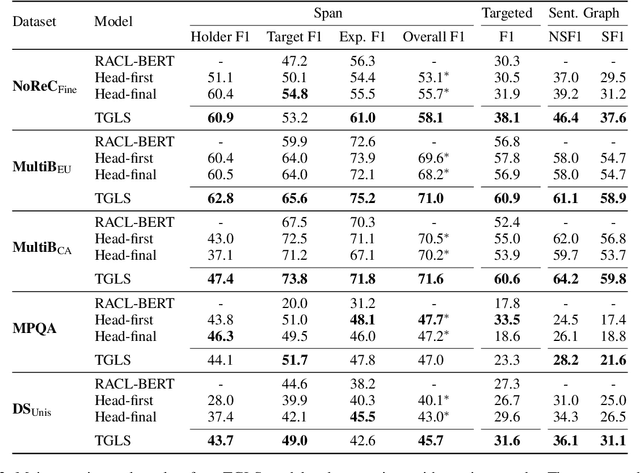
The state-of-the-art model for structured sentiment analysis casts the task as a dependency parsing problem, which has some limitations: (1) The label proportions for span prediction and span relation prediction are imbalanced. (2) The span lengths of sentiment tuple components may be very large in this task, which will further exacerbate the imbalance problem. (3) Two nodes in a dependency graph cannot have multiple arcs, therefore some overlapped sentiment tuples cannot be recognized. In this work, we propose nichetargeting solutions for these issues. First, we introduce a novel labeling strategy, which contains two sets of token pair labels, namely essential label set and whole label set. The essential label set consists of the basic labels for this task, which are relatively balanced and applied in the prediction layer. The whole label set includes rich labels to help our model capture various token relations, which are applied in the hidden layer to softly influence our model. Moreover, we also propose an effective model to well collaborate with our labeling strategy, which is equipped with the graph attention networks to iteratively refine token representations, and the adaptive multi-label classifier to dynamically predict multiple relations between token pairs. We perform extensive experiments on 5 benchmark datasets in four languages. Experimental results show that our model outperforms previous SOTA models by a large margin.