 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training
Apr 19, 2023Aspect-based sentiment analysis (ABSA) aims at automatically inferring the specific sentiment polarities toward certain aspects of products or services behind the social media texts or reviews, which has been a fundamental application to the real-world society. Since the early 2010s, ABSA has achieved extraordinarily high accuracy with various deep neural models. However, existing ABSA models with strong in-house performances may fail to generalize to some challenging cases where the contexts are variable, i.e., low robustness to real-world environments. In this study, we propose to enhance the ABSA robustness by systematically rethinking the bottlenecks from all possible angles, including model, data, and training. First, we strengthen the current best-robust syntax-aware models by further incorporating the rich external syntactic dependencies and the labels with aspect simultaneously with a universal-syntax graph convolutional network. In the corpus perspective, we propose to automatically induce high-quality synthetic training data with various types, allowing models to learn sufficient inductive bias for better robustness. Last, we based on the rich pseudo data perform adversarial training to enhance the resistance to the context perturbation and meanwhile employ contrastive learning to reinforce the representations of instances with contrastive sentiments. Extensive robustness evaluations are conducted. The results demonstrate that our enhanced syntax-aware model achieves better robustness performances than all the state-of-the-art baselines. By additionally incorporating our synthetic corpus, the robust testing results are pushed with around 10% accuracy, which are then further improved by installing the advanced training strategies. In-depth analyses are presented for revealing the factors influencing the ABSA robustness.
Conversational Semantic Role Labeling with Predicate-Oriented Latent Graph
Oct 06, 2022
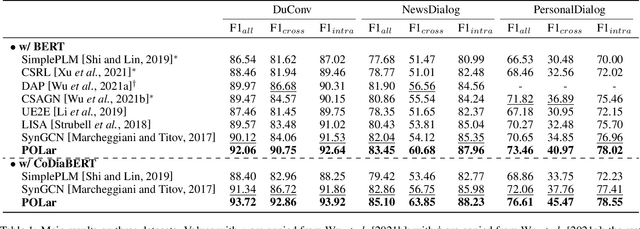
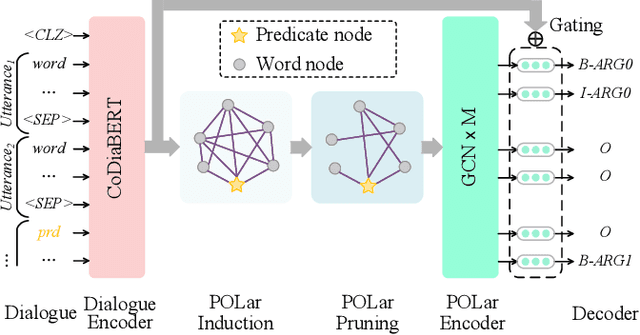
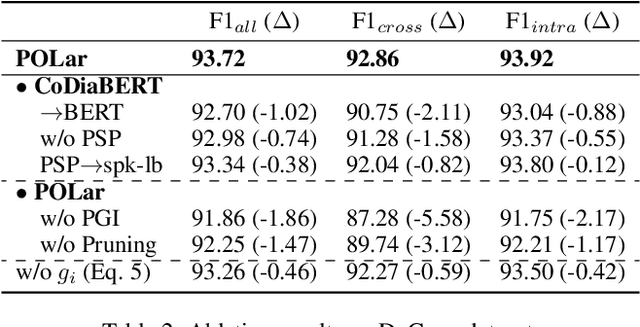
Conversational semantic role labeling (CSRL) is a newly proposed task that uncovers the shallow semantic structures in a dialogue text. Unfortunately several important characteristics of the CSRL task have been overlooked by the existing works, such as the structural information integration, near-neighbor influence. In this work, we investigate the integration of a latent graph for CSRL. We propose to automatically induce a predicate-oriented latent graph (POLar) with a predicate-centered Gaussian mechanism, by which the nearer and informative words to the predicate will be allocated with more attention. The POLar structure is then dynamically pruned and refined so as to best fit the task need. We additionally introduce an effective dialogue-level pre-trained language model, CoDiaBERT, for better supporting multiple utterance sentences and handling the speaker coreference issue in CSRL. Our system outperforms best-performing baselines on three benchmark CSRL datasets with big margins, especially achieving over 4% F1 score improvements on the cross-utterance argument detection. Further analyses are presented to better understand the effectiveness of our proposed methods.
Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extractionwith Rich Syntactic Knowledge
May 06, 2021
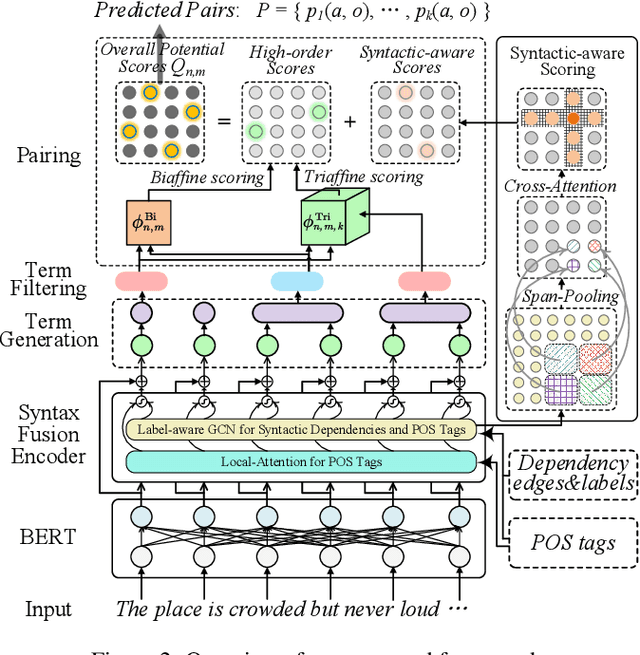
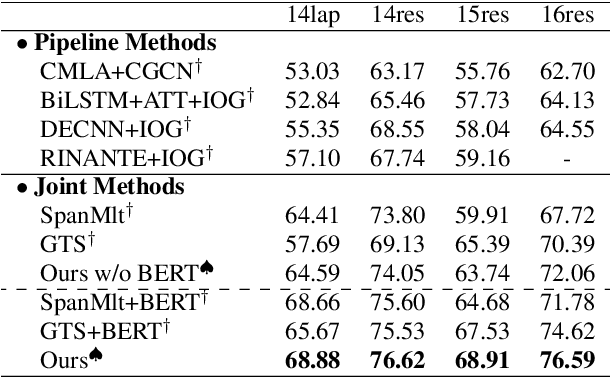
In this paper, we propose to enhance the pair-wise aspect and opinion terms extraction (PAOTE) task by incorporating rich syntactic knowledge. We first build a syntax fusion encoder for encoding syntactic features, including a label-aware graph convolutional network (LAGCN) for modeling the dependency edges and labels, as well as the POS tags unifiedly, and a local-attention module encoding POS tags for better term boundary detection. During pairing, we then adopt Biaffine and Triaffine scoring for high-order aspect-opinion term pairing, in the meantime re-harnessing the syntax-enriched representations in LAGCN for syntactic-aware scoring. Experimental results on four benchmark datasets demonstrate that our model outperforms current state-of-the-art baselines, meanwhile yielding explainable predictions with syntactic knowledge.
Nominal Compound Chain Extraction: A New Task for Semantic-enriched Lexical Chain
Sep 19, 2020
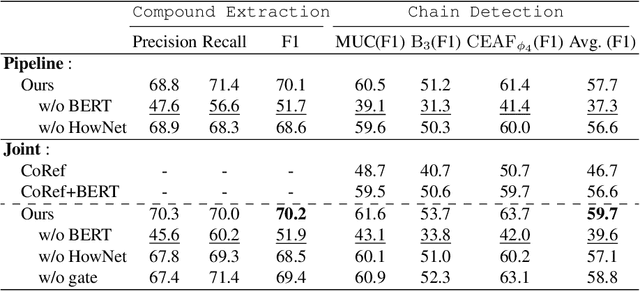
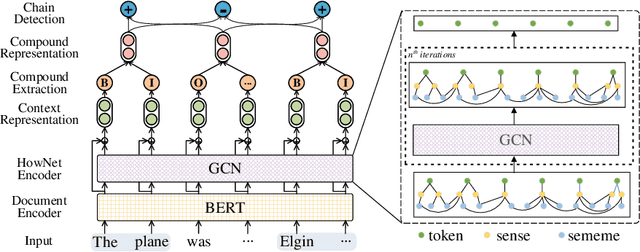

Lexical chain consists of cohesion words in a document, which implies the underlying structure of a text, and thus facilitates downstream NLP tasks. Nevertheless, existing work focuses on detecting the simple surface lexicons with shallow syntax associations, ignoring the semantic-aware lexical compounds as well as the latent semantic frames, (e.g., topic), which can be much more crucial for real-world NLP applications. In this paper, we introduce a novel task, Nominal Compound Chain Extraction (NCCE), extracting and clustering all the nominal compounds that share identical semantic topics. In addition, we model the task as a two-stage prediction (i.e., compound extraction and chain detection), which is handled via a proposed joint framework. The model employs the BERT encoder to yield contextualized document representation. Also, HowNet is exploited as external resources for offering rich sememe information. The experiments are based on our manually annotated corpus, and the results prove the necessity of the NCCE task as well as the effectiveness of our joint approach.
Mimic and Conquer: Heterogeneous Tree Structure Distillation for Syntactic NLP
Sep 16, 2020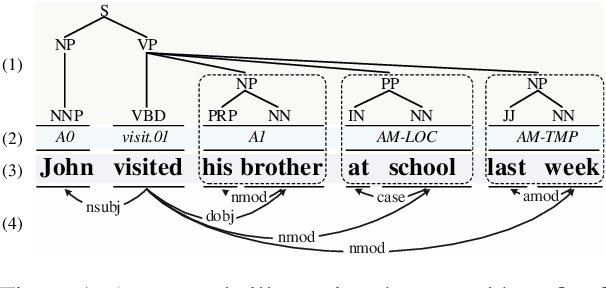
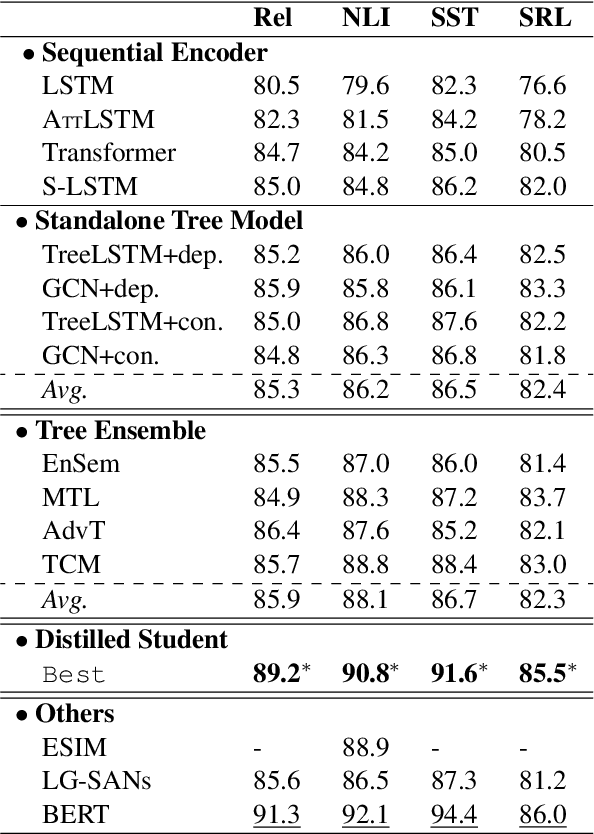
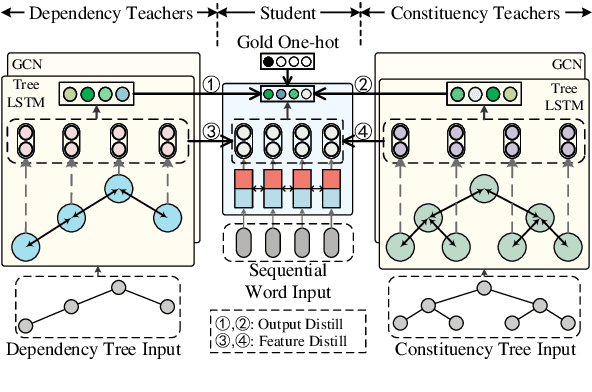
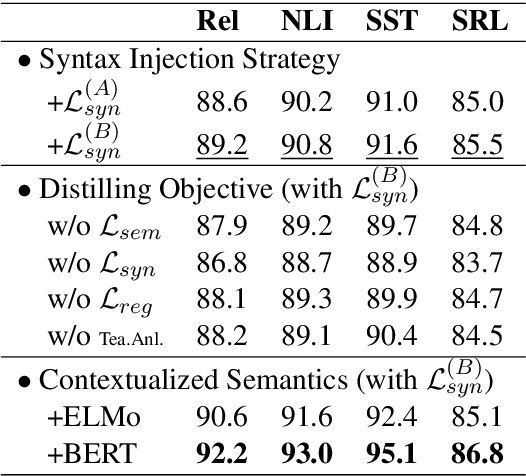
Syntax has been shown useful for various NLP tasks, while existing work mostly encodes singleton syntactic tree using one hierarchical neural network. In this paper, we investigate a simple and effective method, Knowledge Distillation, to integrate heterogeneous structure knowledge into a unified sequential LSTM encoder. Experimental results on four typical syntax-dependent tasks show that our method outperforms tree encoders by effectively integrating rich heterogeneous structure syntax, meanwhile reducing error propagation, and also outperforms ensemble methods, in terms of both the efficiency and accuracy.
Retrofitting Structure-aware Transformer Language Model for End Tasks
Sep 16, 2020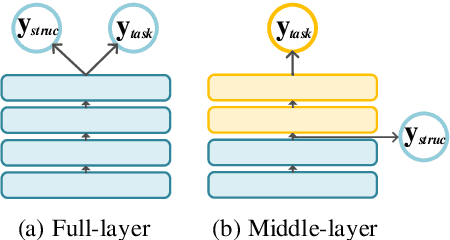
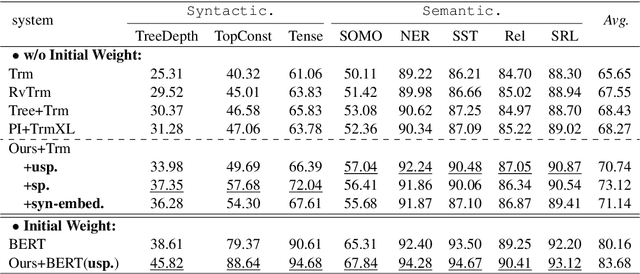
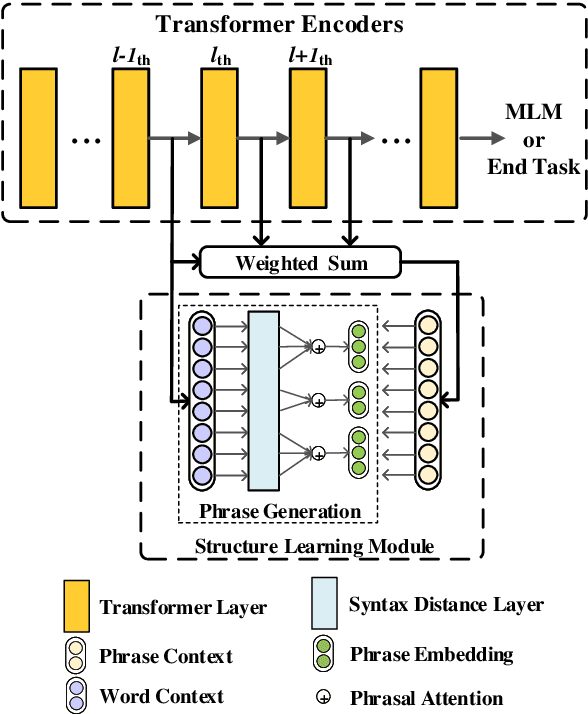
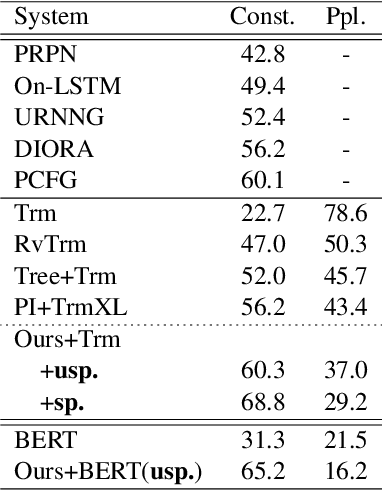
We consider retrofitting structure-aware Transformer-based language model for facilitating end tasks by proposing to exploit syntactic distance to encode both the phrasal constituency and dependency connection into the language model. A middle-layer structural learning strategy is leveraged for structure integration, accomplished with main semantic task training under multi-task learning scheme. Experimental results show that the retrofitted structure-aware Transformer language model achieves improved perplexity, meanwhile inducing accurate syntactic phrases. By performing structure-aware fine-tuning, our model achieves significant improvements for both semantic- and syntactic-dependent tasks.
High-order Refining for End-to-end Chinese Semantic Role Labeling
Sep 15, 2020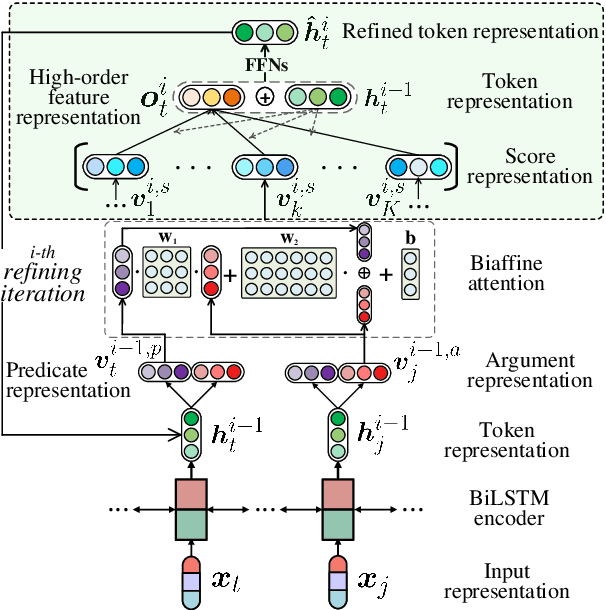
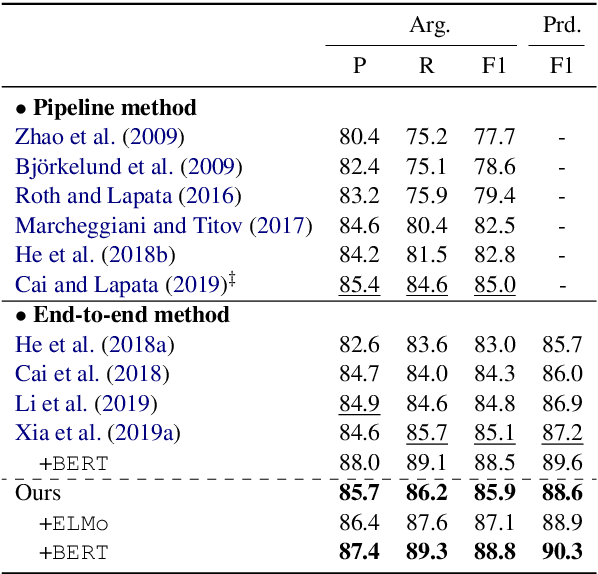
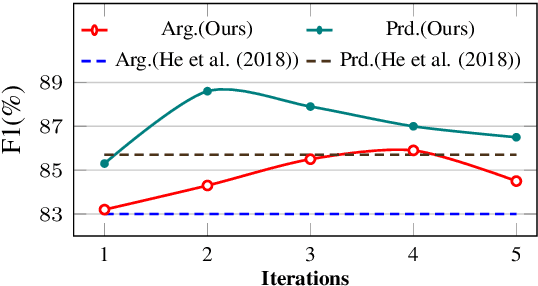
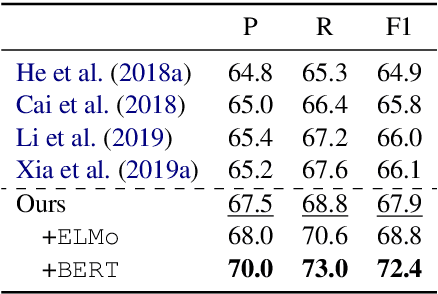
Current end-to-end semantic role labeling is mostly accomplished via graph-based neural models. However, these all are first-order models, where each decision for detecting any predicate-argument pair is made in isolation with local features. In this paper, we present a high-order refining mechanism to perform interaction between all predicate-argument pairs. Based on the baseline graph model, our high-order refining module learns higher-order features between all candidate pairs via attention calculation, which are later used to update the original token representations. After several iterations of refinement, the underlying token representations can be enriched with globally interacted features. Our high-order model achieves state-of-the-art results on Chinese SRL data, including CoNLL09 and Universal Proposition Bank, meanwhile relieving the long-range dependency issues.