 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
QAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
Query Refinement Prompts for Closed-Book Long-Form Question Answering
Oct 31, 2022Large language models (LLMs) have been shown to perform well in answering questions and in producing long-form texts, both in few-shot closed-book settings. While the former can be validated using well-known evaluation metrics, the latter is difficult to evaluate. We resolve the difficulties to evaluate long-form output by doing both tasks at once -- to do question answering that requires long-form answers. Such questions tend to be multifaceted, i.e., they may have ambiguities and/or require information from multiple sources. To this end, we define query refinement prompts that encourage LLMs to explicitly express the multifacetedness in questions and generate long-form answers covering multiple facets of the question. Our experiments on two long-form question answering datasets, ASQA and AQuAMuSe, show that using our prompts allows us to outperform fully finetuned models in the closed book setting, as well as achieve results comparable to retrieve-then-generate open-book models.
Language Models are Multilingual Chain-of-Thought Reasoners
Oct 06, 2022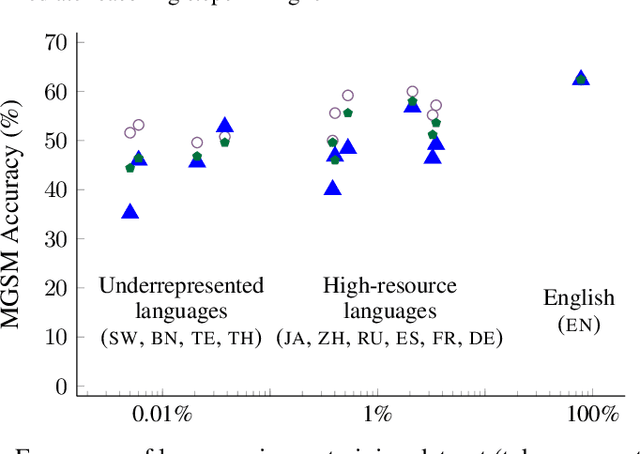


We evaluate the reasoning abilities of large language models in multilingual settings. We introduce the Multilingual Grade School Math (MGSM) benchmark, by manually translating 250 grade-school math problems from the GSM8K dataset (Cobbe et al., 2021) into ten typologically diverse languages. We find that the ability to solve MGSM problems via chain-of-thought prompting emerges with increasing model scale, and that models have strikingly strong multilingual reasoning abilities, even in underrepresented languages such as Bengali and Swahili. Finally, we show that the multilingual reasoning abilities of language models extend to other tasks such as commonsense reasoning and word-in-context semantic judgment. The MGSM benchmark is publicly available at https://github.com/google-research/url-nlp.
Conditional Generation with a Question-Answering Blueprint
Jul 01, 2022
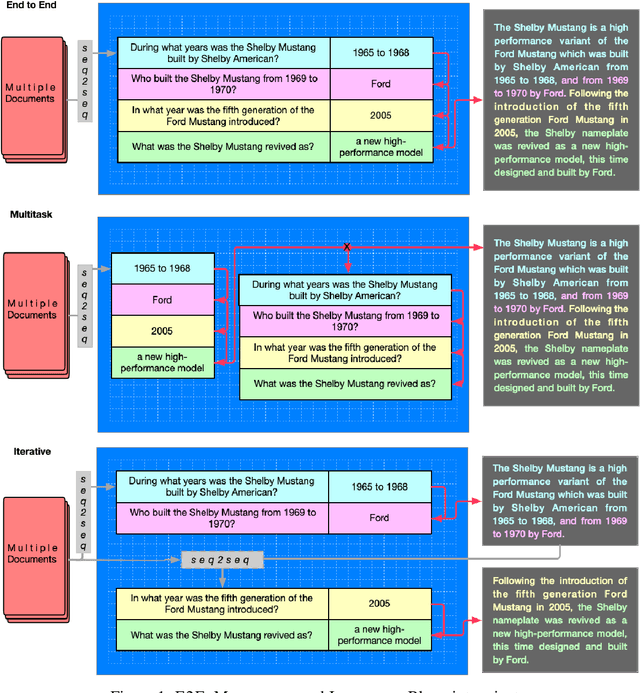
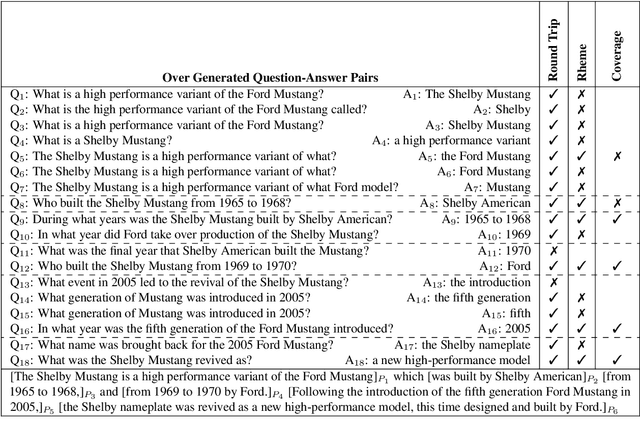
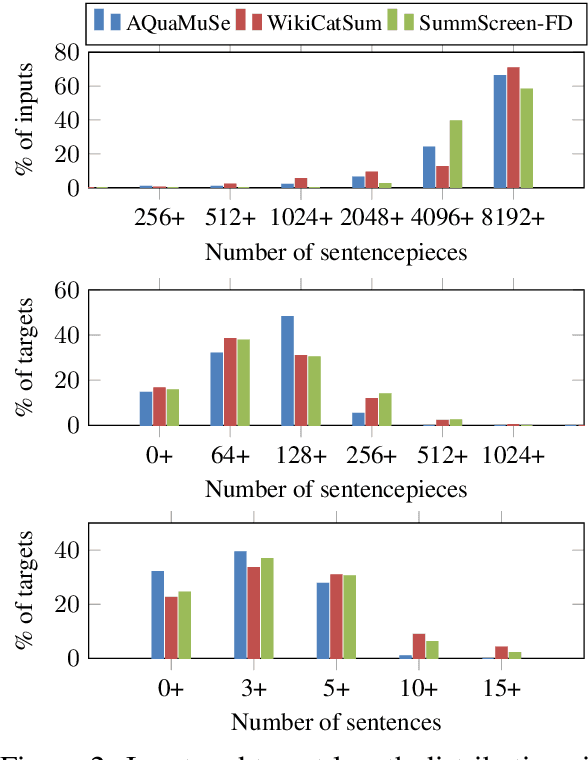
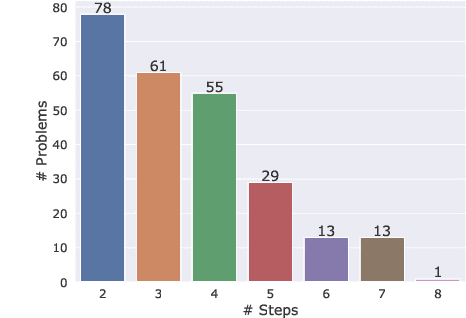
The ability to convey relevant and faithful information is critical for many tasks in conditional generation and yet remains elusive for neural seq-to-seq models whose outputs often reveal hallucinations and fail to correctly cover important details. In this work, we advocate planning as a useful intermediate representation for rendering conditional generation less opaque and more grounded. Our work proposes a new conceptualization of text plans as a sequence of question-answer (QA) pairs. We enhance existing datasets (e.g., for summarization) with a QA blueprint operating as a proxy for both content selection (i.e.,~what to say) and planning (i.e.,~in what order). We obtain blueprints automatically by exploiting state-of-the-art question generation technology and convert input-output pairs into input-blueprint-output tuples. We develop Transformer-based models, each varying in how they incorporate the blueprint in the generated output (e.g., as a global plan or iteratively). Evaluation across metrics and datasets demonstrates that blueprint models are more factual than alternatives which do not resort to planning and allow tighter control of the generation output.
A Well-Composed Text is Half Done! Composition Sampling for Diverse Conditional Generation
Mar 28, 2022
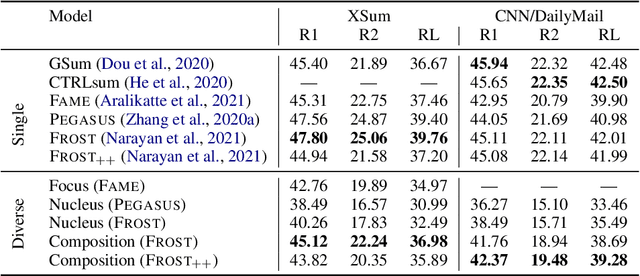

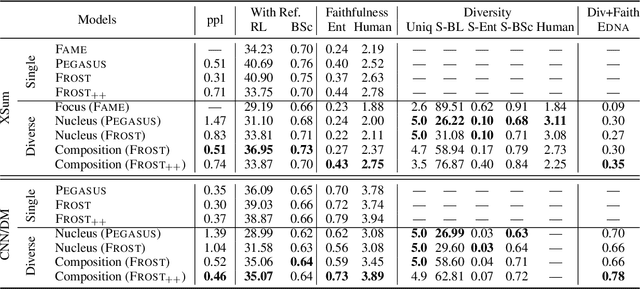
We propose Composition Sampling, a simple but effective method to generate diverse outputs for conditional generation of higher quality compared to previous stochastic decoding strategies. It builds on recently proposed plan-based neural generation models (Narayan et al, 2021) that are trained to first create a composition of the output and then generate by conditioning on it and the input. Our approach avoids text degeneration by first sampling a composition in the form of an entity chain and then using beam search to generate the best possible text grounded to this entity chain. Experiments on summarization (CNN/DailyMail and XSum) and question generation (SQuAD), using existing and newly proposed automatic metrics together with human-based evaluation, demonstrate that Composition Sampling is currently the best available decoding strategy for generating diverse meaningful outputs.
Measuring Attribution in Natural Language Generation Models
Dec 23, 2021

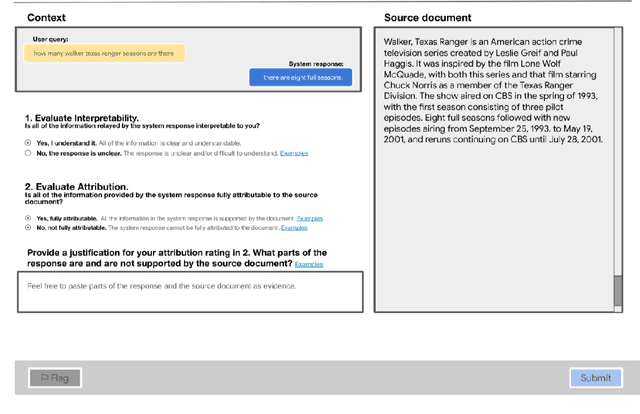
With recent improvements in natural language generation (NLG) models for various applications, it has become imperative to have the means to identify and evaluate whether NLG output is only sharing verifiable information about the external world. In this work, we present a new evaluation framework entitled Attributable to Identified Sources (AIS) for assessing the output of natural language generation models, when such output pertains to the external world. We first define AIS and introduce a two-stage annotation pipeline for allowing annotators to appropriately evaluate model output according to AIS guidelines. We empirically validate this approach on three generation datasets (two in the conversational QA domain and one in summarization) via human evaluation studies that suggest that AIS could serve as a common framework for measuring whether model-generated statements are supported by underlying sources. We release guidelines for the human evaluation studies.
Increasing Faithfulness in Knowledge-Grounded Dialogue with Controllable Features
Jul 14, 2021
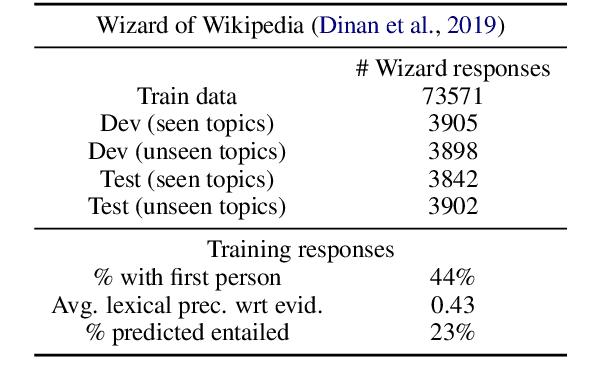
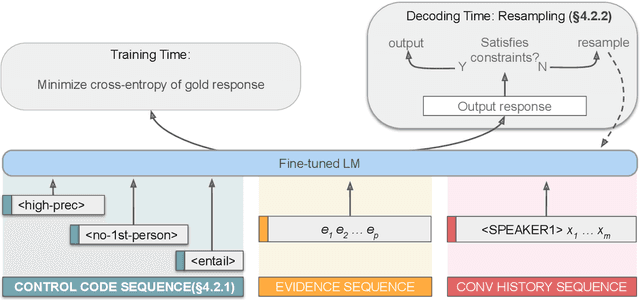
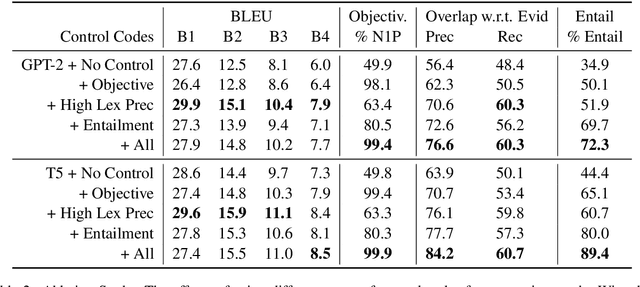
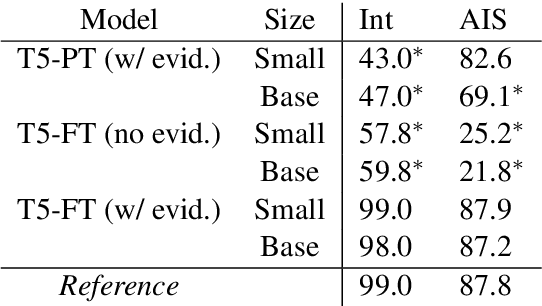
Knowledge-grounded dialogue systems are intended to convey information that is based on evidence provided in a given source text. We discuss the challenges of training a generative neural dialogue model for such systems that is controlled to stay faithful to the evidence. Existing datasets contain a mix of conversational responses that are faithful to selected evidence as well as more subjective or chit-chat style responses. We propose different evaluation measures to disentangle these different styles of responses by quantifying the informativeness and objectivity. At training time, additional inputs based on these evaluation measures are given to the dialogue model. At generation time, these additional inputs act as stylistic controls that encourage the model to generate responses that are faithful to the provided evidence. We also investigate the usage of additional controls at decoding time using resampling techniques. In addition to automatic metrics, we perform a human evaluation study where raters judge the output of these controlled generation models to be generally more objective and faithful to the evidence compared to baseline dialogue systems.
The MultiBERTs: BERT Reproductions for Robustness Analysis
Jun 30, 2021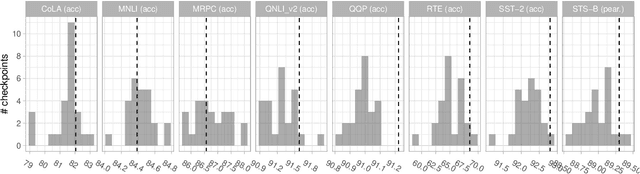
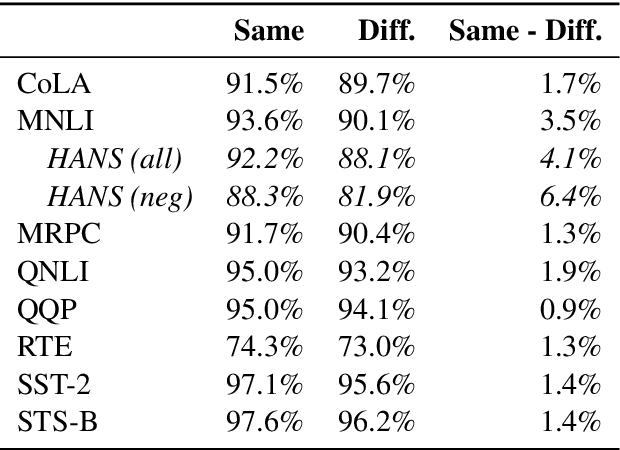
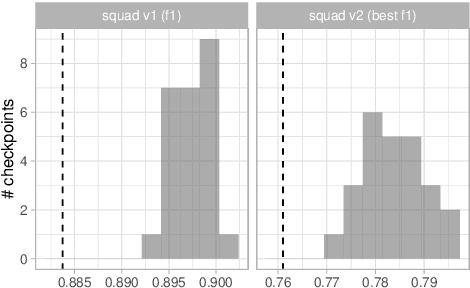
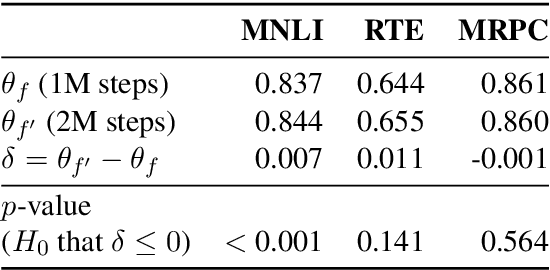
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.
Decontextualization: Making Sentences Stand-Alone
Feb 09, 2021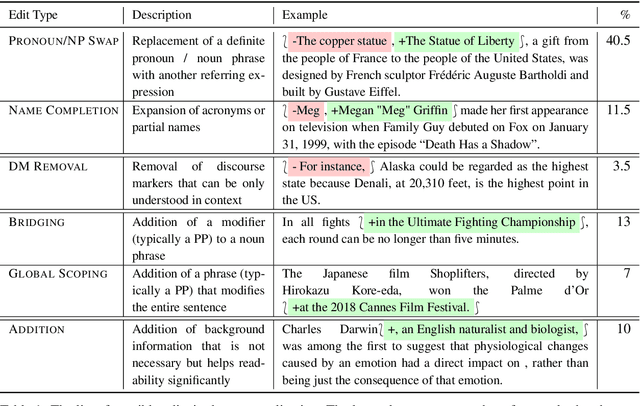


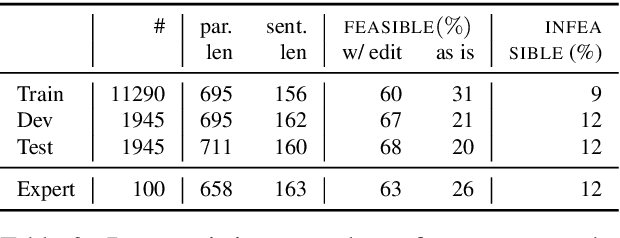
Models for question answering, dialogue agents, and summarization often interpret the meaning of a sentence in a rich context and use that meaning in a new context. Taking excerpts of text can be problematic, as key pieces may not be explicit in a local window. We isolate and define the problem of sentence decontextualization: taking a sentence together with its context and rewriting it to be interpretable out of context, while preserving its meaning. We describe an annotation procedure, collect data on the Wikipedia corpus, and use the data to train models to automatically decontextualize sentences. We present preliminary studies that show the value of sentence decontextualization in a user facing task, and as preprocessing for systems that perform document understanding. We argue that decontextualization is an important subtask in many downstream applications, and that the definitions and resources provided can benefit tasks that operate on sentences that occur in a richer context.