 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFM-RAG: Graph Foundation Model for Retrieval Augmented Generation
Feb 03, 2025



Retrieval-augmented generation (RAG) has proven effective in integrating knowledge into large language models (LLMs). However, conventional RAGs struggle to capture complex relationships between pieces of knowledge, limiting their performance in intricate reasoning that requires integrating knowledge from multiple sources. Recently, graph-enhanced retrieval augmented generation (GraphRAG) builds graph structure to explicitly model these relationships, enabling more effective and efficient retrievers. Nevertheless, its performance is still hindered by the noise and incompleteness within the graph structure. To address this, we introduce GFM-RAG, a novel graph foundation model (GFM) for retrieval augmented generation. GFM-RAG is powered by an innovative graph neural network that reasons over graph structure to capture complex query-knowledge relationships. The GFM with 8M parameters undergoes a two-stage training process on large-scale datasets, comprising 60 knowledge graphs with over 14M triples and 700k documents. This results in impressive performance and generalizability for GFM-RAG, making it the first graph foundation model applicable to unseen datasets for retrieval without any fine-tuning required. Extensive experiments on three multi-hop QA datasets and seven domain-specific RAG datasets demonstrate that GFM-RAG achieves state-of-the-art performance while maintaining efficiency and alignment with neural scaling laws, highlighting its potential for further improvement.
Fantastic Targets for Concept Erasure in Diffusion Models and Where To Find Them
Jan 31, 2025Concept erasure has emerged as a promising technique for mitigating the risk of harmful content generation in diffusion models by selectively unlearning undesirable concepts. The common principle of previous works to remove a specific concept is to map it to a fixed generic concept, such as a neutral concept or just an empty text prompt. In this paper, we demonstrate that this fixed-target strategy is suboptimal, as it fails to account for the impact of erasing one concept on the others. To address this limitation, we model the concept space as a graph and empirically analyze the effects of erasing one concept on the remaining concepts. Our analysis uncovers intriguing geometric properties of the concept space, where the influence of erasing a concept is confined to a local region. Building on this insight, we propose the Adaptive Guided Erasure (AGE) method, which \emph{dynamically} selects optimal target concepts tailored to each undesirable concept, minimizing unintended side effects. Experimental results show that AGE significantly outperforms state-of-the-art erasure methods on preserving unrelated concepts while maintaining effective erasure performance. Our code is published at {https://github.com/tuananhbui89/Adaptive-Guided-Erasure}.
PanSplat: 4K Panorama Synthesis with Feed-Forward Gaussian Splatting
Dec 16, 2024With the advent of portable 360{\deg} cameras, panorama has gained significant attention in applications like virtual reality (VR), virtual tours, robotics, and autonomous driving. As a result, wide-baseline panorama view synthesis has emerged as a vital task, where high resolution, fast inference, and memory efficiency are essential. Nevertheless, existing methods are typically constrained to lower resolutions (512 $\times$ 1024) due to demanding memory and computational requirements. In this paper, we present PanSplat, a generalizable, feed-forward approach that efficiently supports resolution up to 4K (2048 $\times$ 4096). Our approach features a tailored spherical 3D Gaussian pyramid with a Fibonacci lattice arrangement, enhancing image quality while reducing information redundancy. To accommodate the demands of high resolution, we propose a pipeline that integrates a hierarchical spherical cost volume and Gaussian heads with local operations, enabling two-step deferred backpropagation for memory-efficient training on a single A100 GPU. Experiments demonstrate that PanSplat achieves state-of-the-art results with superior efficiency and image quality across both synthetic and real-world datasets. Code will be available at \url{https://github.com/chengzhag/PanSplat}.
Large-Scale Data-Free Knowledge Distillation for ImageNet via Multi-Resolution Data Generation
Nov 26, 2024



Data-Free Knowledge Distillation (DFKD) is an advanced technique that enables knowledge transfer from a teacher model to a student model without relying on original training data. While DFKD methods have achieved success on smaller datasets like CIFAR10 and CIFAR100, they encounter challenges on larger, high-resolution datasets such as ImageNet. A primary issue with previous approaches is their generation of synthetic images at high resolutions (e.g., $224 \times 224$) without leveraging information from real images, often resulting in noisy images that lack essential class-specific features in large datasets. Additionally, the computational cost of generating the extensive data needed for effective knowledge transfer can be prohibitive. In this paper, we introduce MUlti-reSolution data-freE (MUSE) to address these limitations. MUSE generates images at lower resolutions while using Class Activation Maps (CAMs) to ensure that the generated images retain critical, class-specific features. To further enhance model diversity, we propose multi-resolution generation and embedding diversity techniques that strengthen latent space representations, leading to significant performance improvements. Experimental results demonstrate that MUSE achieves state-of-the-art performance across both small- and large-scale datasets, with notable performance gains of up to two digits in nearly all ImageNet and subset experiments. Code is available at https://github.com/tmtuan1307/muse.
Neural Topic Modeling with Large Language Models in the Loop
Nov 13, 2024Topic modeling is a fundamental task in natural language processing, allowing the discovery of latent thematic structures in text corpora. While Large Language Models (LLMs) have demonstrated promising capabilities in topic discovery, their direct application to topic modeling suffers from issues such as incomplete topic coverage, misalignment of topics, and inefficiency. To address these limitations, we propose LLM-ITL, a novel LLM-in-the-loop framework that integrates LLMs with many existing Neural Topic Models (NTMs). In LLM-ITL, global topics and document representations are learned through the NTM, while an LLM refines the topics via a confidence-weighted Optimal Transport (OT)-based alignment objective. This process enhances the interpretability and coherence of the learned topics, while maintaining the efficiency of NTMs. Extensive experiments demonstrate that LLM-ITL can help NTMs significantly improve their topic interpretability while maintaining the quality of document representation.
Erasing Undesirable Concepts in Diffusion Models with Adversarial Preservation
Oct 21, 2024



Diffusion models excel at generating visually striking content from text but can inadvertently produce undesirable or harmful content when trained on unfiltered internet data. A practical solution is to selectively removing target concepts from the model, but this may impact the remaining concepts. Prior approaches have tried to balance this by introducing a loss term to preserve neutral content or a regularization term to minimize changes in the model parameters, yet resolving this trade-off remains challenging. In this work, we propose to identify and preserving concepts most affected by parameter changes, termed as \textit{adversarial concepts}. This approach ensures stable erasure with minimal impact on the other concepts. We demonstrate the effectiveness of our method using the Stable Diffusion model, showing that it outperforms state-of-the-art erasure methods in eliminating unwanted content while maintaining the integrity of other unrelated elements. Our code is available at \url{https://github.com/tuananhbui89/Erasing-Adversarial-Preservation}.
Leveraging Hierarchical Taxonomies in Prompt-based Continual Learning
Oct 06, 2024



Drawing inspiration from human learning behaviors, this work proposes a novel approach to mitigate catastrophic forgetting in Prompt-based Continual Learning models by exploiting the relationships between continuously emerging class data. We find that applying human habits of organizing and connecting information can serve as an efficient strategy when training deep learning models. Specifically, by building a hierarchical tree structure based on the expanding set of labels, we gain fresh insights into the data, identifying groups of similar classes could easily cause confusion. Additionally, we delve deeper into the hidden connections between classes by exploring the original pretrained model's behavior through an optimal transport-based approach. From these insights, we propose a novel regularization loss function that encourages models to focus more on challenging knowledge areas, thereby enhancing overall performance. Experimentally, our method demonstrated significant superiority over the most robust state-of-the-art models on various benchmarks.
Improving Generalization with Flat Hilbert Bayesian Inference
Oct 05, 2024
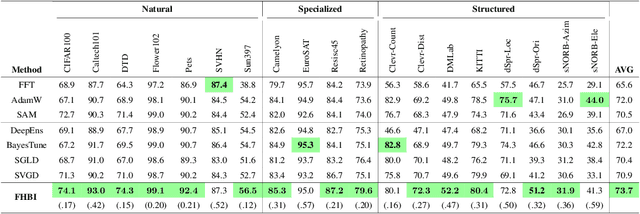
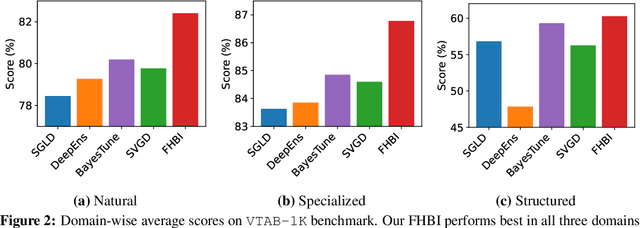

We introduce Flat Hilbert Bayesian Inference (FHBI), an algorithm designed to enhance generalization in Bayesian inference. Our approach involves an iterative two-step procedure with an adversarial functional perturbation step and a functional descent step within the reproducing kernel Hilbert spaces. This methodology is supported by a theoretical analysis that extends previous findings on generalization ability from finite-dimensional Euclidean spaces to infinite-dimensional functional spaces. To evaluate the effectiveness of FHBI, we conduct comprehensive comparisons against seven baseline methods on the VTAB-1K benchmark, which encompasses 19 diverse datasets across various domains with diverse semantics. Empirical results demonstrate that FHBI consistently outperforms the baselines by notable margins, highlighting its practical efficacy.
Connective Viewpoints of Signal-to-Noise Diffusion Models
Aug 08, 2024



Diffusion models (DM) have become fundamental components of generative models, excelling across various domains such as image creation, audio generation, and complex data interpolation. Signal-to-Noise diffusion models constitute a diverse family covering most state-of-the-art diffusion models. While there have been several attempts to study Signal-to-Noise (S2N) diffusion models from various perspectives, there remains a need for a comprehensive study connecting different viewpoints and exploring new perspectives. In this study, we offer a comprehensive perspective on noise schedulers, examining their role through the lens of the signal-to-noise ratio (SNR) and its connections to information theory. Building upon this framework, we have developed a generalized backward equation to enhance the performance of the inference process.
MetaAug: Meta-Data Augmentation for Post-Training Quantization
Jul 27, 2024



Post-Training Quantization (PTQ) has received significant attention because it requires only a small set of calibration data to quantize a full-precision model, which is more practical in real-world applications in which full access to a large training set is not available. However, it often leads to overfitting on the small calibration dataset. Several methods have been proposed to address this issue, yet they still rely on only the calibration set for the quantization and they do not validate the quantized model due to the lack of a validation set. In this work, we propose a novel meta-learning based approach to enhance the performance of post-training quantization. Specifically, to mitigate the overfitting problem, instead of only training the quantized model using the original calibration set without any validation during the learning process as in previous PTQ works, in our approach, we both train and validate the quantized model using two different sets of images. In particular, we propose a meta-learning based approach to jointly optimize a transformation network and a quantized model through bi-level optimization. The transformation network modifies the original calibration data and the modified data will be used as the training set to learn the quantized model with the objective that the quantized model achieves a good performance on the original calibration data. Extensive experiments on the widely used ImageNet dataset with different neural network architectures demonstrate that our approach outperforms the state-of-the-art PTQ methods.