 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriAlign: Towards Universal Truth Consistency in Personalized LLM Alignment
Jun 01, 2026Personalized large language models adapt responses to users' preferences and social attributes, but can introduce substantial universal truth inconsistencies across social groups, where some groups systematically receive less accurate responses on objective tasks. Existing alignment methods either ignore personalization or mainly focus on subjective preference alignment, largely overlooking fairness and consistency in universal truths. To address this gap, we study Truth-Invariant Alignment (TIA), an alignment problem for personalized LLMs that aims to ensure universal truths remain consistent across social groups while preserving personalization. We propose TriAlign, the first offline multi-agent reinforcement learning (MARL) framework for TIA, where each social group is modeled as an agent interacting. TriAlign jointly optimizes universal truth accuracy, cross-group truth consistency, and personalization through a fairness-aware objective and an explicit inconsistency penalty. Experiments across diverse benchmarks demonstrate that TriAlign achieves a stronger balance among these three objectives than strong baselines, reducing universal truth disparities across social groups while improving both objective task performance and personalization quality.
MATO: Multi-objective Personalized Alignment with Test-time Optimization for Large Language Models
May 25, 2026Aligning large language models (LLMs) with diverse and multifaceted user preferences is a fundamental challenge in personalized AI systems. Existing multi-objective alignment methods either rely on costly training or require pre-trained reward models for each preference, making it difficult for them to adapt to evolving preferences. Prompt-based personalization offers a training-free alternative, but prompting alone often provides limited steerability, as LLMs may overemphasize or overlook certain preferences and fail to give users reliable control over the relative importance of different objectives when conflicts arise, leading to suboptimal alignment. In this paper, we introduce MATO, a training-free framework for Multi-objective personalized Alignment with Test-time Optimization. MATO formulates personalization as a test-time optimization problem that steers the relative importance of multiple objectives through controllable weights during decoding, without modifying model parameters or requiring external reward models. Specifically, a reward discovery module recovers preference rewards directly from the backbone LLM for diverse objectives specified in natural language, while a weight optimization module dynamically adjusts objective weights based on the user's initial preferences and the partially generated response to balance competing objectives during generation. The resulting rewards and weights jointly guide an online optimization procedure over the token distribution, enabling better alignment with the target objectives. Extensive experiments across multiple datasets and backbone LLMs show that MATO consistently outperforms strong baselines, achieving Pareto-improving multi-objective alignment and stronger steerability. These results highlight test-time optimization as a promising direction for scalable, controllable, and model-agnostic personalized alignment.
Finding the Weakest Link: Adversarial Attack against Multi-Agent Communications
May 13, 2026Multi-agent systems rely on communication for information sharing and action coordination, which exposes a vulnerability to attacks. We investigate single-victim communication perturbation attacks against Multi-Agent Reinforcement Learning-trained systems and propose methods that use gradient information from the Jacobian to identify which messages, agent, and timesteps are most susceptible to attack and have the greatest impact on the system. We enhance these methods with two proposed adversarial loss functions that trade-off attack success for attack impact which also create more effective perturbations. We empirically demonstrate the effectiveness of our methods against two different multi-agent communication methods in navigation, PredatorPrey, and TrafficJunction environments. Our results show that our novel message selection method achieves a similar or greater impact than random message selection across almost all tested scenarios. Our victim selection, message selection, tempo, and loss functions improve attack effectiveness in half of the thirty scenarios we tested.
Fantastic Targets for Concept Erasure in Diffusion Models and Where To Find Them
Jan 31, 2025Concept erasure has emerged as a promising technique for mitigating the risk of harmful content generation in diffusion models by selectively unlearning undesirable concepts. The common principle of previous works to remove a specific concept is to map it to a fixed generic concept, such as a neutral concept or just an empty text prompt. In this paper, we demonstrate that this fixed-target strategy is suboptimal, as it fails to account for the impact of erasing one concept on the others. To address this limitation, we model the concept space as a graph and empirically analyze the effects of erasing one concept on the remaining concepts. Our analysis uncovers intriguing geometric properties of the concept space, where the influence of erasing a concept is confined to a local region. Building on this insight, we propose the Adaptive Guided Erasure (AGE) method, which \emph{dynamically} selects optimal target concepts tailored to each undesirable concept, minimizing unintended side effects. Experimental results show that AGE significantly outperforms state-of-the-art erasure methods on preserving unrelated concepts while maintaining effective erasure performance. Our code is published at {https://github.com/tuananhbui89/Adaptive-Guided-Erasure}.
A Survey on Adversarial Robustness of LiDAR-based Machine Learning Perception in Autonomous Vehicles
Nov 21, 2024In autonomous driving, the combination of AI and vehicular technology offers great potential. However, this amalgamation comes with vulnerabilities to adversarial attacks. This survey focuses on the intersection of Adversarial Machine Learning (AML) and autonomous systems, with a specific focus on LiDAR-based systems. We comprehensively explore the threat landscape, encompassing cyber-attacks on sensors and adversarial perturbations. Additionally, we investigate defensive strategies employed in countering these threats. This paper endeavors to present a concise overview of the challenges and advances in securing autonomous driving systems against adversarial threats, emphasizing the need for robust defenses to ensure safety and security.
EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection
Jul 27, 2024



Recently, deep learning has demonstrated promising results in enhancing the accuracy of vulnerability detection and identifying vulnerabilities in software. However, these techniques are still vulnerable to attacks. Adversarial examples can exploit vulnerabilities within deep neural networks, posing a significant threat to system security. This study showcases the susceptibility of deep learning models to adversarial attacks, which can achieve 100% attack success rate (refer to Table 5). The proposed method, EaTVul, encompasses six stages: identification of important samples using support vector machines, identification of important features using the attention mechanism, generation of adversarial data based on these features using ChatGPT, preparation of an adversarial attack pool, selection of seed data using a fuzzy genetic algorithm, and the execution of an evasion attack. Extensive experiments demonstrate the effectiveness of EaTVul, achieving an attack success rate of more than 83% when the snippet size is greater than 2. Furthermore, in most cases with a snippet size of 4, EaTVul achieves a 100% attack success rate. The findings of this research emphasize the necessity of robust defenses against adversarial attacks in software vulnerability detection.
Adversarial Robustness on Image Classification with $k$-means
Dec 15, 2023


In this paper we explore the challenges and strategies for enhancing the robustness of $k$-means clustering algorithms against adversarial manipulations. We evaluate the vulnerability of clustering algorithms to adversarial attacks, emphasising the associated security risks. Our study investigates the impact of incremental attack strength on training, introduces the concept of transferability between supervised and unsupervised models, and highlights the sensitivity of unsupervised models to sample distributions. We additionally introduce and evaluate an adversarial training method that improves testing performance in adversarial scenarios, and we highlight the importance of various parameters in the proposed training method, such as continuous learning, centroid initialisation, and adversarial step-count.
SoK: Adversarial Machine Learning Attacks and Defences in Multi-Agent Reinforcement Learning
Jan 11, 2023



Multi-Agent Reinforcement Learning (MARL) is vulnerable to Adversarial Machine Learning (AML) attacks and needs adequate defences before it can be used in real world applications. We have conducted a survey into the use of execution-time AML attacks against MARL and the defences against those attacks. We surveyed related work in the application of AML in Deep Reinforcement Learning (DRL) and Multi-Agent Learning (MAL) to inform our analysis of AML for MARL. We propose a novel perspective to understand the manner of perpetrating an AML attack, by defining Attack Vectors. We develop two new frameworks to address a gap in current modelling frameworks, focusing on the means and tempo of an AML attack against MARL, and identify knowledge gaps and future avenues of research.
Deep hierarchical reinforcement agents for automated penetration testing
Sep 14, 2021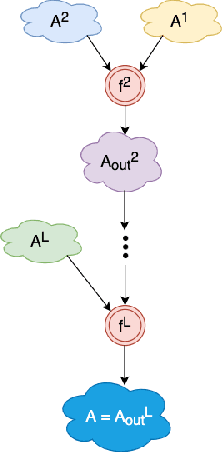
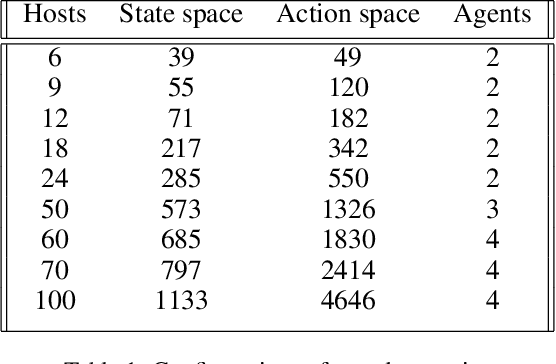
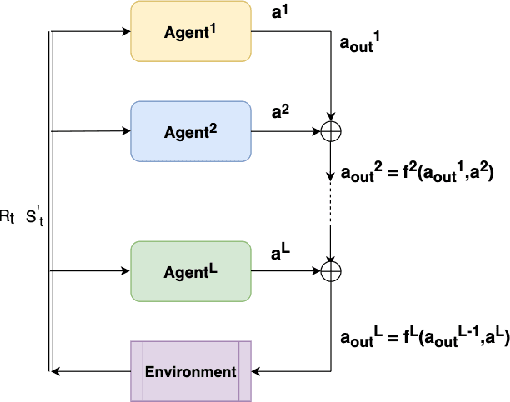
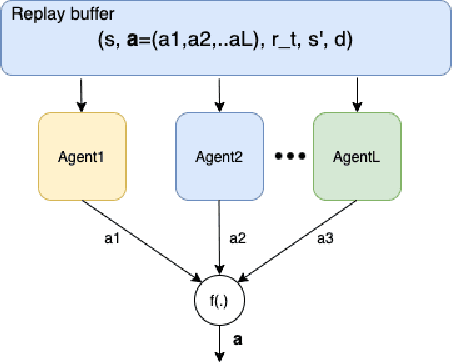
Penetration testing the organised attack of a computer system in order to test existing defences has been used extensively to evaluate network security. This is a time consuming process and requires in-depth knowledge for the establishment of a strategy that resembles a real cyber-attack. This paper presents a novel deep reinforcement learning architecture with hierarchically structured agents called HA-DRL, which employs an algebraic action decomposition strategy to address the large discrete action space of an autonomous penetration testing simulator where the number of actions is exponentially increased with the complexity of the designed cybersecurity network. The proposed architecture is shown to find the optimal attacking policy faster and more stably than a conventional deep Q-learning agent which is commonly used as a method to apply artificial intelligence in automatic penetration testing.
An Efficient Dual Approach to Distance Metric Learning
Feb 13, 2013
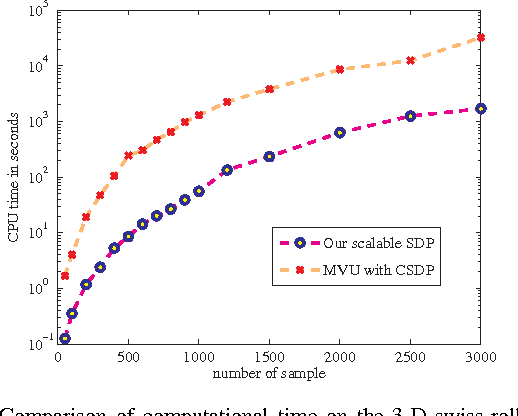
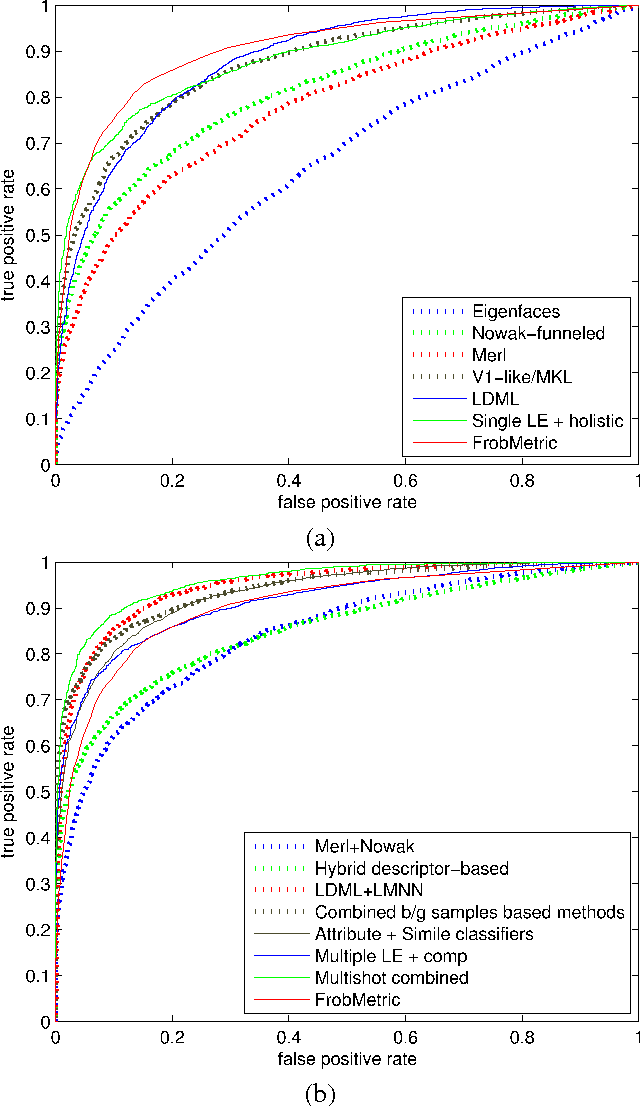

Distance metric learning is of fundamental interest in machine learning because the distance metric employed can significantly affect the performance of many learning methods. Quadratic Mahalanobis metric learning is a popular approach to the problem, but typically requires solving a semidefinite programming (SDP) problem, which is computationally expensive. Standard interior-point SDP solvers typically have a complexity of $O(D^{6.5})$ (with $D$ the dimension of input data), and can thus only practically solve problems exhibiting less than a few thousand variables. Since the number of variables is $D (D+1) / 2 $, this implies a limit upon the size of problem that can practically be solved of around a few hundred dimensions. The complexity of the popular quadratic Mahalanobis metric learning approach thus limits the size of problem to which metric learning can be applied. Here we propose a significantly more efficient approach to the metric learning problem based on the Lagrange dual formulation of the problem. The proposed formulation is much simpler to implement, and therefore allows much larger Mahalanobis metric learning problems to be solved. The time complexity of the proposed method is $O (D ^ 3) $, which is significantly lower than that of the SDP approach. Experiments on a variety of datasets demonstrate that the proposed method achieves an accuracy comparable to the state-of-the-art, but is applicable to significantly larger problems. We also show that the proposed method can be applied to solve more general Frobenius-norm regularized SDP problems approximately.