 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Clusters in Prompt Learning for Unsupervised Domain Adaptation
Jun 13, 2025Recent approaches leveraging multi-modal pre-trained models like CLIP for Unsupervised Domain Adaptation (UDA) have shown significant promise in bridging domain gaps and improving generalization by utilizing rich semantic knowledge and robust visual representations learned through extensive pre-training on diverse image-text datasets. While these methods achieve state-of-the-art performance across benchmarks, much of the improvement stems from base pseudo-labels (CLIP zero-shot predictions) and self-training mechanisms. Thus, the training mechanism exhibits a key limitation wherein the visual embedding distribution in target domains can deviate from the visual embedding distribution in the pre-trained model, leading to misguided signals from class descriptions. This work introduces a fresh solution to reinforce these pseudo-labels and facilitate target-prompt learning, by exploiting the geometry of visual and text embeddings - an aspect that is overlooked by existing methods. We first propose to directly leverage the reference predictions (from source prompts) based on the relationship between source and target visual embeddings. We later show that there is a strong clustering behavior observed between visual and text embeddings in pre-trained multi-modal models. Building on optimal transport theory, we transform this insight into a novel strategy to enforce the clustering property in text embeddings, further enhancing the alignment in the target domain. Our experiments and ablation studies validate the effectiveness of the proposed approach, demonstrating superior performance and improved quality of target prompts in terms of representation.
Fantastic Targets for Concept Erasure in Diffusion Models and Where To Find Them
Jan 31, 2025Concept erasure has emerged as a promising technique for mitigating the risk of harmful content generation in diffusion models by selectively unlearning undesirable concepts. The common principle of previous works to remove a specific concept is to map it to a fixed generic concept, such as a neutral concept or just an empty text prompt. In this paper, we demonstrate that this fixed-target strategy is suboptimal, as it fails to account for the impact of erasing one concept on the others. To address this limitation, we model the concept space as a graph and empirically analyze the effects of erasing one concept on the remaining concepts. Our analysis uncovers intriguing geometric properties of the concept space, where the influence of erasing a concept is confined to a local region. Building on this insight, we propose the Adaptive Guided Erasure (AGE) method, which \emph{dynamically} selects optimal target concepts tailored to each undesirable concept, minimizing unintended side effects. Experimental results show that AGE significantly outperforms state-of-the-art erasure methods on preserving unrelated concepts while maintaining effective erasure performance. Our code is published at {https://github.com/tuananhbui89/Adaptive-Guided-Erasure}.
Erasing Undesirable Concepts in Diffusion Models with Adversarial Preservation
Oct 21, 2024



Diffusion models excel at generating visually striking content from text but can inadvertently produce undesirable or harmful content when trained on unfiltered internet data. A practical solution is to selectively removing target concepts from the model, but this may impact the remaining concepts. Prior approaches have tried to balance this by introducing a loss term to preserve neutral content or a regularization term to minimize changes in the model parameters, yet resolving this trade-off remains challenging. In this work, we propose to identify and preserving concepts most affected by parameter changes, termed as \textit{adversarial concepts}. This approach ensures stable erasure with minimal impact on the other concepts. We demonstrate the effectiveness of our method using the Stable Diffusion model, showing that it outperforms state-of-the-art erasure methods in eliminating unwanted content while maintaining the integrity of other unrelated elements. Our code is available at \url{https://github.com/tuananhbui89/Erasing-Adversarial-Preservation}.
Diversity-Aware Agnostic Ensemble of Sharpness Minimizers
Mar 19, 2024



There has long been plenty of theoretical and empirical evidence supporting the success of ensemble learning. Deep ensembles in particular take advantage of training randomness and expressivity of individual neural networks to gain prediction diversity, ultimately leading to better generalization, robustness and uncertainty estimation. In respect of generalization, it is found that pursuing wider local minima result in models being more robust to shifts between training and testing sets. A natural research question arises out of these two approaches as to whether a boost in generalization ability can be achieved if ensemble learning and loss sharpness minimization are integrated. Our work investigates this connection and proposes DASH - a learning algorithm that promotes diversity and flatness within deep ensembles. More concretely, DASH encourages base learners to move divergently towards low-loss regions of minimal sharpness. We provide a theoretical backbone for our method along with extensive empirical evidence demonstrating an improvement in ensemble generalizability.
Removing Undesirable Concepts in Text-to-Image Generative Models with Learnable Prompts
Mar 18, 2024Generative models have demonstrated remarkable potential in generating visually impressive content from textual descriptions. However, training these models on unfiltered internet data poses the risk of learning and subsequently propagating undesirable concepts, such as copyrighted or unethical content. In this paper, we propose a novel method to remove undesirable concepts from text-to-image generative models by incorporating a learnable prompt into the cross-attention module. This learnable prompt acts as additional memory to transfer the knowledge of undesirable concepts into it and reduce the dependency of these concepts on the model parameters and corresponding textual inputs. Because of this knowledge transfer into the prompt, erasing these undesirable concepts is more stable and has minimal negative impact on other concepts. We demonstrate the effectiveness of our method on the Stable Diffusion model, showcasing its superiority over state-of-the-art erasure methods in terms of removing undesirable content while preserving other unrelated elements.
Robust Contrastive Learning With Theory Guarantee
Nov 16, 2023



Contrastive learning (CL) is a self-supervised training paradigm that allows us to extract meaningful features without any label information. A typical CL framework is divided into two phases, where it first tries to learn the features from unlabelled data, and then uses those features to train a linear classifier with the labeled data. While a fair amount of existing theoretical works have analyzed how the unsupervised loss in the first phase can support the supervised loss in the second phase, none has examined the connection between the unsupervised loss and the robust supervised loss, which can shed light on how to construct an effective unsupervised loss for the first phase of CL. To fill this gap, our work develops rigorous theories to dissect and identify which components in the unsupervised loss can help improve the robust supervised loss and conduct proper experiments to verify our findings.
Generating Adversarial Examples with Task Oriented Multi-Objective Optimization
Apr 26, 2023



Deep learning models, even the-state-of-the-art ones, are highly vulnerable to adversarial examples. Adversarial training is one of the most efficient methods to improve the model's robustness. The key factor for the success of adversarial training is the capability to generate qualified and divergent adversarial examples which satisfy some objectives/goals (e.g., finding adversarial examples that maximize the model losses for simultaneously attacking multiple models). Therefore, multi-objective optimization (MOO) is a natural tool for adversarial example generation to achieve multiple objectives/goals simultaneously. However, we observe that a naive application of MOO tends to maximize all objectives/goals equally, without caring if an objective/goal has been achieved yet. This leads to useless effort to further improve the goal-achieved tasks, while putting less focus on the goal-unachieved tasks. In this paper, we propose \emph{Task Oriented MOO} to address this issue, in the context where we can explicitly define the goal achievement for a task. Our principle is to only maintain the goal-achieved tasks, while letting the optimizer spend more effort on improving the goal-unachieved tasks. We conduct comprehensive experiments for our Task Oriented MOO on various adversarial example generation schemes. The experimental results firmly demonstrate the merit of our proposed approach. Our code is available at \url{https://github.com/tuananhbui89/TAMOO}.
Understanding and Achieving Efficient Robustness with Adversarial Contrastive Learning
Jan 25, 2021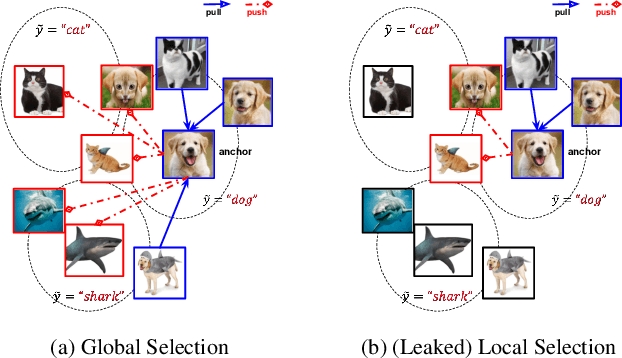

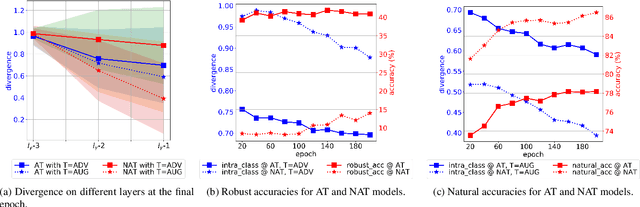
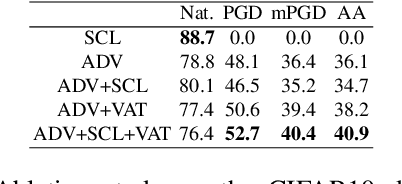
Contrastive learning (CL) has recently emerged as an effective approach to learning representation in a range of downstream tasks. Central to this approach is the selection of positive (similar) and negative (dissimilar) sets to provide the model the opportunity to `contrast' between data and class representation in the latent space. In this paper, we investigate CL for improving model robustness using adversarial samples. We first designed and performed a comprehensive study to understand how adversarial vulnerability behaves in the latent space. Based on these empirical evidences, we propose an effective and efficient supervised contrastive learning to achieve model robustness against adversarial attacks. Moreover, we propose a new sample selection strategy that optimizes the positive/negative sets by removing redundancy and improving correlation with the anchor. Experiments conducted on benchmark datasets show that our Adversarial Supervised Contrastive Learning (ASCL) approach outperforms the state-of-the-art defenses by $2.6\%$ in terms of the robust accuracy, whilst our ASCL with the proposed selection strategy can further gain $1.4\%$ improvement with only $42.8\%$ positives and $6.3\%$ negatives compared with ASCL without a selection strategy.
Improving Ensemble Robustness by Collaboratively Promoting and Demoting Adversarial Robustness
Sep 21, 2020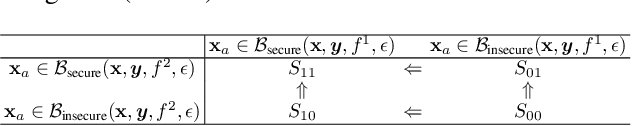
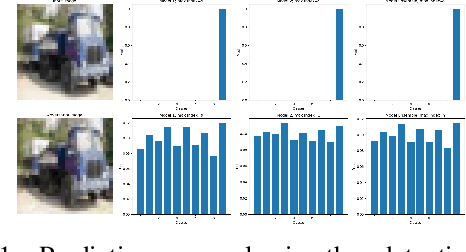
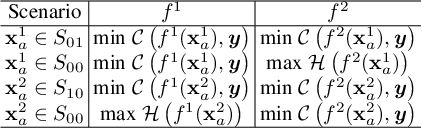
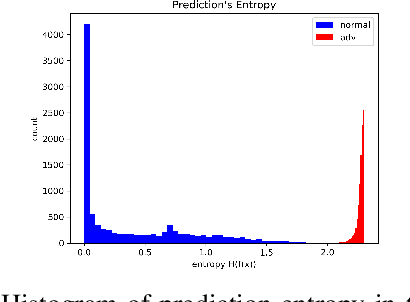
Ensemble-based adversarial training is a principled approach to achieve robustness against adversarial attacks. An important technique of this approach is to control the transferability of adversarial examples among ensemble members. We propose in this work a simple yet effective strategy to collaborate among committee models of an ensemble model. This is achieved via the secure and insecure sets defined for each model member on a given sample, hence help us to quantify and regularize the transferability. Consequently, our proposed framework provides the flexibility to reduce the adversarial transferability as well as to promote the diversity of ensemble members, which are two crucial factors for better robustness in our ensemble approach. We conduct extensive and comprehensive experiments to demonstrate that our proposed method outperforms the state-of-the-art ensemble baselines, at the same time can detect a wide range of adversarial examples with a nearly perfect accuracy.
Improving Adversarial Robustness by Enforcing Local and Global Compactness
Jul 10, 2020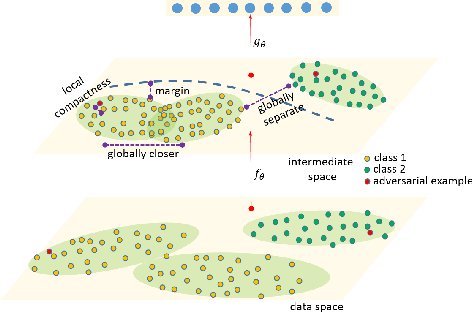
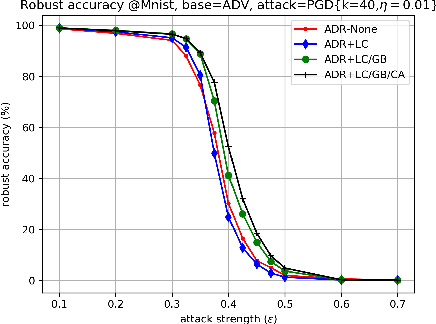
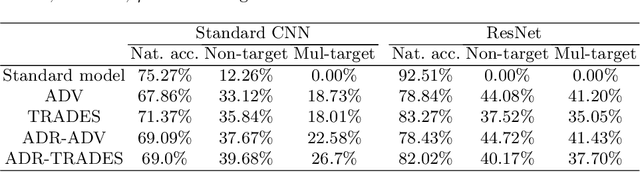
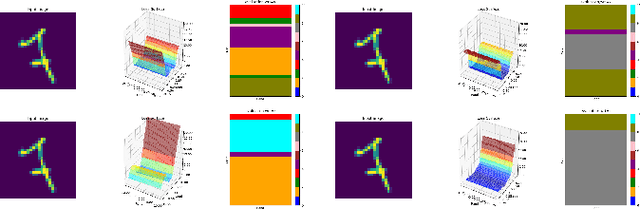
The fact that deep neural networks are susceptible to crafted perturbations severely impacts the use of deep learning in certain domains of application. Among many developed defense models against such attacks, adversarial training emerges as the most successful method that consistently resists a wide range of attacks. In this work, based on an observation from a previous study that the representations of a clean data example and its adversarial examples become more divergent in higher layers of a deep neural net, we propose the Adversary Divergence Reduction Network which enforces local/global compactness and the clustering assumption over an intermediate layer of a deep neural network. We conduct comprehensive experiments to understand the isolating behavior of each component (i.e., local/global compactness and the clustering assumption) and compare our proposed model with state-of-the-art adversarial training methods. The experimental results demonstrate that augmenting adversarial training with our proposed components can further improve the robustness of the network, leading to higher unperturbed and adversarial predictive performances.