 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnective Viewpoints of Signal-to-Noise Diffusion Models
Aug 08, 2024



Diffusion models (DM) have become fundamental components of generative models, excelling across various domains such as image creation, audio generation, and complex data interpolation. Signal-to-Noise diffusion models constitute a diverse family covering most state-of-the-art diffusion models. While there have been several attempts to study Signal-to-Noise (S2N) diffusion models from various perspectives, there remains a need for a comprehensive study connecting different viewpoints and exploring new perspectives. In this study, we offer a comprehensive perspective on noise schedulers, examining their role through the lens of the signal-to-noise ratio (SNR) and its connections to information theory. Building upon this framework, we have developed a generalized backward equation to enhance the performance of the inference process.
Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022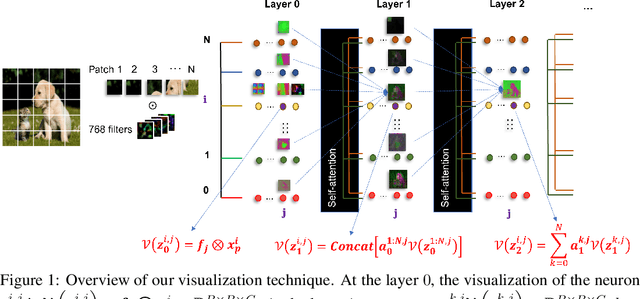
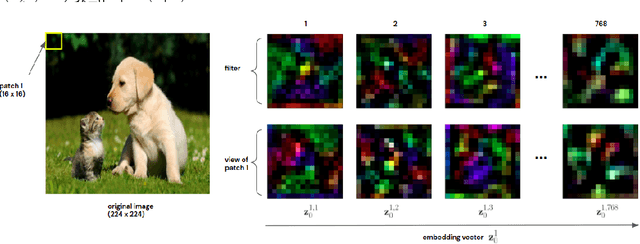


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization
MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation
Sep 19, 2022
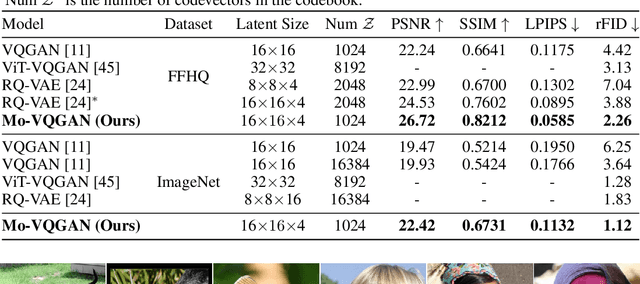
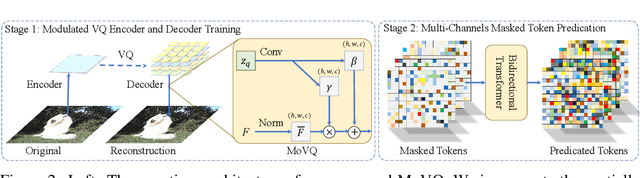
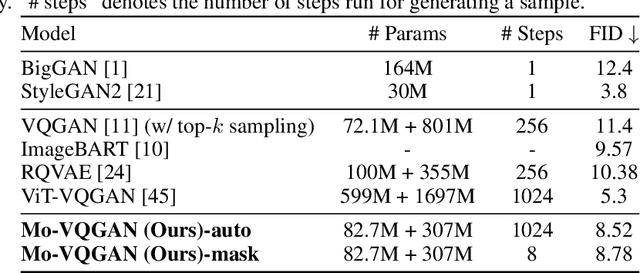
Although two-stage Vector Quantized (VQ) generative models allow for synthesizing high-fidelity and high-resolution images, their quantization operator encodes similar patches within an image into the same index, resulting in a repeated artifact for similar adjacent regions using existing decoder architectures. To address this issue, we propose to incorporate the spatially conditional normalization to modulate the quantized vectors so as to insert spatially variant information to the embedded index maps, encouraging the decoder to generate more photorealistic images. Moreover, we use multichannel quantization to increase the recombination capability of the discrete codes without increasing the cost of model and codebook. Additionally, to generate discrete tokens at the second stage, we adopt a Masked Generative Image Transformer (MaskGIT) to learn an underlying prior distribution in the compressed latent space, which is much faster than the conventional autoregressive model. Experiments on two benchmark datasets demonstrate that our proposed modulated VQGAN is able to greatly improve the reconstructed image quality as well as provide high-fidelity image generation.