 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Necessity of Chain of Thought through Opaque Serial Depth
Mar 10, 2026Large language models (LLMs) tend to externalize their reasoning in their chain of thought, making the chain of thought a good target for monitoring. This is partially an inherent feature of the Transformer architecture: sufficiently long serial cognition must pass through the chain of thought (Korbak et al., 2025). We formalize this argument through the notion of opaque serial depth, given by the length of the longest computation that can be done without the use of interpretable intermediate steps like chain of thought. Given this formalization, we compute numeric upper bounds on the opaque serial depth of Gemma 3 models, as well as asymptotic results for additional architectures beyond standard LLMs. We also open-source an automated method that can calculate upper bounds on the opaque serial depth of arbitrary neural networks, and use it to demonstrate that Mixture-of-Experts models likely have lower depth than dense models. Overall, our results suggest that opaque serial depth is a useful tool for understanding the potential for models to do significant reasoning that is not externalized.
Debate is efficient with your time
Feb 09, 2026AI safety via debate uses two competing models to help a human judge verify complex computational tasks. Previous work has established what problems debate can solve in principle, but has not analysed the practical cost of human oversight: how many queries must the judge make to the debate transcript? We introduce Debate Query Complexity}(DQC), the minimum number of bits a verifier must inspect to correctly decide a debate. Surprisingly, we find that PSPACE/poly (the class of problems which debate can efficiently decide) is precisely the class of functions decidable with O(log n) queries. This characterisation shows that debate is remarkably query-efficient: even for highly complex problems, logarithmic oversight suffices. We also establish that functions depending on all their input bits require Omega(log n) queries, and that any function computable by a circuit of size s satisfies DQC(f) <= log(s) + 3. Interestingly, this last result implies that proving DQC lower bounds of log(n) + 6 for languages in P would yield new circuit lower bounds, connecting debate query complexity to central questions in circuit complexity.
Avoiding Obfuscation with Prover-Estimator Debate
Jun 16, 2025Training powerful AI systems to exhibit desired behaviors hinges on the ability to provide accurate human supervision on increasingly complex tasks. A promising approach to this problem is to amplify human judgement by leveraging the power of two competing AIs in a debate about the correct solution to a given problem. Prior theoretical work has provided a complexity-theoretic formalization of AI debate, and posed the problem of designing protocols for AI debate that guarantee the correctness of human judgements for as complex a class of problems as possible. Recursive debates, in which debaters decompose a complex problem into simpler subproblems, hold promise for growing the class of problems that can be accurately judged in a debate. However, existing protocols for recursive debate run into the obfuscated arguments problem: a dishonest debater can use a computationally efficient strategy that forces an honest opponent to solve a computationally intractable problem to win. We mitigate this problem with a new recursive debate protocol that, under certain stability assumptions, ensures that an honest debater can win with a strategy requiring computational efficiency comparable to their opponent.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
On scalable oversight with weak LLMs judging strong LLMs
Jul 05, 2024



Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Scalable AI Safety via Doubly-Efficient Debate
Nov 23, 2023



The emergence of pre-trained AI systems with powerful capabilities across a diverse and ever-increasing set of complex domains has raised a critical challenge for AI safety as tasks can become too complicated for humans to judge directly. Irving et al. [2018] proposed a debate method in this direction with the goal of pitting the power of such AI models against each other until the problem of identifying (mis)-alignment is broken down into a manageable subtask. While the promise of this approach is clear, the original framework was based on the assumption that the honest strategy is able to simulate deterministic AI systems for an exponential number of steps, limiting its applicability. In this paper, we show how to address these challenges by designing a new set of debate protocols where the honest strategy can always succeed using a simulation of a polynomial number of steps, whilst being able to verify the alignment of stochastic AI systems, even when the dishonest strategy is allowed to use exponentially many simulation steps.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models
Oct 26, 2023



With LLMs shifting their role from statistical modeling of language to serving as general-purpose AI agents, how should LLM evaluations change? Arguably, a key ability of an AI agent is to flexibly combine, as needed, the basic skills it has learned. The capability to combine skills plays an important role in (human) pedagogy and also in a paper on emergence phenomena (Arora & Goyal, 2023). This work introduces Skill-Mix, a new evaluation to measure ability to combine skills. Using a list of $N$ skills the evaluator repeatedly picks random subsets of $k$ skills and asks the LLM to produce text combining that subset of skills. Since the number of subsets grows like $N^k$, for even modest $k$ this evaluation will, with high probability, require the LLM to produce text significantly different from any text in the training set. The paper develops a methodology for (a) designing and administering such an evaluation, and (b) automatic grading (plus spot-checking by humans) of the results using GPT-4 as well as the open LLaMA-2 70B model. Administering a version of to popular chatbots gave results that, while generally in line with prior expectations, contained surprises. Sizeable differences exist among model capabilities that are not captured by their ranking on popular LLM leaderboards ("cramming for the leaderboard"). Furthermore, simple probability calculations indicate that GPT-4's reasonable performance on $k=5$ is suggestive of going beyond "stochastic parrot" behavior (Bender et al., 2021), i.e., it combines skills in ways that it had not seen during training. We sketch how the methodology can lead to a Skill-Mix based eco-system of open evaluations for AI capabilities of future models.
Detecting Adversarial Directions in Deep Reinforcement Learning to Make Robust Decisions
Jun 09, 2023



Learning in MDPs with highly complex state representations is currently possible due to multiple advancements in reinforcement learning algorithm design. However, this incline in complexity, and furthermore the increase in the dimensions of the observation came at the cost of volatility that can be taken advantage of via adversarial attacks (i.e. moving along worst-case directions in the observation space). To solve this policy instability problem we propose a novel method to detect the presence of these non-robust directions via local quadratic approximation of the deep neural policy loss. Our method provides a theoretical basis for the fundamental cut-off between safe observations and adversarial observations. Furthermore, our technique is computationally efficient, and does not depend on the methods used to produce the worst-case directions. We conduct extensive experiments in the Arcade Learning Environment with several different adversarial attack techniques. Most significantly, we demonstrate the effectiveness of our approach even in the setting where non-robust directions are explicitly optimized to circumvent our proposed method.
Faster Algorithms and Constant Lower Bounds for the Worst-Case Expected Error
Dec 27, 2021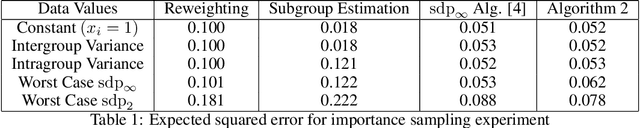


The study of statistical estimation without distributional assumptions on data values, but with knowledge of data collection methods was recently introduced by Chen, Valiant and Valiant (NeurIPS 2020). In this framework, the goal is to design estimators that minimize the worst-case expected error. Here the expectation is over a known, randomized data collection process from some population, and the data values corresponding to each element of the population are assumed to be worst-case. Chen, Valiant and Valiant show that, when data values are $\ell_{\infty}$-normalized, there is a polynomial time algorithm to compute an estimator for the mean with worst-case expected error that is within a factor $\frac{\pi}{2}$ of the optimum within the natural class of semilinear estimators. However, their algorithm is based on optimizing a somewhat complex concave objective function over a constrained set of positive semidefinite matrices, and thus does not come with explicit runtime guarantees beyond being polynomial time in the input. In this paper we design provably efficient algorithms for approximating the optimal semilinear estimator based on online convex optimization. In the setting where data values are $\ell_{\infty}$-normalized, our algorithm achieves a $\frac{\pi}{2}$-approximation by iteratively solving a sequence of standard SDPs. When data values are $\ell_2$-normalized, our algorithm iteratively computes the top eigenvector of a sequence of matrices, and does not lose any multiplicative approximation factor. We complement these positive results by stating a simple combinatorial condition which, if satisfied by a data collection process, implies that any (not necessarily semilinear) estimator for the mean has constant worst-case expected error.