 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Perimeter Defense via Multiview Pose Estimation
Sep 25, 2022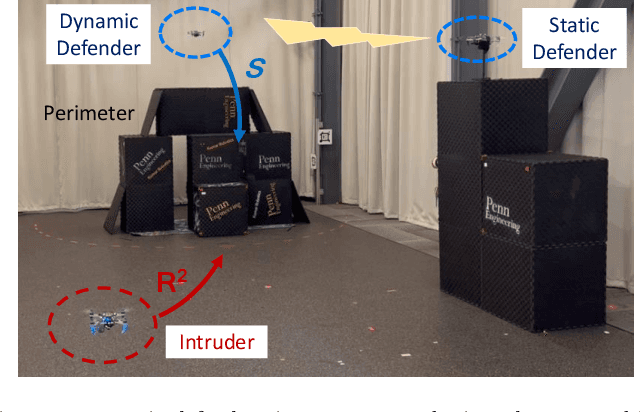
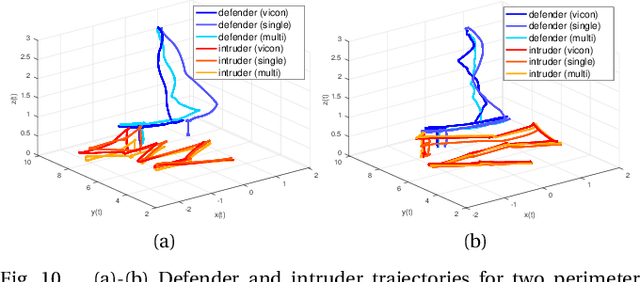
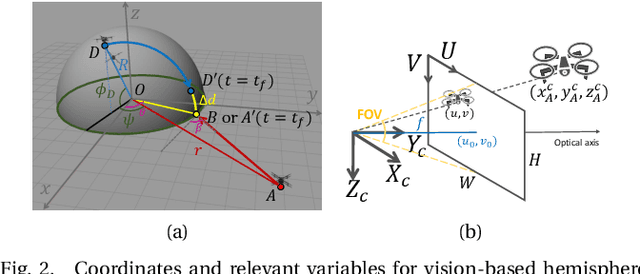
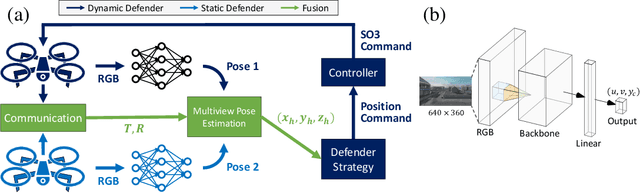
Previous studies in the perimeter defense game have largely focused on the fully observable setting where the true player states are known to all players. However, this is unrealistic for practical implementation since defenders may have to perceive the intruders and estimate their states. In this work, we study the perimeter defense game in a photo-realistic simulator and the real world, requiring defenders to estimate intruder states from vision. We train a deep machine learning-based system for intruder pose detection with domain randomization that aggregates multiple views to reduce state estimation errors and adapt the defensive strategy to account for this. We newly introduce performance metrics to evaluate the vision-based perimeter defense. Through extensive experiments, we show that our approach improves state estimation, and eventually, perimeter defense performance in both 1-defender-vs-1-intruder games, and 2-defenders-vs-1-intruder games.
Fighting Fire with Fire: Avoiding DNN Shortcuts through Priming
Jun 22, 2022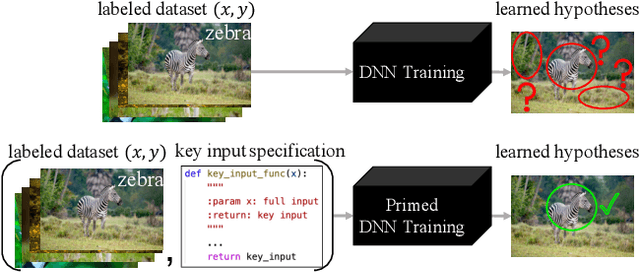

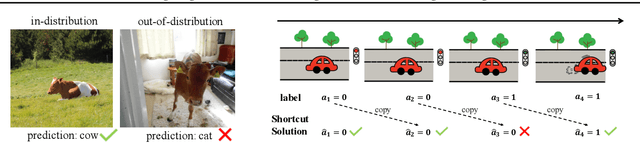
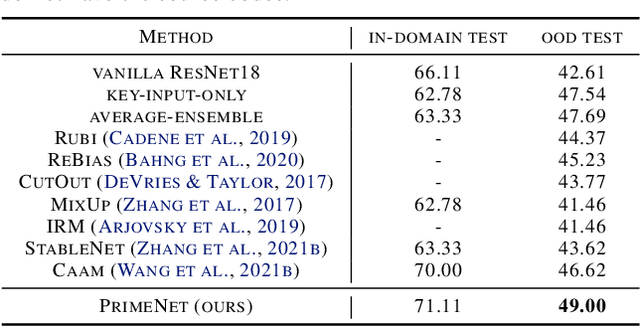
Across applications spanning supervised classification and sequential control, deep learning has been reported to find "shortcut" solutions that fail catastrophically under minor changes in the data distribution. In this paper, we show empirically that DNNs can be coaxed to avoid poor shortcuts by providing an additional "priming" feature computed from key input features, usually a coarse output estimate. Priming relies on approximate domain knowledge of these task-relevant key input features, which is often easy to obtain in practical settings. For example, one might prioritize recent frames over past frames in a video input for visual imitation learning, or salient foreground over background pixels for image classification. On NICO image classification, MuJoCo continuous control, and CARLA autonomous driving, our priming strategy works significantly better than several popular state-of-the-art approaches for feature selection and data augmentation. We connect these empirical findings to recent theoretical results on DNN optimization, and argue theoretically that priming distracts the optimizer away from poor shortcuts by creating better, simpler shortcuts.
How Far I'll Go: Offline Goal-Conditioned Reinforcement Learning via $f$-Advantage Regression
Jun 07, 2022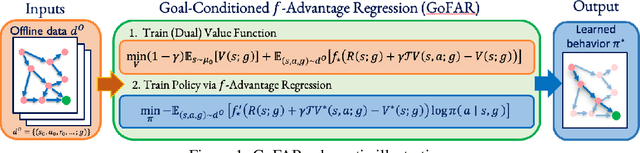
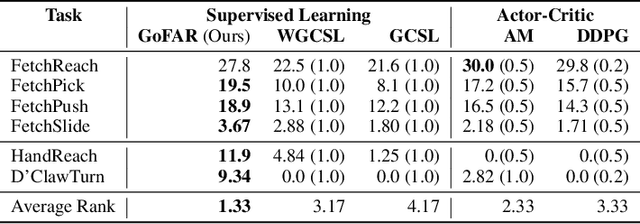

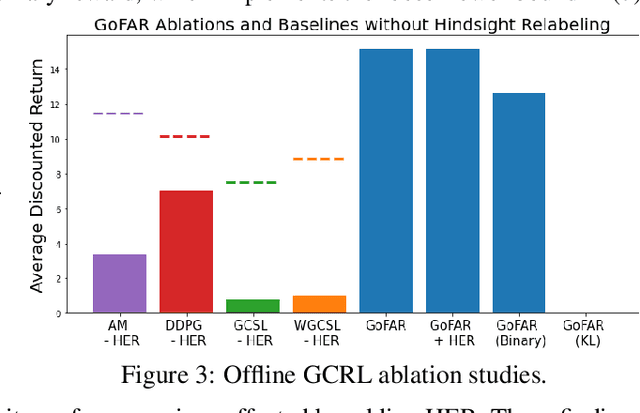
Offline goal-conditioned reinforcement learning (GCRL) promises general-purpose skill learning in the form of reaching diverse goals from purely offline datasets. We propose $\textbf{Go}$al-conditioned $f$-$\textbf{A}$dvantage $\textbf{R}$egression (GoFAR), a novel regression-based offline GCRL algorithm derived from a state-occupancy matching perspective; the key intuition is that the goal-reaching task can be formulated as a state-occupancy matching problem between a dynamics-abiding imitator agent and an expert agent that directly teleports to the goal. In contrast to prior approaches, GoFAR does not require any hindsight relabeling and enjoys uninterleaved optimization for its value and policy networks. These distinct features confer GoFAR with much better offline performance and stability as well as statistical performance guarantee that is unattainable for prior methods. Furthermore, we demonstrate that GoFAR's training objectives can be re-purposed to learn an agent-independent goal-conditioned planner from purely offline source-domain data, which enables zero-shot transfer to new target domains. Through extensive experiments, we validate GoFAR's effectiveness in various problem settings and tasks, significantly outperforming prior state-of-art. Notably, on a real robotic dexterous manipulation task, while no other method makes meaningful progress, GoFAR acquires complex manipulation behavior that successfully accomplishes diverse goals.
SMODICE: Versatile Offline Imitation Learning via State Occupancy Matching
Feb 04, 2022

We propose State Matching Offline DIstribution Correction Estimation (SMODICE), a novel and versatile algorithm for offline imitation learning (IL) via state-occupancy matching. We show that the SMODICE objective admits a simple optimization procedure through an application of Fenchel duality and an analytic solution in tabular MDPs. Without requiring access to expert actions, SMODICE can be effectively applied to three offline IL settings: (i) imitation from observations (IfO), (ii) IfO with dynamics or morphologically mismatched expert, and (iii) example-based reinforcement learning, which we show can be formulated as a state-occupancy matching problem. We extensively evaluate SMODICE on both gridworld environments as well as on high-dimensional offline benchmarks. Our results demonstrate that SMODICE is effective for all three problem settings and significantly outperforms prior state-of-art.
Prospective Learning: Back to the Future
Jan 19, 2022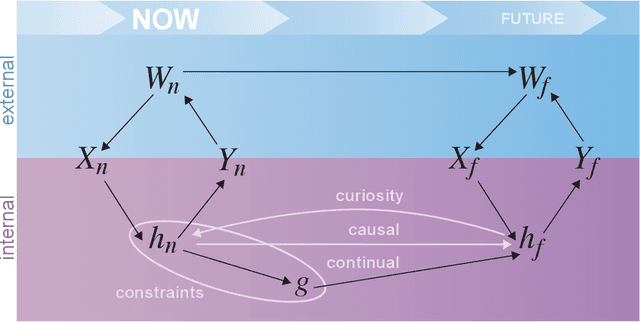

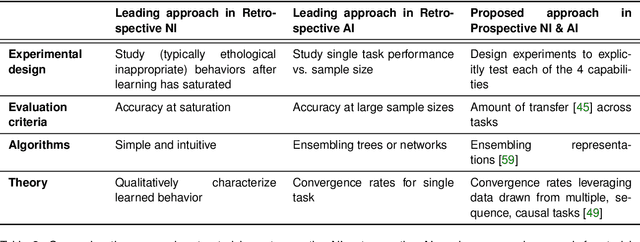
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning
Dec 14, 2021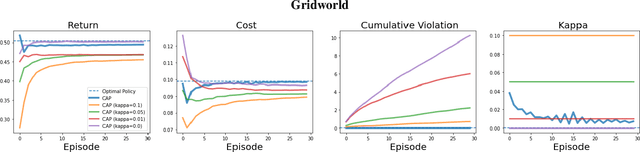
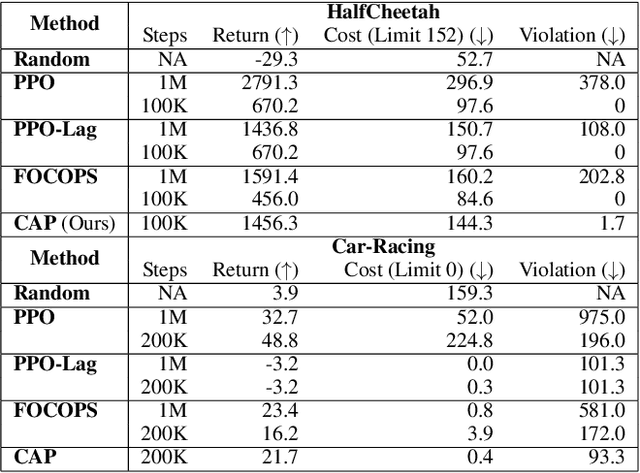
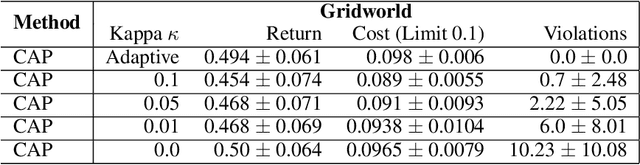
Reinforcement Learning (RL) agents in the real world must satisfy safety constraints in addition to maximizing a reward objective. Model-based RL algorithms hold promise for reducing unsafe real-world actions: they may synthesize policies that obey all constraints using simulated samples from a learned model. However, imperfect models can result in real-world constraint violations even for actions that are predicted to satisfy all constraints. We propose Conservative and Adaptive Penalty (CAP), a model-based safe RL framework that accounts for potential modeling errors by capturing model uncertainty and adaptively exploiting it to balance the reward and the cost objectives. First, CAP inflates predicted costs using an uncertainty-based penalty. Theoretically, we show that policies that satisfy this conservative cost constraint are guaranteed to also be feasible in the true environment. We further show that this guarantees the safety of all intermediate solutions during RL training. Further, CAP adaptively tunes this penalty during training using true cost feedback from the environment. We evaluate this conservative and adaptive penalty-based approach for model-based safe RL extensively on state and image-based environments. Our results demonstrate substantial gains in sample-efficiency while incurring fewer violations than prior safe RL algorithms. Code is available at: https://github.com/Redrew/CAP
Probabilistic Modeling for Human Mesh Recovery
Aug 26, 2021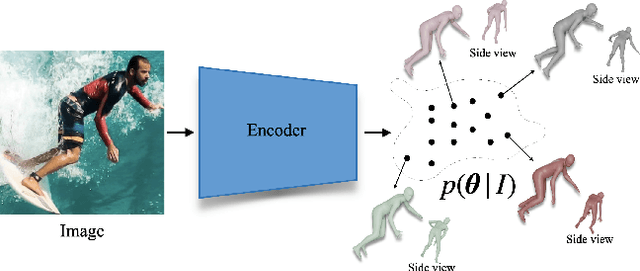
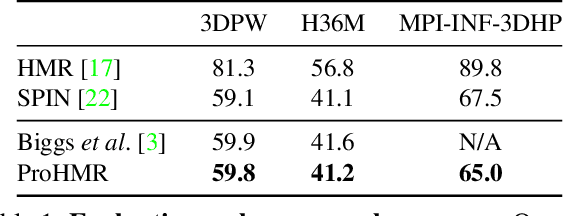
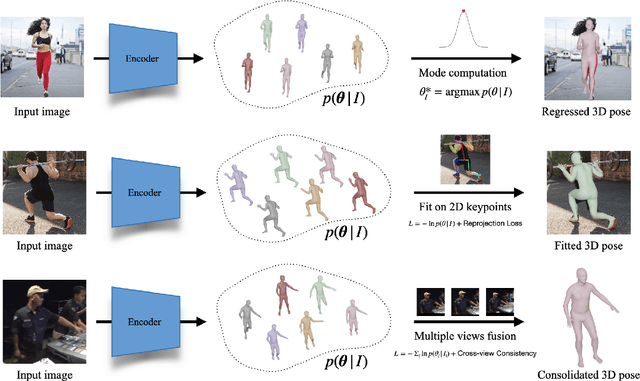
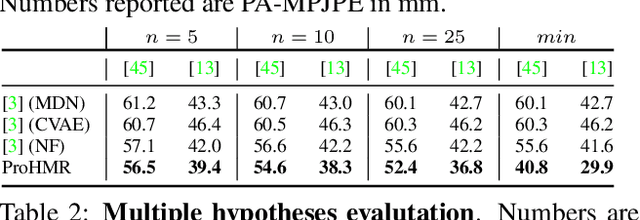
This paper focuses on the problem of 3D human reconstruction from 2D evidence. Although this is an inherently ambiguous problem, the majority of recent works avoid the uncertainty modeling and typically regress a single estimate for a given input. In contrast to that, in this work, we propose to embrace the reconstruction ambiguity and we recast the problem as learning a mapping from the input to a distribution of plausible 3D poses. Our approach is based on the normalizing flows model and offers a series of advantages. For conventional applications, where a single 3D estimate is required, our formulation allows for efficient mode computation. Using the mode leads to performance that is comparable with the state of the art among deterministic unimodal regression models. Simultaneously, since we have access to the likelihood of each sample, we demonstrate that our model is useful in a series of downstream tasks, where we leverage the probabilistic nature of the prediction as a tool for more accurate estimation. These tasks include reconstruction from multiple uncalibrated views, as well as human model fitting, where our model acts as a powerful image-based prior for mesh recovery. Our results validate the importance of probabilistic modeling, and indicate state-of-the-art performance across a variety of settings. Code and models are available at: https://www.seas.upenn.edu/~nkolot/projects/prohmr.
Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jul 28, 2021

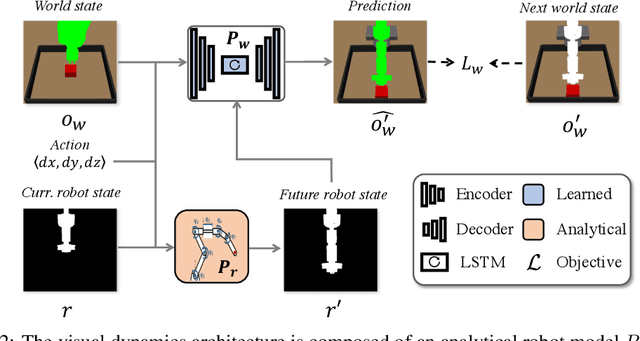
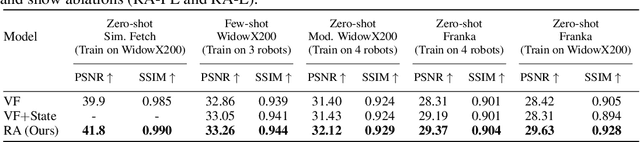
Training visuomotor robot controllers from scratch on a new robot typically requires generating large amounts of robot-specific data. Could we leverage data previously collected on another robot to reduce or even completely remove this need for robot-specific data? We propose a "robot-aware" solution paradigm that exploits readily available robot "self-knowledge" such as proprioception, kinematics, and camera calibration to achieve this. First, we learn modular dynamics models that pair a transferable, robot-agnostic world dynamics module with a robot-specific, analytical robot dynamics module. Next, we set up visual planning costs that draw a distinction between the robot self and the world. Our experiments on tabletop manipulation tasks in simulation and on real robots demonstrate that these plug-in improvements dramatically boost the transferability of visuomotor controllers, even permitting zero-shot transfer onto new robots for the very first time. Project website: https://hueds.github.io/rac/
Conservative Offline Distributional Reinforcement Learning
Jul 12, 2021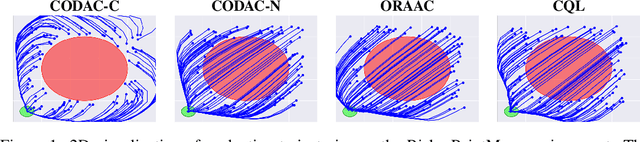


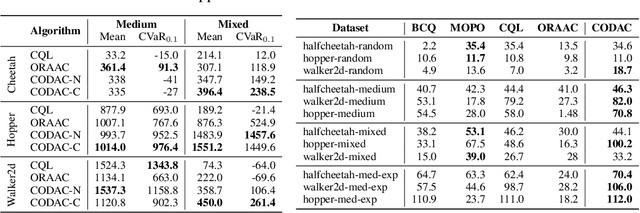
Many reinforcement learning (RL) problems in practice are offline, learning purely from observational data. A key challenge is how to ensure the learned policy is safe, which requires quantifying the risk associated with different actions. In the online setting, distributional RL algorithms do so by learning the distribution over returns (i.e., cumulative rewards) instead of the expected return; beyond quantifying risk, they have also been shown to learn better representations for planning. We propose Conservative Offline Distributional Actor Critic (CODAC), an offline RL algorithm suitable for both risk-neutral and risk-averse domains. CODAC adapts distributional RL to the offline setting by penalizing the predicted quantiles of the return for out-of-distribution actions. We prove that CODAC learns a conservative return distribution -- in particular, for finite MDPs, CODAC converges to an uniform lower bound on the quantiles of the return distribution; our proof relies on a novel analysis of the distributional Bellman operator. In our experiments, on two challenging robot navigation tasks, CODAC successfully learns risk-averse policies using offline data collected purely from risk-neutral agents. Furthermore, CODAC is state-of-the-art on the D4RL MuJoCo benchmark in terms of both expected and risk-sensitive performance.
Keyframe-Focused Visual Imitation Learning
Jun 11, 2021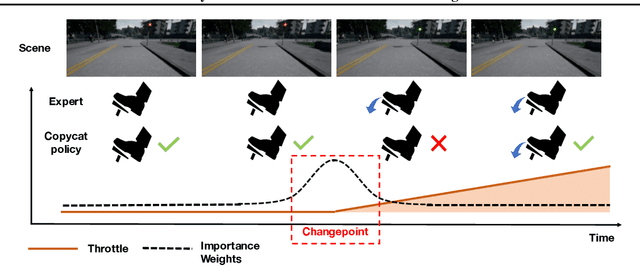
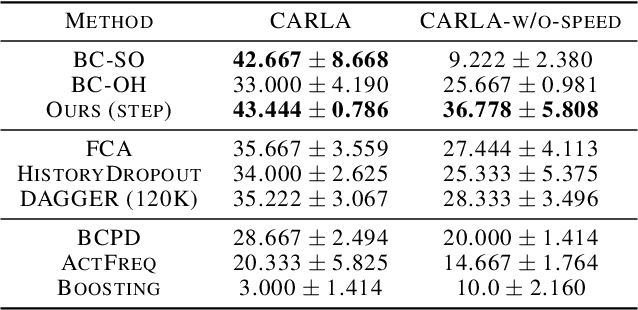
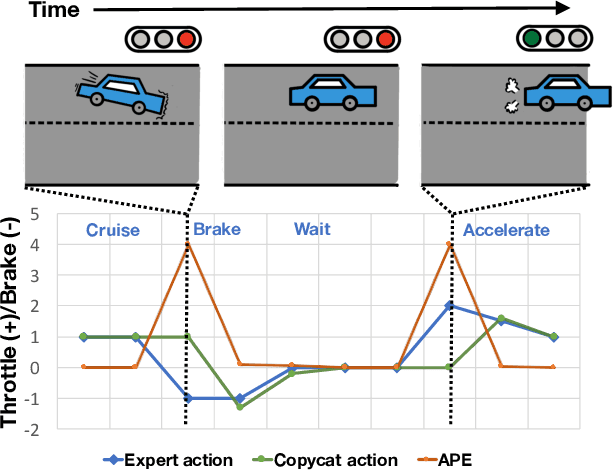

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.