 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Visual Decomposer: Long-Horizon Manipulation Made Easy
Oct 12, 2023



Real-world robotic tasks stretch over extended horizons and encompass multiple stages. Learning long-horizon manipulation tasks, however, is a long-standing challenge, and demands decomposing the overarching task into several manageable subtasks to facilitate policy learning and generalization to unseen tasks. Prior task decomposition methods require task-specific knowledge, are computationally intensive, and cannot readily be applied to new tasks. To address these shortcomings, we propose Universal Visual Decomposer (UVD), an off-the-shelf task decomposition method for visual long horizon manipulation using pre-trained visual representations designed for robotic control. At a high level, UVD discovers subgoals by detecting phase shifts in the embedding space of the pre-trained representation. Operating purely on visual demonstrations without auxiliary information, UVD can effectively extract visual subgoals embedded in the videos, while incurring zero additional training cost on top of standard visuomotor policy training. Goal-conditioned policies learned with UVD-discovered subgoals exhibit significantly improved compositional generalization at test time to unseen tasks. Furthermore, UVD-discovered subgoals can be used to construct goal-based reward shaping that jump-starts temporally extended exploration for reinforcement learning. We extensively evaluate UVD on both simulation and real-world tasks, and in all cases, UVD substantially outperforms baselines across imitation and reinforcement learning settings on in-domain and out-of-domain task sequences alike, validating the clear advantage of automated visual task decomposition within the simple, compact UVD framework.
Memory-Consistent Neural Networks for Imitation Learning
Oct 09, 2023Imitation learning considerably simplifies policy synthesis compared to alternative approaches by exploiting access to expert demonstrations. For such imitation policies, errors away from the training samples are particularly critical. Even rare slip-ups in the policy action outputs can compound quickly over time, since they lead to unfamiliar future states where the policy is still more likely to err, eventually causing task failures. We revisit simple supervised ``behavior cloning'' for conveniently training the policy from nothing more than pre-recorded demonstrations, but carefully design the model class to counter the compounding error phenomenon. Our ``memory-consistent neural network'' (MCNN) outputs are hard-constrained to stay within clearly specified permissible regions anchored to prototypical ``memory'' training samples. We provide a guaranteed upper bound for the sub-optimality gap induced by MCNN policies. Using MCNNs on 9 imitation learning tasks, with MLP, Transformer, and Diffusion backbones, spanning dexterous robotic manipulation and driving, proprioceptive inputs and visual inputs, and varying sizes and types of demonstration data, we find large and consistent gains in performance, validating that MCNNs are better-suited than vanilla deep neural networks for imitation learning applications. Website: https://sites.google.com/view/mcnn-imitation
LIV: Language-Image Representations and Rewards for Robotic Control
Jun 01, 2023



We present Language-Image Value learning (LIV), a unified objective for vision-language representation and reward learning from action-free videos with text annotations. Exploiting a novel connection between dual reinforcement learning and mutual information contrastive learning, the LIV objective trains a multi-modal representation that implicitly encodes a universal value function for tasks specified as language or image goals. We use LIV to pre-train the first control-centric vision-language representation from large human video datasets such as EpicKitchen. Given only a language or image goal, the pre-trained LIV model can assign dense rewards to each frame in videos of unseen robots or humans attempting that task in unseen environments. Further, when some target domain-specific data is available, the same objective can be used to fine-tune and improve LIV and even other pre-trained representations for robotic control and reward specification in that domain. In our experiments on several simulated and real-world robot environments, LIV models consistently outperform the best prior input state representations for imitation learning, as well as reward specification methods for policy synthesis. Our results validate the advantages of joint vision-language representation and reward learning within the unified, compact LIV framework.
ZeroFlow: Fast Zero Label Scene Flow via Distillation
May 23, 2023



Scene flow estimation is the task of describing the 3D motion field between temporally successive point clouds. State-of-the-art methods use strong priors and test-time optimization techniques, but require on the order of tens of seconds for large-scale point clouds, making them unusable as computer vision primitives for real-time applications such as open world object detection. Feed forward methods are considerably faster, running on the order of tens to hundreds of milliseconds for large-scale point clouds, but require expensive human supervision. To address both limitations, we propose Scene Flow via Distillation, a simple distillation framework that uses a label-free optimization method to produce pseudo-labels to supervise a feed forward model. Our instantiation of this framework, ZeroFlow, produces scene flow estimates in real-time on large-scale point clouds at quality competitive with state-of-the-art methods while using zero human labels. Notably, at test-time ZeroFlow is over 1000$\times$ faster than label-free state-of-the-art optimization-based methods on large-scale point clouds and over 1000$\times$ cheaper to train on unlabeled data compared to the cost of human annotation of that data. To facilitate research reuse, we release our code, trained model weights, and high quality pseudo-labels for the Argoverse 2 and Waymo Open datasets.
TOM: Learning Policy-Aware Models for Model-Based Reinforcement Learning via Transition Occupancy Matching
May 22, 2023Standard model-based reinforcement learning (MBRL) approaches fit a transition model of the environment to all past experience, but this wastes model capacity on data that is irrelevant for policy improvement. We instead propose a new "transition occupancy matching" (TOM) objective for MBRL model learning: a model is good to the extent that the current policy experiences the same distribution of transitions inside the model as in the real environment. We derive TOM directly from a novel lower bound on the standard reinforcement learning objective. To optimize TOM, we show how to reduce it to a form of importance weighted maximum-likelihood estimation, where the automatically computed importance weights identify policy-relevant past experiences from a replay buffer, enabling stable optimization. TOM thus offers a plug-and-play model learning sub-routine that is compatible with any backbone MBRL algorithm. On various Mujoco continuous robotic control tasks, we show that TOM successfully focuses model learning on policy-relevant experience and drives policies faster to higher task rewards than alternative model learning approaches.
Planning Goals for Exploration
Mar 23, 2023



Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it? We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "Planning Exploratory Goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward. PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command. Website: https://penn-pal-lab.github.io/peg/
Learning a Meta-Controller for Dynamic Grasping
Feb 16, 2023



Grasping moving objects is a challenging task that combines multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters either heuristically or through grid search; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene. In this work, we learn a meta-controller through reinforcement learning to control the look-ahead time and time budget dynamically. Our extensive experiments show that the meta-controller improves the grasping success rate (up to 12% in the most cluttered environment) and reduces grasping time, compared to the strongest baseline. Our meta-controller learns to reason about the reachable workspace and maintain the predicted pose within the reachable region. In addition, it assigns a small but sufficient time budget for the motion planner. Our method can handle different target objects, trajectories, and obstacles. Despite being trained only with 3-6 randomly generated cuboidal obstacles, our meta-controller generalizes well to 7-9 obstacles and more realistic out-of-domain household setups with unseen obstacle shapes. Video is available at https://youtu.be/CwHq77wFQqI.
Training Robots to Evaluate Robots: Example-Based Interactive Reward Functions for Policy Learning
Dec 17, 2022



Physical interactions can often help reveal information that is not readily apparent. For example, we may tug at a table leg to evaluate whether it is built well, or turn a water bottle upside down to check that it is watertight. We propose to train robots to acquire such interactive behaviors automatically, for the purpose of evaluating the result of an attempted robotic skill execution. These evaluations in turn serve as "interactive reward functions" (IRFs) for training reinforcement learning policies to perform the target skill, such as screwing the table leg tightly. In addition, even after task policies are fully trained, IRFs can serve as verification mechanisms that improve online task execution. For any given task, our IRFs can be conveniently trained using only examples of successful outcomes, and no further specification is needed to train the task policy thereafter. In our evaluations on door locking and weighted block stacking in simulation, and screw tightening on a real robot, IRFs enable large performance improvements, even outperforming baselines with access to demonstrations or carefully engineered rewards. Project website: https://sites.google.com/view/lirf-corl-2022/
Long-HOT: A Modular Hierarchical Approach for Long-Horizon Object Transport
Oct 28, 2022


We address key challenges in long-horizon embodied exploration and navigation by proposing a new object transport task and a novel modular framework for temporally extended navigation. Our first contribution is the design of a novel Long-HOT environment focused on deep exploration and long-horizon planning where the agent is required to efficiently find and pick up target objects to be carried and dropped at a goal location, with load constraints and optional access to a container if it finds one. Further, we propose a modular hierarchical transport policy (HTP) that builds a topological graph of the scene to perform exploration with the help of weighted frontiers. Our hierarchical approach uses a combination of motion planning algorithms to reach point goals within explored locations and object navigation policies for moving towards semantic targets at unknown locations. Experiments on both our proposed Habitat transport task and on MultiOn benchmarks show that our method significantly outperforms baselines and prior works. Further, we validate the effectiveness of our modular approach for long-horizon transport by demonstrating meaningful generalization to much harder transport scenes with training only on simpler versions of the task.
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Sep 30, 2022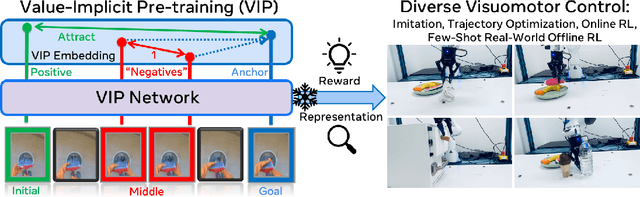

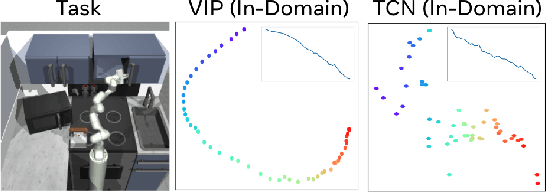
Reward and representation learning are two long-standing challenges for learning an expanding set of robot manipulation skills from sensory observations. Given the inherent cost and scarcity of in-domain, task-specific robot data, learning from large, diverse, offline human videos has emerged as a promising path towards acquiring a generally useful visual representation for control; however, how these human videos can be used for general-purpose reward learning remains an open question. We introduce $\textbf{V}$alue-$\textbf{I}$mplicit $\textbf{P}$re-training (VIP), a self-supervised pre-trained visual representation capable of generating dense and smooth reward functions for unseen robotic tasks. VIP casts representation learning from human videos as an offline goal-conditioned reinforcement learning problem and derives a self-supervised dual goal-conditioned value-function objective that does not depend on actions, enabling pre-training on unlabeled human videos. Theoretically, VIP can be understood as a novel implicit time contrastive objective that generates a temporally smooth embedding, enabling the value function to be implicitly defined via the embedding distance, which can then be used to construct the reward for any goal-image specified downstream task. Trained on large-scale Ego4D human videos and without any fine-tuning on in-domain, task-specific data, VIP's frozen representation can provide dense visual reward for an extensive set of simulated and $\textbf{real-robot}$ tasks, enabling diverse reward-based visual control methods and significantly outperforming all prior pre-trained representations. Notably, VIP can enable simple, $\textbf{few-shot}$ offline RL on a suite of real-world robot tasks with as few as 20 trajectories.