 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Guided Unsupervised Multi-domain Image-to-Image Translation
Aug 11, 2020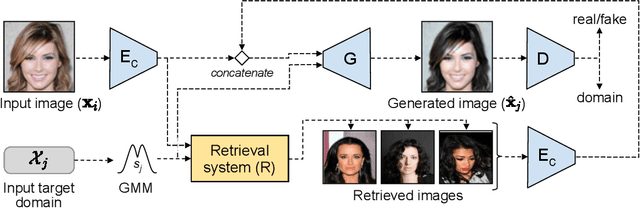
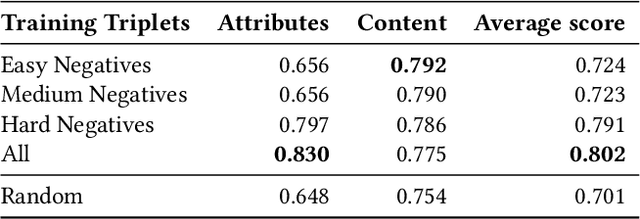
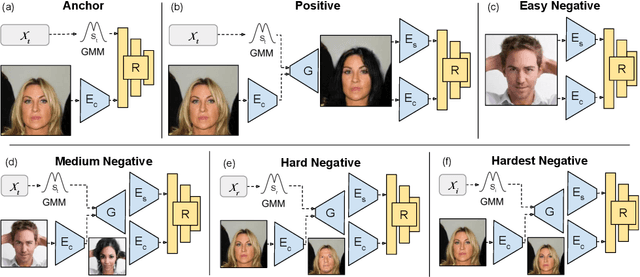
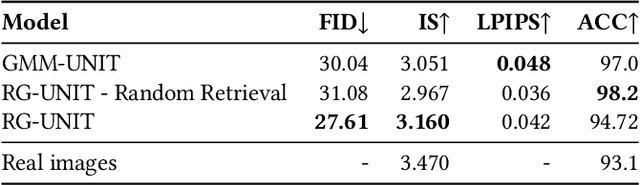
Image to image translation aims to learn a mapping that transforms an image from one visual domain to another. Recent works assume that images descriptors can be disentangled into a domain-invariant content representation and a domain-specific style representation. Thus, translation models seek to preserve the content of source images while changing the style to a target visual domain. However, synthesizing new images is extremely challenging especially in multi-domain translations, as the network has to compose content and style to generate reliable and diverse images in multiple domains. In this paper we propose the use of an image retrieval system to assist the image-to-image translation task. First, we train an image-to-image translation model to map images to multiple domains. Then, we train an image retrieval model using real and generated images to find images similar to a query one in content but in a different domain. Finally, we exploit the image retrieval system to fine-tune the image-to-image translation model and generate higher quality images. Our experiments show the effectiveness of the proposed solution and highlight the contribution of the retrieval network, which can benefit from additional unlabeled data and help image-to-image translation models in the presence of scarce data.
Text Recognition -- Real World Data and Where to Find Them
Jul 17, 2020



We present a method for exploiting weakly annotated images to improve text extraction pipelines. The approach uses an arbitrary end-to-end text recognition system to obtain text region proposals and their, possibly erroneous, transcriptions. The proposed method includes matching of imprecise transcription to weak annotations and edit distance guided neighbourhood search. It produces nearly error-free, localised instances of scene text, which we treat as "pseudo ground truth" (PGT). We apply the method to two weakly-annotated datasets. Training with the extracted PGT consistently improves the accuracy of a state of the art recognition model, by 3.7~\% on average, across different benchmark datasets (image domains) and 24.5~\% on one of the weakly annotated datasets.
Location Sensitive Image Retrieval and Tagging
Jul 07, 2020
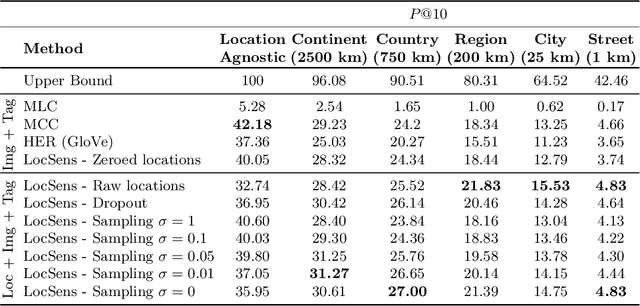

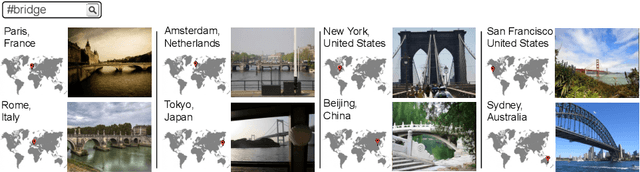
People from different parts of the globe describe objects and concepts in distinct manners. Visual appearance can thus vary across different geographic locations, which makes location a relevant contextual information when analysing visual data. In this work, we address the task of image retrieval related to a given tag conditioned on a certain location on Earth. We present LocSens, a model that learns to rank triplets of images, tags and coordinates by plausibility, and two training strategies to balance the location influence in the final ranking. LocSens learns to fuse textual and location information of multimodal queries to retrieve related images at different levels of location granularity, and successfully utilizes location information to improve image tagging.
DocVQA: A Dataset for VQA on Document Images
Jul 01, 2020
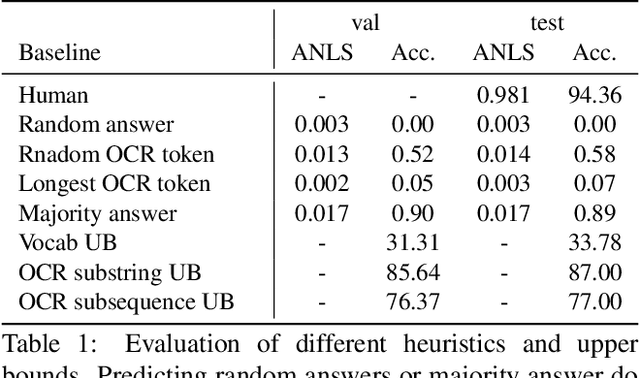

We present a new dataset for Visual Question Answering on document images called DocVQA. The dataset consistsof 50,000 questions defined on 12,000+ document images. We provide detailed analysis of the dataset in comparison with similar datasets for VQA and reading comprehension. We report several baseline results by adopting existing VQA and reading comprehension models. Although the existing models perform reasonably well on certain types of questions, there is large performance gap compared to human performance (94.36% accuracy). The models need to improve specifically on questions where understanding structure of the document is crucial.
Multimodal grid features and cell pointers for Scene Text Visual Question Answering
Jun 25, 2020
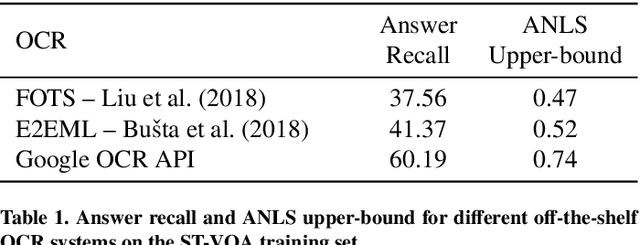
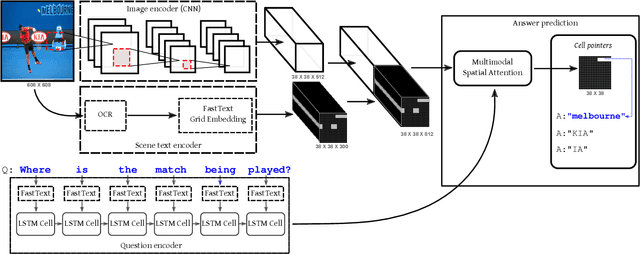
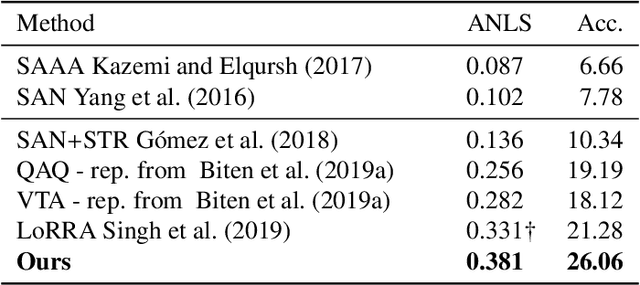
This paper presents a new model for the task of scene text visual question answering, in which questions about a given image can only be answered by reading and understanding scene text that is present in it. The proposed model is based on an attention mechanism that attends to multi-modal features conditioned to the question, allowing it to reason jointly about the textual and visual modalities in the scene. The output weights of this attention module over the grid of multi-modal spatial features are interpreted as the probability that a certain spatial location of the image contains the answer text the to the given question. Our experiments demonstrate competitive performance in two standard datasets. Furthermore, this paper provides a novel analysis of the ST-VQA dataset based on a human performance study.
Fine-grained Image Classification and Retrieval by Combining Visual and Locally Pooled Textual Features
Jan 14, 2020
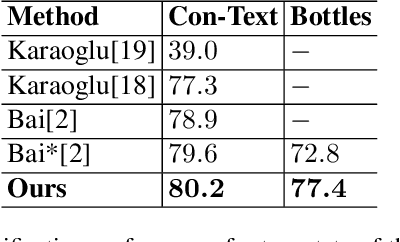
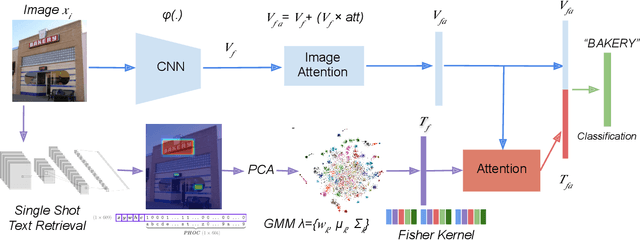
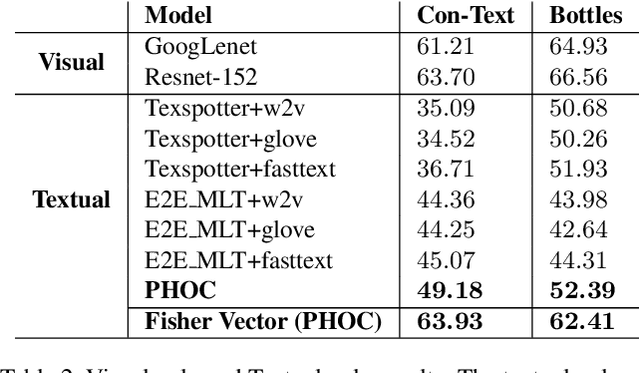
Text contained in an image carries high-level semantics that can be exploited to achieve richer image understanding. In particular, the mere presence of text provides strong guiding content that should be employed to tackle a diversity of computer vision tasks such as image retrieval, fine-grained classification, and visual question answering. In this paper, we address the problem of fine-grained classification and image retrieval by leveraging textual information along with visual cues to comprehend the existing intrinsic relation between the two modalities. The novelty of the proposed model consists of the usage of a PHOC descriptor to construct a bag of textual words along with a Fisher Vector Encoding that captures the morphology of text. This approach provides a stronger multimodal representation for this task and as our experiments demonstrate, it achieves state-of-the-art results on two different tasks, fine-grained classification and image retrieval.
ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard
Dec 20, 2019


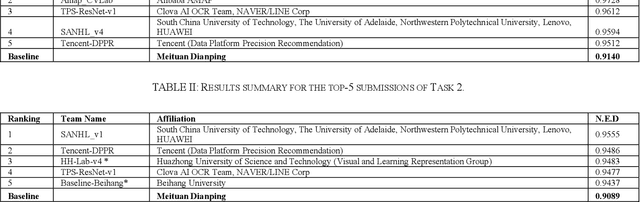
Chinese scene text reading is one of the most challenging problems in computer vision and has attracted great interest. Different from English text, Chinese has more than 6000 commonly used characters and Chinesecharacters can be arranged in various layouts with numerous fonts. The Chinese signboards in street view are a good choice for Chinese scene text images since they have different backgrounds, fonts and layouts. We organized a competition called ICDAR2019-ReCTS, which mainly focuses on reading Chinese text on signboard. This report presents the final results of the competition. A large-scale dataset of 25,000 annotated signboard images, in which all the text lines and characters are annotated with locations and transcriptions, were released. Four tasks, namely character recognition, text line recognition, text line detection and end-to-end recognition were set up. Besides, considering the Chinese text ambiguity issue, we proposed a multi ground truth (multi-GT) evaluation method to make evaluation fairer. The competition started on March 1, 2019 and ended on April 30, 2019. 262 submissions from 46 teams are received. Most of the participants come from universities, research institutes, and tech companies in China. There are also some participants from the United States, Australia, Singapore, and Korea. 21 teams submit results for Task 1, 23 teams submit results for Task 2, 24 teams submit results for Task 3, and 13 teams submit results for Task 4. The official website for the competition is http://rrc.cvc.uab.es/?ch=12.
Exploring Hate Speech Detection in Multimodal Publications
Oct 09, 2019
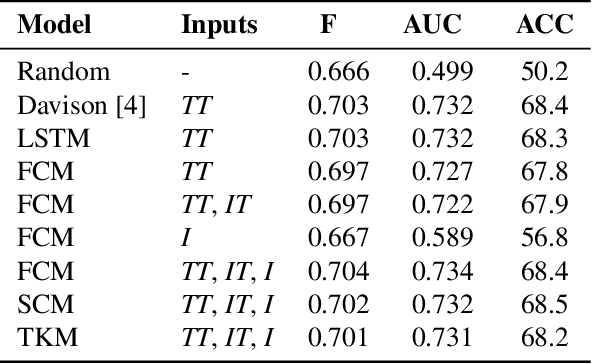
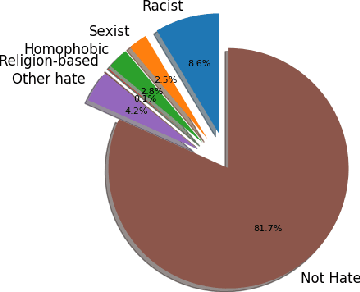
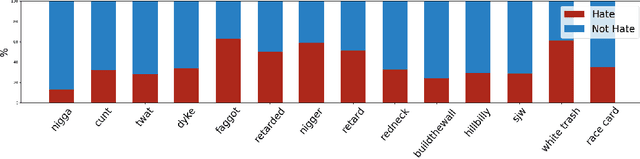
In this work we target the problem of hate speech detection in multimodal publications formed by a text and an image. We gather and annotate a large scale dataset from Twitter, MMHS150K, and propose different models that jointly analyze textual and visual information for hate speech detection, comparing them with unimodal detection. We provide quantitative and qualitative results and analyze the challenges of the proposed task. We find that, even though images are useful for the hate speech detection task, current multimodal models cannot outperform models analyzing only text. We discuss why and open the field and the dataset for further research.
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


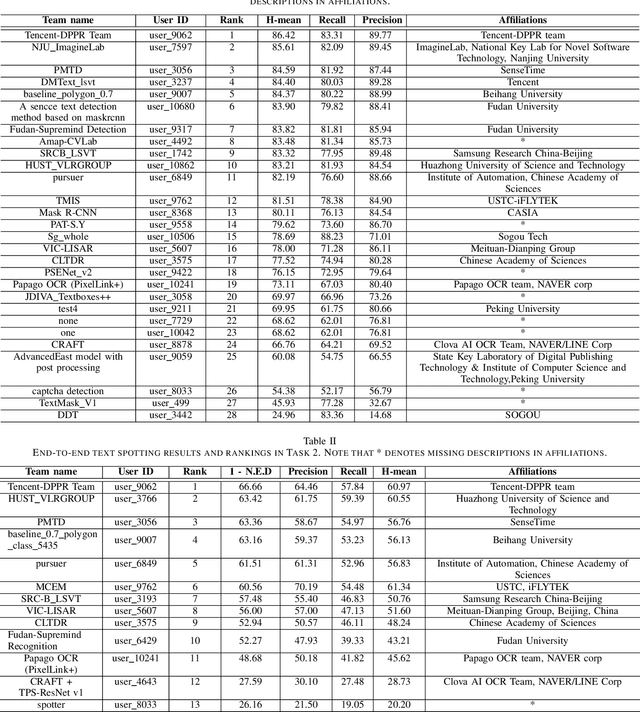
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019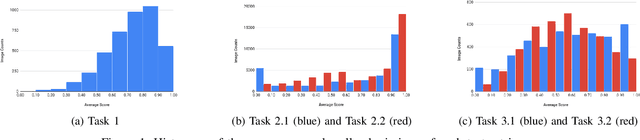



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14