 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQE-Catalytic: A Graph-Language Multimodal Base Model for Relaxed-Energy Prediction in Catalytic Adsorption
Dec 23, 2025Adsorption energy is a key descriptor of catalytic reactivity. It is fundamentally defined as the difference between the relaxed total energy of the adsorbate-surface system and that of an appropriate reference state; therefore, the accuracy of relaxed-energy prediction directly determines the reliability of machine-learning-driven catalyst screening. E(3)-equivariant graph neural networks (GNNs) can natively operate on three-dimensional atomic coordinates under periodic boundary conditions and have demonstrated strong performance on such tasks. In contrast, language-model-based approaches, while enabling human-readable textual descriptions and reducing reliance on explicit graph -- thereby broadening applicability -- remain insufficient in both adsorption-configuration energy prediction accuracy and in distinguishing ``the same system with different configurations,'' even with graph-assisted pretraining in the style of GAP-CATBERTa. To this end, we propose QE-Catalytic, a multimodal framework that deeply couples a large language model (\textbf{Q}wen) with an E(3)-equivariant graph Transformer (\textbf{E}quiformer-V2), enabling unified support for adsorption-configuration property prediction and inverse design on complex catalytic surfaces. During prediction, QE-Catalytic jointly leverages three-dimensional structures and structured configuration text, and injects ``3D geometric information'' into the language channel via graph-text alignment, allowing it to function as a high-performance text-based predictor when precise coordinates are unavailable, while also autoregressively generating CIF files for target-energy-driven structure design and information completion. On OC20, QE-Catalytic reduces the MAE of relaxed adsorption energy from 0.713~eV to 0.486~eV, and consistently outperforms baseline models such as CatBERTa and GAP-CATBERTa across multiple evaluation protocols.
A comprehensive survey of oracle character recognition: challenges, benchmarks, and beyond
Nov 18, 2024



Oracle character recognition-an analysis of ancient Chinese inscriptions found on oracle bones-has become a pivotal field intersecting archaeology, paleography, and historical cultural studies. Traditional methods of oracle character recognition have relied heavily on manual interpretation by experts, which is not only labor-intensive but also limits broader accessibility to the general public. With recent breakthroughs in pattern recognition and deep learning, there is a growing movement towards the automation of oracle character recognition (OrCR), showing considerable promise in tackling the challenges inherent to these ancient scripts. However, a comprehensive understanding of OrCR still remains elusive. Therefore, this paper presents a systematic and structured survey of the current landscape of OrCR research. We commence by identifying and analyzing the key challenges of OrCR. Then, we provide an overview of the primary benchmark datasets and digital resources available for OrCR. A review of contemporary research methodologies follows, in which their respective efficacies, limitations, and applicability to the complex nature of oracle characters are critically highlighted and examined. Additionally, our review extends to ancillary tasks associated with OrCR across diverse disciplines, providing a broad-spectrum analysis of its applications. We conclude with a forward-looking perspective, proposing potential avenues for future investigations that could yield significant advancements in the field.
ICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition -- RRC-MLT-2019
Jul 01, 2019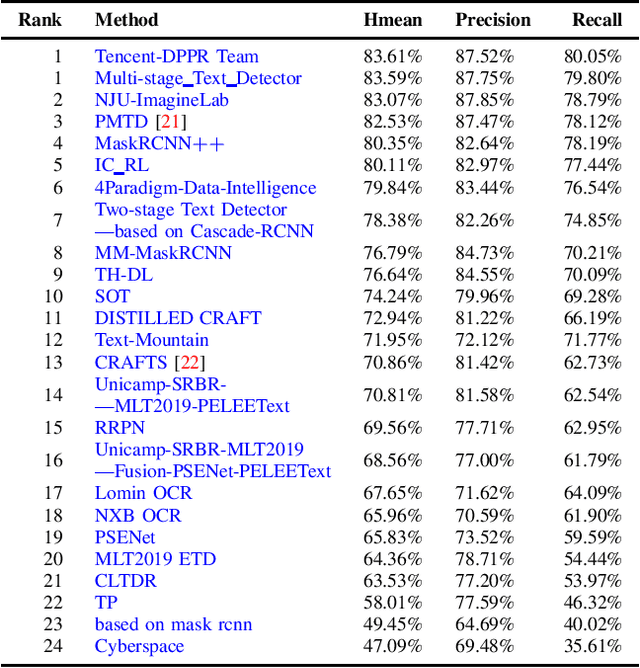
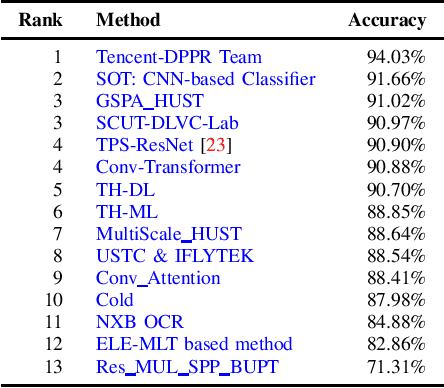
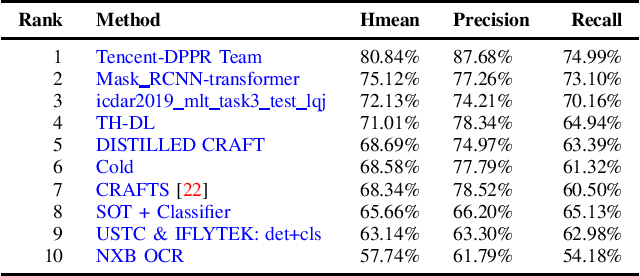
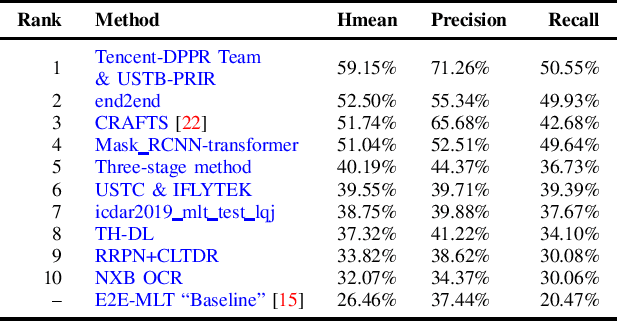
With the growing cosmopolitan culture of modern cities, the need of robust Multi-Lingual scene Text (MLT) detection and recognition systems has never been more immense. With the goal to systematically benchmark and push the state-of-the-art forward, the proposed competition builds on top of the RRC-MLT-2017 with an additional end-to-end task, an additional language in the real images dataset, a large scale multi-lingual synthetic dataset to assist the training, and a baseline End-to-End recognition method. The real dataset consists of 20,000 images containing text from 10 languages. The challenge has 4 tasks covering various aspects of multi-lingual scene text: (a) text detection, (b) cropped word script classification, (c) joint text detection and script classification and (d) end-to-end detection and recognition. In total, the competition received 60 submissions from the research and industrial communities. This paper presents the dataset, the tasks and the findings of the presented RRC-MLT-2019 challenge.