 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantaneous Perception of Moving Objects in 3D
May 05, 2024The perception of 3D motion of surrounding traffic participants is crucial for driving safety. While existing works primarily focus on general large motions, we contend that the instantaneous detection and quantification of subtle motions is equally important as they indicate the nuances in driving behavior that may be safety critical, such as behaviors near a stop sign of parking positions. We delve into this under-explored task, examining its unique challenges and developing our solution, accompanied by a carefully designed benchmark. Specifically, due to the lack of correspondences between consecutive frames of sparse Lidar point clouds, static objects might appear to be moving - the so-called swimming effect. This intertwines with the true object motion, thereby posing ambiguity in accurate estimation, especially for subtle motions. To address this, we propose to leverage local occupancy completion of object point clouds to densify the shape cue, and mitigate the impact of swimming artifacts. The occupancy completion is learned in an end-to-end fashion together with the detection of moving objects and the estimation of their motion, instantaneously as soon as objects start to move. Extensive experiments demonstrate superior performance compared to standard 3D motion estimation approaches, particularly highlighting our method's specialized treatment of subtle motions.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024



Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Generating Enhanced Negatives for Training Language-Based Object Detectors
Dec 29, 2023The recent progress in language-based open-vocabulary object detection can be largely attributed to finding better ways of leveraging large-scale data with free-form text annotations. Training such models with a discriminative objective function has proven successful, but requires good positive and negative samples. However, the free-form nature and the open vocabulary of object descriptions make the space of negatives extremely large. Prior works randomly sample negatives or use rule-based techniques to build them. In contrast, we propose to leverage the vast knowledge built into modern generative models to automatically build negatives that are more relevant to the original data. Specifically, we use large-language-models to generate negative text descriptions, and text-to-image diffusion models to also generate corresponding negative images. Our experimental analysis confirms the relevance of the generated negative data, and its use in language-based detectors improves performance on two complex benchmarks.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023



Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
Fill the K-Space and Refine the Image: Prompting for Dynamic and Multi-Contrast MRI Reconstruction
Sep 25, 2023



The key to dynamic or multi-contrast magnetic resonance imaging (MRI) reconstruction lies in exploring inter-frame or inter-contrast information. Currently, the unrolled model, an approach combining iterative MRI reconstruction steps with learnable neural network layers, stands as the best-performing method for MRI reconstruction. However, there are two main limitations to overcome: firstly, the unrolled model structure and GPU memory constraints restrict the capacity of each denoising block in the network, impeding the effective extraction of detailed features for reconstruction; secondly, the existing model lacks the flexibility to adapt to variations in the input, such as different contrasts, resolutions or views, necessitating the training of separate models for each input type, which is inefficient and may lead to insufficient reconstruction. In this paper, we propose a two-stage MRI reconstruction pipeline to address these limitations. The first stage involves filling the missing k-space data, which we approach as a physics-based reconstruction problem. We first propose a simple yet efficient baseline model, which utilizes adjacent frames/contrasts and channel attention to capture the inherent inter-frame/-contrast correlation. Then, we extend the baseline model to a prompt-based learning approach, PromptMR, for all-in-one MRI reconstruction from different views, contrasts, adjacent types, and acceleration factors. The second stage is to refine the reconstruction from the first stage, which we treat as a general video restoration problem to further fuse features from neighboring frames/contrasts in the image domain. Extensive experiments show that our proposed method significantly outperforms previous state-of-the-art accelerated MRI reconstruction methods.
DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
Sep 22, 2023



Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
Deep Deformable Models: Learning 3D Shape Abstractions with Part Consistency
Sep 02, 2023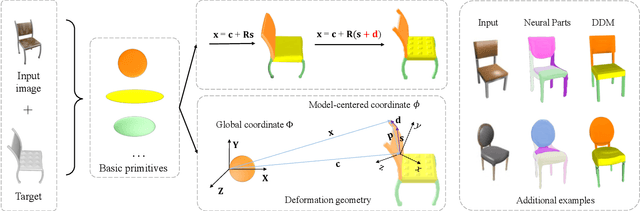
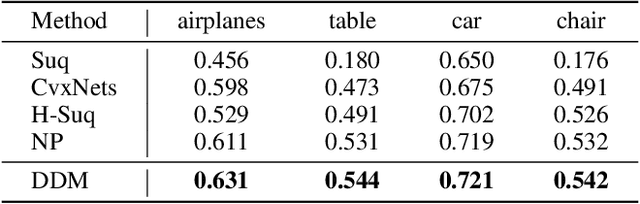
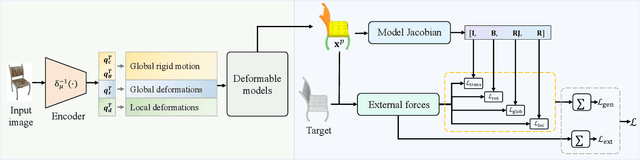
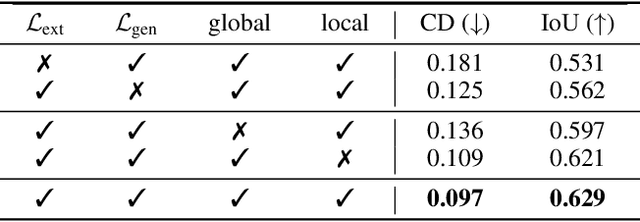
The task of shape abstraction with semantic part consistency is challenging due to the complex geometries of natural objects. Recent methods learn to represent an object shape using a set of simple primitives to fit the target. \textcolor{black}{However, in these methods, the primitives used do not always correspond to real parts or lack geometric flexibility for semantic interpretation.} In this paper, we investigate salient and efficient primitive descriptors for accurate shape abstractions, and propose \textit{Deep Deformable Models (DDMs)}. DDM employs global deformations and diffeomorphic local deformations. These properties enable DDM to abstract complex object shapes with significantly fewer primitives that offer broader geometry coverage and finer details. DDM is also capable of learning part-level semantic correspondences due to the differentiable and invertible properties of our primitive deformation. Moreover, DDM learning formulation is based on dynamic and kinematic modeling, which enables joint regularization of each sub-transformation during primitive fitting. Extensive experiments on \textit{ShapeNet} demonstrate that DDM outperforms the state-of-the-art in terms of reconstruction and part consistency by a notable margin.
DMCVR: Morphology-Guided Diffusion Model for 3D Cardiac Volume Reconstruction
Aug 18, 2023Accurate 3D cardiac reconstruction from cine magnetic resonance imaging (cMRI) is crucial for improved cardiovascular disease diagnosis and understanding of the heart's motion. However, current cardiac MRI-based reconstruction technology used in clinical settings is 2D with limited through-plane resolution, resulting in low-quality reconstructed cardiac volumes. To better reconstruct 3D cardiac volumes from sparse 2D image stacks, we propose a morphology-guided diffusion model for 3D cardiac volume reconstruction, DMCVR, that synthesizes high-resolution 2D images and corresponding 3D reconstructed volumes. Our method outperforms previous approaches by conditioning the cardiac morphology on the generative model, eliminating the time-consuming iterative optimization process of the latent code, and improving generation quality. The learned latent spaces provide global semantics, local cardiac morphology and details of each 2D cMRI slice with highly interpretable value to reconstruct 3D cardiac shape. Our experiments show that DMCVR is highly effective in several aspects, such as 2D generation and 3D reconstruction performance. With DMCVR, we can produce high-resolution 3D cardiac MRI reconstructions, surpassing current techniques. Our proposed framework has great potential for improving the accuracy of cardiac disease diagnosis and treatment planning. Code can be accessed at https://github.com/hexiaoxiao-cs/DMCVR.
Improving Pseudo Labels for Open-Vocabulary Object Detection
Aug 11, 2023Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
Classification of lung cancer subtypes on CT images with synthetic pathological priors
Aug 09, 2023



The accurate diagnosis on pathological subtypes for lung cancer is of significant importance for the follow-up treatments and prognosis managements. In this paper, we propose self-generating hybrid feature network (SGHF-Net) for accurately classifying lung cancer subtypes on computed tomography (CT) images. Inspired by studies stating that cross-scale associations exist in the image patterns between the same case's CT images and its pathological images, we innovatively developed a pathological feature synthetic module (PFSM), which quantitatively maps cross-modality associations through deep neural networks, to derive the "gold standard" information contained in the corresponding pathological images from CT images. Additionally, we designed a radiological feature extraction module (RFEM) to directly acquire CT image information and integrated it with the pathological priors under an effective feature fusion framework, enabling the entire classification model to generate more indicative and specific pathologically related features and eventually output more accurate predictions. The superiority of the proposed model lies in its ability to self-generate hybrid features that contain multi-modality image information based on a single-modality input. To evaluate the effectiveness, adaptability, and generalization ability of our model, we performed extensive experiments on a large-scale multi-center dataset (i.e., 829 cases from three hospitals) to compare our model and a series of state-of-the-art (SOTA) classification models. The experimental results demonstrated the superiority of our model for lung cancer subtypes classification with significant accuracy improvements in terms of accuracy (ACC), area under the curve (AUC), and F1 score.