 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVanilla Group Equivariant Vision Transformer: Simple and Effective
Feb 08, 2026Incorporating symmetry priors as inductive biases to design equivariant Vision Transformers (ViTs) has emerged as a promising avenue for enhancing their performance. However, existing equivariant ViTs often struggle to balance performance with equivariance, primarily due to the challenge of achieving holistic equivariant modifications across the diverse modules in ViTs-particularly in harmonizing the Self-Attention mechanism with Patch Embedding. To address this, we propose a straightforward framework that systematically renders key ViT components, including patch embedding, self-attention, positional encodings, and Down/Up-Sampling, equivariant, thereby constructing ViTs with guaranteed equivariance. The resulting architecture serves as a plug-and-play replacement that is both theoretically grounded and practically versatile, scaling seamlessly even to Swin Transformers. Extensive experiments demonstrate that our equivariant ViTs consistently improve performance and data efficiency across a wide spectrum of vision tasks.
Enhancing Underwater Light Field Images via Global Geometry-aware Diffusion Process
Jan 29, 2026This work studies the challenging problem of acquiring high-quality underwater images via 4-D light field (LF) imaging. To this end, we propose GeoDiff-LF, a novel diffusion-based framework built upon SD-Turbo to enhance underwater 4-D LF imaging by leveraging its spatial-angular structure. GeoDiff-LF consists of three key adaptations: (1) a modified U-Net architecture with convolutional and attention adapters to model geometric cues, (2) a geometry-guided loss function using tensor decomposition and progressive weighting to regularize global structure, and (3) an optimized sampling strategy with noise prediction to improve efficiency. By integrating diffusion priors and LF geometry, GeoDiff-LF effectively mitigates color distortion in underwater scenes. Extensive experiments demonstrate that our framework outperforms existing methods across both visual fidelity and quantitative performance, advancing the state-of-the-art in enhancing underwater imaging. The code will be publicly available at https://github.com/linlos1234/GeoDiff-LF.
SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images
Dec 23, 2025Effectively grounding complex language to pixels in remote sensing (RS) images is a critical challenge for applications like disaster response and environmental monitoring. Current models can parse simple, single-target commands but fail when presented with complex geospatial scenarios, e.g., segmenting objects at various granularities, executing multi-target instructions, and interpreting implicit user intent. To drive progress against these failures, we present LaSeRS, the first large-scale dataset built for comprehensive training and evaluation across four critical dimensions of language-guided segmentation: hierarchical granularity, target multiplicity, reasoning requirements, and linguistic variability. By capturing these dimensions, LaSeRS moves beyond simple commands, providing a benchmark for complex geospatial reasoning. This addresses a critical gap: existing datasets oversimplify, leading to sensitivity-prone real-world models. We also propose SegEarth-R2, an MLLM architecture designed for comprehensive language-guided segmentation in RS, which directly confronts these challenges. The model's effectiveness stems from two key improvements: (1) a spatial attention supervision mechanism specifically handles the localization of small objects and their components, and (2) a flexible and efficient segmentation query mechanism that handles both single-target and multi-target scenarios. Experimental results demonstrate that our SegEarth-R2 achieves outstanding performance on LaSeRS and other benchmarks, establishing a powerful baseline for the next generation of geospatial segmentation. All data and code will be released at https://github.com/earth-insights/SegEarth-R2.
Phase-space entropy at acquisition reflects downstream learnability
Dec 22, 2025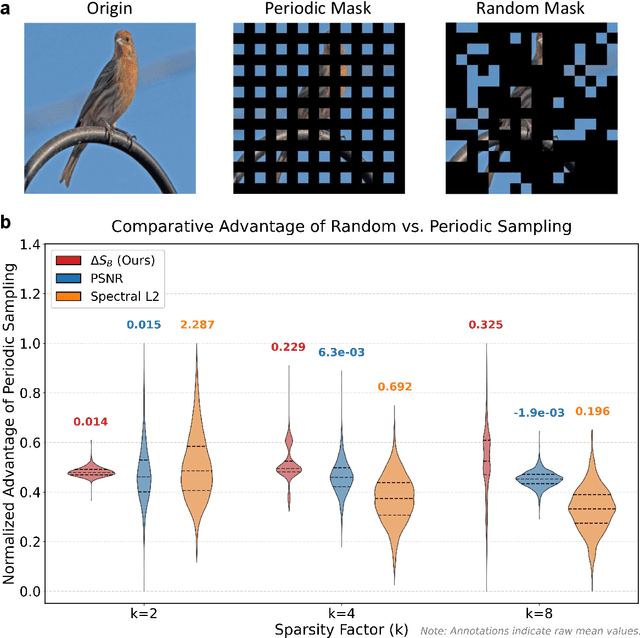
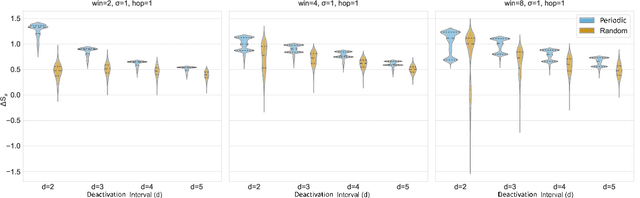
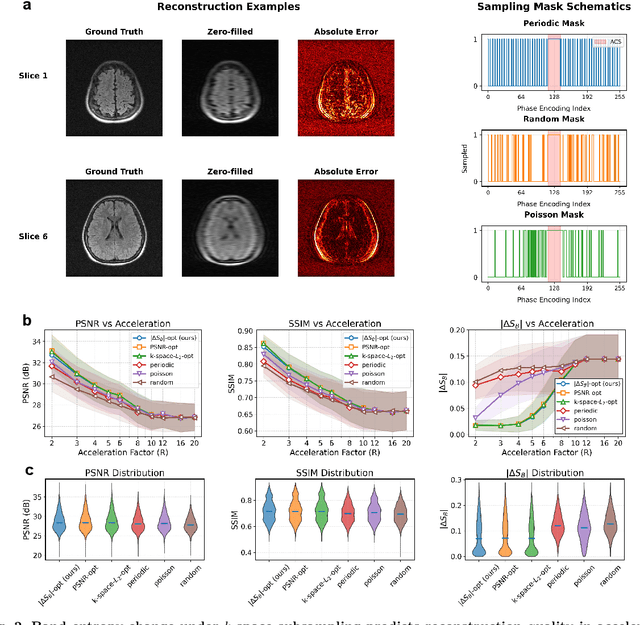

Modern learning systems work with data that vary widely across domains, but they all ultimately depend on how much structure is already present in the measurements before any model is trained. This raises a basic question: is there a general, modality-agnostic way to quantify how acquisition itself preserves or destroys the information that downstream learners could use? Here we propose an acquisition-level scalar $ΔS_{\mathcal B}$ based on instrument-resolved phase space. Unlike pixelwise distortion or purely spectral errors that often saturate under aggressive undersampling, $ΔS_{\mathcal B}$ directly quantifies how acquisition mixes or removes joint space--frequency structure at the instrument scale. We show theoretically that \(ΔS_{\mathcal B}\) correctly identifies the phase-space coherence of periodic sampling as the physical source of aliasing, recovering classical sampling-theorem consequences. Empirically, across masked image classification, accelerated MRI, and massive MIMO (including over-the-air measurements), $|ΔS_{\mathcal B}|$ consistently ranks sampling geometries and predicts downstream reconstruction/recognition difficulty \emph{without training}. In particular, minimizing $|ΔS_{\mathcal B}|$ enables zero-training selection of variable-density MRI mask parameters that matches designs tuned by conventional pre-reconstruction criteria. These results suggest that phase-space entropy at acquisition reflects downstream learnability, enabling pre-training selection of candidate sampling policies and as a shared notion of information preservation across modalities.
SegEarth-OV3: Exploring SAM 3 for Open-Vocabulary Semantic Segmentation in Remote Sensing Images
Dec 09, 2025Most existing methods for training-free Open-Vocabulary Semantic Segmentation (OVSS) are based on CLIP. While these approaches have made progress, they often face challenges in precise localization or require complex pipelines to combine separate modules, especially in remote sensing scenarios where numerous dense and small targets are present. Recently, Segment Anything Model 3 (SAM 3) was proposed, unifying segmentation and recognition in a promptable framework. In this paper, we present a preliminary exploration of applying SAM 3 to the remote sensing OVSS task without any training. First, we implement a mask fusion strategy that combines the outputs from SAM 3's semantic segmentation head and the Transformer decoder (instance head). This allows us to leverage the strengths of both heads for better land coverage. Second, we utilize the presence score from the presence head to filter out categories that do not exist in the scene, reducing false positives caused by the vast vocabulary sizes and patch-level processing in geospatial scenes. We evaluate our method on extensive remote sensing datasets. Experiments show that this simple adaptation achieves promising performance, demonstrating the potential of SAM 3 for remote sensing OVSS. Our code is released at https://github.com/earth-insights/SegEarth-OV-3.
ZoomEarth: Active Perception for Ultra-High-Resolution Geospatial Vision-Language Tasks
Nov 15, 2025



Ultra-high-resolution (UHR) remote sensing (RS) images offer rich fine-grained information but also present challenges in effective processing. Existing dynamic resolution and token pruning methods are constrained by a passive perception paradigm, suffering from increased redundancy when obtaining finer visual inputs. In this work, we explore a new active perception paradigm that enables models to revisit information-rich regions. First, we present LRS-GRO, a large-scale benchmark dataset tailored for active perception in UHR RS processing, encompassing 17 question types across global, region, and object levels, annotated via a semi-automatic pipeline. Building on LRS-GRO, we propose ZoomEarth, an adaptive cropping-zooming framework with a novel Region-Guided reward that provides fine-grained guidance. Trained via supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), ZoomEarth achieves state-of-the-art performance on LRS-GRO and, in the zero-shot setting, on three public UHR remote sensing benchmarks. Furthermore, ZoomEarth can be seamlessly integrated with downstream models for tasks such as cloud removal, denoising, segmentation, and image editing through simple tool interfaces, demonstrating strong versatility and extensibility.
Annotation-Free Open-Vocabulary Segmentation for Remote-Sensing Images
Aug 25, 2025



Semantic segmentation of remote sensing (RS) images is pivotal for comprehensive Earth observation, but the demand for interpreting new object categories, coupled with the high expense of manual annotation, poses significant challenges. Although open-vocabulary semantic segmentation (OVSS) offers a promising solution, existing frameworks designed for natural images are insufficient for the unique complexities of RS data. They struggle with vast scale variations and fine-grained details, and their adaptation often relies on extensive, costly annotations. To address this critical gap, this paper introduces SegEarth-OV, the first framework for annotation-free open-vocabulary segmentation of RS images. Specifically, we propose SimFeatUp, a universal upsampler that robustly restores high-resolution spatial details from coarse features, correcting distorted target shapes without any task-specific post-training. We also present a simple yet effective Global Bias Alleviation operation to subtract the inherent global context from patch features, significantly enhancing local semantic fidelity. These components empower SegEarth-OV to effectively harness the rich semantics of pre-trained VLMs, making OVSS possible in optical RS contexts. Furthermore, to extend the framework's universality to other challenging RS modalities like SAR images, where large-scale VLMs are unavailable and expensive to create, we introduce AlignEarth, which is a distillation-based strategy and can efficiently transfer semantic knowledge from an optical VLM encoder to an SAR encoder, bypassing the need to build SAR foundation models from scratch and enabling universal OVSS across diverse sensor types. Extensive experiments on both optical and SAR datasets validate that SegEarth-OV can achieve dramatic improvements over the SOTA methods, establishing a robust foundation for annotation-free and open-world Earth observation.
Rotation Equivariant Arbitrary-scale Image Super-Resolution
Aug 07, 2025The arbitrary-scale image super-resolution (ASISR), a recent popular topic in computer vision, aims to achieve arbitrary-scale high-resolution recoveries from a low-resolution input image. This task is realized by representing the image as a continuous implicit function through two fundamental modules, a deep-network-based encoder and an implicit neural representation (INR) module. Despite achieving notable progress, a crucial challenge of such a highly ill-posed setting is that many common geometric patterns, such as repetitive textures, edges, or shapes, are seriously warped and deformed in the low-resolution images, naturally leading to unexpected artifacts appearing in their high-resolution recoveries. Embedding rotation equivariance into the ASISR network is thus necessary, as it has been widely demonstrated that this enhancement enables the recovery to faithfully maintain the original orientations and structural integrity of geometric patterns underlying the input image. Motivated by this, we make efforts to construct a rotation equivariant ASISR method in this study. Specifically, we elaborately redesign the basic architectures of INR and encoder modules, incorporating intrinsic rotation equivariance capabilities beyond those of conventional ASISR networks. Through such amelioration, the ASISR network can, for the first time, be implemented with end-to-end rotational equivariance maintained from input to output. We also provide a solid theoretical analysis to evaluate its intrinsic equivariance error, demonstrating its inherent nature of embedding such an equivariance structure. The superiority of the proposed method is substantiated by experiments conducted on both simulated and real datasets. We also validate that the proposed framework can be readily integrated into current ASISR methods in a plug \& play manner to further enhance their performance.
Compressive Imaging Reconstruction via Tensor Decomposed Multi-Resolution Grid Encoding
Jul 10, 2025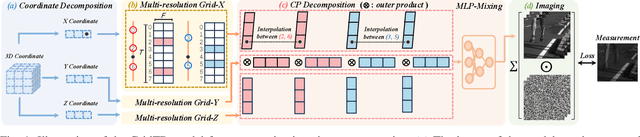

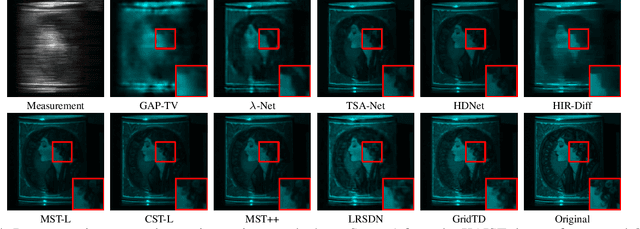
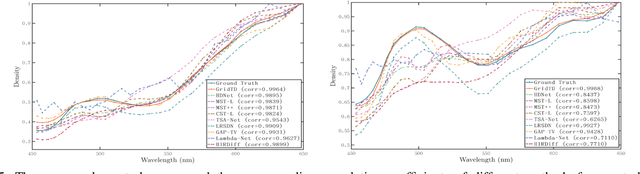
Compressive imaging (CI) reconstruction, such as snapshot compressive imaging (SCI) and compressive sensing magnetic resonance imaging (MRI), aims to recover high-dimensional images from low-dimensional compressed measurements. This process critically relies on learning an accurate representation of the underlying high-dimensional image. However, existing unsupervised representations may struggle to achieve a desired balance between representation ability and efficiency. To overcome this limitation, we propose Tensor Decomposed multi-resolution Grid encoding (GridTD), an unsupervised continuous representation framework for CI reconstruction. GridTD optimizes a lightweight neural network and the input tensor decomposition model whose parameters are learned via multi-resolution hash grid encoding. It inherently enjoys the hierarchical modeling ability of multi-resolution grid encoding and the compactness of tensor decomposition, enabling effective and efficient reconstruction of high-dimensional images. Theoretical analyses for the algorithm's Lipschitz property, generalization error bound, and fixed-point convergence reveal the intrinsic superiority of GridTD as compared with existing continuous representation models. Extensive experiments across diverse CI tasks, including video SCI, spectral SCI, and compressive dynamic MRI reconstruction, consistently demonstrate the superiority of GridTD over existing methods, positioning GridTD as a versatile and state-of-the-art CI reconstruction method.
RS-MTDF: Multi-Teacher Distillation and Fusion for Remote Sensing Semi-Supervised Semantic Segmentation
Jun 11, 2025Semantic segmentation in remote sensing images is crucial for various applications, yet its performance is heavily reliant on large-scale, high-quality pixel-wise annotations, which are notoriously expensive and time-consuming to acquire. Semi-supervised semantic segmentation (SSS) offers a promising alternative to mitigate this data dependency. However, existing SSS methods often struggle with the inherent distribution mismatch between limited labeled data and abundant unlabeled data, leading to suboptimal generalization. To alleviate this issue, we attempt to introduce the Vision Foundation Models (VFMs) pre-trained on vast and diverse datasets into the SSS task since VFMs possess robust generalization capabilities that can effectively bridge this distribution gap and provide strong semantic priors for SSS. Inspired by this, we introduce RS-MTDF (Multi-Teacher Distillation and Fusion), a novel framework that leverages the powerful semantic knowledge embedded in VFMs to guide semi-supervised learning in remote sensing. Specifically, RS-MTDF employs multiple frozen VFMs (e.g., DINOv2 and CLIP) as expert teachers, utilizing feature-level distillation to align student features with their robust representations. To further enhance discriminative power, the distilled knowledge is seamlessly fused into the student decoder. Extensive experiments on three challenging remote sensing datasets demonstrate that RS-MTDF consistently achieves state-of-the-art performance. Notably, our method outperforms existing approaches across various label ratios on LoveDA and secures the highest IoU in the majority of semantic categories. These results underscore the efficacy of multi-teacher VFM guidance in significantly enhancing both generalization and semantic understanding for remote sensing segmentation. Ablation studies further validate the contribution of each proposed module.