 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning the City : Quantifying Urban Perception At A Global Scale
Sep 12, 2016
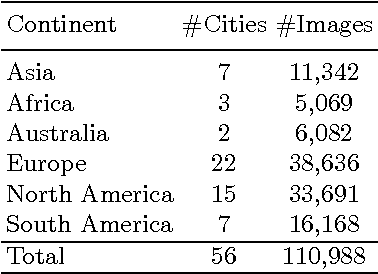
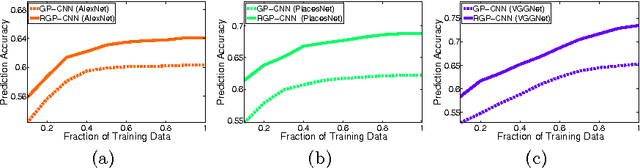
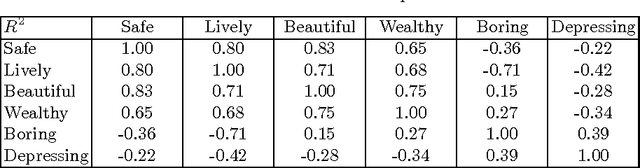
Computer vision methods that quantify the perception of urban environment are increasingly being used to study the relationship between a city's physical appearance and the behavior and health of its residents. Yet, the throughput of current methods is too limited to quantify the perception of cities across the world. To tackle this challenge, we introduce a new crowdsourced dataset containing 110,988 images from 56 cities, and 1,170,000 pairwise comparisons provided by 81,630 online volunteers along six perceptual attributes: safe, lively, boring, wealthy, depressing, and beautiful. Using this data, we train a Siamese-like convolutional neural architecture, which learns from a joint classification and ranking loss, to predict human judgments of pairwise image comparisons. Our results show that crowdsourcing combined with neural networks can produce urban perception data at the global scale.
Towards Transparent AI Systems: Interpreting Visual Question Answering Models
Sep 09, 2016
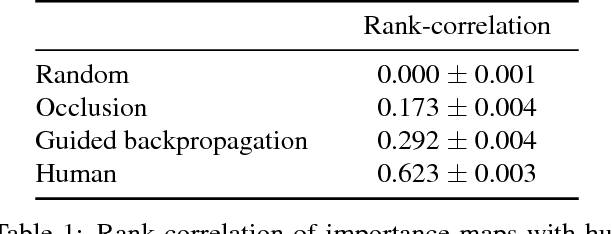

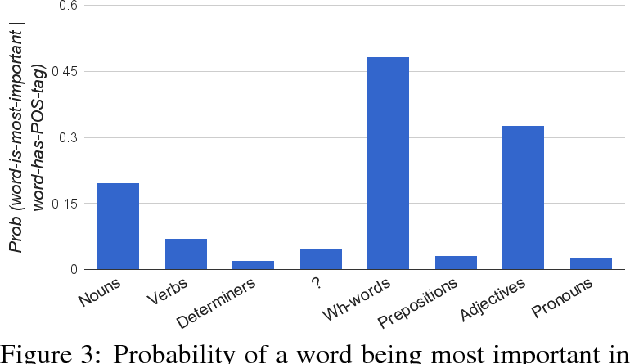
Deep neural networks have shown striking progress and obtained state-of-the-art results in many AI research fields in the recent years. However, it is often unsatisfying to not know why they predict what they do. In this paper, we address the problem of interpreting Visual Question Answering (VQA) models. Specifically, we are interested in finding what part of the input (pixels in images or words in questions) the VQA model focuses on while answering the question. To tackle this problem, we use two visualization techniques -- guided backpropagation and occlusion -- to find important words in the question and important regions in the image. We then present qualitative and quantitative analyses of these importance maps. We found that even without explicit attention mechanisms, VQA models may sometimes be implicitly attending to relevant regions in the image, and often to appropriate words in the question.
Leveraging Visual Question Answering for Image-Caption Ranking
Aug 31, 2016
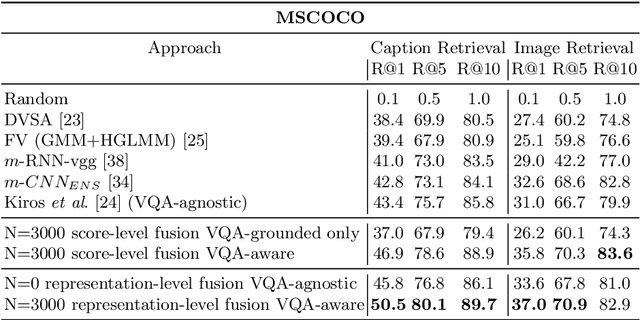


Visual Question Answering (VQA) is the task of taking as input an image and a free-form natural language question about the image, and producing an accurate answer. In this work we view VQA as a "feature extraction" module to extract image and caption representations. We employ these representations for the task of image-caption ranking. Each feature dimension captures (imagines) whether a fact (question-answer pair) could plausibly be true for the image and caption. This allows the model to interpret images and captions from a wide variety of perspectives. We propose score-level and representation-level fusion models to incorporate VQA knowledge in an existing state-of-the-art VQA-agnostic image-caption ranking model. We find that incorporating and reasoning about consistency between images and captions significantly improves performance. Concretely, our model improves state-of-the-art on caption retrieval by 7.1% and on image retrieval by 4.4% on the MSCOCO dataset.
Measuring Machine Intelligence Through Visual Question Answering
Aug 31, 2016


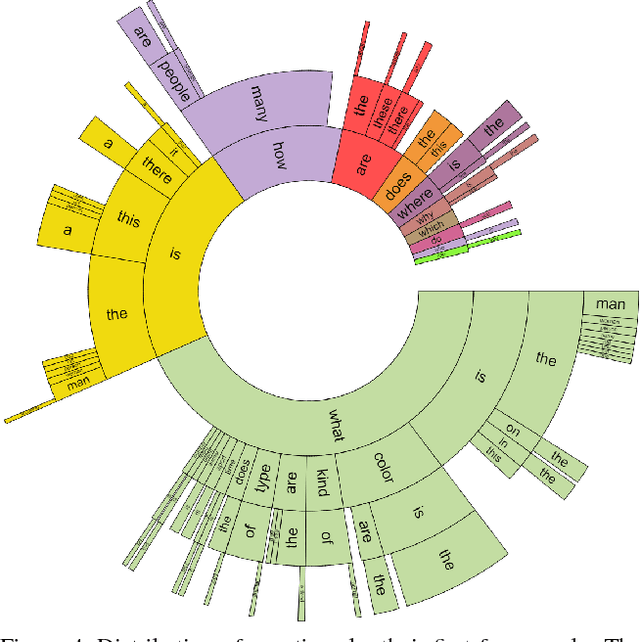
As machines have become more intelligent, there has been a renewed interest in methods for measuring their intelligence. A common approach is to propose tasks for which a human excels, but one which machines find difficult. However, an ideal task should also be easy to evaluate and not be easily gameable. We begin with a case study exploring the recently popular task of image captioning and its limitations as a task for measuring machine intelligence. An alternative and more promising task is Visual Question Answering that tests a machine's ability to reason about language and vision. We describe a dataset unprecedented in size created for the task that contains over 760,000 human generated questions about images. Using around 10 million human generated answers, machines may be easily evaluated.
Visual Word2Vec (vis-w2v): Learning Visually Grounded Word Embeddings Using Abstract Scenes
Jun 29, 2016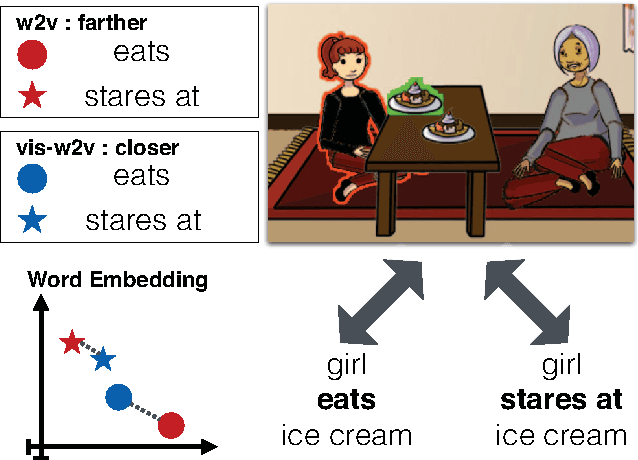

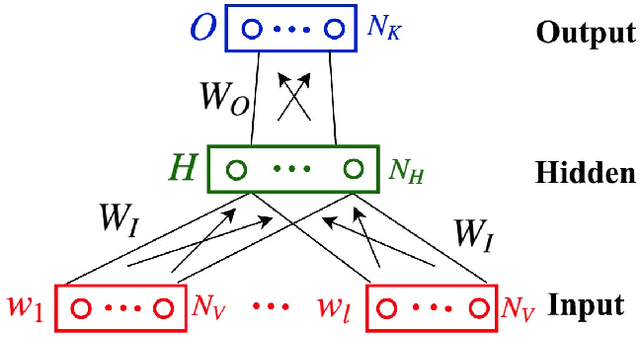

We propose a model to learn visually grounded word embeddings (vis-w2v) to capture visual notions of semantic relatedness. While word embeddings trained using text have been extremely successful, they cannot uncover notions of semantic relatedness implicit in our visual world. For instance, although "eats" and "stares at" seem unrelated in text, they share semantics visually. When people are eating something, they also tend to stare at the food. Grounding diverse relations like "eats" and "stares at" into vision remains challenging, despite recent progress in vision. We note that the visual grounding of words depends on semantics, and not the literal pixels. We thus use abstract scenes created from clipart to provide the visual grounding. We find that the embeddings we learn capture fine-grained, visually grounded notions of semantic relatedness. We show improvements over text-only word embeddings (word2vec) on three tasks: common-sense assertion classification, visual paraphrasing and text-based image retrieval. Our code and datasets are available online.
Joint Unsupervised Learning of Deep Representations and Image Clusters
Jun 20, 2016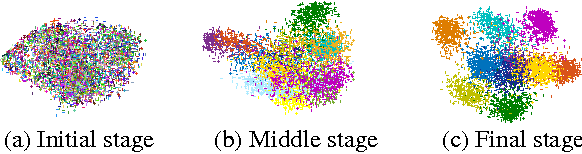

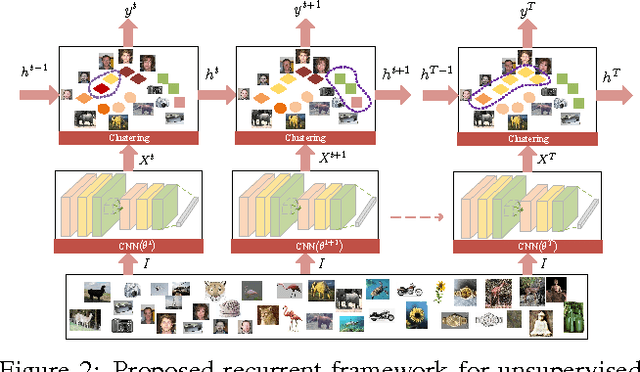
In this paper, we propose a recurrent framework for Joint Unsupervised LEarning (JULE) of deep representations and image clusters. In our framework, successive operations in a clustering algorithm are expressed as steps in a recurrent process, stacked on top of representations output by a Convolutional Neural Network (CNN). During training, image clusters and representations are updated jointly: image clustering is conducted in the forward pass, while representation learning in the backward pass. Our key idea behind this framework is that good representations are beneficial to image clustering and clustering results provide supervisory signals to representation learning. By integrating two processes into a single model with a unified weighted triplet loss and optimizing it end-to-end, we can obtain not only more powerful representations, but also more precise image clusters. Extensive experiments show that our method outperforms the state-of-the-art on image clustering across a variety of image datasets. Moreover, the learned representations generalize well when transferred to other tasks.
Human Attention in Visual Question Answering: Do Humans and Deep Networks Look at the Same Regions?
Jun 17, 2016
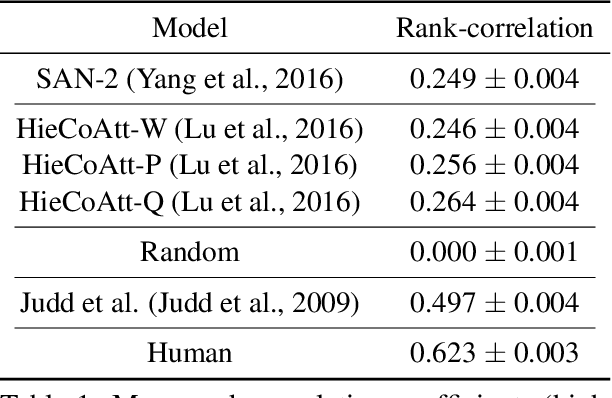


We conduct large-scale studies on `human attention' in Visual Question Answering (VQA) to understand where humans choose to look to answer questions about images. We design and test multiple game-inspired novel attention-annotation interfaces that require the subject to sharpen regions of a blurred image to answer a question. Thus, we introduce the VQA-HAT (Human ATtention) dataset. We evaluate attention maps generated by state-of-the-art VQA models against human attention both qualitatively (via visualizations) and quantitatively (via rank-order correlation). Overall, our experiments show that current attention models in VQA do not seem to be looking at the same regions as humans.
We Are Humor Beings: Understanding and Predicting Visual Humor
May 05, 2016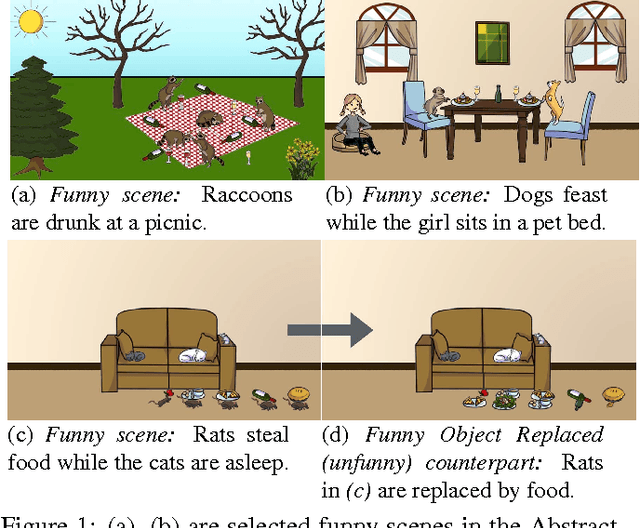



Humor is an integral part of human lives. Despite being tremendously impactful, it is perhaps surprising that we do not have a detailed understanding of humor yet. As interactions between humans and AI systems increase, it is imperative that these systems are taught to understand subtleties of human expressions such as humor. In this work, we are interested in the question - what content in a scene causes it to be funny? As a first step towards understanding visual humor, we analyze the humor manifested in abstract scenes and design computational models for them. We collect two datasets of abstract scenes that facilitate the study of humor at both the scene-level and the object-level. We analyze the funny scenes and explore the different types of humor depicted in them via human studies. We model two tasks that we believe demonstrate an understanding of some aspects of visual humor. The tasks involve predicting the funniness of a scene and altering the funniness of a scene. We show that our models perform well quantitatively, and qualitatively through human studies. Our datasets are publicly available.
Yin and Yang: Balancing and Answering Binary Visual Questions
Apr 19, 2016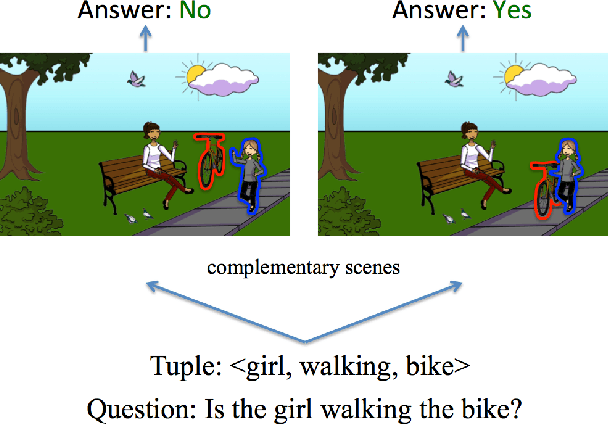
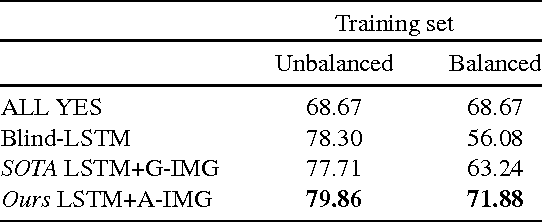
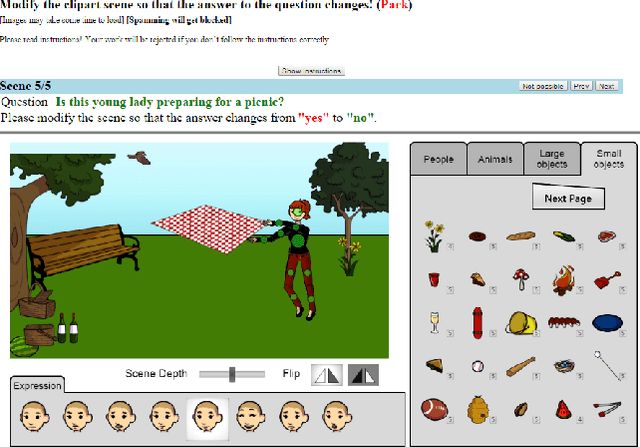
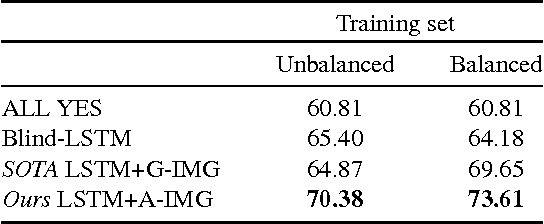
The complex compositional structure of language makes problems at the intersection of vision and language challenging. But language also provides a strong prior that can result in good superficial performance, without the underlying models truly understanding the visual content. This can hinder progress in pushing state of art in the computer vision aspects of multi-modal AI. In this paper, we address binary Visual Question Answering (VQA) on abstract scenes. We formulate this problem as visual verification of concepts inquired in the questions. Specifically, we convert the question to a tuple that concisely summarizes the visual concept to be detected in the image. If the concept can be found in the image, the answer to the question is "yes", and otherwise "no". Abstract scenes play two roles (1) They allow us to focus on the high-level semantics of the VQA task as opposed to the low-level recognition problems, and perhaps more importantly, (2) They provide us the modality to balance the dataset such that language priors are controlled, and the role of vision is essential. In particular, we collect fine-grained pairs of scenes for every question, such that the answer to the question is "yes" for one scene, and "no" for the other for the exact same question. Indeed, language priors alone do not perform better than chance on our balanced dataset. Moreover, our proposed approach matches the performance of a state-of-the-art VQA approach on the unbalanced dataset, and outperforms it on the balanced dataset.
Visual Storytelling
Apr 13, 2016

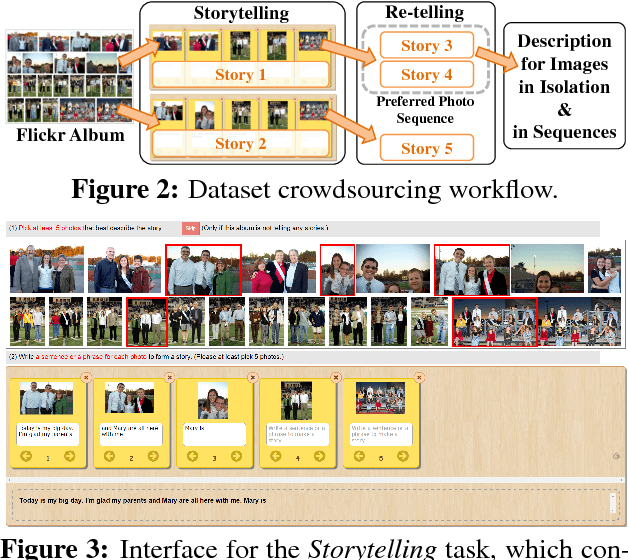
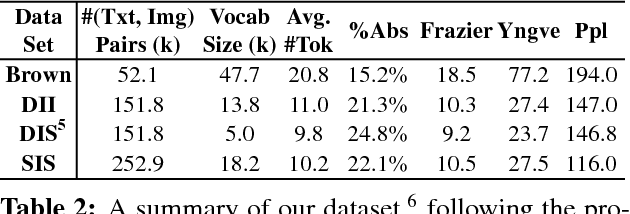
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.