 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2Map: Cross-modal Retrieval for Inferring Street Maps from Images
Jan 10, 2023



Self-driving vehicles rely on urban street maps for autonomous navigation. In this paper, we introduce Pix2Map, a method for inferring urban street map topology directly from ego-view images, as needed to continually update and expand existing maps. This is a challenging task, as we need to infer a complex urban road topology directly from raw image data. The main insight of this paper is that this problem can be posed as cross-modal retrieval by learning a joint, cross-modal embedding space for images and existing maps, represented as discrete graphs that encode the topological layout of the visual surroundings. We conduct our experimental evaluation using the Argoverse dataset and show that it is indeed possible to accurately retrieve street maps corresponding to both seen and unseen roads solely from image data. Moreover, we show that our retrieved maps can be used to update or expand existing maps and even show proof-of-concept results for visual localization and image retrieval from spatial graphs.
TarViS: A Unified Approach for Target-based Video Segmentation
Jan 06, 2023



The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
Far3Det: Towards Far-Field 3D Detection
Nov 25, 2022



We focus on the task of far-field 3D detection (Far3Det) of objects beyond a certain distance from an observer, e.g., $>$50m. Far3Det is particularly important for autonomous vehicles (AVs) operating at highway speeds, which require detections of far-field obstacles to ensure sufficient braking distances. However, contemporary AV benchmarks such as nuScenes underemphasize this problem because they evaluate performance only up to a certain distance (50m). One reason is that obtaining far-field 3D annotations is difficult, particularly for lidar sensors that produce very few point returns for far-away objects. Indeed, we find that almost 50% of far-field objects (beyond 50m) contain zero lidar points. Secondly, current metrics for 3D detection employ a "one-size-fits-all" philosophy, using the same tolerance thresholds for near and far objects, inconsistent with tolerances for both human vision and stereo disparities. Both factors lead to an incomplete analysis of the Far3Det task. For example, while conventional wisdom tells us that high-resolution RGB sensors should be vital for 3D detection of far-away objects, lidar-based methods still rank higher compared to RGB counterparts on the current benchmark leaderboards. As a first step towards a Far3Det benchmark, we develop a method to find well-annotated scenes from the nuScenes dataset and derive a well-annotated far-field validation set. We also propose a Far3Det evaluation protocol and explore various 3D detection methods for Far3Det. Our result convincingly justifies the long-held conventional wisdom that high-resolution RGB improves 3D detection in the far-field. We further propose a simple yet effective method that fuses detections from RGB and lidar detectors based on non-maximum suppression, which remarkably outperforms state-of-the-art 3D detectors in the far-field.
Towards Long-Tailed 3D Detection
Nov 16, 2022Contemporary autonomous vehicle (AV) benchmarks have advanced techniques for training 3D detectors, particularly on large-scale lidar data. Surprisingly, although semantic class labels naturally follow a long-tailed distribution, contemporary benchmarks focus on only a few common classes (e.g., pedestrian and car) and neglect many rare classes in-the-tail (e.g., debris and stroller). However, AVs must still detect rare classes to ensure safe operation. Moreover, semantic classes are often organized within a hierarchy, e.g., tail classes such as child and construction-worker are arguably subclasses of pedestrian. However, such hierarchical relationships are often ignored, which may lead to misleading estimates of performance and missed opportunities for algorithmic innovation. We address these challenges by formally studying the problem of Long-Tailed 3D Detection (LT3D), which evaluates on all classes, including those in-the-tail. We evaluate and innovate upon popular 3D detection codebases, such as CenterPoint and PointPillars, adapting them for LT3D. We develop hierarchical losses that promote feature sharing across common-vs-rare classes, as well as improved detection metrics that award partial credit to "reasonable" mistakes respecting the hierarchy (e.g., mistaking a child for an adult). Finally, we point out that fine-grained tail class accuracy is particularly improved via multimodal fusion of RGB images with LiDAR; simply put, small fine-grained classes are challenging to identify from sparse (lidar) geometry alone, suggesting that multimodal cues are crucial to long-tailed 3D detection. Our modifications improve accuracy by 5% AP on average for all classes, and dramatically improve AP for rare classes (e.g., stroller AP improves from 3.6 to 31.6)!
Soft Augmentation for Image Classification
Nov 09, 2022



Modern neural networks are over-parameterized and thus rely on strong regularization such as data augmentation and weight decay to reduce overfitting and improve generalization. The dominant form of data augmentation applies invariant transforms, where the learning target of a sample is invariant to the transform applied to that sample. We draw inspiration from human visual classification studies and propose generalizing augmentation with invariant transforms to soft augmentation where the learning target softens non-linearly as a function of the degree of the transform applied to the sample: e.g., more aggressive image crop augmentations produce less confident learning targets. We demonstrate that soft targets allow for more aggressive data augmentation, offer more robust performance boosts, work with other augmentation policies, and interestingly, produce better calibrated models (since they are trained to be less confident on aggressively cropped/occluded examples). Combined with existing aggressive augmentation strategies, soft target 1) doubles the top-1 accuracy boost across Cifar-10, Cifar-100, ImageNet-1K, and ImageNet-V2, 2) improves model occlusion performance by up to $4\times$, and 3) halves the expected calibration error (ECE). Finally, we show that soft augmentation generalizes to self-supervised classification tasks.
Learning to Discover and Detect Objects
Oct 19, 2022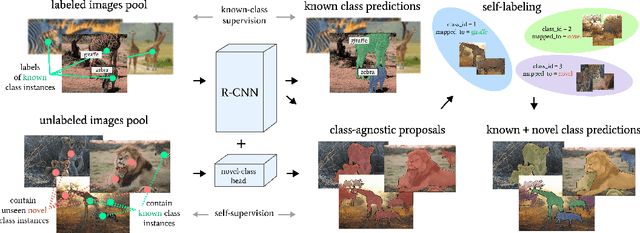
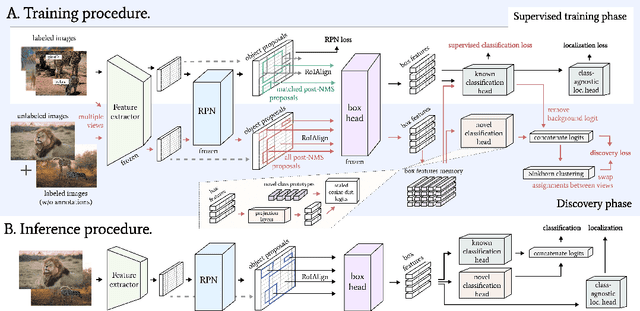


We tackle the problem of novel class discovery, detection, and localization (NCDL). In this setting, we assume a source dataset with labels for objects of commonly observed classes. Instances of other classes need to be discovered, classified, and localized automatically based on visual similarity, without human supervision. To this end, we propose a two-stage object detection network Region-based NCDL (RNCDL), that uses a region proposal network to localize object candidates and is trained to classify each candidate, either as one of the known classes, seen in the source dataset, or one of the extended set of novel classes, with a long-tail distribution constraint on the class assignments, reflecting the natural frequency of classes in the real world. By training our detection network with this objective in an end-to-end manner, it learns to classify all region proposals for a large variety of classes, including those that are not part of the labeled object class vocabulary. Our experiments conducted using COCO and LVIS datasets reveal that our method is significantly more effective compared to multi-stage pipelines that rely on traditional clustering algorithms or use pre-extracted crops. Furthermore, we demonstrate the generality of our approach by applying our method to a large-scale Visual Genome dataset, where our network successfully learns to detect various semantic classes without explicit supervision.
Learning with an Evolving Class Ontology
Oct 12, 2022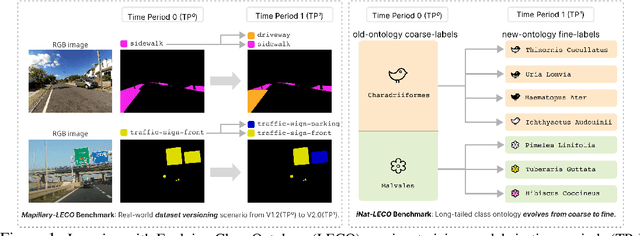
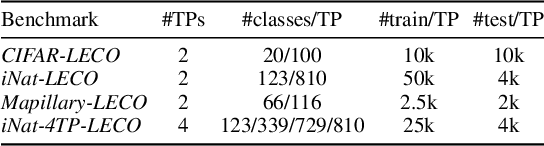
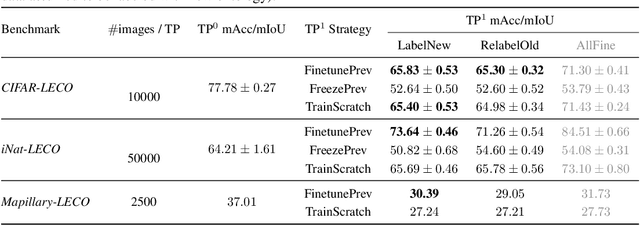
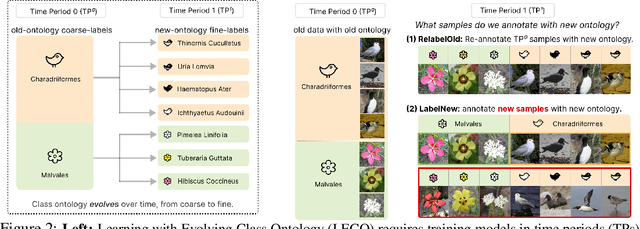
Lifelong learners must recognize concept vocabularies that evolve over time. A common yet underexplored scenario is learning with class labels over time that refine/expand old classes. For example, humans learn to recognize ${\tt dog}$ before dog breeds. In practical settings, dataset $\textit{versioning}$ often introduces refinement to ontologies, such as autonomous vehicle benchmarks that refine a previous ${\tt vehicle}$ class into ${\tt school-bus}$ as autonomous operations expand to new cities. This paper formalizes a protocol for studying the problem of $\textit{Learning with Evolving Class Ontology}$ (LECO). LECO requires learning classifiers in distinct time periods (TPs); each TP introduces a new ontology of "fine" labels that refines old ontologies of "coarse" labels (e.g., dog breeds that refine the previous ${\tt dog}$). LECO explores such questions as whether to annotate new data or relabel the old, how to leverage coarse labels, and whether to finetune the previous TP's model or train from scratch. To answer these questions, we leverage insights from related problems such as class-incremental learning. We validate them under the LECO protocol through the lens of image classification (CIFAR and iNaturalist) and semantic segmentation (Mapillary). Our experiments lead to surprising conclusions; while the current status quo is to relabel existing datasets with new ontologies (such as COCO-to-LVIS or Mapillary1.2-to-2.0), LECO demonstrates that a far better strategy is to annotate $\textit{new}$ data with the new ontology. However, this produces an aggregate dataset with inconsistent old-vs-new labels, complicating learning. To address this challenge, we adopt methods from semi-supervised and partial-label learning. Such strategies can surprisingly be made near-optimal, approaching an "oracle" that learns on the aggregate dataset exhaustively labeled with the newest ontology.
Dfferentiable Raycasting for Self-supervised Occupancy Forecasting
Oct 04, 2022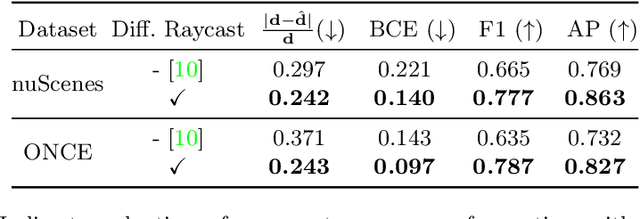


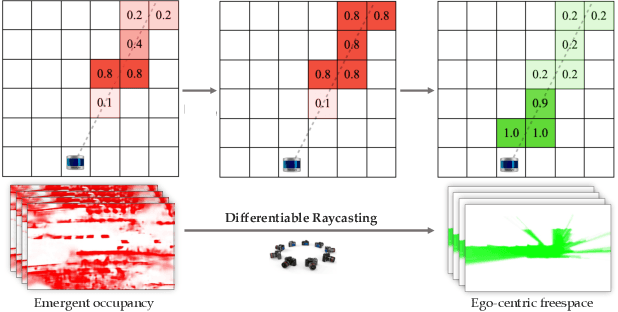
Motion planning for safe autonomous driving requires learning how the environment around an ego-vehicle evolves with time. Ego-centric perception of driveable regions in a scene not only changes with the motion of actors in the environment, but also with the movement of the ego-vehicle itself. Self-supervised representations proposed for large-scale planning, such as ego-centric freespace, confound these two motions, making the representation difficult to use for downstream motion planners. In this paper, we use geometric occupancy as a natural alternative to view-dependent representations such as freespace. Occupancy maps naturally disentangle the motion of the environment from the motion of the ego-vehicle. However, one cannot directly observe the full 3D occupancy of a scene (due to occlusion), making it difficult to use as a signal for learning. Our key insight is to use differentiable raycasting to "render" future occupancy predictions into future LiDAR sweep predictions, which can be compared with ground-truth sweeps for self-supervised learning. The use of differentiable raycasting allows occupancy to emerge as an internal representation within the forecasting network. In the absence of groundtruth occupancy, we quantitatively evaluate the forecasting of raycasted LiDAR sweeps and show improvements of upto 15 F1 points. For downstream motion planners, where emergent occupancy can be directly used to guide non-driveable regions, this representation relatively reduces the number of collisions with objects by up to 17% as compared to freespace-centric motion planners.
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video
Sep 25, 2022
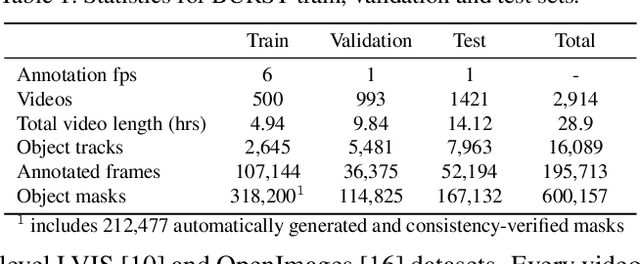
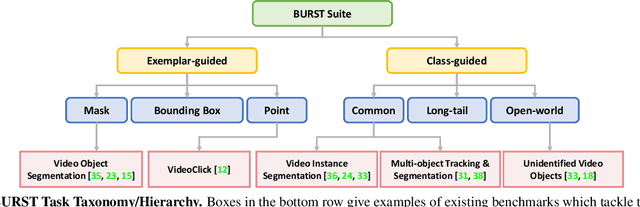
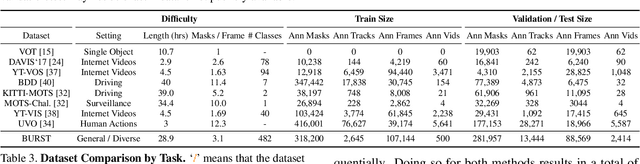
Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference. Dataset annotations and evaluation code is available at: https://github.com/Ali2500/BURST-benchmark.