 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeomGCL: Geometric Graph Contrastive Learning for Molecular Property Prediction
Sep 24, 2021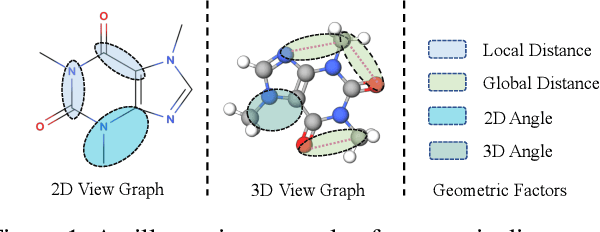
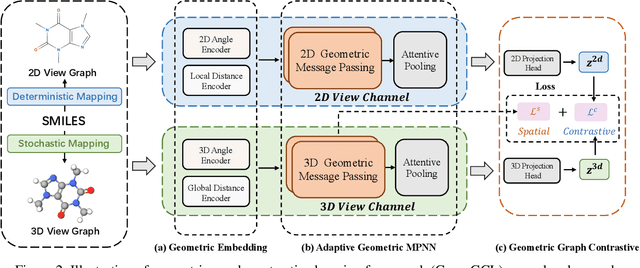
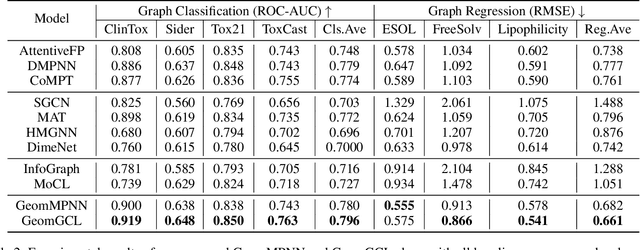
Recently many efforts have been devoted to applying graph neural networks (GNNs) to molecular property prediction which is a fundamental task for computational drug and material discovery. One of major obstacles to hinder the successful prediction of molecule property by GNNs is the scarcity of labeled data. Though graph contrastive learning (GCL) methods have achieved extraordinary performance with insufficient labeled data, most focused on designing data augmentation schemes for general graphs. However, the fundamental property of a molecule could be altered with the augmentation method (like random perturbation) on molecular graphs. Whereas, the critical geometric information of molecules remains rarely explored under the current GNN and GCL architectures. To this end, we propose a novel graph contrastive learning method utilizing the geometry of the molecule across 2D and 3D views, which is named GeomGCL. Specifically, we first devise a dual-view geometric message passing network (GeomMPNN) to adaptively leverage the rich information of both 2D and 3D graphs of a molecule. The incorporation of geometric properties at different levels can greatly facilitate the molecular representation learning. Then a novel geometric graph contrastive scheme is designed to make both geometric views collaboratively supervise each other to improve the generalization ability of GeomMPNN. We evaluate GeomGCL on various downstream property prediction tasks via a finetune process. Experimental results on seven real-life molecular datasets demonstrate the effectiveness of our proposed GeomGCL against state-of-the-art baselines.
Cross-Model Consensus of Explanations and Beyond for Image Classification Models: An Empirical Study
Sep 02, 2021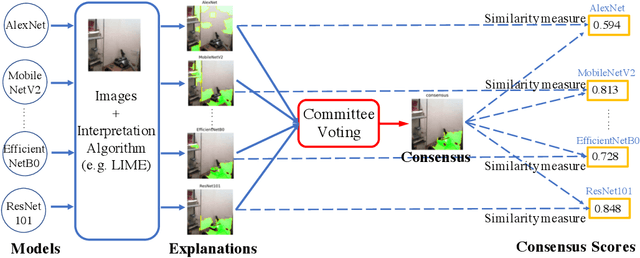

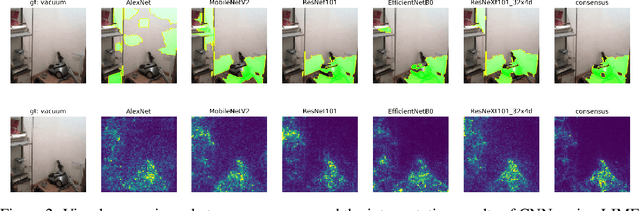
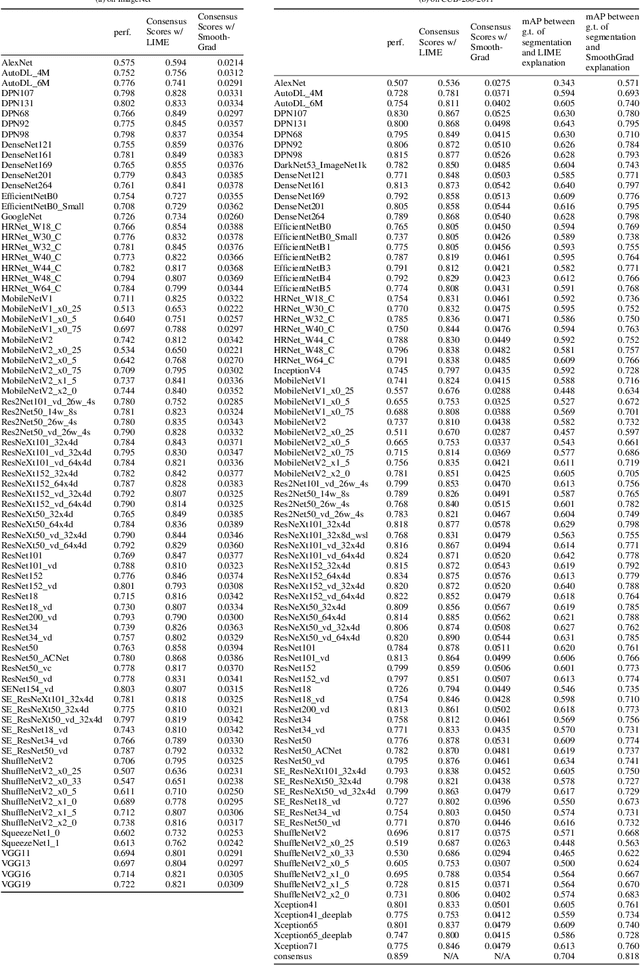
Existing interpretation algorithms have found that, even deep models make the same and right predictions on the same image, they might rely on different sets of input features for classification. However, among these sets of features, some common features might be used by the majority of models. In this paper, we are wondering what are the common features used by various models for classification and whether the models with better performance may favor those common features. For this purpose, our works uses an interpretation algorithm to attribute the importance of features (e.g., pixels or superpixels) as explanations, and proposes the cross-model consensus of explanations to capture the common features. Specifically, we first prepare a set of deep models as a committee, then deduce the explanation for every model, and obtain the consensus of explanations across the entire committee through voting. With the cross-model consensus of explanations, we conduct extensive experiments using 80+ models on 5 datasets/tasks. We find three interesting phenomena as follows: (1) the consensus obtained from image classification models is aligned with the ground truth of semantic segmentation; (2) we measure the similarity of the explanation result of each model in the committee to the consensus (namely consensus score), and find positive correlations between the consensus score and model performance; and (3) the consensus score coincidentally correlates to the interpretability.
MugRep: A Multi-Task Hierarchical Graph Representation Learning Framework for Real Estate Appraisal
Aug 02, 2021
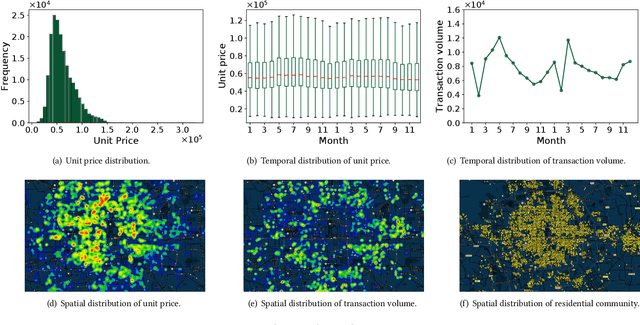
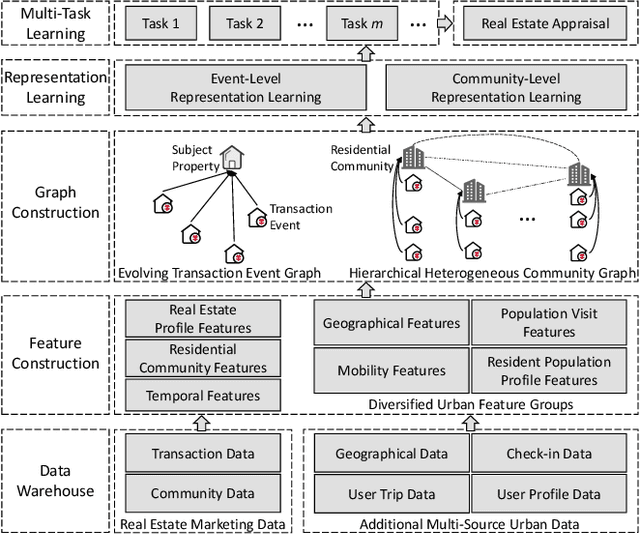
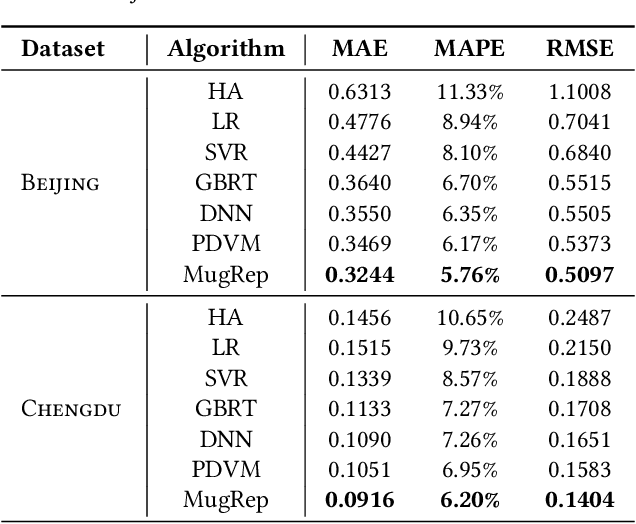
Real estate appraisal refers to the process of developing an unbiased opinion for real property's market value, which plays a vital role in decision-making for various players in the marketplace (e.g., real estate agents, appraisers, lenders, and buyers). However, it is a nontrivial task for accurate real estate appraisal because of three major challenges: (1) The complicated influencing factors for property value; (2) The asynchronously spatiotemporal dependencies among real estate transactions; (3) The diversified correlations between residential communities. To this end, we propose a Multi-Task Hierarchical Graph Representation Learning (MugRep) framework for accurate real estate appraisal. Specifically, by acquiring and integrating multi-source urban data, we first construct a rich feature set to comprehensively profile the real estate from multiple perspectives (e.g., geographical distribution, human mobility distribution, and resident demographics distribution). Then, an evolving real estate transaction graph and a corresponding event graph convolution module are proposed to incorporate asynchronously spatiotemporal dependencies among real estate transactions. Moreover, to further incorporate valuable knowledge from the view of residential communities, we devise a hierarchical heterogeneous community graph convolution module to capture diversified correlations between residential communities. Finally, an urban district partitioned multi-task learning module is introduced to generate differently distributed value opinions for real estate. Extensive experiments on two real-world datasets demonstrate the effectiveness of MugRep and its components and features.
Semi-Supervised Active Learning with Temporal Output Discrepancy
Jul 29, 2021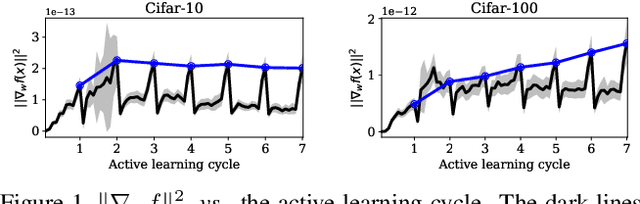
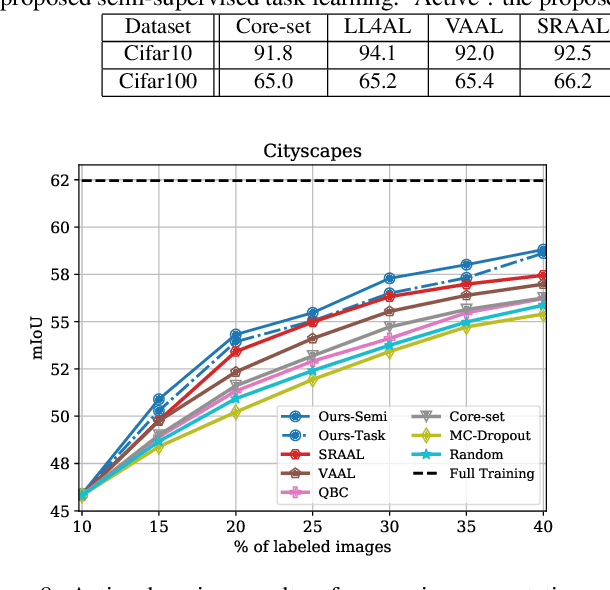


While deep learning succeeds in a wide range of tasks, it highly depends on the massive collection of annotated data which is expensive and time-consuming. To lower the cost of data annotation, active learning has been proposed to interactively query an oracle to annotate a small proportion of informative samples in an unlabeled dataset. Inspired by the fact that the samples with higher loss are usually more informative to the model than the samples with lower loss, in this paper we present a novel deep active learning approach that queries the oracle for data annotation when the unlabeled sample is believed to incorporate high loss. The core of our approach is a measurement Temporal Output Discrepancy (TOD) that estimates the sample loss by evaluating the discrepancy of outputs given by models at different optimization steps. Our theoretical investigation shows that TOD lower-bounds the accumulated sample loss thus it can be used to select informative unlabeled samples. On basis of TOD, we further develop an effective unlabeled data sampling strategy as well as an unsupervised learning criterion that enhances model performance by incorporating the unlabeled data. Due to the simplicity of TOD, our active learning approach is efficient, flexible, and task-agnostic. Extensive experimental results demonstrate that our approach achieves superior performances than the state-of-the-art active learning methods on image classification and semantic segmentation tasks.
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
Jul 21, 2021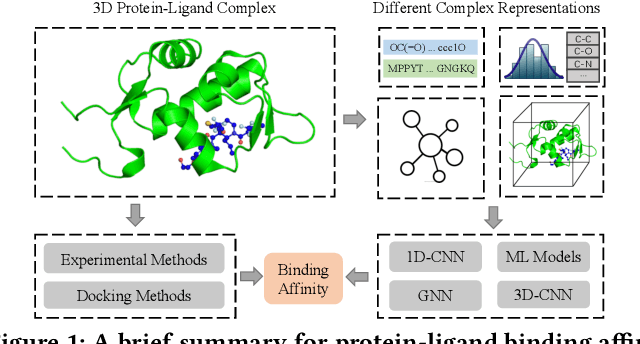
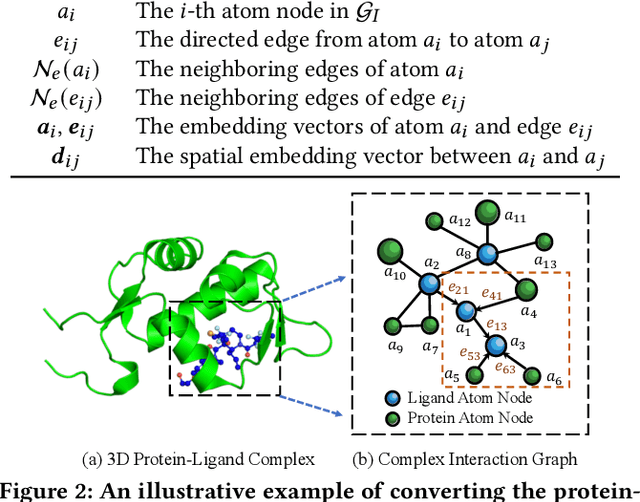
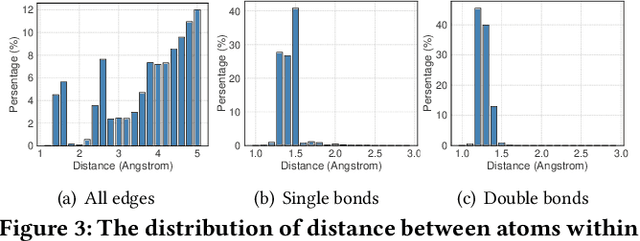
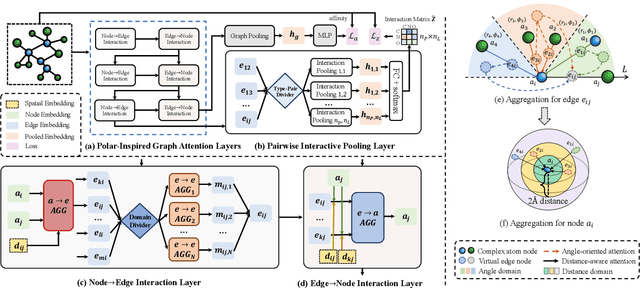
Drug discovery often relies on the successful prediction of protein-ligand binding affinity. Recent advances have shown great promise in applying graph neural networks (GNNs) for better affinity prediction by learning the representations of protein-ligand complexes. However, existing solutions usually treat protein-ligand complexes as topological graph data, thus the biomolecular structural information is not fully utilized. The essential long-range interactions among atoms are also neglected in GNN models. To this end, we propose a structure-aware interactive graph neural network (SIGN) which consists of two components: polar-inspired graph attention layers (PGAL) and pairwise interactive pooling (PiPool). Specifically, PGAL iteratively performs the node-edge aggregation process to update embeddings of nodes and edges while preserving the distance and angle information among atoms. Then, PiPool is adopted to gather interactive edges with a subsequent reconstruction loss to reflect the global interactions. Exhaustive experimental study on two benchmarks verifies the superiority of SIGN.
Property-aware Adaptive Relation Networks for Molecular Property Prediction
Jul 16, 2021
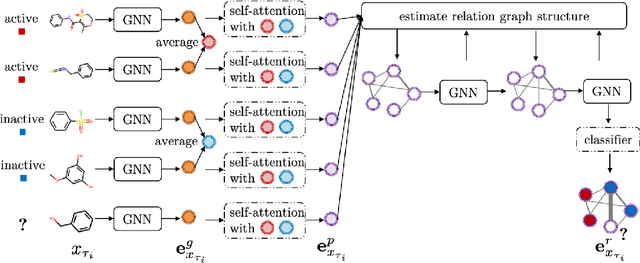
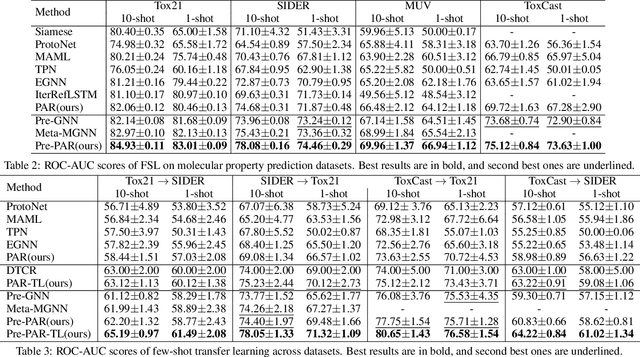
Molecular property prediction plays a fundamental role in drug discovery to discover candidate molecules with target properties. However, molecular property prediction is essentially a few-shot problem which makes it hard to obtain regular models. In this paper, we propose a property-aware adaptive relation networks (PAR) for the few-shot molecular property prediction problem. In comparison to existing works, we leverage the facts that both substructures and relationships among molecules are different considering various molecular properties. Our PAR is compatible with existing graph-based molecular encoders, and are further equipped with the ability to obtain property-aware molecular embedding and model molecular relation graph adaptively. The resultant relation graph also facilitates effective label propagation within each task. Extensive experiments on benchmark molecular property prediction datasets show that our method consistently outperforms state-of-the-art methods and is able to obtain property-aware molecular embedding and model molecular relation graph properly.
Noise Stability Regularization for Improving BERT Fine-tuning
Jul 10, 2021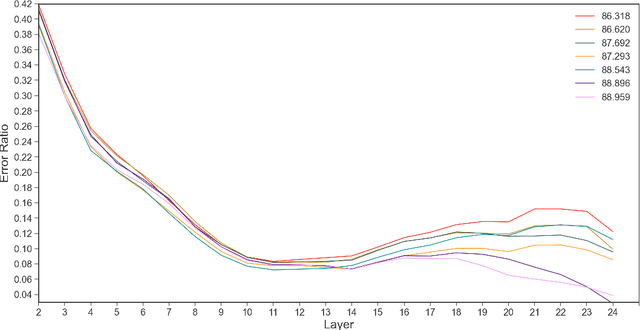
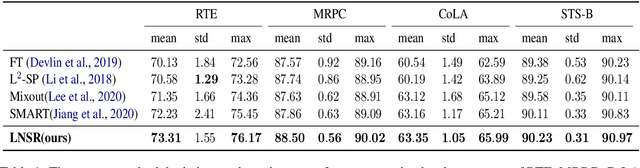

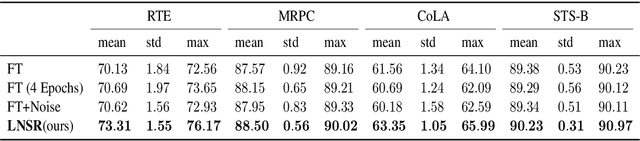
Fine-tuning pre-trained language models such as BERT has become a common practice dominating leaderboards across various NLP tasks. Despite its recent success and wide adoption, this process is unstable when there are only a small number of training samples available. The brittleness of this process is often reflected by the sensitivity to random seeds. In this paper, we propose to tackle this problem based on the noise stability property of deep nets, which is investigated in recent literature (Arora et al., 2018; Sanyal et al., 2020). Specifically, we introduce a novel and effective regularization method to improve fine-tuning on NLP tasks, referred to as Layer-wise Noise Stability Regularization (LNSR). We extend the theories about adding noise to the input and prove that our method gives a stabler regularization effect. We provide supportive evidence by experimentally confirming that well-performing models show a low sensitivity to noise and fine-tuning with LNSR exhibits clearly higher generalizability and stability. Furthermore, our method also demonstrates advantages over other state-of-the-art algorithms including L2-SP (Li et al., 2018), Mixout (Lee et al., 2020) and SMART (Jiang et al., 2020).
Robust Matrix Factorization with Grouping Effect
Jul 08, 2021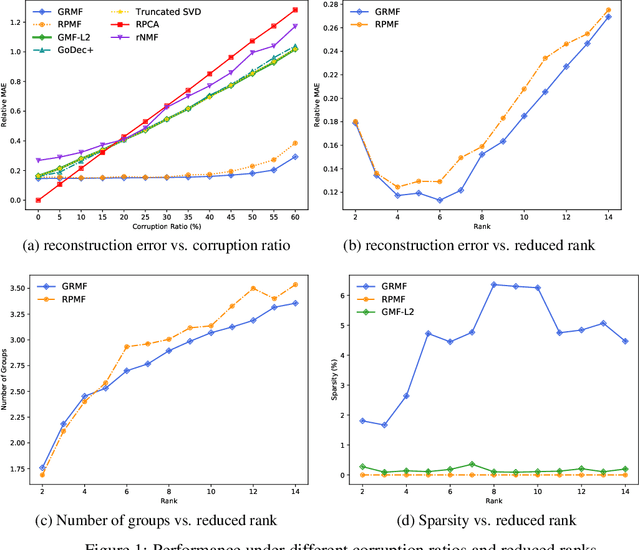

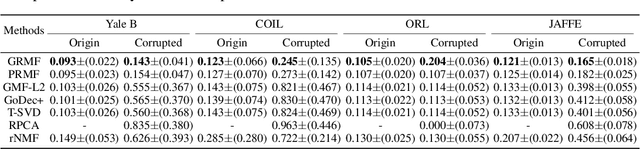

Although many techniques have been applied to matrix factorization (MF), they may not fully exploit the feature structure. In this paper, we incorporate the grouping effect into MF and propose a novel method called Robust Matrix Factorization with Grouping effect (GRMF). The grouping effect is a generalization of the sparsity effect, which conducts denoising by clustering similar values around multiple centers instead of just around 0. Compared with existing algorithms, the proposed GRMF can automatically learn the grouping structure and sparsity in MF without prior knowledge, by introducing a naturally adjustable non-convex regularization to achieve simultaneous sparsity and grouping effect. Specifically, GRMF uses an efficient alternating minimization framework to perform MF, in which the original non-convex problem is first converted into a convex problem through Difference-of-Convex (DC) programming, and then solved by Alternating Direction Method of Multipliers (ADMM). In addition, GRMF can be easily extended to the Non-negative Matrix Factorization (NMF) settings. Extensive experiments have been conducted using real-world data sets with outliers and contaminated noise, where the experimental results show that GRMF has promoted performance and robustness, compared to five benchmark algorithms.
Feature Grouping and Sparse Principal Component Analysis
Jun 25, 2021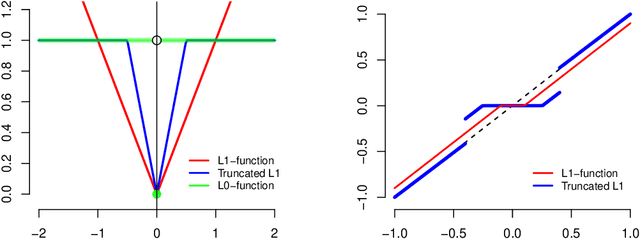
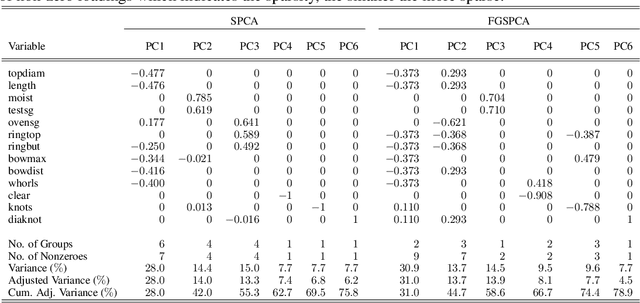
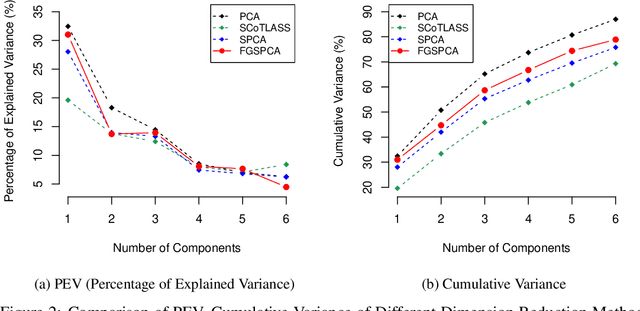
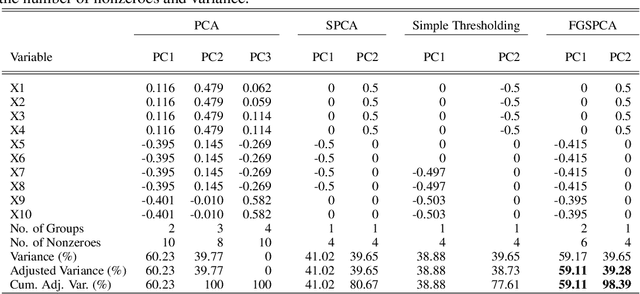
Sparse Principal Component Analysis (SPCA) is widely used in data processing and dimension reduction; it uses the lasso to produce modified principal components with sparse loadings for better interpretability. However, sparse PCA never considers an additional grouping structure where the loadings share similar coefficients (i.e., feature grouping), besides a special group with all coefficients being zero (i.e., feature selection). In this paper, we propose a novel method called Feature Grouping and Sparse Principal Component Analysis (FGSPCA) which allows the loadings to belong to disjoint homogeneous groups, with sparsity as a special case. The proposed FGSPCA is a subspace learning method designed to simultaneously perform grouping pursuit and feature selection, by imposing a non-convex regularization with naturally adjustable sparsity and grouping effect. To solve the resulting non-convex optimization problem, we propose an alternating algorithm that incorporates the difference-of-convex programming, augmented Lagrange and coordinate descent methods. Additionally, the experimental results on real data sets show that the proposed FGSPCA benefits from the grouping effect compared with methods without grouping effect.
Practical Assessment of Generalization Performance Robustness for Deep Networks via Contrastive Examples
Jun 20, 2021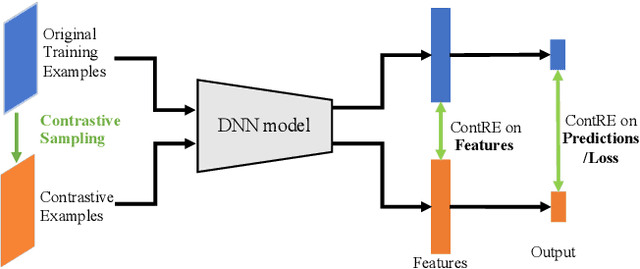
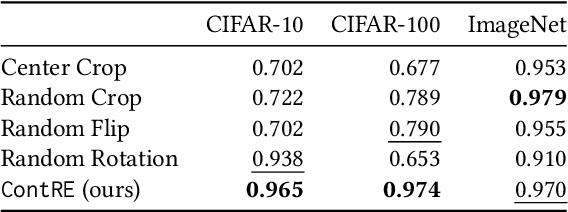
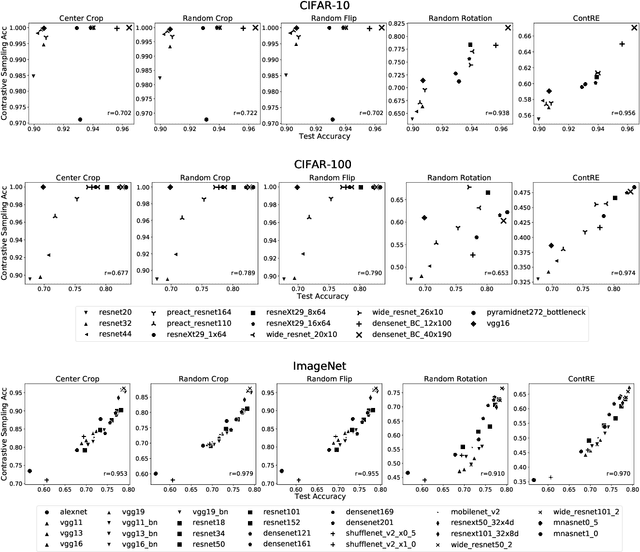
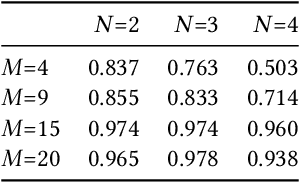
Training images with data transformations have been suggested as contrastive examples to complement the testing set for generalization performance evaluation of deep neural networks (DNNs). In this work, we propose a practical framework ContRE (The word "contre" means "against" or "versus" in French.) that uses Contrastive examples for DNN geneRalization performance Estimation. Specifically, ContRE follows the assumption in contrastive learning that robust DNN models with good generalization performance are capable of extracting a consistent set of features and making consistent predictions from the same image under varying data transformations. Incorporating with a set of randomized strategies for well-designed data transformations over the training set, ContRE adopts classification errors and Fisher ratios on the generated contrastive examples to assess and analyze the generalization performance of deep models in complement with a testing set. To show the effectiveness and the efficiency of ContRE, extensive experiments have been done using various DNN models on three open source benchmark datasets with thorough ablation studies and applicability analyses. Our experiment results confirm that (1) behaviors of deep models on contrastive examples are strongly correlated to what on the testing set, and (2) ContRE is a robust measure of generalization performance complementing to the testing set in various settings.