 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Detection by Exemplar-Guided Contrastive Learning
Nov 30, 2021
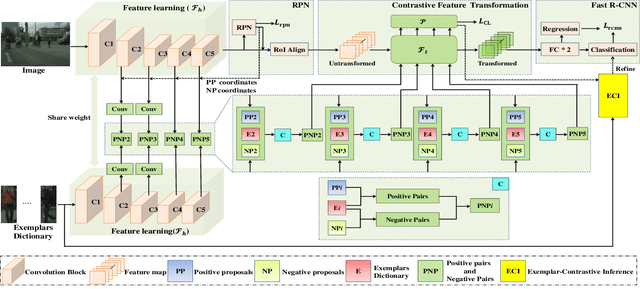
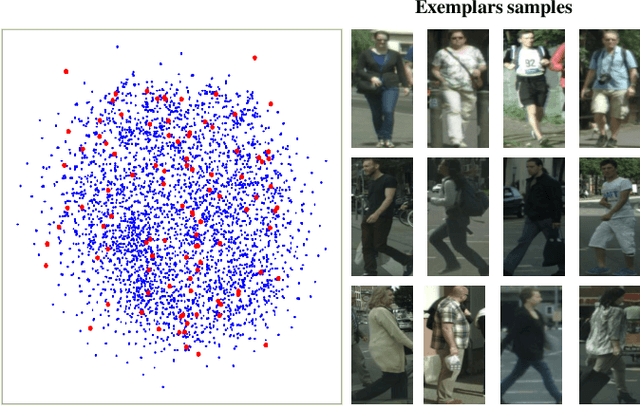
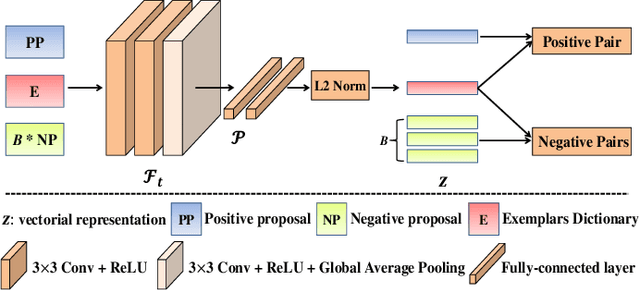
Typical methods for pedestrian detection focus on either tackling mutual occlusions between crowded pedestrians, or dealing with the various scales of pedestrians. Detecting pedestrians with substantial appearance diversities such as different pedestrian silhouettes, different viewpoints or different dressing, remains a crucial challenge. Instead of learning each of these diverse pedestrian appearance features individually as most existing methods do, we propose to perform contrastive learning to guide the feature learning in such a way that the semantic distance between pedestrians with different appearances in the learned feature space is minimized to eliminate the appearance diversities, whilst the distance between pedestrians and background is maximized. To facilitate the efficiency and effectiveness of contrastive learning, we construct an exemplar dictionary with representative pedestrian appearances as prior knowledge to construct effective contrastive training pairs and thus guide contrastive learning. Besides, the constructed exemplar dictionary is further leveraged to evaluate the quality of pedestrian proposals during inference by measuring the semantic distance between the proposal and the exemplar dictionary. Extensive experiments on both daytime and nighttime pedestrian detection validate the effectiveness of the proposed method.
Multi-modal Aggregation Network for Fast MR Imaging
Oct 20, 2021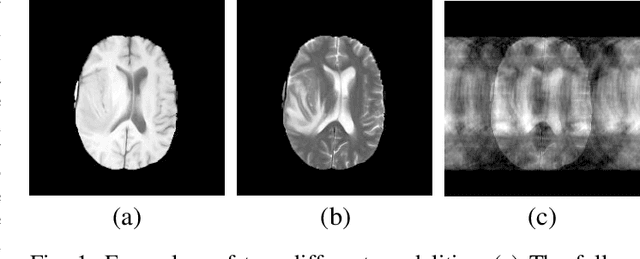
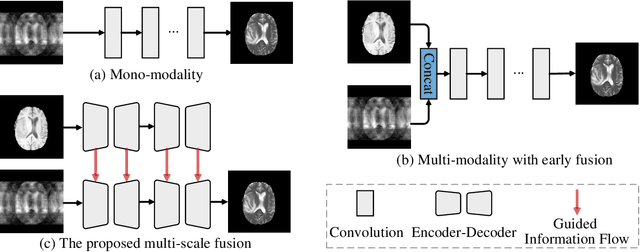
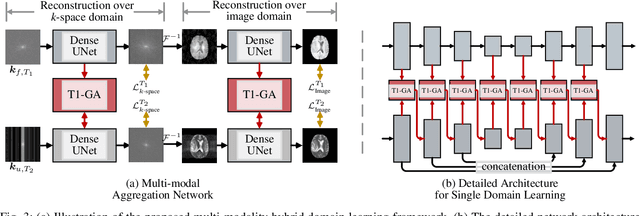
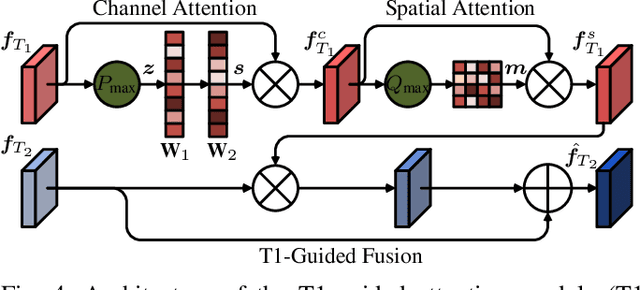
Magnetic resonance (MR) imaging is a commonly used scanning technique for disease detection, diagnosis and treatment monitoring. Although it is able to produce detailed images of organs and tissues with better contrast, it suffers from a long acquisition time, which makes the image quality vulnerable to say motion artifacts. Recently, many approaches have been developed to reconstruct full-sampled images from partially observed measurements in order to accelerate MR imaging. However, most of these efforts focus on reconstruction over a single modality or simple fusion of multiple modalities, neglecting the discovery of correlation knowledge at different feature level. In this work, we propose a novel Multi-modal Aggregation Network, named MANet, which is capable of discovering complementary representations from a fully sampled auxiliary modality, with which to hierarchically guide the reconstruction of a given target modality. In our MANet, the representations from the fully sampled auxiliary and undersampled target modalities are learned independently through a specific network. Then, a guided attention module is introduced in each convolutional stage to selectively aggregate multi-modal features for better reconstruction, yielding comprehensive, multi-scale, multi-modal feature fusion. Moreover, our MANet follows a hybrid domain learning framework, which allows it to simultaneously recover the frequency signal in the $k$-space domain as well as restore the image details from the image domain. Extensive experiments demonstrate the superiority of the proposed approach over state-of-the-art MR image reconstruction methods.
Stepwise-Refining Speech Separation Network via Fine-Grained Encoding in High-order Latent Domain
Oct 10, 2021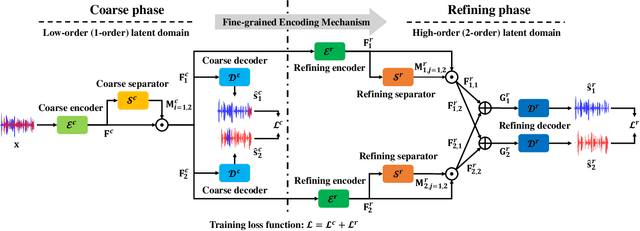
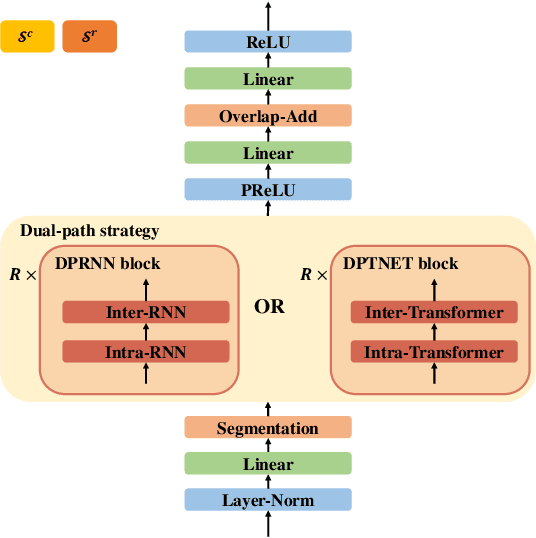
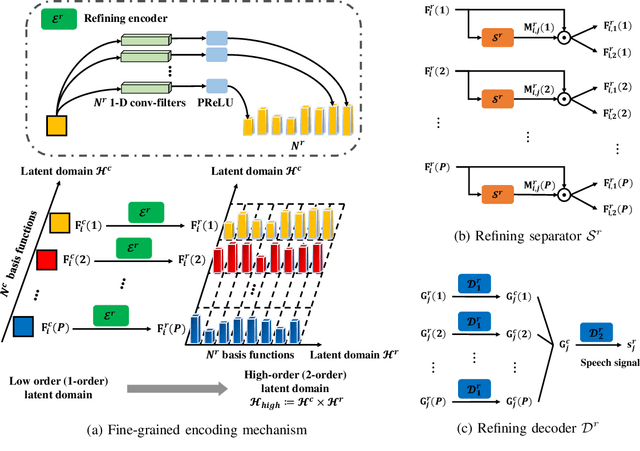
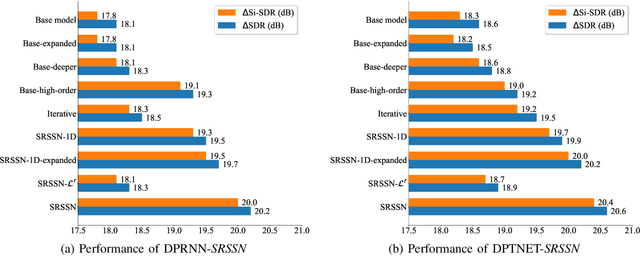
The crux of single-channel speech separation is how to encode the mixture of signals into such a latent embedding space that the signals from different speakers can be precisely separated. Existing methods for speech separation either transform the speech signals into frequency domain to perform separation or seek to learn a separable embedding space by constructing a latent domain based on convolutional filters. While the latter type of methods learning an embedding space achieves substantial improvement for speech separation, we argue that the embedding space defined by only one latent domain does not suffice to provide a thoroughly separable encoding space for speech separation. In this paper, we propose the Stepwise-Refining Speech Separation Network (SRSSN), which follows a coarse-to-fine separation framework. It first learns a 1-order latent domain to define an encoding space and thereby performs a rough separation in the coarse phase. Then the proposed SRSSN learns a new latent domain along each basis function of the existing latent domain to obtain a high-order latent domain in the refining phase, which enables our model to perform a refining separation to achieve a more precise speech separation. We demonstrate the effectiveness of our SRSSN by conducting extensive experiments, including speech separation in a clean (noise-free) setting on WSJ0-2/3mix datasets as well as in noisy/reverberant settings on WHAM!/WHAMR! datasets. Furthermore, we also perform experiments of speech recognition on separated speech signals by our model to evaluate the performance of speech separation indirectly.
BPFNet: A Unified Framework for Bimodal Palmprint Alignment and Fusion
Oct 04, 2021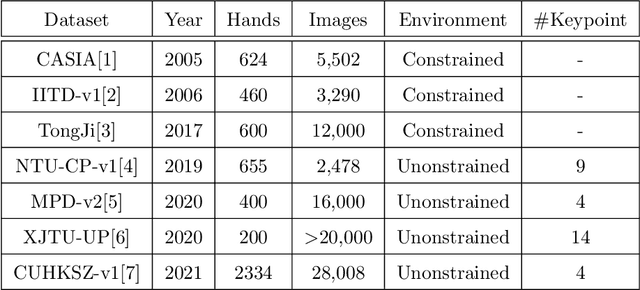
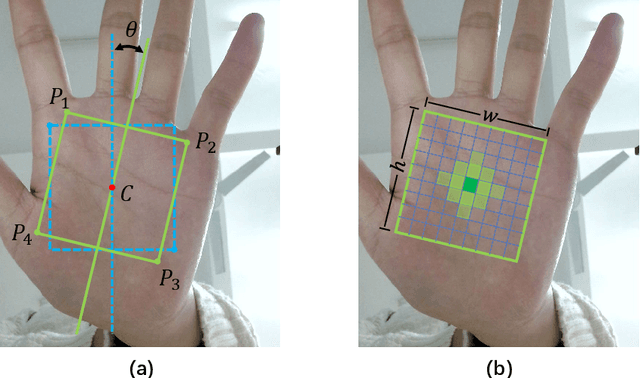
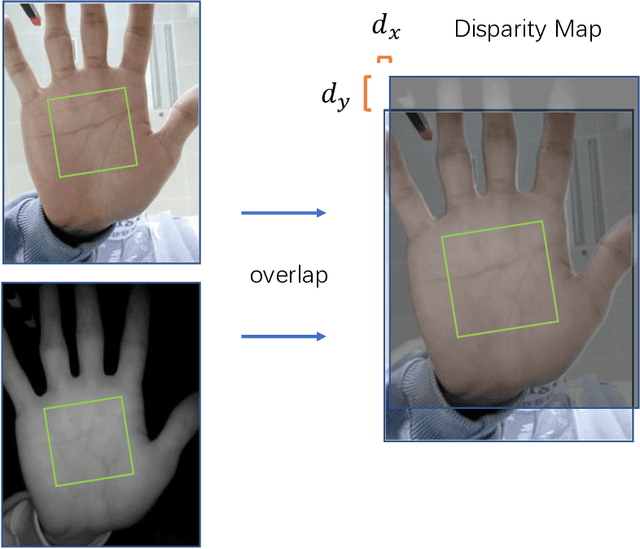
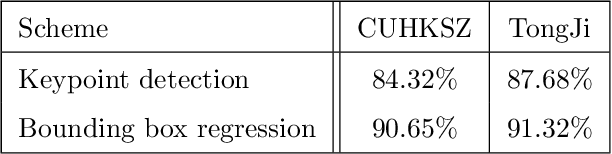
Bimodal palmprint recognition leverages palmprint and palm vein images simultaneously,which achieves high accuracy by multi-model information fusion and has strong anti-falsification property. In the recognition pipeline, the detection of palm and the alignment of region-of-interest (ROI) are two crucial steps for accurate matching. Most existing methods localize palm ROI by keypoint detection algorithms, however the intrinsic difficulties of keypoint detection tasks make the results unsatisfactory. Besides, the ROI alignment and fusion algorithms at image-level are not fully investigaged.To bridge the gap, in this paper, we propose Bimodal Palmprint Fusion Network (BPFNet) which focuses on ROI localization, alignment and bimodal image fusion.BPFNet is an end-to-end framework containing two subnets: The detection network directly regresses the palmprint ROIs based on bounding box prediction and conducts alignment by translation estimation.In the downstream,the bimodal fusion network implements bimodal ROI image fusion leveraging a novel proposed cross-modal selection scheme. To show the effectiveness of BPFNet,we carry out experiments on the large-scale touchless palmprint datasets CUHKSZ-v1 and TongJi and the proposed method achieves state-of-the-art performances.
Generative Memory-Guided Semantic Reasoning Model for Image Inpainting
Oct 01, 2021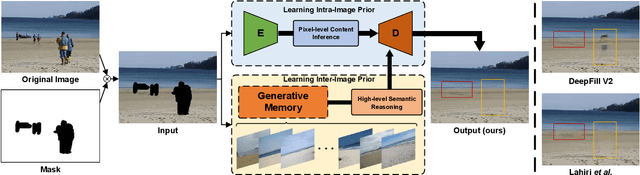

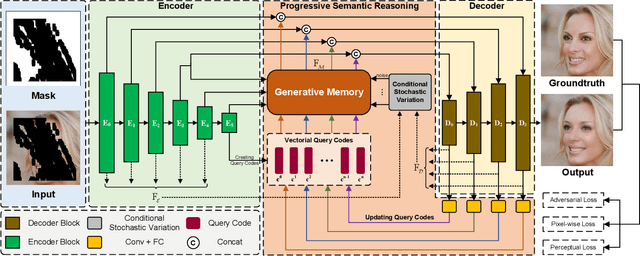
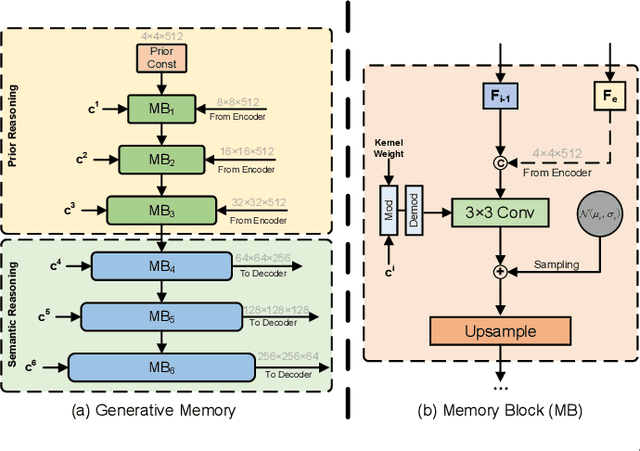
Most existing methods for image inpainting focus on learning the intra-image priors from the known regions of the current input image to infer the content of the corrupted regions in the same image. While such methods perform well on images with small corrupted regions, it is challenging for these methods to deal with images with large corrupted area due to two potential limitations: 1) such methods tend to overfit each single training pair of images relying solely on the intra-image prior knowledge learned from the limited known area; 2) the inter-image prior knowledge about the general distribution patterns of visual semantics, which can be transferred across images sharing similar semantics, is not exploited. In this paper, we propose the Generative Memory-Guided Semantic Reasoning Model (GM-SRM), which not only learns the intra-image priors from the known regions, but also distills the inter-image reasoning priors to infer the content of the corrupted regions. In particular, the proposed GM-SRM first pre-learns a generative memory from the whole training data to capture the semantic distribution patterns in a global view. Then the learned memory are leveraged to retrieve the matching inter-image priors for the current corrupted image to perform semantic reasoning during image inpainting. While the intra-image priors are used for guaranteeing the pixel-level content consistency, the inter-image priors are favorable for performing high-level semantic reasoning, which is particularly effective for inferring semantic content for large corrupted area. Extensive experiments on Paris Street View, CelebA-HQ, and Places2 benchmarks demonstrate that our GM-SRM outperforms the state-of-the-art methods for image inpainting in terms of both the visual quality and quantitative metrics.
TransAttUnet: Multi-level Attention-guided U-Net with Transformer for Medical Image Segmentation
Jul 12, 2021
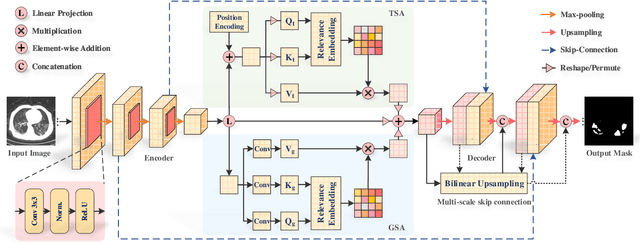
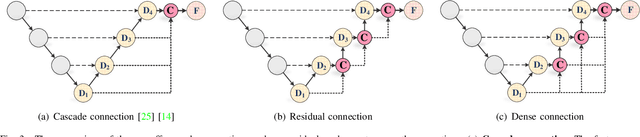
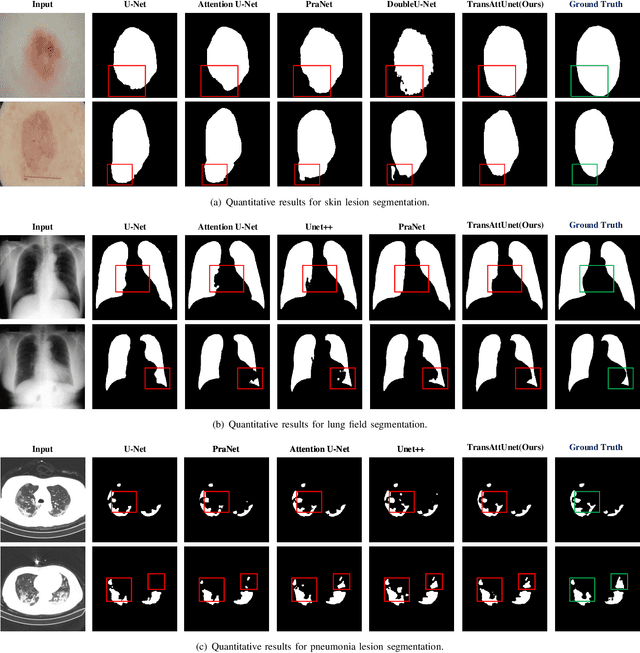
With the development of deep encoder-decoder architectures and large-scale annotated medical datasets, great progress has been achieved in the development of automatic medical image segmentation. Due to the stacking of convolution layers and the consecutive sampling operations, existing standard models inevitably encounter the information recession problem of feature representations, which fails to fully model the global contextual feature dependencies. To overcome the above challenges, this paper proposes a novel Transformer based medical image semantic segmentation framework called TransAttUnet, in which the multi-level guided attention and multi-scale skip connection are jointly designed to effectively enhance the functionality and flexibility of traditional U-shaped architecture. Inspired by Transformer, a novel self-aware attention (SAA) module with both Transformer Self Attention (TSA) and Global Spatial Attention (GSA) is incorporated into TransAttUnet to effectively learn the non-local interactions between encoder features. In particular, we also establish additional multi-scale skip connections between decoder blocks to aggregate the different semantic-scale upsampling features. In this way, the representation ability of multi-scale context information is strengthened to generate discriminative features. Benefitting from these complementary components, the proposed TransAttUnet can effectively alleviate the loss of fine details caused by the information recession problem, improving the diagnostic sensitivity and segmentation quality of medical image analysis. Extensive experiments on multiple medical image segmentation datasets of different imaging demonstrate that our method consistently outperforms the state-of-the-art baselines.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021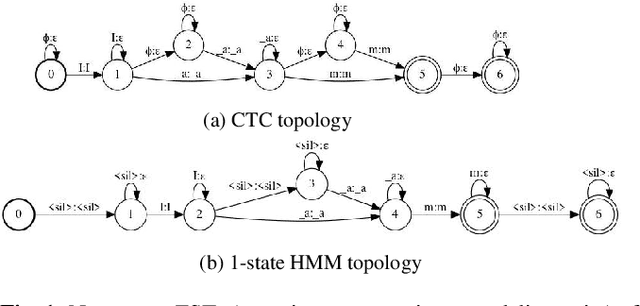
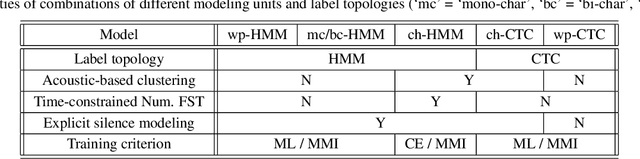
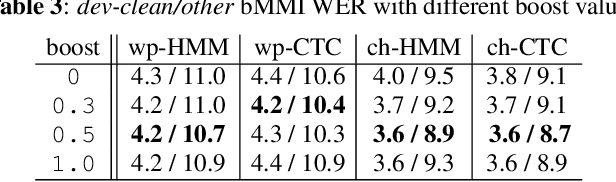
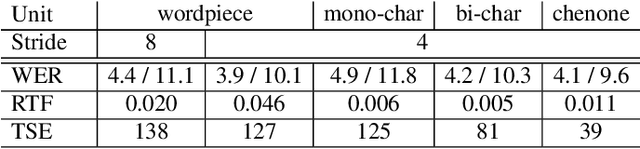
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
Dual-Stream Reciprocal Disentanglement Learning for Domain Adaption Person Re-Identification
Jun 26, 2021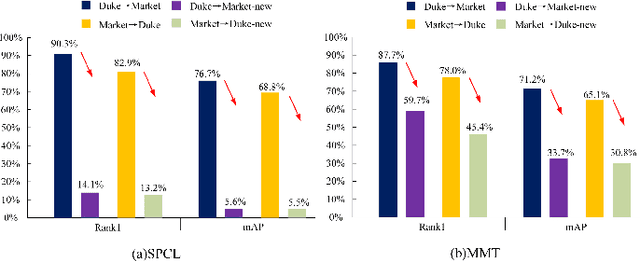
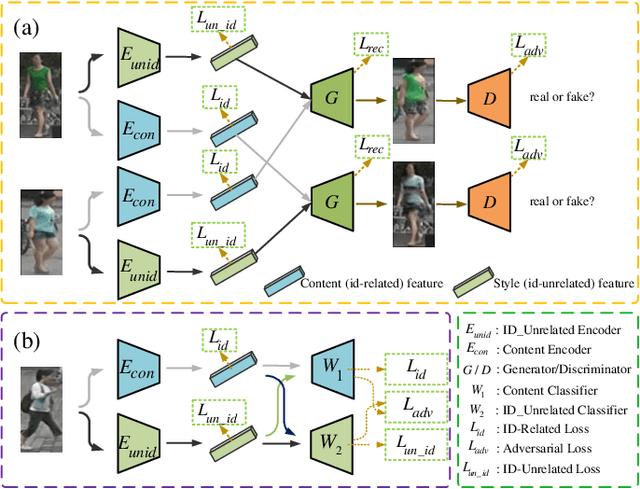
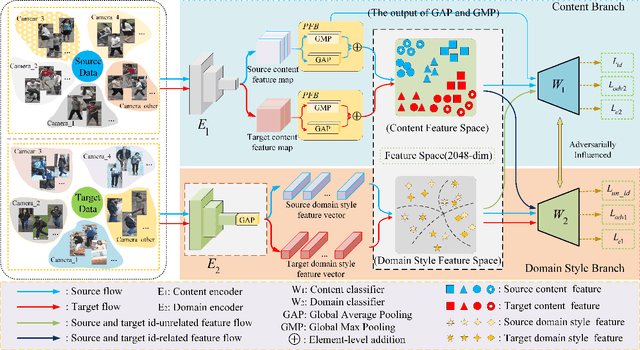
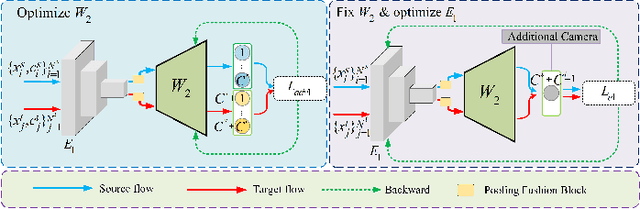
Since human-labeled samples are free for the target set, unsupervised person re-identification (Re-ID) has attracted much attention in recent years, by additionally exploiting the source set. However, due to the differences on camera styles, illumination and backgrounds, there exists a large gap between source domain and target domain, introducing a great challenge on cross-domain matching. To tackle this problem, in this paper we propose a novel method named Dual-stream Reciprocal Disentanglement Learning (DRDL), which is quite efficient in learning domain-invariant features. In DRDL, two encoders are first constructed for id-related and id-unrelated feature extractions, which are respectively measured by their associated classifiers. Furthermore, followed by an adversarial learning strategy, both streams reciprocally and positively effect each other, so that the id-related features and id-unrelated features are completely disentangled from a given image, allowing the encoder to be powerful enough to obtain the discriminative but domain-invariant features. In contrast to existing approaches, our proposed method is free from image generation, which not only reduces the computational complexity remarkably, but also removes redundant information from id-related features. Extensive experiments substantiate the superiority of our proposed method compared with the state-of-the-arts. The source code has been released in https://github.com/lhf12278/DRDL.
Asymmetric CNN for image super-resolution
Mar 30, 2021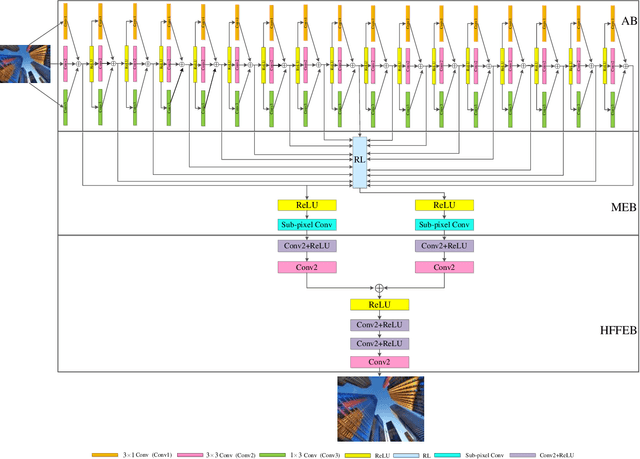
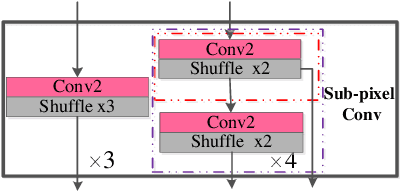
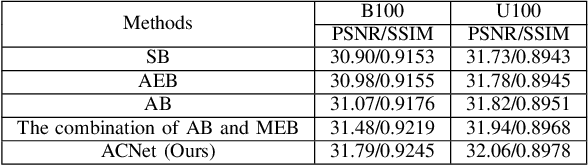
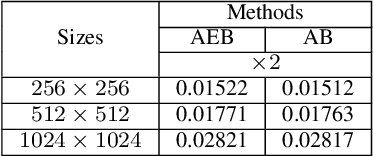
Deep convolutional neural networks (CNNs) have been widely applied for low-level vision over the past five years. According to nature of different applications, designing appropriate CNN architectures is developed. However, customized architectures gather different features via treating all pixel points as equal to improve the performance of given application, which ignores the effects of local power pixel points and results in low training efficiency. In this paper, we propose an asymmetric CNN (ACNet) comprising an asymmetric block (AB), a memory enhancement block (MEB) and a high-frequency feature enhancement block (HFFEB) for image super-resolution. The AB utilizes one-dimensional asymmetric convolutions to intensify the square convolution kernels in horizontal and vertical directions for promoting the influences of local salient features for SISR. The MEB fuses all hierarchical low-frequency features from the AB via residual learning (RL) technique to resolve the long-term dependency problem and transforms obtained low-frequency features into high-frequency features. The HFFEB exploits low- and high-frequency features to obtain more robust super-resolution features and address excessive feature enhancement problem. Addditionally, it also takes charge of reconstructing a high-resolution (HR) image. Extensive experiments show that our ACNet can effectively address single image super-resolution (SISR), blind SISR and blind SISR of blind noise problems. The code of the ACNet is shown at https://github.com/hellloxiaotian/ACNet.
Touchless Palmprint Recognition based on 3D Gabor Template and Block Feature Refinement
Mar 03, 2021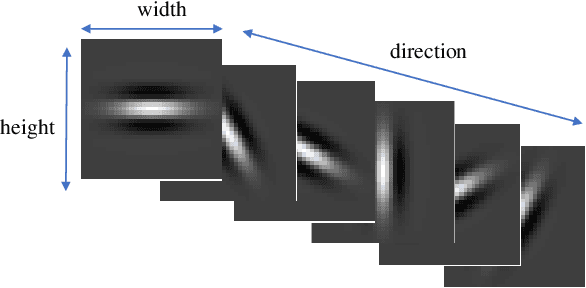
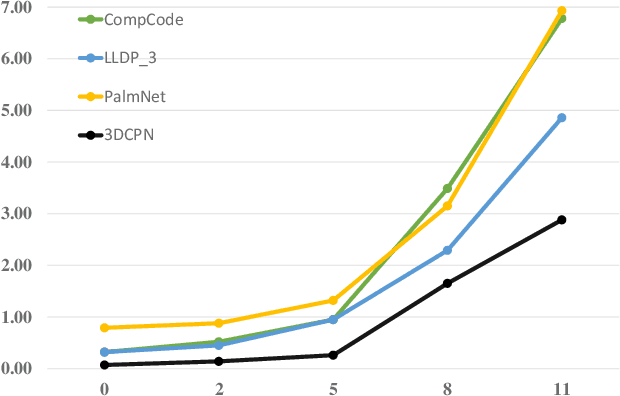
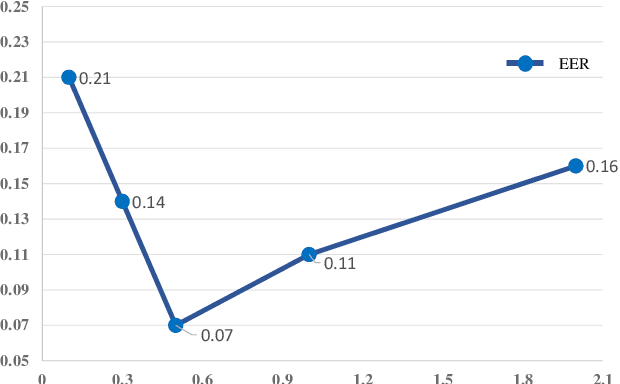

With the growing demand for hand hygiene and convenience of use, palmprint recognition with touchless manner made a great development recently, providing an effective solution for person identification. Despite many efforts that have been devoted to this area, it is still uncertain about the discriminative ability of the contactless palmprint, especially for large-scale datasets. To tackle the problem, in this paper, we build a large-scale touchless palmprint dataset containing 2334 palms from 1167 individuals. To our best knowledge, it is the largest contactless palmprint image benchmark ever collected with regard to the number of individuals and palms. Besides, we propose a novel deep learning framework for touchless palmprint recognition named 3DCPN (3D Convolution Palmprint recognition Network) which leverages 3D convolution to dynamically integrate multiple Gabor features. In 3DCPN, a novel variant of Gabor filter is embedded into the first layer for enhancement of curve feature extraction. With a well-designed ensemble scheme,low-level 3D features are then convolved to extract high-level features. Finally on the top, we set a region-based loss function to strengthen the discriminative ability of both global and local descriptors. To demonstrate the superiority of our method, extensive experiments are conducted on our dataset and other popular databases TongJi and IITD, where the results show the proposed 3DCPN achieves state-of-the-art or comparable performances.