 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustState: Boosting Fidelity of Quantum State Preparation via Noise-Aware Variational Training
Nov 27, 2023



Quantum state preparation, a crucial subroutine in quantum computing, involves generating a target quantum state from initialized qubits. Arbitrary state preparation algorithms can be broadly categorized into arithmetic decomposition (AD) and variational quantum state preparation (VQSP). AD employs a predefined procedure to decompose the target state into a series of gates, whereas VQSP iteratively tunes ansatz parameters to approximate target state. VQSP is particularly apt for Noisy-Intermediate Scale Quantum (NISQ) machines due to its shorter circuits. However, achieving noise-robust parameter optimization still remains challenging. We present RobustState, a novel VQSP training methodology that combines high robustness with high training efficiency. The core idea involves utilizing measurement outcomes from real machines to perform back-propagation through classical simulators, thus incorporating real quantum noise into gradient calculations. RobustState serves as a versatile, plug-and-play technique applicable for training parameters from scratch or fine-tuning existing parameters to enhance fidelity on target machines. It is adaptable to various ansatzes at both gate and pulse levels and can even benefit other variational algorithms, such as variational unitary synthesis. Comprehensive evaluation of RobustState on state preparation tasks for 4 distinct quantum algorithms using 10 real quantum machines demonstrates a coherent error reduction of up to 7.1 $\times$ and state fidelity improvement of up to 96\% and 81\% for 4-Q and 5-Q states, respectively. On average, RobustState improves fidelity by 50\% and 72\% for 4-Q and 5-Q states compared to baseline approaches.
Practical Layout-Aware Analog/Mixed-Signal Design Automation with Bayesian Neural Networks
Nov 27, 2023The high simulation cost has been a bottleneck of practical analog/mixed-signal design automation. Many learning-based algorithms require thousands of simulated data points, which is impractical for expensive to simulate circuits. We propose a learning-based algorithm that can be trained using a small amount of data and, therefore, scalable to tasks with expensive simulations. Our efficient algorithm solves the post-layout performance optimization problem where simulations are known to be expensive. Our comprehensive study also solves the schematic-level sizing problem. For efficient optimization, we utilize Bayesian Neural Networks as a regression model to approximate circuit performance. For layout-aware optimization, we handle the problem as a multi-fidelity optimization problem and improve efficiency by exploiting the correlations from cheaper evaluations. We present three test cases to demonstrate the efficiency of our algorithms. Our tests prove that the proposed approach is more efficient than conventional baselines and state-of-the-art algorithms.
M3ICRO: Machine Learning-Enabled Compact Photonic Tensor Core based on PRogrammable Multi-Operand Multimode Interference
May 31, 2023



Photonic computing shows promise for transformative advancements in machine learning (ML) acceleration, offering ultra-fast speed, massive parallelism, and high energy efficiency. However, current photonic tensor core (PTC) designs based on standard optical components hinder scalability and compute density due to their large spatial footprint. To address this, we propose an ultra-compact PTC using customized programmable multi-operand multimode interference (MOMMI) devices, named M3ICRO. The programmable MOMMI leverages the intrinsic light propagation principle, providing a single-device programmable matrix unit beyond the conventional computing paradigm of one multiply-accumulate (MAC) operation per device. To overcome the optimization difficulty of customized devices that often requires time-consuming simulation, we apply ML for optics to predict the device behavior and enable a differentiable optimization flow. We thoroughly investigate the reconfigurability and matrix expressivity of our customized PTC, and introduce a novel block unfolding method to fully exploit the computing capabilities of a complex-valued PTC for near-universal real-valued linear transformations. Extensive evaluations demonstrate that M3ICRO achieves a 3.4-9.6x smaller footprint, 1.6-4.4x higher speed, 10.6-42x higher compute density, 3.7-12x higher system throughput, and superior noise robustness compared to state-of-the-art coherent PTC designs, while maintaining close-to-digital task accuracy across various ML benchmarks. Our code is open-sourced at https://github.com/JeremieMelo/M3ICRO-MOMMI.
Integrated multi-operand optical neurons for scalable and hardware-efficient deep learning
May 31, 2023The optical neural network (ONN) is a promising hardware platform for next-generation neuromorphic computing due to its high parallelism, low latency, and low energy consumption. However, previous integrated photonic tensor cores (PTCs) consume numerous single-operand optical modulators for signal and weight encoding, leading to large area costs and high propagation loss to implement large tensor operations. This work proposes a scalable and efficient optical dot-product engine based on customized multi-operand photonic devices, namely multi-operand optical neurons (MOON). We experimentally demonstrate the utility of a MOON using a multi-operand-Mach-Zehnder-interferometer (MOMZI) in image recognition tasks. Specifically, our MOMZI-based ONN achieves a measured accuracy of 85.89% in the street view house number (SVHN) recognition dataset with 4-bit voltage control precision. Furthermore, our performance analysis reveals that a 128x128 MOMZI-based PTCs outperform their counterparts based on single-operand MZIs by one to two order-of-magnitudes in propagation loss, optical delay, and total device footprint, with comparable matrix expressivity.
Pre-RMSNorm and Pre-CRMSNorm Transformers: Equivalent and Efficient Pre-LN Transformers
May 24, 2023



Transformers have achieved great success in machine learning applications. Normalization techniques, such as Layer Normalization (LayerNorm, LN) and Root Mean Square Normalization (RMSNorm), play a critical role in accelerating and stabilizing the training of Transformers. While LayerNorm recenters and rescales input vectors, RMSNorm only rescales the vectors by their RMS value. Despite being more computationally efficient, RMSNorm may compromise the representation ability of Transformers. There is currently no consensus regarding the preferred normalization technique, as some models employ LayerNorm while others utilize RMSNorm, especially in recent large language models. It is challenging to convert Transformers with one normalization to the other type. While there is an ongoing disagreement between the two normalization types, we propose a solution to unify two mainstream Transformer architectures, Pre-LN and Pre-RMSNorm Transformers. By removing the inherent redundant mean information in the main branch of Pre-LN Transformers, we can reduce LayerNorm to RMSNorm, achieving higher efficiency. We further propose the Compressed RMSNorm (CRMSNorm) and Pre-CRMSNorm Transformer based on a lossless compression of the zero-mean vectors. We formally establish the equivalence of Pre-LN, Pre-RMSNorm, and Pre-CRMSNorm Transformer variants in both training and inference. It implies that Pre-LN Transformers can be substituted with Pre-(C)RMSNorm counterparts at almost no cost, offering the same arithmetic functionality along with free efficiency improvement. Experiments demonstrate that we can reduce the training and inference time of Pre-LN Transformers by up to 10%.
HEAT: Hardware-Efficient Automatic Tensor Decomposition for Transformer Compression
Nov 30, 2022



Transformers have attained superior performance in natural language processing and computer vision. Their self-attention and feedforward layers are overparameterized, limiting inference speed and energy efficiency. Tensor decomposition is a promising technique to reduce parameter redundancy by leveraging tensor algebraic properties to express the parameters in a factorized form. Prior efforts used manual or heuristic factorization settings without hardware-aware customization, resulting in poor hardware efficiencies and large performance degradation. In this work, we propose a hardware-aware tensor decomposition framework, dubbed HEAT, that enables efficient exploration of the exponential space of possible decompositions and automates the choice of tensorization shape and decomposition rank with hardware-aware co-optimization. We jointly investigate tensor contraction path optimizations and a fused Einsum mapping strategy to bridge the gap between theoretical benefits and real hardware efficiency improvement. Our two-stage knowledge distillation flow resolves the trainability bottleneck and thus significantly boosts the final accuracy of factorized Transformers. Overall, we experimentally show that our hardware-aware factorized BERT variants reduce the energy-delay product by 5.7x with less than 1.1% accuracy loss and achieve a better efficiency-accuracy Pareto frontier than hand-tuned and heuristic baselines.
QuEst: Graph Transformer for Quantum Circuit Reliability Estimation
Oct 30, 2022Among different quantum algorithms, PQC for QML show promises on near-term devices. To facilitate the QML and PQC research, a recent python library called TorchQuantum has been released. It can construct, simulate, and train PQC for machine learning tasks with high speed and convenient debugging supports. Besides quantum for ML, we want to raise the community's attention on the reversed direction: ML for quantum. Specifically, the TorchQuantum library also supports using data-driven ML models to solve problems in quantum system research, such as predicting the impact of quantum noise on circuit fidelity and improving the quantum circuit compilation efficiency. This paper presents a case study of the ML for quantum part. Since estimating the noise impact on circuit reliability is an essential step toward understanding and mitigating noise, we propose to leverage classical ML to predict noise impact on circuit fidelity. Inspired by the natural graph representation of quantum circuits, we propose to leverage a graph transformer model to predict the noisy circuit fidelity. We firstly collect a large dataset with a variety of quantum circuits and obtain their fidelity on noisy simulators and real machines. Then we embed each circuit into a graph with gate and noise properties as node features, and adopt a graph transformer to predict the fidelity. Evaluated on 5 thousand random and algorithm circuits, the graph transformer predictor can provide accurate fidelity estimation with RMSE error 0.04 and outperform a simple neural network-based model by 0.02 on average. It can achieve 0.99 and 0.95 R$^2$ scores for random and algorithm circuits, respectively. Compared with circuit simulators, the predictor has over 200X speedup for estimating the fidelity.
An Adversarial Active Sampling-based Data Augmentation Framework for Manufacturable Chip Design
Oct 27, 2022Lithography modeling is a crucial problem in chip design to ensure a chip design mask is manufacturable. It requires rigorous simulations of optical and chemical models that are computationally expensive. Recent developments in machine learning have provided alternative solutions in replacing the time-consuming lithography simulations with deep neural networks. However, the considerable accuracy drop still impedes its industrial adoption. Most importantly, the quality and quantity of the training dataset directly affect the model performance. To tackle this problem, we propose a litho-aware data augmentation (LADA) framework to resolve the dilemma of limited data and improve the machine learning model performance. First, we pretrain the neural networks for lithography modeling and a gradient-friendly StyleGAN2 generator. We then perform adversarial active sampling to generate informative and synthetic in-distribution mask designs. These synthetic mask images will augment the original limited training dataset used to finetune the lithography model for improved performance. Experimental results demonstrate that LADA can successfully exploits the neural network capacity by narrowing down the performance gap between the training and testing data instances.
NeurOLight: A Physics-Agnostic Neural Operator Enabling Parametric Photonic Device Simulation
Sep 19, 2022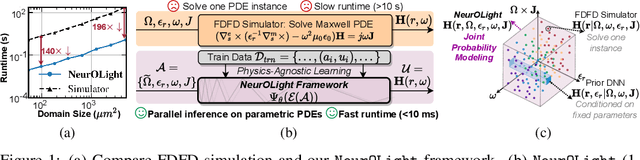
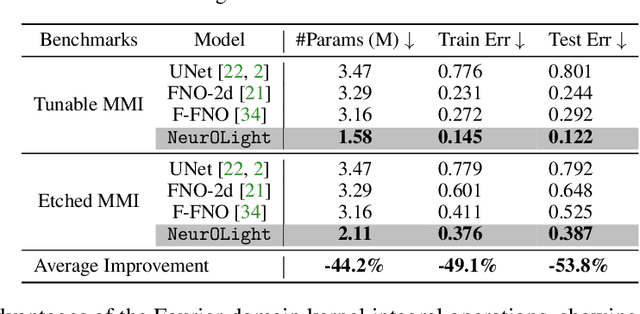
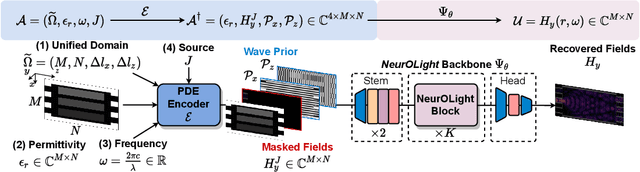
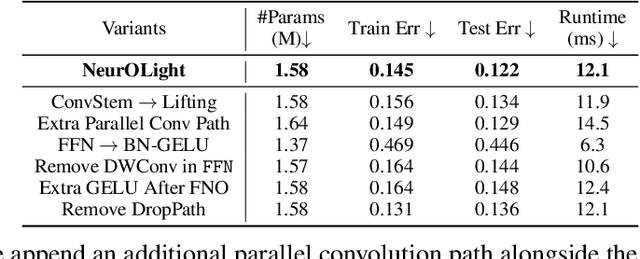
Optical computing is an emerging technology for next-generation efficient artificial intelligence (AI) due to its ultra-high speed and efficiency. Electromagnetic field simulation is critical to the design, optimization, and validation of photonic devices and circuits. However, costly numerical simulation significantly hinders the scalability and turn-around time in the photonic circuit design loop. Recently, physics-informed neural networks have been proposed to predict the optical field solution of a single instance of a partial differential equation (PDE) with predefined parameters. Their complicated PDE formulation and lack of efficient parametrization mechanisms limit their flexibility and generalization in practical simulation scenarios. In this work, for the first time, a physics-agnostic neural operator-based framework, dubbed NeurOLight, is proposed to learn a family of frequency-domain Maxwell PDEs for ultra-fast parametric photonic device simulation. We balance the efficiency and generalization of NeurOLight via several novel techniques. Specifically, we discretize different devices into a unified domain, represent parametric PDEs with a compact wave prior, and encode the incident light via masked source modeling. We design our model with parameter-efficient cross-shaped NeurOLight blocks and adopt superposition-based augmentation for data-efficient learning. With these synergistic approaches, NeurOLight generalizes to a large space of unseen simulation settings, demonstrates 2-orders-of-magnitude faster simulation speed than numerical solvers, and outperforms prior neural network models by ~54% lower prediction error with ~44% fewer parameters. Our code is available at https://github.com/JeremieMelo/NeurOLight.
TAG: Learning Circuit Spatial Embedding From Layouts
Sep 07, 2022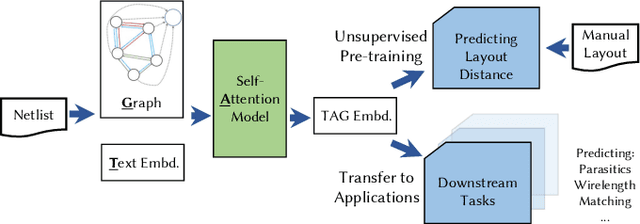
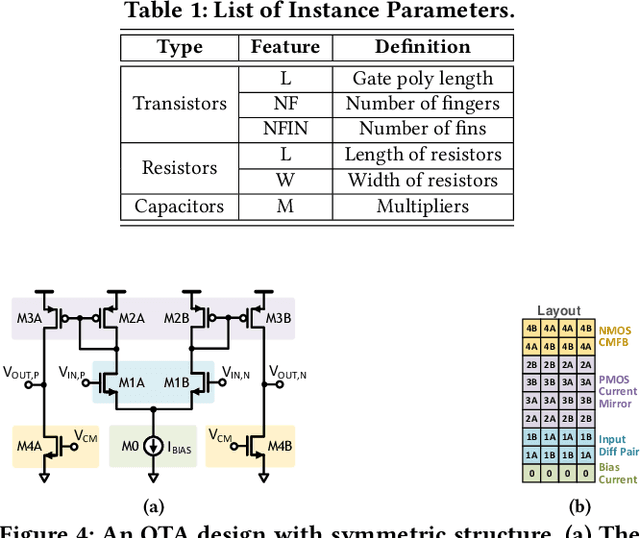
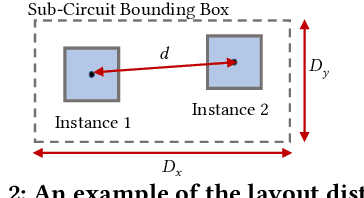
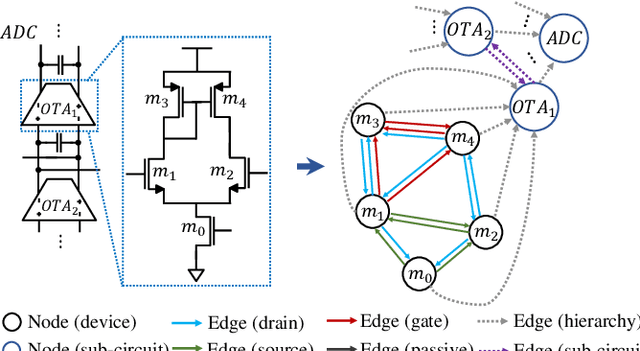
Analog and mixed-signal (AMS) circuit designs still rely on human design expertise. Machine learning has been assisting circuit design automation by replacing human experience with artificial intelligence. This paper presents TAG, a new paradigm of learning the circuit representation from layouts leveraging text, self-attention and graph. The embedding network model learns spatial information without manual labeling. We introduce text embedding and a self-attention mechanism to AMS circuit learning. Experimental results demonstrate the ability to predict layout distances between instances with industrial FinFET technology benchmarks. The effectiveness of the circuit representation is verified by showing the transferability to three other learning tasks with limited data in the case studies: layout matching prediction, wirelength estimation, and net parasitic capacitance prediction.