 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer
Jun 14, 2022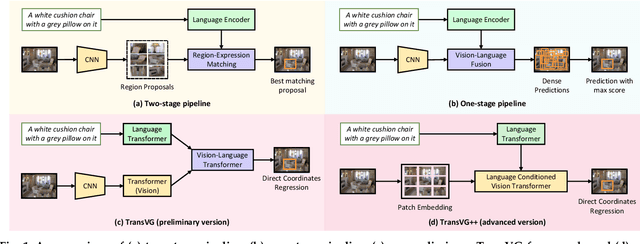
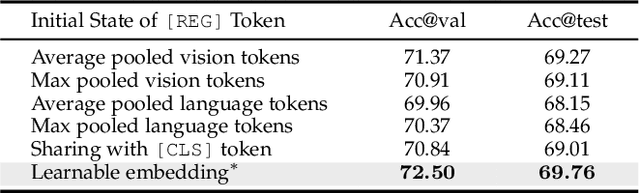
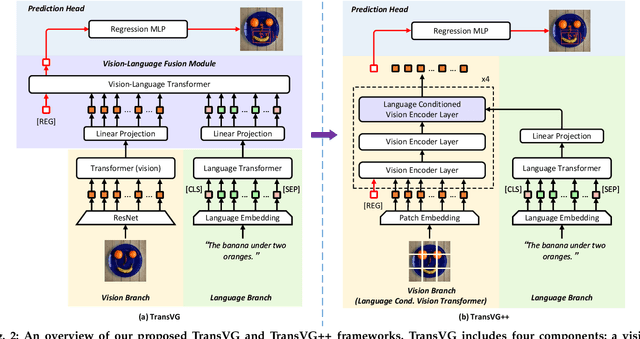
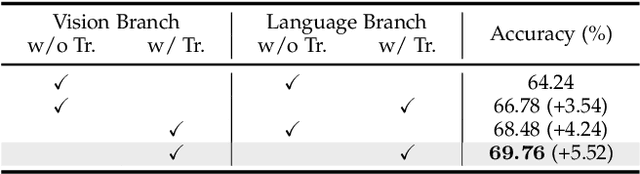
In this work, we explore neat yet effective Transformer-based frameworks for visual grounding. The previous methods generally address the core problem of visual grounding, i.e., multi-modal fusion and reasoning, with manually-designed mechanisms. Such heuristic designs are not only complicated but also make models easily overfit specific data distributions. To avoid this, we first propose TransVG, which establishes multi-modal correspondences by Transformers and localizes referred regions by directly regressing box coordinates. We empirically show that complicated fusion modules can be replaced by a simple stack of Transformer encoder layers with higher performance. However, the core fusion Transformer in TransVG is stand-alone against uni-modal encoders, and thus should be trained from scratch on limited visual grounding data, which makes it hard to be optimized and leads to sub-optimal performance. To this end, we further introduce TransVG++ to make two-fold improvements. For one thing, we upgrade our framework to a purely Transformer-based one by leveraging Vision Transformer (ViT) for vision feature encoding. For another, we devise Language Conditioned Vision Transformer that removes external fusion modules and reuses the uni-modal ViT for vision-language fusion at the intermediate layers. We conduct extensive experiments on five prevalent datasets, and report a series of state-of-the-art records.
Modeling Image Composition for Complex Scene Generation
Jun 02, 2022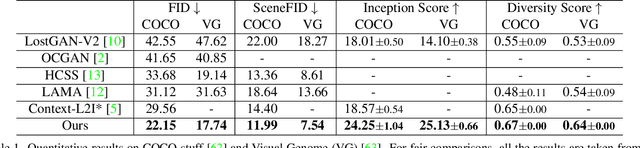
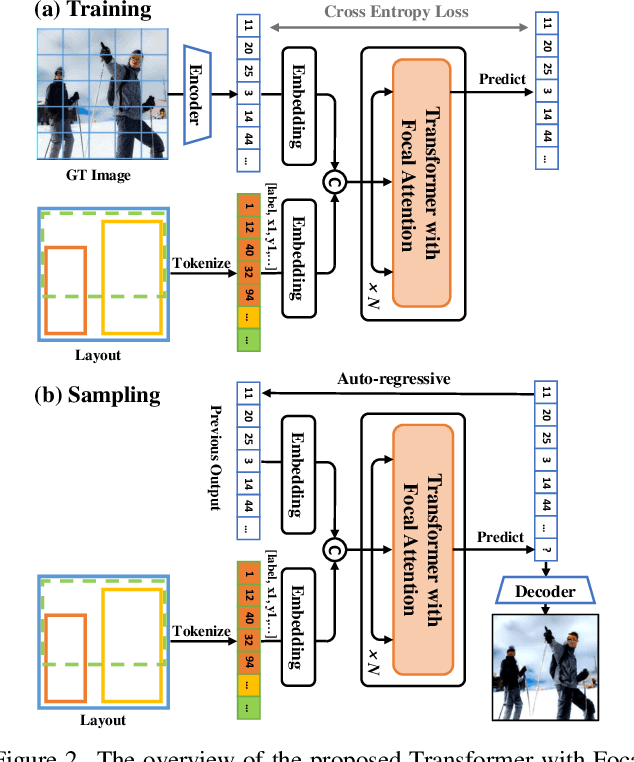
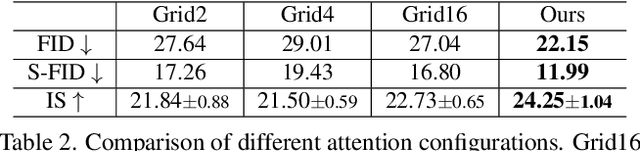
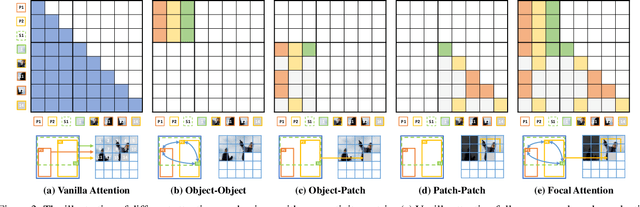
We present a method that achieves state-of-the-art results on challenging (few-shot) layout-to-image generation tasks by accurately modeling textures, structures and relationships contained in a complex scene. After compressing RGB images into patch tokens, we propose the Transformer with Focal Attention (TwFA) for exploring dependencies of object-to-object, object-to-patch and patch-to-patch. Compared to existing CNN-based and Transformer-based generation models that entangled modeling on pixel-level&patch-level and object-level&patch-level respectively, the proposed focal attention predicts the current patch token by only focusing on its highly-related tokens that specified by the spatial layout, thereby achieving disambiguation during training. Furthermore, the proposed TwFA largely increases the data efficiency during training, therefore we propose the first few-shot complex scene generation strategy based on the well-trained TwFA. Comprehensive experiments show the superiority of our method, which significantly increases both quantitative metrics and qualitative visual realism with respect to state-of-the-art CNN-based and transformer-based methods. Code is available at https://github.com/JohnDreamer/TwFA.
Compact Bidirectional Transformer for Image Captioning
Jan 06, 2022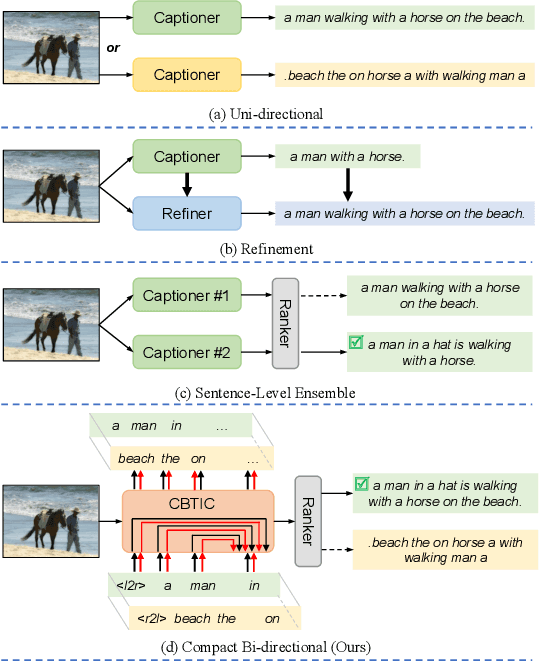
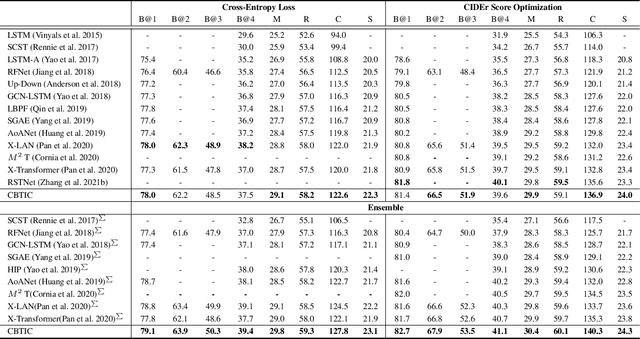

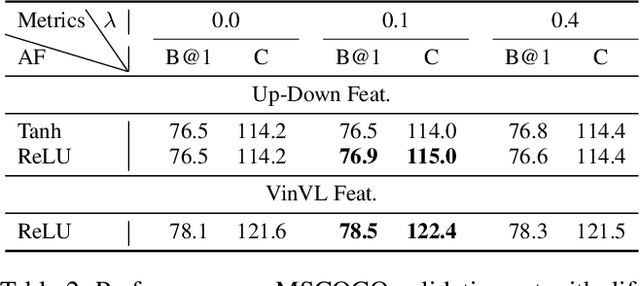
Most current image captioning models typically generate captions from left to right. This unidirectional property makes them can only leverage past context but not future context. Though recent refinement-based models can exploit both past and future context by generating a new caption in the second stage based on pre-retrieved or pre-generated captions in the first stage, the decoder of these models generally consists of two networks~(i.e. a retriever or captioner in the first stage and a refiner in the second stage), which can only be executed sequentially. In this paper, we introduce a Compact Bidirectional Transformer model for image captioning that can leverage bidirectional context implicitly and explicitly while the decoder can be executed parallelly. Specifically, it is implemented by tightly coupling left-to-right(L2R) and right-to-left(R2L) flows into a single compact model~(i.e. implicitly) and optionally allowing interaction of the two flows(i.e. explicitly), while the final caption is chosen from either L2R or R2L flow in a sentence-level ensemble manner. We conduct extensive ablation studies on the MSCOCO benchmark and find that the compact architecture, which serves as a regularization for implicitly exploiting bidirectional context, and the sentence-level ensemble play more important roles than the explicit interaction mechanism. By combining with word-level ensemble seamlessly, the effect of the sentence-level ensemble is further enlarged. We further extend the conventional one-flow self-critical training to the two-flows version under this architecture and achieve new state-of-the-art results in comparison with non-vision-language-pretraining models. Source code is available at {\color{magenta}\url{https://github.com/YuanEZhou/CBTrans}}.
Learning to Discretely Compose Reasoning Module Networks for Video Captioning
Jul 17, 2020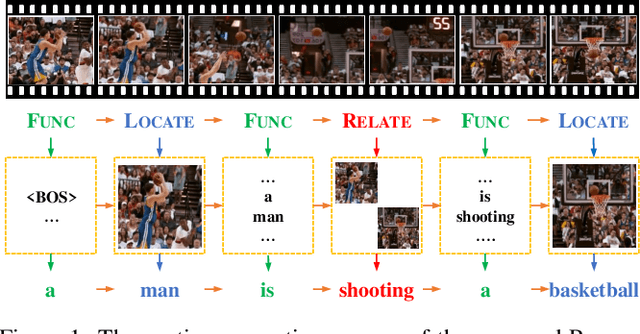

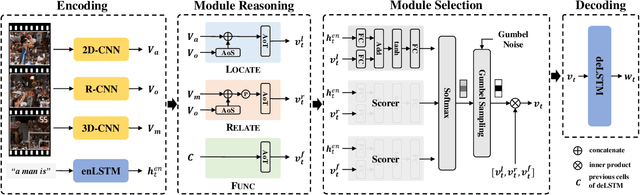
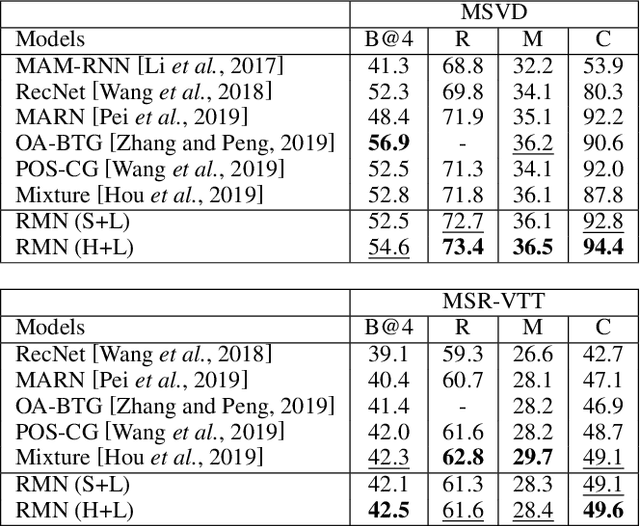
Generating natural language descriptions for videos, i.e., video captioning, essentially requires step-by-step reasoning along the generation process. For example, to generate the sentence "a man is shooting a basketball", we need to first locate and describe the subject "man", next reason out the man is "shooting", then describe the object "basketball" of shooting. However, existing visual reasoning methods designed for visual question answering are not appropriate to video captioning, for it requires more complex visual reasoning on videos over both space and time, and dynamic module composition along the generation process. In this paper, we propose a novel visual reasoning approach for video captioning, named Reasoning Module Networks (RMN), to equip the existing encoder-decoder framework with the above reasoning capacity. Specifically, our RMN employs 1) three sophisticated spatio-temporal reasoning modules, and 2) a dynamic and discrete module selector trained by a linguistic loss with a Gumbel approximation. Extensive experiments on MSVD and MSR-VTT datasets demonstrate the proposed RMN outperforms the state-of-the-art methods while providing an explicit and explainable generation process. Our code is available at https://github.com/tgc1997/RMN.
* Accepted at IJCAI 2020 Main Track. Sole copyright holder is IJCAI. Code is available at https://github.com/tgc1997/RMN
More Grounded Image Captioning by Distilling Image-Text Matching Model
Apr 01, 2020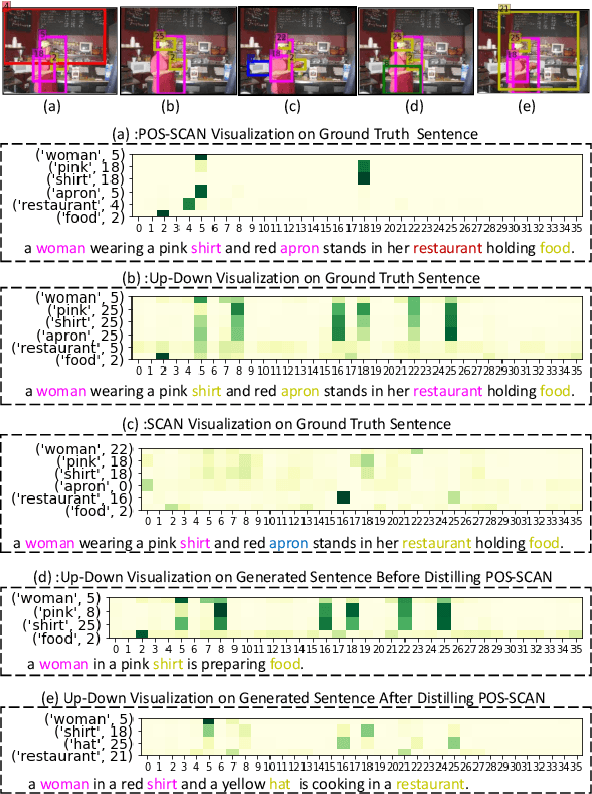

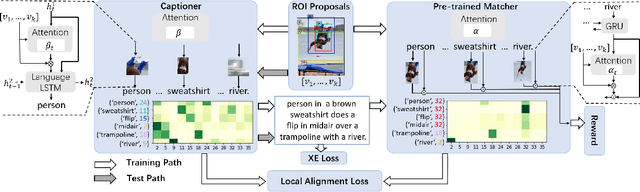
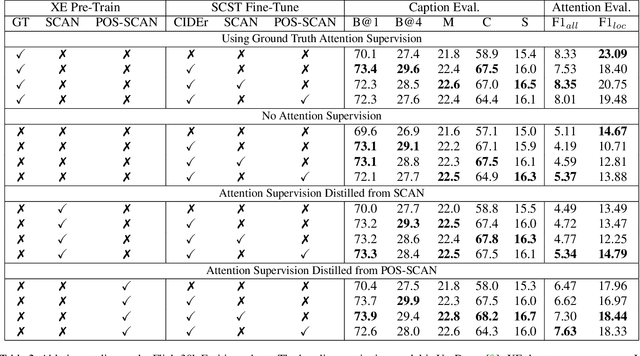
Visual attention not only improves the performance of image captioners, but also serves as a visual interpretation to qualitatively measure the caption rationality and model transparency. Specifically, we expect that a captioner can fix its attentive gaze on the correct objects while generating the corresponding words. This ability is also known as grounded image captioning. However, the grounding accuracy of existing captioners is far from satisfactory. To improve the grounding accuracy while retaining the captioning quality, it is expensive to collect the word-region alignment as strong supervision. To this end, we propose a Part-of-Speech (POS) enhanced image-text matching model (SCAN \cite{lee2018stacked}): POS-SCAN, as the effective knowledge distillation for more grounded image captioning. The benefits are two-fold: 1) given a sentence and an image, POS-SCAN can ground the objects more accurately than SCAN; 2) POS-SCAN serves as a word-region alignment regularization for the captioner's visual attention module. By showing benchmark experimental results, we demonstrate that conventional image captioners equipped with POS-SCAN can significantly improve the grounding accuracy without strong supervision. Last but not the least, we explore the indispensable Self-Critical Sequence Training (SCST) \cite{Rennie_2017_CVPR} in the context of grounded image captioning and show that the image-text matching score can serve as a reward for more grounded captioning \footnote{https://github.com/YuanEZhou/Grounded-Image-Captioning}.
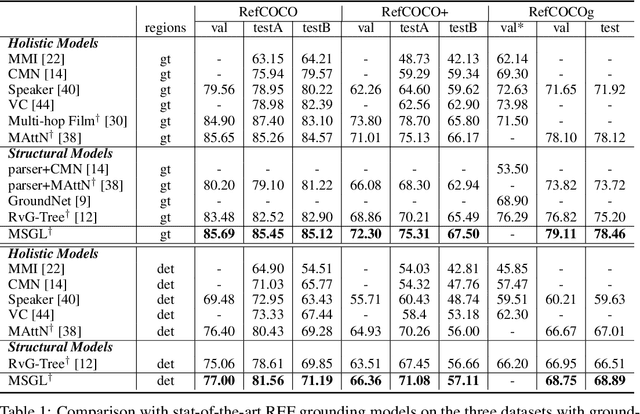
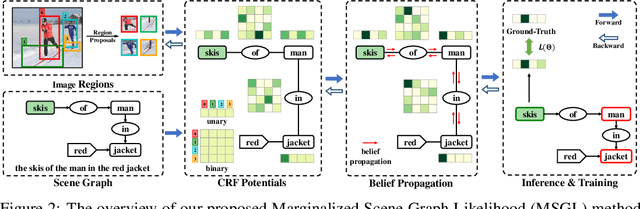
Referring Expression Grounding by Marginalizing Scene Graph Likelihood
Jun 09, 2019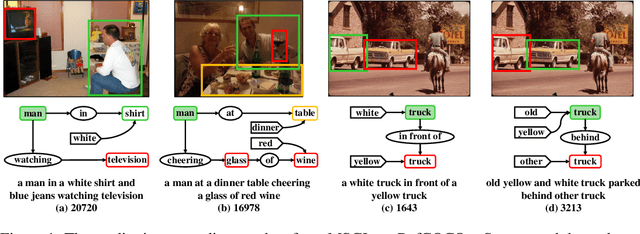
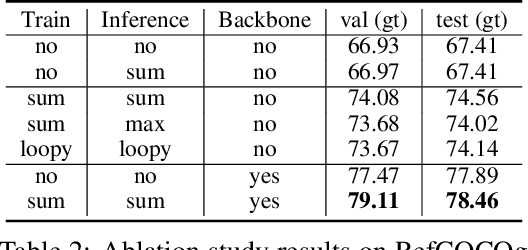
We focus on the task of grounding referring expressions in images, e.g., localizing "the white truck in front of a yellow one". To resolve this task fundamentally, one should first find out the contextual objects (e.g., the "yellow" truck) and then exploit them to disambiguate the referent from other similar objects, by using the attributes and relationships (e.g., "white", "yellow", "in front of"). However, it is extremely challenging to train such a model as the ground-truth of the contextual objects and their relationships are usually missing due to the prohibitive annotation cost. Therefore, nearly all existing methods attempt to evade the above joint grounding and reasoning process, but resort to a holistic association between the sentence and region feature. As a result, they suffer from heavy parameters of fully-connected layers, poor interpretability, and limited generalization to unseen expressions. In this paper, we tackle this challenge by training and inference with the proposed Marginalized Scene Graph Likelihood (MSGL). Specifically, we use scene graph: a graphical representation parsed from the referring expression, where the nodes are objects with attributes and the edges are relationships. Thanks to the conditional random field (CRF) built on scene graph, we can ground every object to its corresponding region, and perform reasoning with the unlabeled contexts by marginalizing out them using the sum-product belief propagation. Overall, our proposed MSGL is effective and interpretable, e.g., on three benchmarks, MSGL consistently outperforms the state-of-the-arts while offers a complete grounding of all the objects in a sentence.
Context-Aware Visual Policy Network for Fine-Grained Image Captioning
Jun 06, 2019
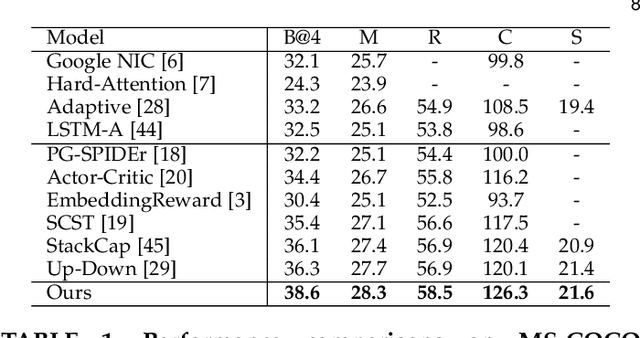

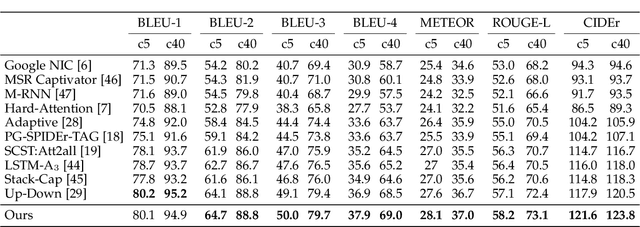
With the maturity of visual detection techniques, we are more ambitious in describing visual content with open-vocabulary, fine-grained and free-form language, i.e., the task of image captioning. In particular, we are interested in generating longer, richer and more fine-grained sentences and paragraphs as image descriptions. Image captioning can be translated to the task of sequential language prediction given visual content, where the output sequence forms natural language description with plausible grammar. However, existing image captioning methods focus only on language policy while not visual policy, and thus fail to capture visual context that are crucial for compositional reasoning such as object relationships (e.g., "man riding horse") and visual comparisons (e.g., "small(er) cat"). This issue is especially severe when generating longer sequences such as a paragraph. To fill the gap, we propose a Context-Aware Visual Policy network (CAVP) for fine-grained image-to-language generation: image sentence captioning and image paragraph captioning. During captioning, CAVP explicitly considers the previous visual attentions as context, and decides whether the context is used for the current word/sentence generation given the current visual attention. Compared against traditional visual attention mechanism that only fixes a single visual region at each step, CAVP can attend to complex visual compositions over time. The whole image captioning model -- CAVP and its subsequent language policy network -- can be efficiently optimized end-to-end by using an actor-critic policy gradient method. We have demonstrated the effectiveness of CAVP by state-of-the-art performances on MS-COCO and Stanford captioning datasets, using various metrics and sensible visualizations of qualitative visual context.
Learning to Compose and Reason with Language Tree Structures for Visual Grounding
Jun 05, 2019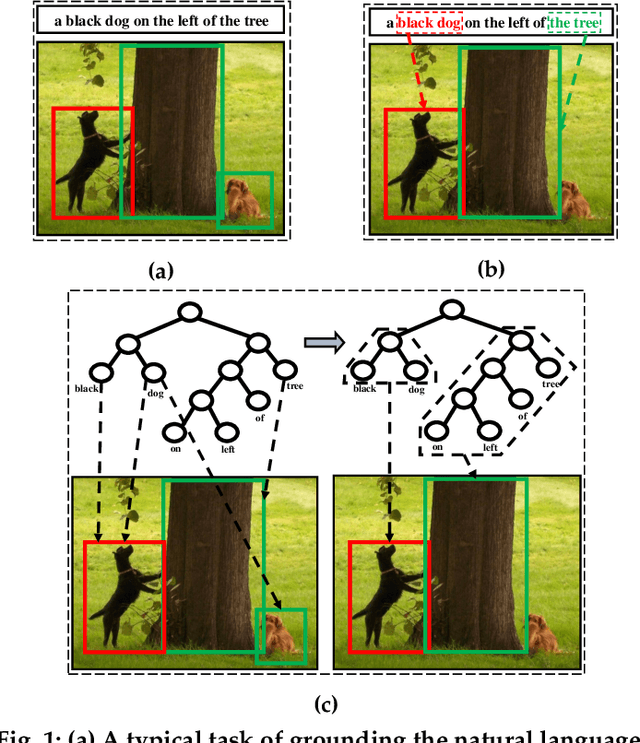
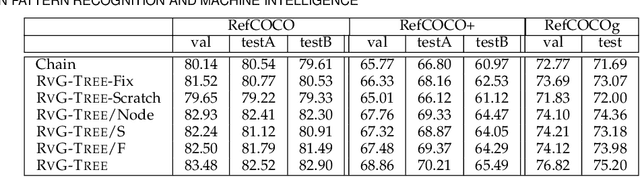
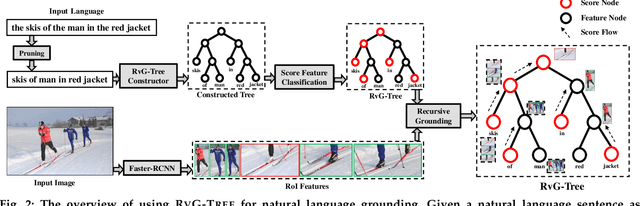
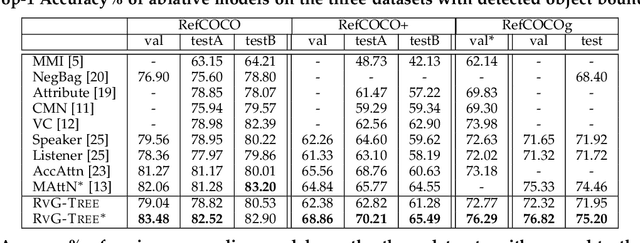
Grounding natural language in images, such as localizing "the black dog on the left of the tree", is one of the core problems in artificial intelligence, as it needs to comprehend the fine-grained and compositional language space. However, existing solutions rely on the association between the holistic language features and visual features, while neglect the nature of compositional reasoning implied in the language. In this paper, we propose a natural language grounding model that can automatically compose a binary tree structure for parsing the language and then perform visual reasoning along the tree in a bottom-up fashion. We call our model RVG-TREE: Recursive Grounding Tree, which is inspired by the intuition that any language expression can be recursively decomposed into two constituent parts, and the grounding confidence score can be recursively accumulated by calculating their grounding scores returned by sub-trees. RVG-TREE can be trained end-to-end by using the Straight-Through Gumbel-Softmax estimator that allows the gradients from the continuous score functions passing through the discrete tree construction. Experiments on several benchmarks show that our model achieves the state-of-the-art performance with more explainable reasoning.
Explainability by Parsing: Neural Module Tree Networks for Natural Language Visual Grounding
Dec 08, 2018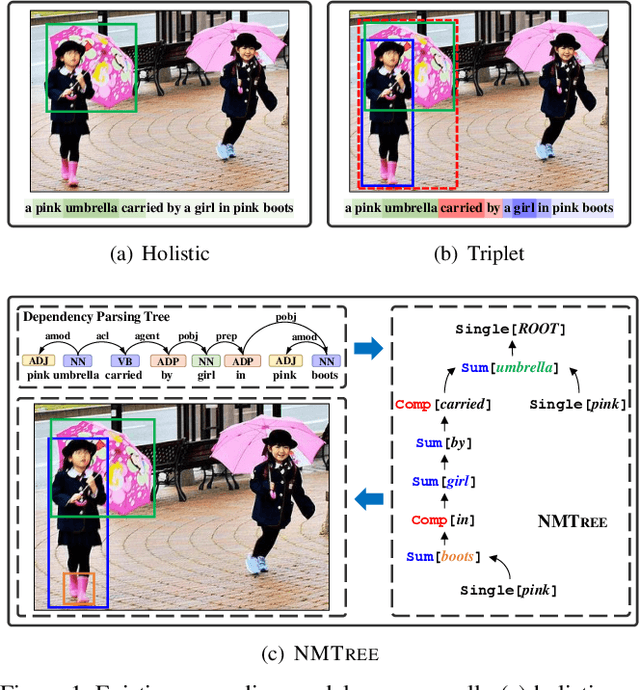
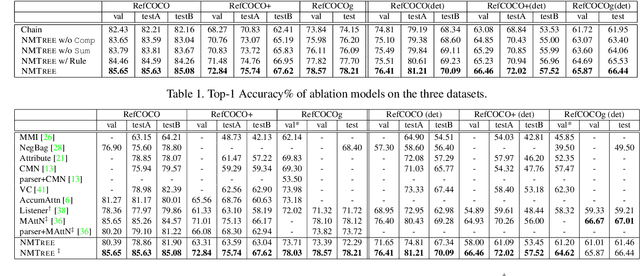
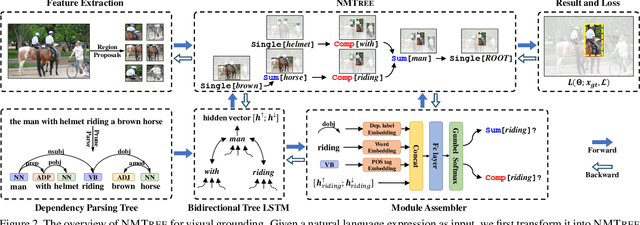

Grounding natural language in images essentially requires composite visual reasoning. However, existing methods over-simplify the composite nature of language into a monolithic sentence embedding or a coarse composition of subject-predicate-object triplet. They might perform well on short phrases, but generally fail in longer sentences, mainly due to the over-fitting to certain vision-language bias. In this paper, we propose to ground natural language in an intuitive, explainable, and composite fashion as it should be. In particular, we develop a novel modular network called Neural Module Tree network (NMTree) that regularizes the visual grounding along the dependency parsing tree of the sentence, where each node is a module network that calculates or accumulates the grounding score in a bottom-up direction where as needed. NMTree disentangles the visual grounding from the composite reasoning, allowing the former to only focus on primitive and easy-to-generalize patterns. To reduce the impact of parsing errors, we train the modules and their assembly end-to-end by using the Gumbel-Softmax approximation and its straight-through gradient estimator, accounting for the discrete process of module selection. Overall, the proposed NMTree not only consistently outperforms the state-of-the-arts on several benchmarks and tasks, but also shows explainable reasoning in grounding score calculation. Therefore, NMTree shows a good direction in closing the gap between explainability and performance.
Context-Aware Visual Policy Network for Sequence-Level Image Captioning
Aug 22, 2018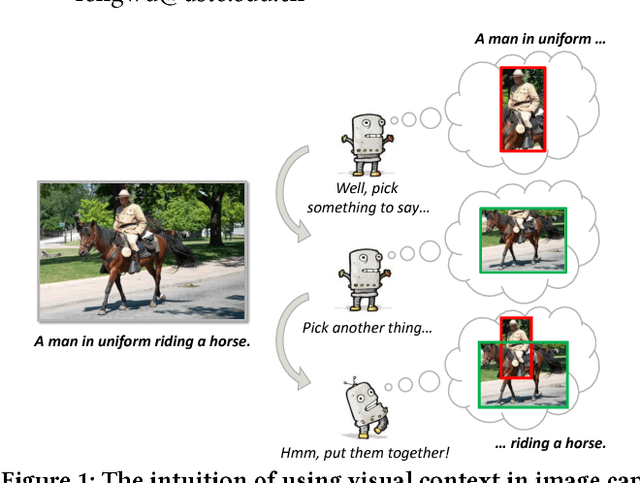
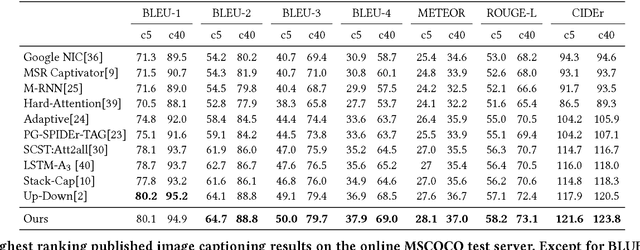
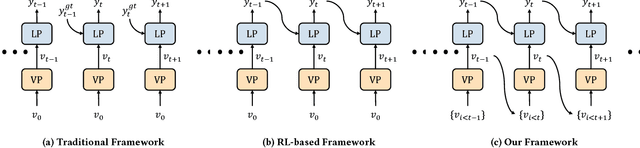
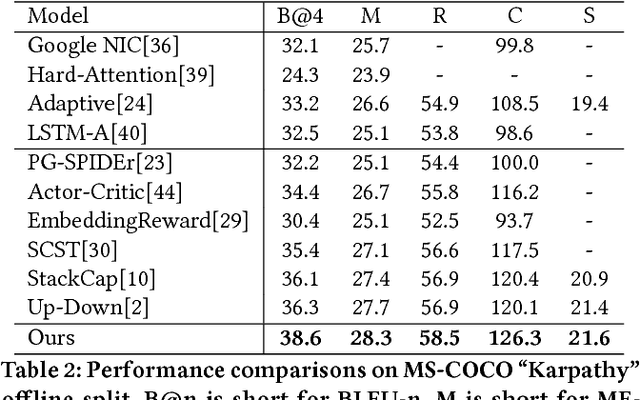
Many vision-language tasks can be reduced to the problem of sequence prediction for natural language output. In particular, recent advances in image captioning use deep reinforcement learning (RL) to alleviate the "exposure bias" during training: ground-truth subsequence is exposed in every step prediction, which introduces bias in test when only predicted subsequence is seen. However, existing RL-based image captioning methods only focus on the language policy while not the visual policy (e.g., visual attention), and thus fail to capture the visual context that are crucial for compositional reasoning such as visual relationships (e.g., "man riding horse") and comparisons (e.g., "smaller cat"). To fill the gap, we propose a Context-Aware Visual Policy network (CAVP) for sequence-level image captioning. At every time step, CAVP explicitly accounts for the previous visual attentions as the context, and then decides whether the context is helpful for the current word generation given the current visual attention. Compared against traditional visual attention that only fixes a single image region at every step, CAVP can attend to complex visual compositions over time. The whole image captioning model --- CAVP and its subsequent language policy network --- can be efficiently optimized end-to-end by using an actor-critic policy gradient method with respect to any caption evaluation metric. We demonstrate the effectiveness of CAVP by state-of-the-art performances on MS-COCO offline split and online server, using various metrics and sensible visualizations of qualitative visual context. The code is available at https://github.com/daqingliu/CAVP