 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Object Detectors with Conditional Domain Normalization
Mar 16, 2020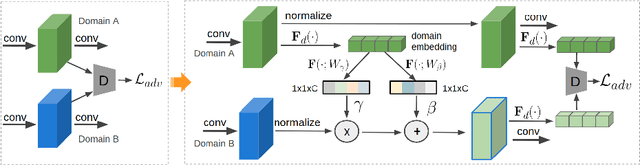
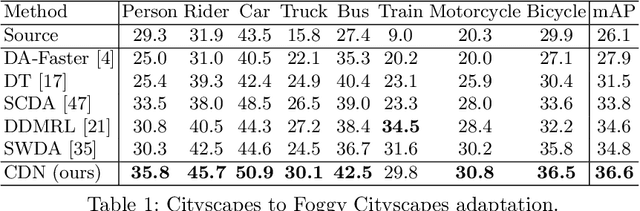
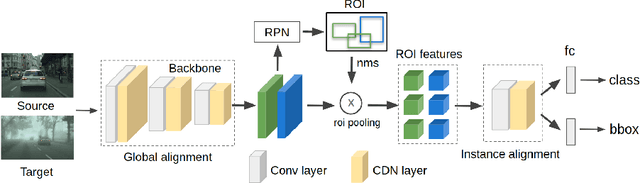
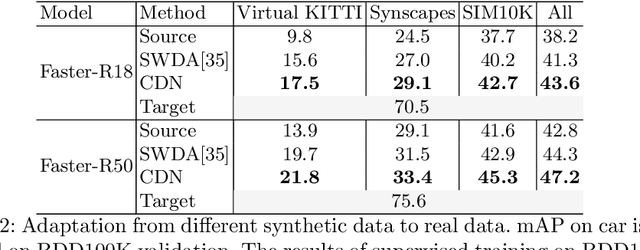
Real-world object detectors are often challenged by the domain gaps between different datasets. In this work, we present the Conditional Domain Normalization (CDN) to bridge the domain gap. CDN is designed to encode different domain inputs into a shared latent space, where the features from different domains carry the same domain attribute. To achieve this, we first disentangle the domain-specific attribute out of the semantic features from one domain via a domain embedding module, which learns a domain-vector to characterize the corresponding domain attribute information. Then this domain-vector is used to encode the features from another domain through a conditional normalization, resulting in different domains' features carrying the same domain attribute. We incorporate CDN into various convolution stages of an object detector to adaptively address the domain shifts of different level's representation. In contrast to existing adaptation works that conduct domain confusion learning on semantic features to remove domain-specific factors, CDN aligns different domain distributions by modulating the semantic features of one domain conditioned on the learned domain-vector of another domain. Extensive experiments show that CDN outperforms existing methods remarkably on both real-to-real and synthetic-to-real adaptation benchmarks, including 2D image detection and 3D point cloud detection.
Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification
Jan 30, 2020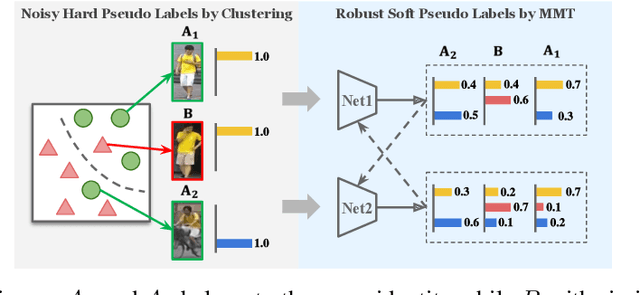
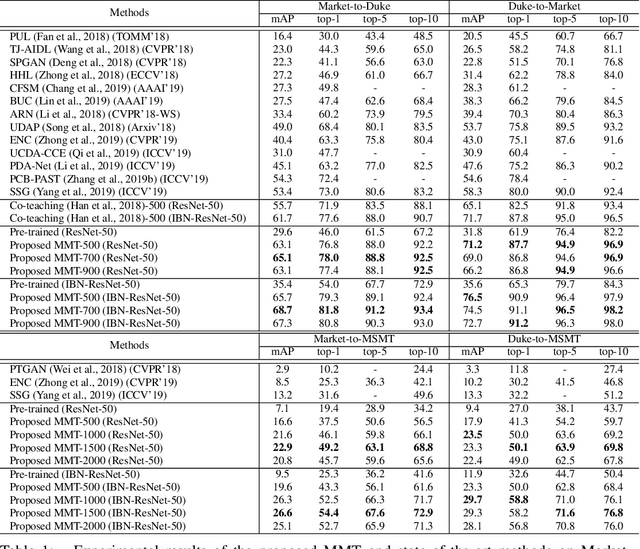
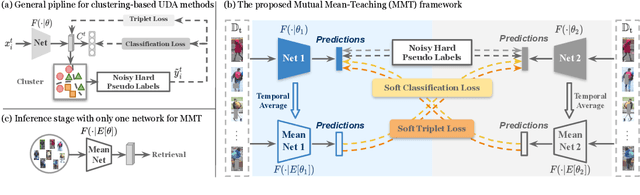
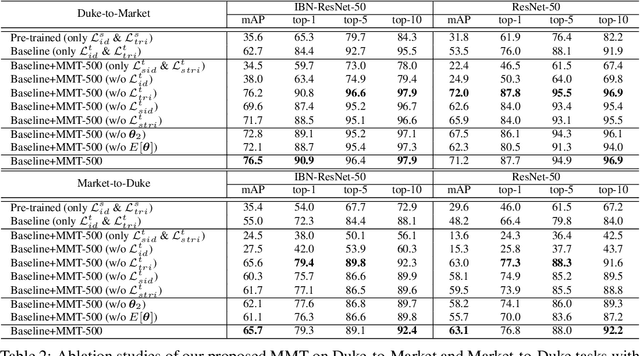
Person re-identification (re-ID) aims at identifying the same persons' images across different cameras. However, domain diversities between different datasets pose an evident challenge for adapting the re-ID model trained on one dataset to another one. State-of-the-art unsupervised domain adaptation methods for person re-ID transferred the learned knowledge from the source domain by optimizing with pseudo labels created by clustering algorithms on the target domain. Although they achieved state-of-the-art performances, the inevitable label noise caused by the clustering procedure was ignored. Such noisy pseudo labels substantially hinders the model's capability on further improving feature representations on the target domain. In order to mitigate the effects of noisy pseudo labels, we propose to softly refine the pseudo labels in the target domain by proposing an unsupervised framework, Mutual Mean-Teaching (MMT), to learn better features from the target domain via off-line refined hard pseudo labels and on-line refined soft pseudo labels in an alternative training manner. In addition, the common practice is to adopt both the classification loss and the triplet loss jointly for achieving optimal performances in person re-ID models. However, conventional triplet loss cannot work with softly refined labels. To solve this problem, a novel soft softmax-triplet loss is proposed to support learning with soft pseudo triplet labels for achieving the optimal domain adaptation performance. The proposed MMT framework achieves considerable improvements of 14.4%, 18.2%, 13.1% and 16.4% mAP on Market-to-Duke, Duke-to-Market, Market-to-MSMT and Duke-to-MSMT unsupervised domain adaptation tasks. Code is available at https://github.com/yxgeee/MMT.
Memory-Based Neighbourhood Embedding for Visual Recognition
Aug 14, 2019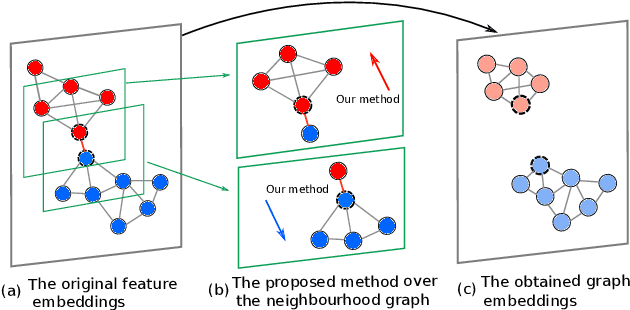
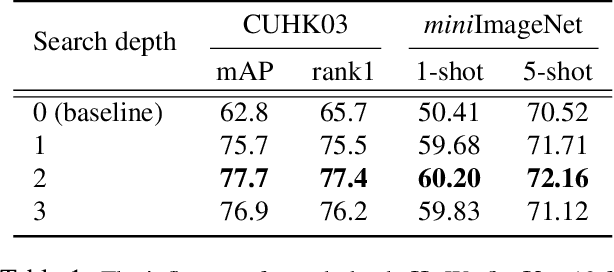
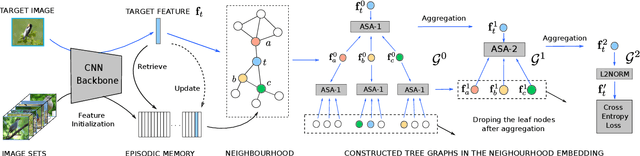
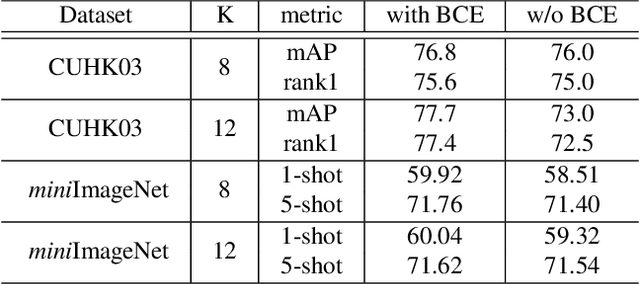
Learning discriminative image feature embeddings is of great importance to visual recognition. To achieve better feature embeddings, most current methods focus on designing different network structures or loss functions, and the estimated feature embeddings are usually only related to the input images. In this paper, we propose Memory-based Neighbourhood Embedding (MNE) to enhance a general CNN feature by considering its neighbourhood. The method aims to solve two critical problems, i.e., how to acquire more relevant neighbours in the network training and how to aggregate the neighbourhood information for a more discriminative embedding. We first augment an episodic memory module into the network, which can provide more relevant neighbours for both training and testing. Then the neighbours are organized in a tree graph with the target instance as the root node. The neighbourhood information is gradually aggregated to the root node in a bottom-up manner, and aggregation weights are supervised by the class relationships between the nodes. We apply MNE on image search and few shot learning tasks. Extensive ablation studies demonstrate the effectiveness of each component, and our method significantly outperforms the state-of-the-art approaches.
Learning to Cluster Faces on an Affinity Graph
May 05, 2019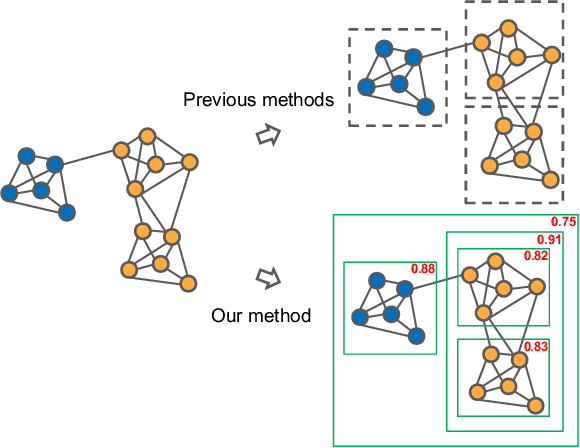
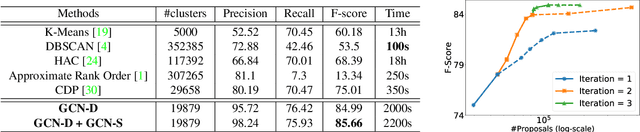
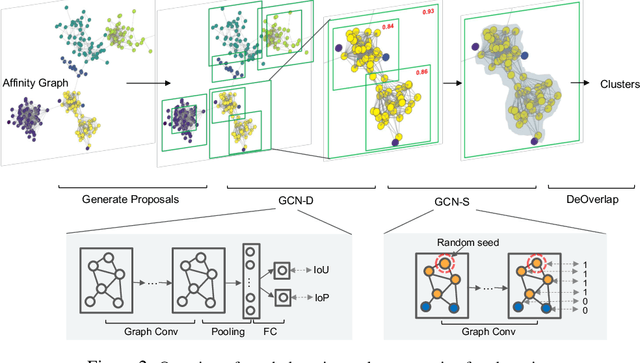
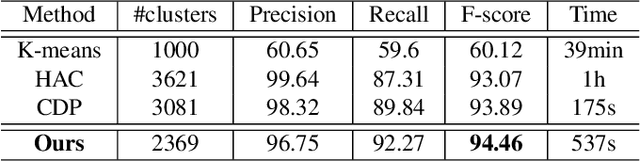
Face recognition sees remarkable progress in recent years, and its performance has reached a very high level. Taking it to a next level requires substantially larger data, which would involve prohibitive annotation cost. Hence, exploiting unlabeled data becomes an appealing alternative. Recent works have shown that clustering unlabeled faces is a promising approach, often leading to notable performance gains. Yet, how to effectively cluster, especially on a large-scale (i.e. million-level or above) dataset, remains an open question. A key challenge lies in the complex variations of cluster patterns, which make it difficult for conventional clustering methods to meet the needed accuracy. This work explores a novel approach, namely, learning to cluster instead of relying on hand-crafted criteria. Specifically, we propose a framework based on graph convolutional network, which combines a detection and a segmentation module to pinpoint face clusters. Experiments show that our method yields significantly more accurate face clusters, which, as a result, also lead to further performance gain in face recognition.
Improving Deep Visual Representation for Person Re-identification by Global and Local Image-language Association
Aug 05, 2018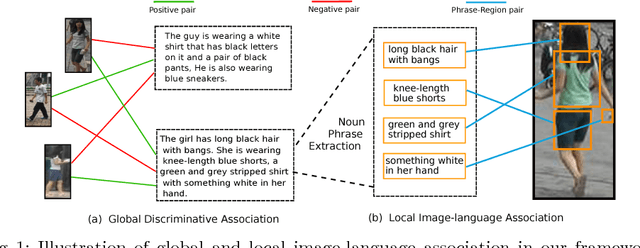
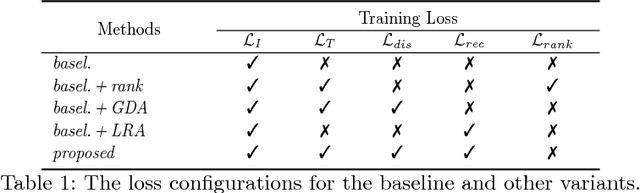
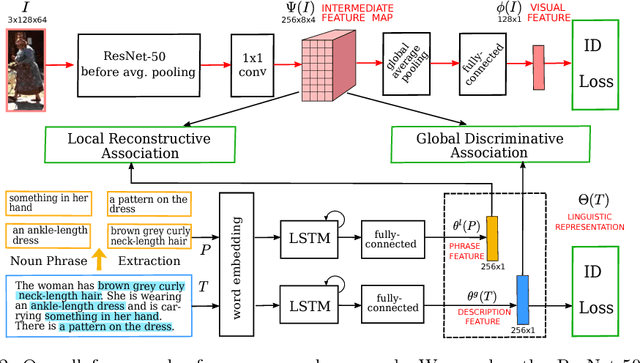
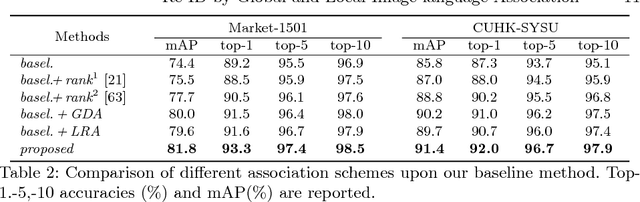
Person re-identification is an important task that requires learning discriminative visual features for distinguishing different person identities. Diverse auxiliary information has been utilized to improve the visual feature learning. In this paper, we propose to exploit natural language description as additional training supervisions for effective visual features. Compared with other auxiliary information, language can describe a specific person from more compact and semantic visual aspects, thus is complementary to the pixel-level image data. Our method not only learns better global visual feature with the supervision of the overall description but also enforces semantic consistencies between local visual and linguistic features, which is achieved by building global and local image-language associations. The global image-language association is established according to the identity labels, while the local association is based upon the implicit correspondences between image regions and noun phrases. Extensive experiments demonstrate the effectiveness of employing language as training supervisions with the two association schemes. Our method achieves state-of-the-art performance without utilizing any auxiliary information during testing and shows better performance than other joint embedding methods for the image-language association.
Deep Group-shuffling Random Walk for Person Re-identification
Jul 30, 2018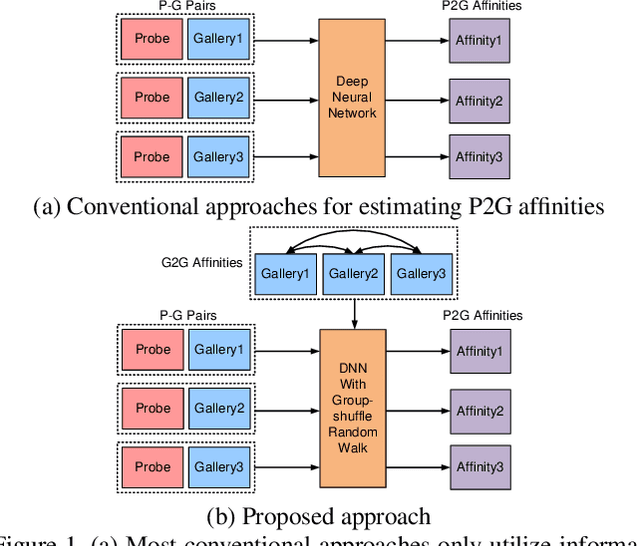
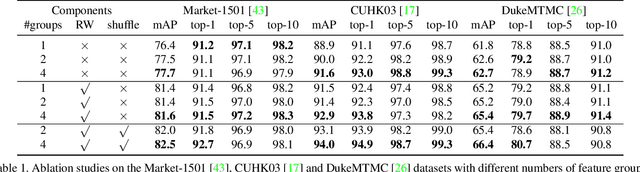
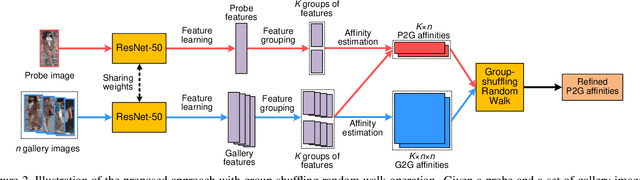
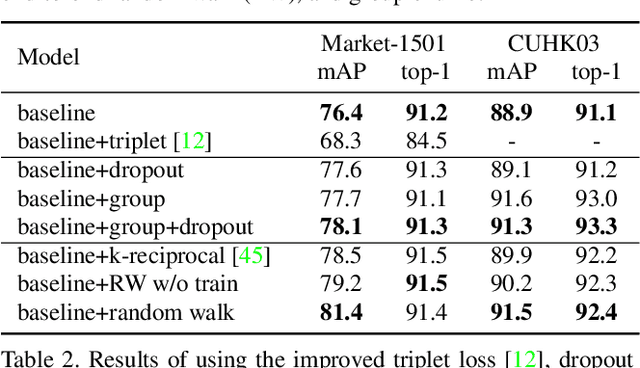
Person re-identification aims at finding a person of interest in an image gallery by comparing the probe image of this person with all the gallery images. It is generally treated as a retrieval problem, where the affinities between the probe image and gallery images (P2G affinities) are used to rank the retrieved gallery images. However, most existing methods only consider P2G affinities but ignore the affinities between all the gallery images (G2G affinity). Some frameworks incorporated G2G affinities into the testing process, which is not end-to-end trainable for deep neural networks. In this paper, we propose a novel group-shuffling random walk network for fully utilizing the affinity information between gallery images in both the training and testing processes. The proposed approach aims at end-to-end refining the P2G affinities based on G2G affinity information with a simple yet effective matrix operation, which can be integrated into deep neural networks. Feature grouping and group shuffle are also proposed to apply rich supervisions for learning better person features. The proposed approach outperforms state-of-the-art methods on the Market-1501, CUHK03, and DukeMTMC datasets by large margins, which demonstrate the effectiveness of our approach.
Person Re-identification with Deep Similarity-Guided Graph Neural Network
Jul 26, 2018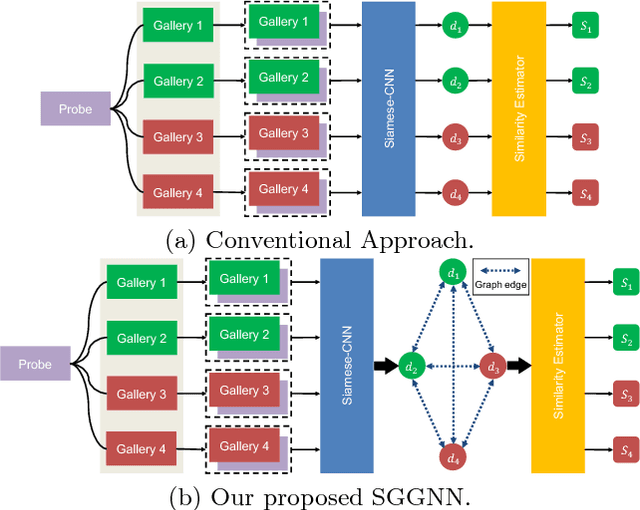
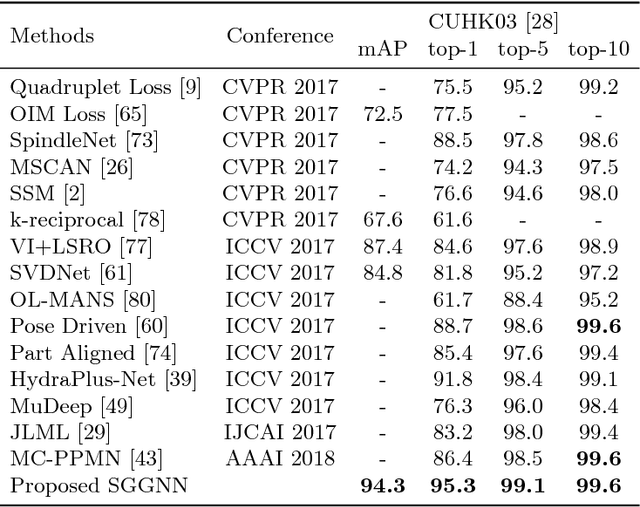
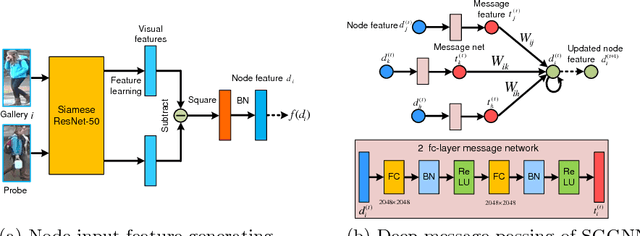
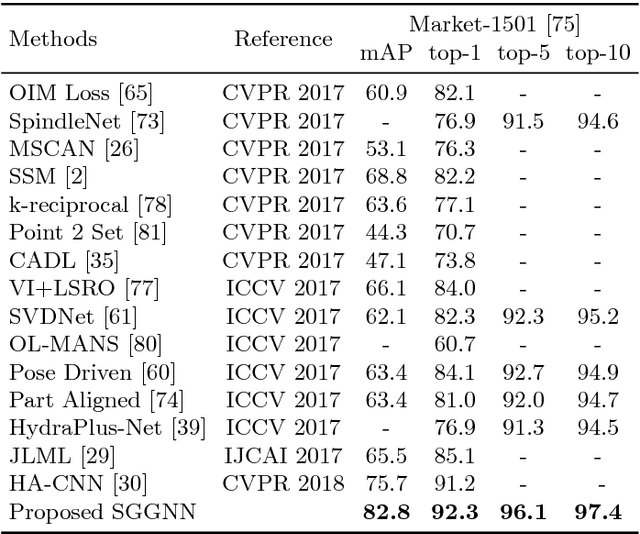
The person re-identification task requires to robustly estimate visual similarities between person images. However, existing person re-identification models mostly estimate the similarities of different image pairs of probe and gallery images independently while ignores the relationship information between different probe-gallery pairs. As a result, the similarity estimation of some hard samples might not be accurate. In this paper, we propose a novel deep learning framework, named Similarity-Guided Graph Neural Network (SGGNN) to overcome such limitations. Given a probe image and several gallery images, SGGNN creates a graph to represent the pairwise relationships between probe-gallery pairs (nodes) and utilizes such relationships to update the probe-gallery relation features in an end-to-end manner. Accurate similarity estimation can be achieved by using such updated probe-gallery relation features for prediction. The input features for nodes on the graph are the relation features of different probe-gallery image pairs. The probe-gallery relation feature updating is then performed by the messages passing in SGGNN, which takes other nodes' information into account for similarity estimation. Different from conventional GNN approaches, SGGNN learns the edge weights with rich labels of gallery instance pairs directly, which provides relation fusion more precise information. The effectiveness of our proposed method is validated on three public person re-identification datasets.
Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data
Jul 23, 2018
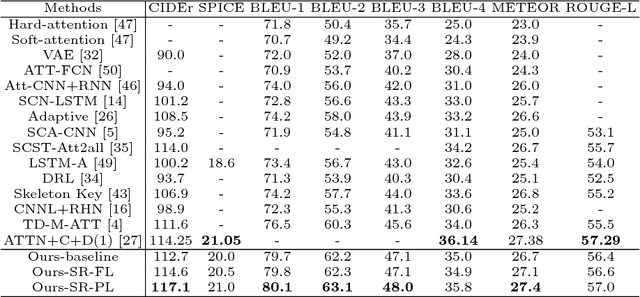
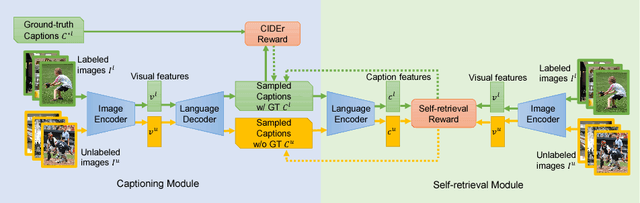
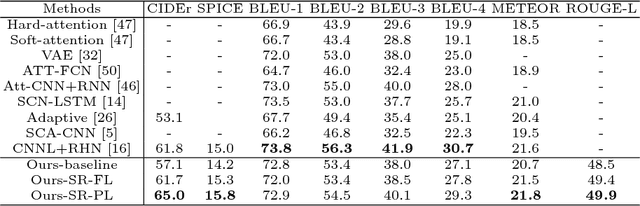
The aim of image captioning is to generate captions by machine to describe image contents. Despite many efforts, generating discriminative captions for images remains non-trivial. Most traditional approaches imitate the language structure patterns, thus tend to fall into a stereotype of replicating frequent phrases or sentences and neglect unique aspects of each image. In this work, we propose an image captioning framework with a self-retrieval module as training guidance, which encourages generating discriminative captions. It brings unique advantages: (1) the self-retrieval guidance can act as a metric and an evaluator of caption discriminativeness to assure the quality of generated captions. (2) The correspondence between generated captions and images are naturally incorporated in the generation process without human annotations, and hence our approach could utilize a large amount of unlabeled images to boost captioning performance with no additional laborious annotations. We demonstrate the effectiveness of the proposed retrieval-guided method on COCO and Flickr30k captioning datasets, and show its superior captioning performance with more discriminative captions.
Long-term Multi-granularity Deep Framework for Driver Drowsiness Detection
Jan 08, 2018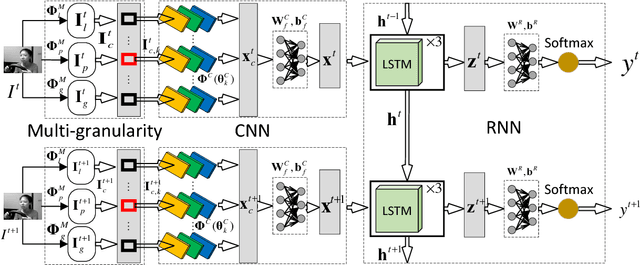
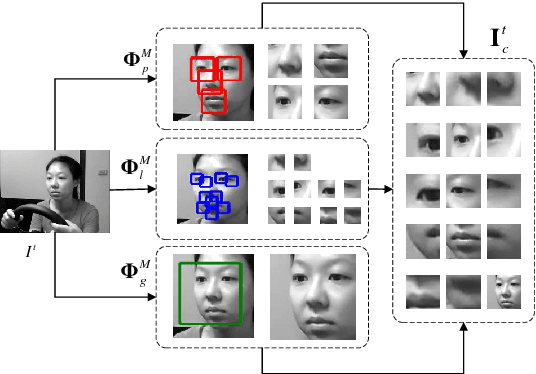
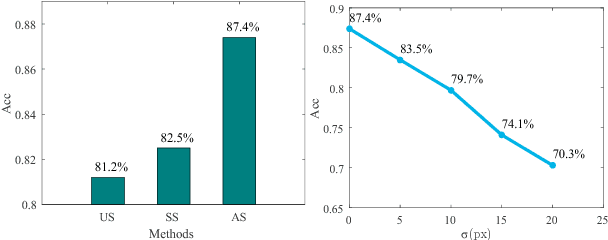
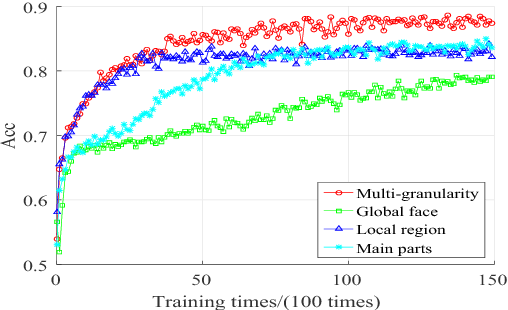
For real-world driver drowsiness detection from videos, the variation of head pose is so large that the existing methods on global face is not capable of extracting effective features, such as looking aside and lowering head. Temporal dependencies with variable length are also rarely considered by the previous approaches, e.g., yawning and speaking. In this paper, we propose a Long-term Multi-granularity Deep Framework to detect driver drowsiness in driving videos containing the frontal faces. The framework includes two key components: (1) Multi-granularity Convolutional Neural Network (MCNN), a novel network utilizes a group of parallel CNN extractors on well-aligned facial patches of different granularities, and extracts facial representations effectively for large variation of head pose, furthermore, it can flexibly fuse both detailed appearance clues of the main parts and local to global spatial constraints; (2) a deep Long Short Term Memory network is applied on facial representations to explore long-term relationships with variable length over sequential frames, which is capable to distinguish the states with temporal dependencies, such as blinking and closing eyes. Our approach achieves 90.05% accuracy and about 37 fps speed on the evaluation set of the public NTHU-DDD dataset, which is the state-of-the-art method on driver drowsiness detection. Moreover, we build a new dataset named FI-DDD, which is of higher precision of drowsy locations in temporal dimension.
Learning Fixation Point Strategy for Object Detection and Classification
Dec 19, 2017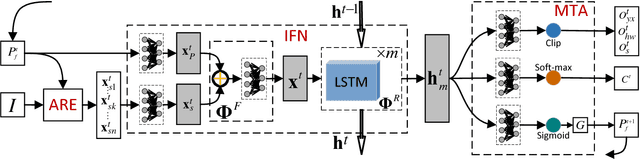
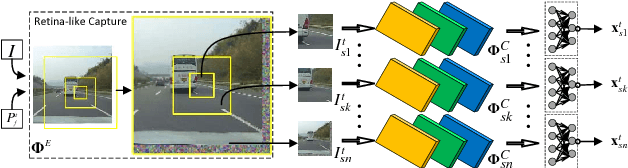
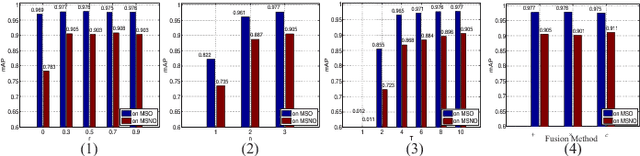
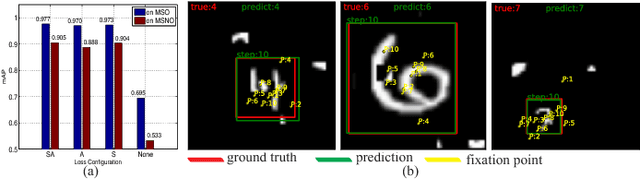
We propose a novel recurrent attentional structure to localize and recognize objects jointly. The network can learn to extract a sequence of local observations with detailed appearance and rough context, instead of sliding windows or convolutions on the entire image. Meanwhile, those observations are fused to complete detection and classification tasks. On training, we present a hybrid loss function to learn the parameters of the multi-task network end-to-end. Particularly, the combination of stochastic and object-awareness strategy, named SA, can select more abundant context and ensure the last fixation close to the object. In addition, we build a real-world dataset to verify the capacity of our method in detecting the object of interest including those small ones. Our method can predict a precise bounding box on an image, and achieve high speed on large images without pooling operations. Experimental results indicate that the proposed method can mine effective context by several local observations. Moreover, the precision and speed are easily improved by changing the number of recurrent steps. Finally, we will open the source code of our proposed approach.