 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftZoo: A Soft Robot Co-design Benchmark For Locomotion In Diverse Environments
Mar 16, 2023



While significant research progress has been made in robot learning for control, unique challenges arise when simultaneously co-optimizing morphology. Existing work has typically been tailored for particular environments or representations. In order to more fully understand inherent design and performance tradeoffs and accelerate the development of new breeds of soft robots, a comprehensive virtual platform with well-established tasks, environments, and evaluation metrics is needed. In this work, we introduce SoftZoo, a soft robot co-design platform for locomotion in diverse environments. SoftZoo supports an extensive, naturally-inspired material set, including the ability to simulate environments such as flat ground, desert, wetland, clay, ice, snow, shallow water, and ocean. Further, it provides a variety of tasks relevant for soft robotics, including fast locomotion, agile turning, and path following, as well as differentiable design representations for morphology and control. Combined, these elements form a feature-rich platform for analysis and development of soft robot co-design algorithms. We benchmark prevalent representations and co-design algorithms, and shed light on 1) the interplay between environment, morphology, and behavior; 2) the importance of design space representations; 3) the ambiguity in muscle formation and controller synthesis; and 4) the value of differentiable physics. We envision that SoftZoo will serve as a standard platform and template an approach toward the development of novel representations and algorithms for co-designing soft robots' behavioral and morphological intelligence.
Provable Data Subset Selection For Efficient Neural Network Training
Mar 09, 2023



Radial basis function neural networks (\emph{RBFNN}) are {well-known} for their capability to approximate any continuous function on a closed bounded set with arbitrary precision given enough hidden neurons. In this paper, we introduce the first algorithm to construct coresets for \emph{RBFNNs}, i.e., small weighted subsets that approximate the loss of the input data on any radial basis function network and thus approximate any function defined by an \emph{RBFNN} on the larger input data. In particular, we construct coresets for radial basis and Laplacian loss functions. We then use our coresets to obtain a provable data subset selection algorithm for training deep neural networks. Since our coresets approximate every function, they also approximate the gradient of each weight in a neural network, which is a particular function on the input. We then perform empirical evaluations on function approximation and dataset subset selection on popular network architectures and data sets, demonstrating the efficacy and accuracy of our coreset construction.
Learned Risk Metric Maps for Kinodynamic Systems
Feb 28, 2023



We present Learned Risk Metric Maps (LRMM) for real-time estimation of coherent risk metrics of high dimensional dynamical systems operating in unstructured, partially observed environments. LRMM models are simple to design and train -- requiring only procedural generation of obstacle sets, state and control sampling, and supervised training of a function approximator -- which makes them broadly applicable to arbitrary system dynamics and obstacle sets. In a parallel autonomy setting, we demonstrate the model's ability to rapidly infer collision probabilities of a fast-moving car-like robot driving recklessly in an obstructed environment; allowing the LRMM agent to intervene, take control of the vehicle, and avoid collisions. In this time-critical scenario, we show that LRMMs can evaluate risk metrics 20-100x times faster than alternative safety algorithms based on control barrier functions (CBFs) and Hamilton-Jacobi reachability (HJ-reach), leading to 5-15\% fewer obstacle collisions by the LRMM agent than CBFs and HJ-reach. This performance improvement comes in spite of the fact that the LRMM model only has access to local/partial observation of obstacles, whereas the CBF and HJ-reach agents are granted privileged/global information. We also show that our model can be equally well trained on a 12-dimensional quadrotor system operating in an obstructed indoor environment. The LRMM codebase is provided at https://github.com/mit-drl/pyrmm.
Deep Reinforcement Learning Based Tracking Control of an Autonomous Surface Vessel in Natural Waters
Feb 20, 2023Accurate control of autonomous marine robots still poses challenges due to the complex dynamics of the environment. In this paper, we propose a Deep Reinforcement Learning (DRL) approach to train a controller for autonomous surface vessel (ASV) trajectory tracking and compare its performance with an advanced nonlinear model predictive controller (NMPC) in real environments. Taking into account environmental disturbances (e.g., wind, waves, and currents), noisy measurements, and non-ideal actuators presented in the physical ASV, several effective reward functions for DRL tracking control policies are carefully designed. The control policies were trained in a simulation environment with diverse tracking trajectories and disturbances. The performance of the DRL controller has been verified and compared with the NMPC in both simulations with model-based environmental disturbances and in natural waters. Simulations show that the DRL controller has 53.33% lower tracking error than that of NMPC. Experimental results further show that, compared to NMPC, the DRL controller has 35.51% lower tracking error, indicating that DRL controllers offer better disturbance rejection in river environments than NMPC.
Dataset Distillation with Convexified Implicit Gradients
Feb 13, 2023We propose a new dataset distillation algorithm using reparameterization and convexification of implicit gradients (RCIG), that substantially improves the state-of-the-art. To this end, we first formulate dataset distillation as a bi-level optimization problem. Then, we show how implicit gradients can be effectively used to compute meta-gradient updates. We further equip the algorithm with a convexified approximation that corresponds to learning on top of a frozen finite-width neural tangent kernel. Finally, we improve bias in implicit gradients by parameterizing the neural network to enable analytical computation of final-layer parameters given the body parameters. RCIG establishes the new state-of-the-art on a diverse series of dataset distillation tasks. Notably, with one image per class, on resized ImageNet, RCIG sees on average a 108% improvement over the previous state-of-the-art distillation algorithm. Similarly, we observed a 66% gain over SOTA on Tiny-ImageNet and 37% on CIFAR-100.
Dataset Distillation Fixes Dataset Reconstruction Attacks
Feb 02, 2023

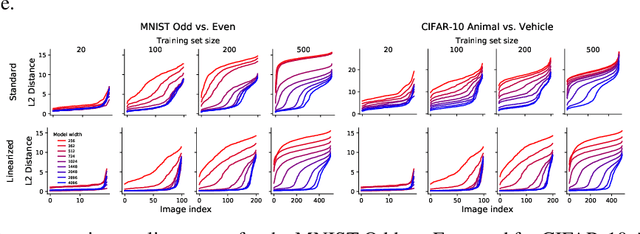
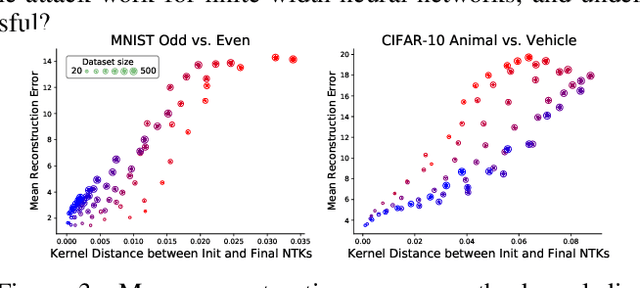
Modern deep learning requires large volumes of data, which could contain sensitive or private information which cannot be leaked. Recent work has shown for homogeneous neural networks a large portion of this training data could be reconstructed with only access to the trained network parameters. While the attack was shown to work empirically, there exists little formal understanding of its effectiveness regime, and ways to defend against it. In this work, we first build a stronger version of the dataset reconstruction attack and show how it can provably recover its entire training set in the infinite width regime. We then empirically study the characteristics of this attack on two-layer networks and reveal that its success heavily depends on deviations from the frozen infinite-width Neural Tangent Kernel limit. More importantly, we formally show for the first time that dataset reconstruction attacks are a variation of dataset distillation. This key theoretical result on the unification of dataset reconstruction and distillation not only sheds more light on the characteristics of the attack but enables us to design defense mechanisms against them via distillation algorithms.
Cooperative Flight Control Using Visual-Attention -- Air-Guardian
Dec 21, 2022



The cooperation of a human pilot with an autonomous agent during flight control realizes parallel autonomy. A parallel-autonomous system acts as a guardian that significantly enhances the robustness and safety of flight operations in challenging circumstances. Here, we propose an air-guardian concept that facilitates cooperation between an artificial pilot agent and a parallel end-to-end neural control system. Our vision-based air-guardian system combines a causal continuous-depth neural network model with a cooperation layer to enable parallel autonomy between a pilot agent and a control system based on perceived differences in their attention profile. The attention profiles are obtained by computing the networks' saliency maps (feature importance) through the VisualBackProp algorithm. The guardian agent is trained via reinforcement learning in a fixed-wing aircraft simulated environment. When the attention profile of the pilot and guardian agents align, the pilot makes control decisions. If the attention map of the pilot and the guardian do not align, the air-guardian makes interventions and takes over the control of the aircraft. We show that our attention-based air-guardian system can balance the trade-off between its level of involvement in the flight and the pilot's expertise and attention. We demonstrate the effectivness of our methods in simulated flight scenarios with a fixed-wing aircraft and on a real drone platform.
Quantization-aware Interval Bound Propagation for Training Certifiably Robust Quantized Neural Networks
Nov 29, 2022



We study the problem of training and certifying adversarially robust quantized neural networks (QNNs). Quantization is a technique for making neural networks more efficient by running them using low-bit integer arithmetic and is therefore commonly adopted in industry. Recent work has shown that floating-point neural networks that have been verified to be robust can become vulnerable to adversarial attacks after quantization, and certification of the quantized representation is necessary to guarantee robustness. In this work, we present quantization-aware interval bound propagation (QA-IBP), a novel method for training robust QNNs. Inspired by advances in robust learning of non-quantized networks, our training algorithm computes the gradient of an abstract representation of the actual network. Unlike existing approaches, our method can handle the discrete semantics of QNNs. Based on QA-IBP, we also develop a complete verification procedure for verifying the adversarial robustness of QNNs, which is guaranteed to terminate and produce a correct answer. Compared to existing approaches, the key advantage of our verification procedure is that it runs entirely on GPU or other accelerator devices. We demonstrate experimentally that our approach significantly outperforms existing methods and establish the new state-of-the-art for training and certifying the robustness of QNNs.
Solving Continuous Control via Q-learning
Oct 22, 2022While there has been substantial success in applying actor-critic methods to continuous control, simpler critic-only methods such as Q-learning often remain intractable in the associated high-dimensional action spaces. However, most actor-critic methods come at the cost of added complexity: heuristics for stabilization, compute requirements as well as wider hyperparameter search spaces. We show that these issues can be largely alleviated via Q-learning by combining action discretization with value decomposition, framing single-agent control as cooperative multi-agent reinforcement learning (MARL). With bang-bang actions, performance of this critic-only approach matches state-of-the-art continuous actor-critic methods when learning from features or pixels. We extend classical bandit examples from cooperative MARL to provide intuition for how decoupled critics leverage state information to coordinate joint optimization, and demonstrate surprisingly strong performance across a wide variety of continuous control tasks.
Interpreting Neural Policies with Disentangled Tree Representations
Oct 13, 2022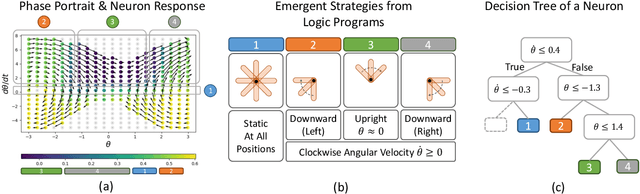
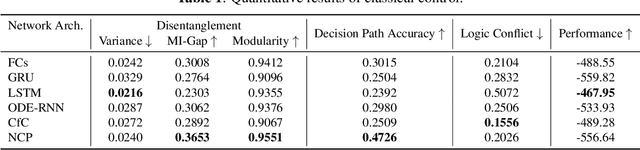
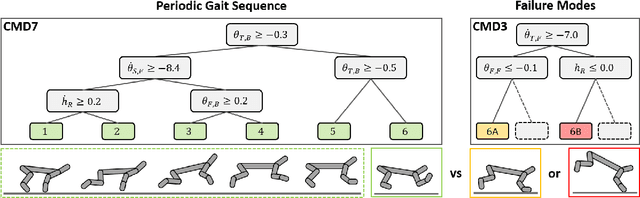
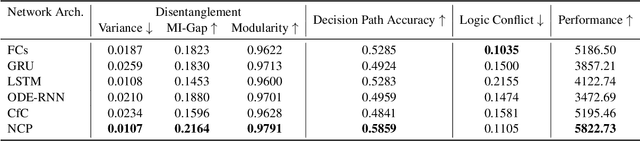
Compact neural networks used in policy learning and closed-loop end-to-end control learn representations from data that encapsulate agent dynamics and potentially the agent-environment's factors of variation. A formal and quantitative understanding and interpretation of these explanatory factors in neural representations is difficult to achieve due to the complex and intertwined correspondence of neural activities with emergent behaviors. In this paper, we design a new algorithm that programmatically extracts tree representations from compact neural policies, in the form of a set of logic programs grounded by the world state. To assess how well networks uncover the dynamics of the task and their factors of variation, we introduce interpretability metrics that measure the disentanglement of learned neural dynamics from a concentration of decisions, mutual information, and modularity perspectives. Moreover, our method allows us to quantify how accurate the extracted decision paths (explanations) are and computes cross-neuron logic conflict. We demonstrate the effectiveness of our approach with several types of compact network architectures on a series of end-to-end learning to control tasks.