 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Shape Completion via Adversarial Shape Priors
Apr 21, 2022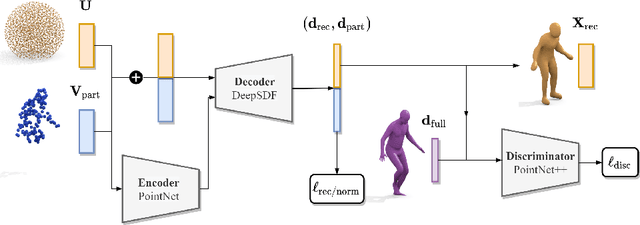

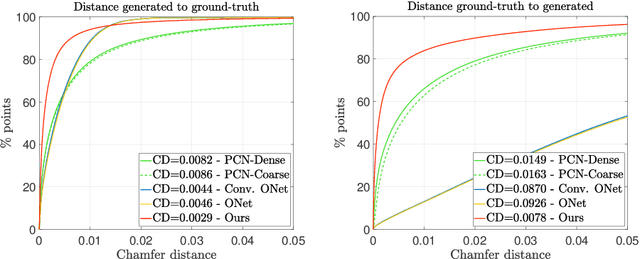

We present a novel neural implicit shape method for partial point cloud completion. To that end, we combine a conditional Deep-SDF architecture with learned, adversarial shape priors. More specifically, our network converts partial inputs into a global latent code and then recovers the full geometry via an implicit, signed distance generator. Additionally, we train a PointNet++ discriminator that impels the generator to produce plausible, globally consistent reconstructions. In that way, we effectively decouple the challenges of predicting shapes that are both realistic, i.e. imitate the training set's pose distribution, and accurate in the sense that they replicate the partial input observations. In our experiments, we demonstrate state-of-the-art performance for completing partial shapes, considering both man-made objects (e.g. airplanes, chairs, ...) and deformable shape categories (human bodies). Finally, we show that our adversarial training approach leads to visually plausible reconstructions that are highly consistent in recovering missing parts of a given object.
The Probabilistic Normal Epipolar Constraint for Frame-To-Frame Rotation Optimization under Uncertain Feature Positions
Apr 05, 2022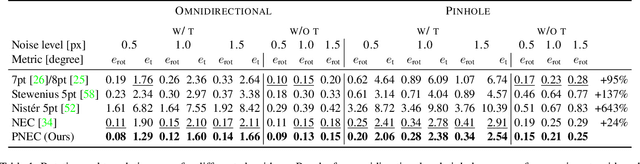

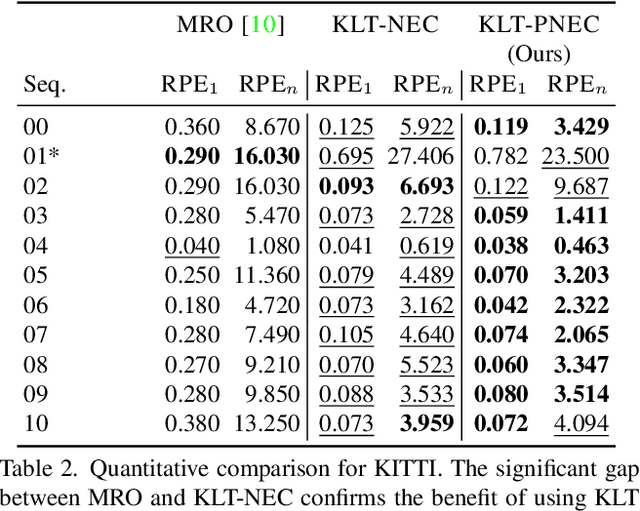
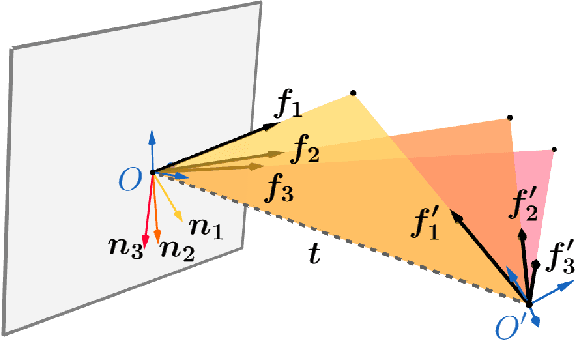
The estimation of the relative pose of two camera views is a fundamental problem in computer vision. Kneip et al. proposed to solve this problem by introducing the normal epipolar constraint (NEC). However, their approach does not take into account uncertainties, so that the accuracy of the estimated relative pose is highly dependent on accurate feature positions in the target frame. In this work, we introduce the probabilistic normal epipolar constraint (PNEC) that overcomes this limitation by accounting for anisotropic and inhomogeneous uncertainties in the feature positions. To this end, we propose a novel objective function, along with an efficient optimization scheme that effectively minimizes our objective while maintaining real-time performance. In experiments on synthetic data, we demonstrate that the novel PNEC yields more accurate rotation estimates than the original NEC and several popular relative rotation estimation algorithms. Furthermore, we integrate the proposed method into a state-of-the-art monocular rotation-only odometry system and achieve consistently improved results for the real-world KITTI dataset.
HDSDF: Hybrid Directional and Signed Distance Functions for Fast Inverse Rendering
Mar 30, 2022

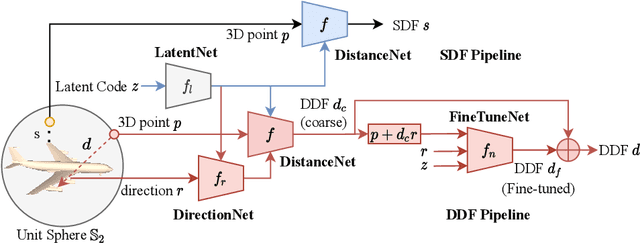
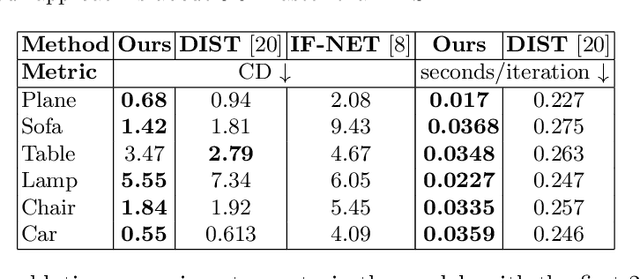
Implicit neural representations of 3D shapes form strong priors that are useful for various applications, such as single and multiple view 3D reconstruction. A downside of existing neural representations is that they require multiple network evaluations for rendering, which leads to high computational costs. This limitation forms a bottleneck particularly in the context of inverse problems, such as image-based 3D reconstruction. To address this issue, in this paper (i) we propose a novel hybrid 3D object representation based on a signed distance function (SDF) that we augment with a directional distance function (DDF), so that we can predict distances to the object surface from any point on a sphere enclosing the object. Moreover, (ii) using the proposed hybrid representation we address the multi-view consistency problem common in existing DDF representations. We evaluate our novel hybrid representation on the task of single-view depth reconstruction and show that our method is several times faster compared to competing methods, while at the same time achieving better reconstruction accuracy.
DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation
Mar 23, 2022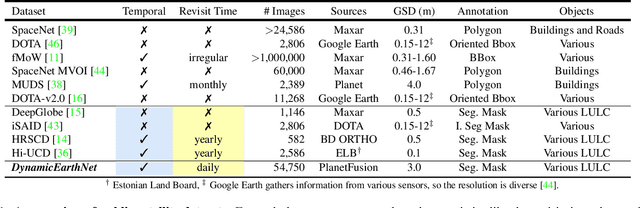
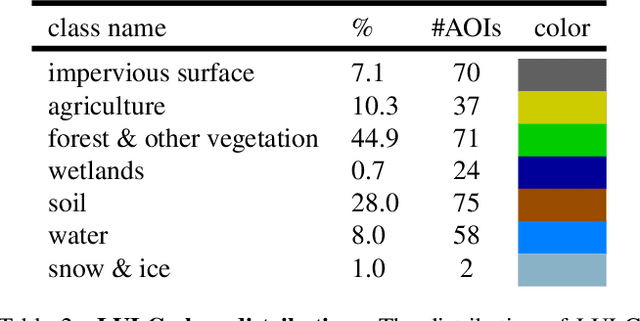

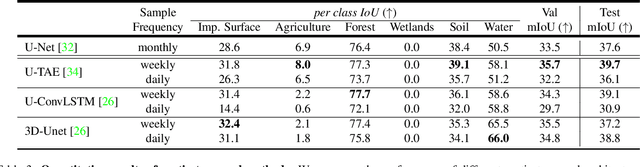
Earth observation is a fundamental tool for monitoring the evolution of land use in specific areas of interest. Observing and precisely defining change, in this context, requires both time-series data and pixel-wise segmentations. To that end, we propose the DynamicEarthNet dataset that consists of daily, multi-spectral satellite observations of 75 selected areas of interest distributed over the globe with imagery from Planet Labs. These observations are paired with pixel-wise monthly semantic segmentation labels of 7 land use and land cover (LULC) classes. DynamicEarthNet is the first dataset that provides this unique combination of daily measurements and high-quality labels. In our experiments, we compare several established baselines that either utilize the daily observations as additional training data (semi-supervised learning) or multiple observations at once (spatio-temporal learning) as a point of reference for future research. Finally, we propose a new evaluation metric SCS that addresses the specific challenges associated with time-series semantic change segmentation. The data is available at: https://mediatum.ub.tum.de/1650201.
Intrinsic Neural Fields: Learning Functions on Manifolds
Mar 23, 2022



Neural fields have gained significant attention in the computer vision community due to their excellent performance in novel view synthesis, geometry reconstruction, and generative modeling. Some of their advantages are a sound theoretic foundation and an easy implementation in current deep learning frameworks. While neural fields have been applied to signals on manifolds, e.g., for texture reconstruction, their representation has been limited to extrinsically embedding the shape into Euclidean space. The extrinsic embedding ignores known intrinsic manifold properties and is inflexible wrt. transfer of the learned function. To overcome these limitations, this work introduces intrinsic neural fields, a novel and versatile representation for neural fields on manifolds. Intrinsic neural fields combine the advantages of neural fields with the spectral properties of the Laplace-Beltrami operator. We show theoretically that intrinsic neural fields inherit many desirable properties of the extrinsic neural field framework but exhibit additional intrinsic qualities, like isometry invariance. In experiments, we show intrinsic neural fields can reconstruct high-fidelity textures from images with state-of-the-art quality and are robust to the discretization of the underlying manifold. We demonstrate the versatility of intrinsic neural fields by tackling various applications: texture transfer between deformed shapes & different shapes, texture reconstruction from real-world images with view dependence, and discretization-agnostic learning on meshes and point clouds.
Lateral Ego-Vehicle Control without Supervision using Point Clouds
Mar 20, 2022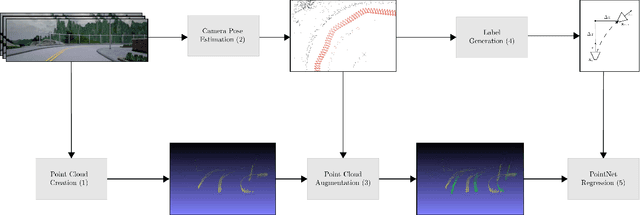
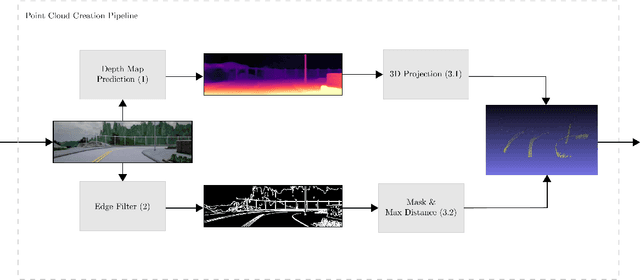

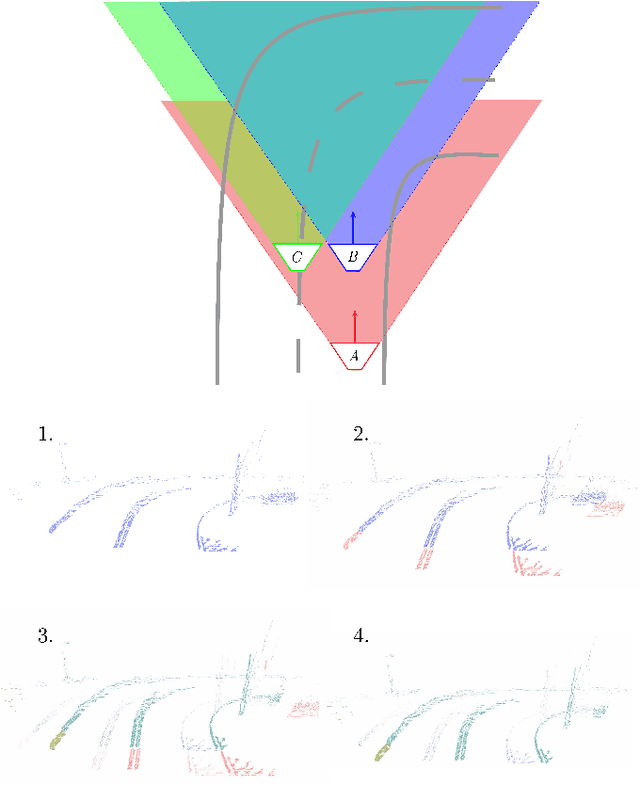
Existing vision based supervised approaches to lateral vehicle control are capable of directly mapping RGB images to the appropriate steering commands. However, they are prone to suffering from inadequate robustness in real world scenarios due to a lack of failure cases in the training data. In this paper, a framework for training a more robust and scalable model for lateral vehicle control is proposed. The framework only requires an unlabeled sequence of RGB images. The trained model takes a point cloud as input and predicts the lateral offset to a subsequent frame from which the steering angle is inferred. The frame poses are in turn obtained from visual odometry. The point cloud is conceived by projecting dense depth maps into 3D. An arbitrary number of additional trajectories from this point cloud can be generated during training. This is to increase the robustness of the model. Online experiments show that the performance of our method is superior to that of the supervised model.
Vision-based Large-scale 3D Semantic Mapping for Autonomous Driving Applications
Mar 02, 2022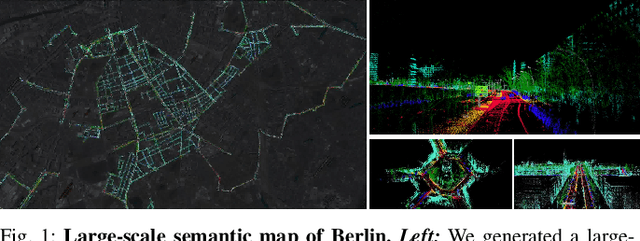
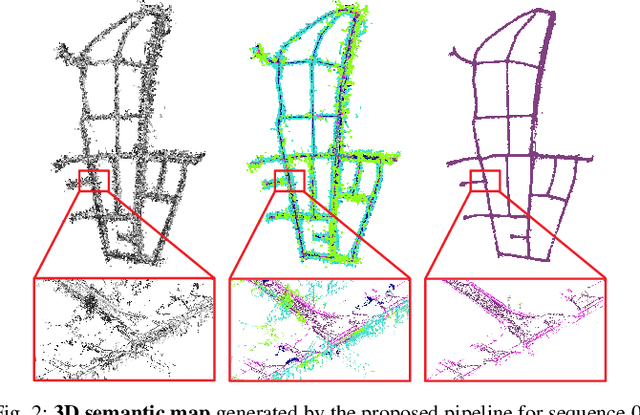
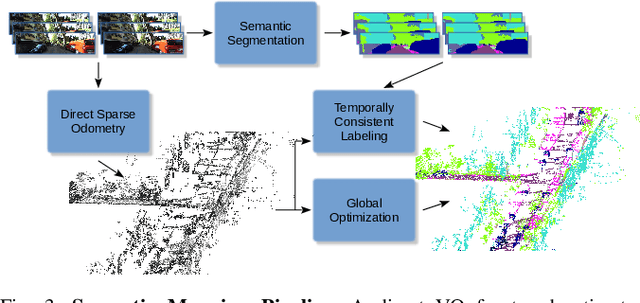
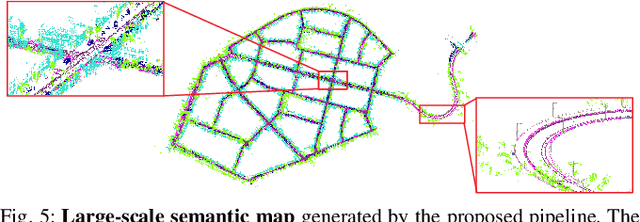
In this paper, we present a complete pipeline for 3D semantic mapping solely based on a stereo camera system. The pipeline comprises a direct sparse visual odometry front-end as well as a back-end for global optimization including GNSS integration, and semantic 3D point cloud labeling. We propose a simple but effective temporal voting scheme which improves the quality and consistency of the 3D point labels. Qualitative and quantitative evaluations of our pipeline are performed on the KITTI-360 dataset. The results show the effectiveness of our proposed voting scheme and the capability of our pipeline for efficient large-scale 3D semantic mapping. The large-scale mapping capabilities of our pipeline is furthermore demonstrated by presenting a very large-scale semantic map covering 8000 km of roads generated from data collected by a fleet of vehicles.
DM-VIO: Delayed Marginalization Visual-Inertial Odometry
Jan 11, 2022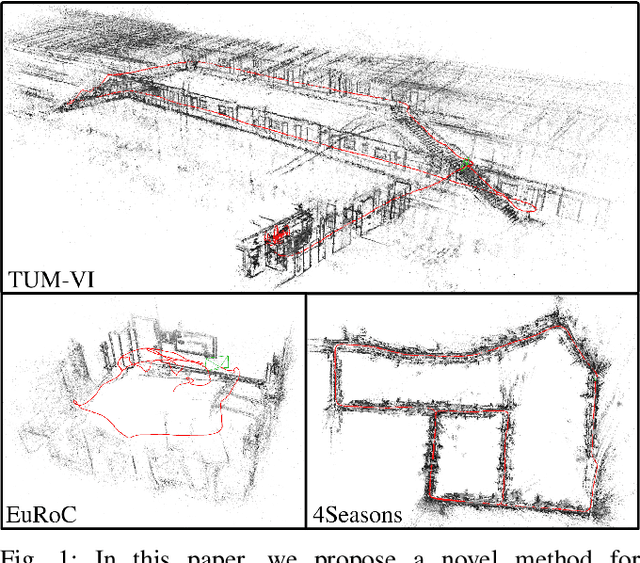
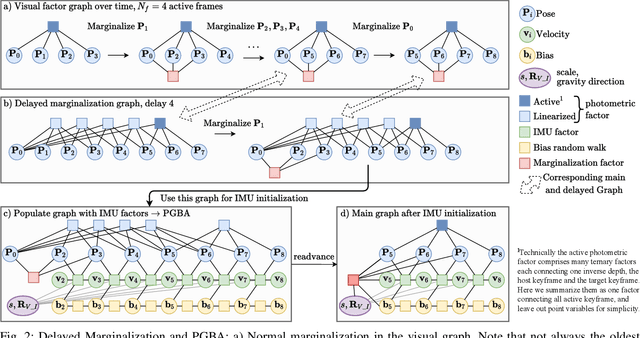
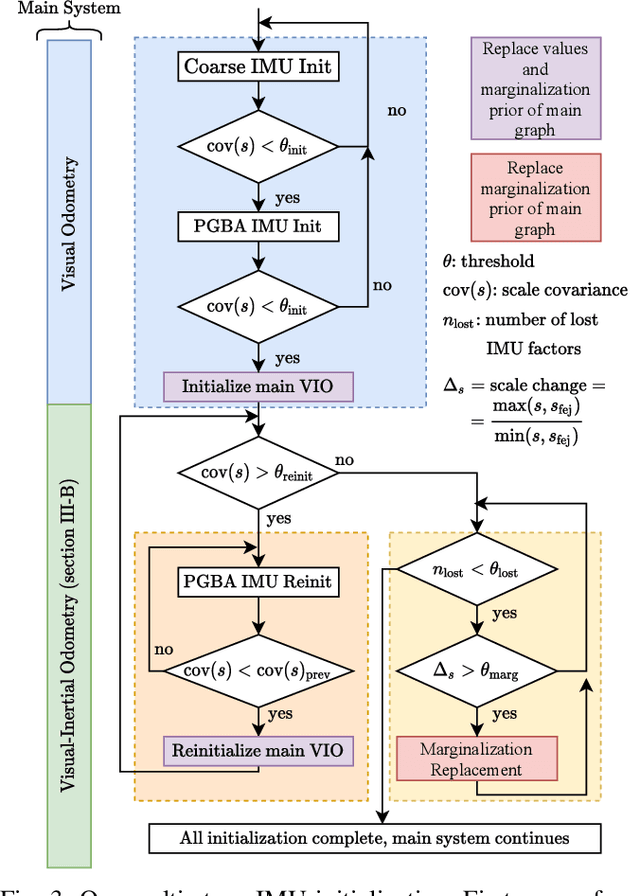
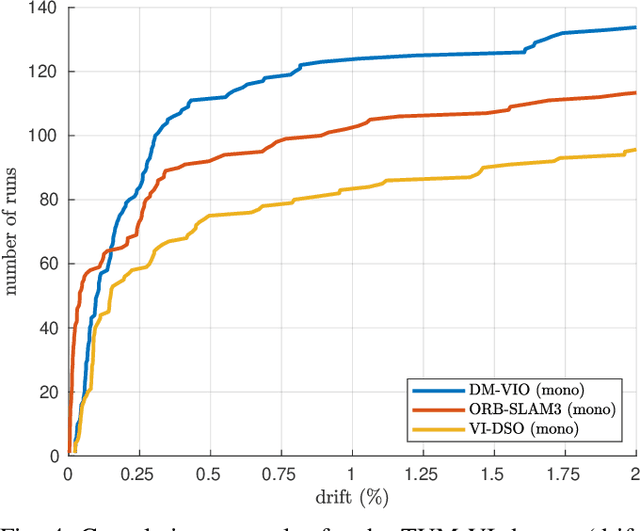
We present DM-VIO, a monocular visual-inertial odometry system based on two novel techniques called delayed marginalization and pose graph bundle adjustment. DM-VIO performs photometric bundle adjustment with a dynamic weight for visual residuals. We adopt marginalization, which is a popular strategy to keep the update time constrained, but it cannot easily be reversed, and linearization points of connected variables have to be fixed. To overcome this we propose delayed marginalization: The idea is to maintain a second factor graph, where marginalization is delayed. This allows us to later readvance this delayed graph, yielding an updated marginalization prior with new and consistent linearization points. In addition, delayed marginalization enables us to inject IMU information into already marginalized states. This is the foundation of the proposed pose graph bundle adjustment, which we use for IMU initialization. In contrast to prior works on IMU initialization, it is able to capture the full photometric uncertainty, improving the scale estimation. In order to cope with initially unobservable scale, we continue to optimize scale and gravity direction in the main system after IMU initialization is complete. We evaluate our system on the EuRoC, TUM-VI, and 4Seasons datasets, which comprise flying drone, large-scale handheld, and automotive scenarios. Thanks to the proposed IMU initialization, our system exceeds the state of the art in visual-inertial odometry, even outperforming stereo-inertial methods while using only a single camera and IMU. The code will be published at http://vision.in.tum.de/dm-vio
Shortest Paths in Graphs with Matrix-Valued Edges: Concepts, Algorithm and Application to 3D Multi-Shape Analysis
Dec 08, 2021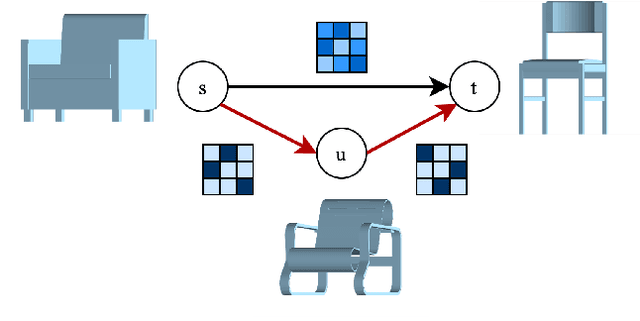
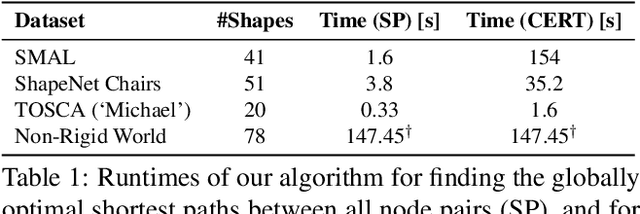
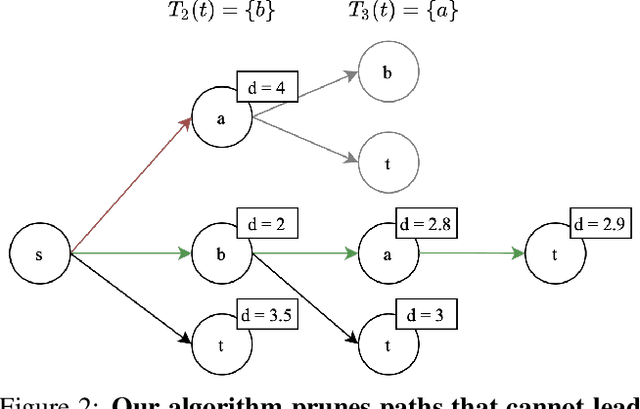
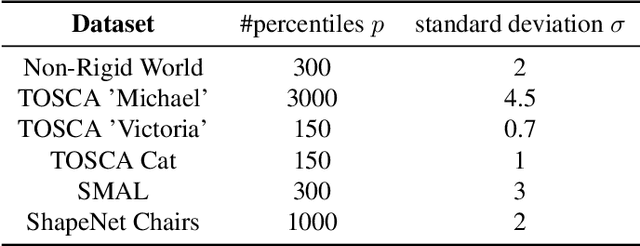
Finding shortest paths in a graph is relevant for numerous problems in computer vision and graphics, including image segmentation, shape matching, or the computation of geodesic distances on discrete surfaces. Traditionally, the concept of a shortest path is considered for graphs with scalar edge weights, which makes it possible to compute the length of a path by adding up the individual edge weights. Yet, graphs with scalar edge weights are severely limited in their expressivity, since oftentimes edges are used to encode significantly more complex interrelations. In this work we compensate for this modelling limitation and introduce the novel graph-theoretic concept of a shortest path in a graph with matrix-valued edges. To this end, we define a meaningful way for quantifying the path length for matrix-valued edges, and we propose a simple yet effective algorithm to compute the respective shortest path. While our formalism is universal and thus applicable to a wide range of settings in vision, graphics and beyond, we focus on demonstrating its merits in the context of 3D multi-shape analysis.
Gradient-SDF: A Semi-Implicit Surface Representation for 3D Reconstruction
Nov 26, 2021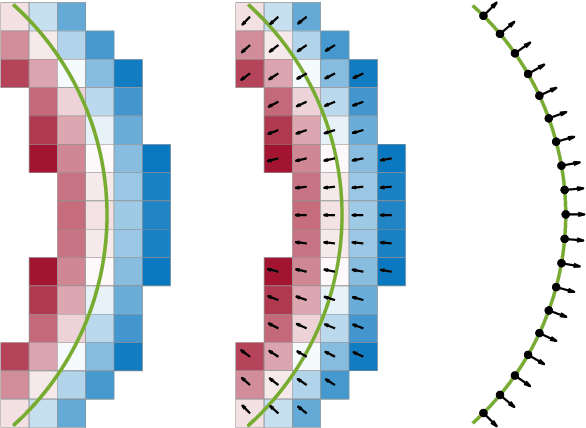
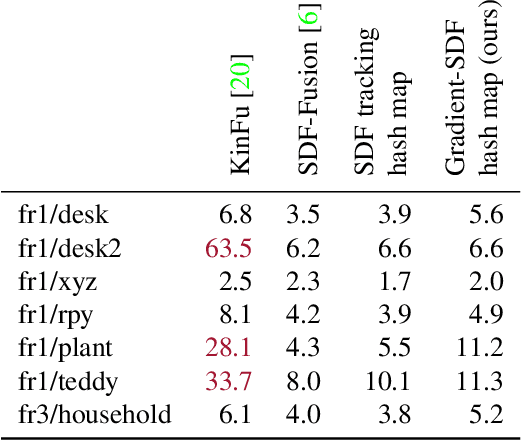

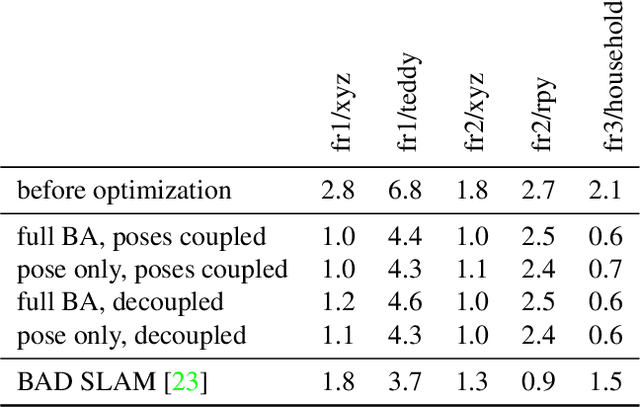
We present Gradient-SDF, a novel representation for 3D geometry that combines the advantages of implict and explicit representations. By storing at every voxel both the signed distance field as well as its gradient vector field, we enhance the capability of implicit representations with approaches originally formulated for explicit surfaces. As concrete examples, we show that (1) the Gradient-SDF allows us to perform direct SDF tracking from depth images, using efficient storage schemes like hash maps, and that (2) the Gradient-SDF representation enables us to perform photometric bundle adjustment directly in a voxel representation (without transforming into a point cloud or mesh), naturally a fully implicit optimization of geometry and camera poses and easy geometry upsampling. Experimental results confirm that this leads to significantly sharper reconstructions. Since the overall SDF voxel structure is still respected, the proposed Gradient-SDF is equally suited for (GPU) parallelization as related approaches.