 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Non-uniformity in First-order Non-convex Optimization
May 13, 2021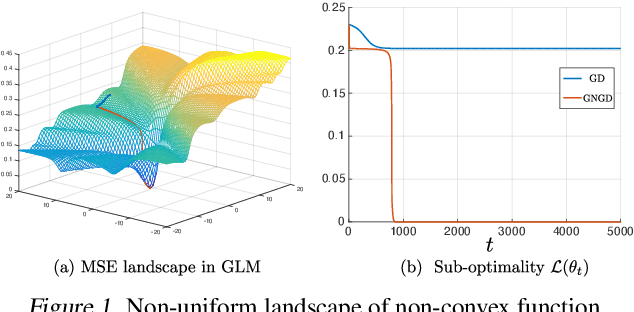
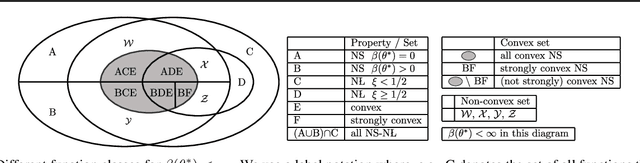
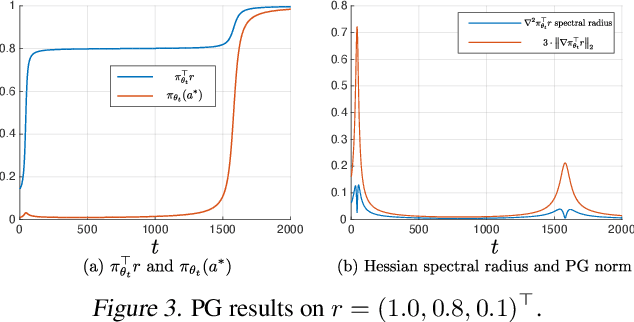
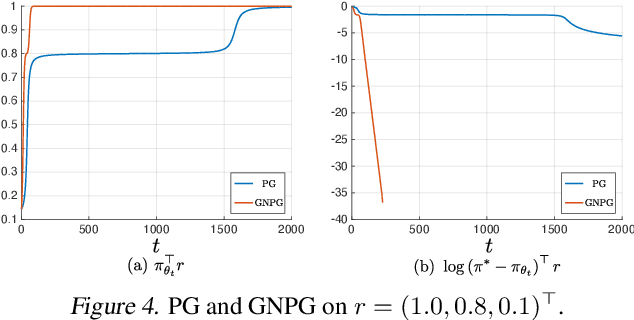
Classical global convergence results for first-order methods rely on uniform smoothness and the \L{}ojasiewicz inequality. Motivated by properties of objective functions that arise in machine learning, we propose a non-uniform refinement of these notions, leading to \emph{Non-uniform Smoothness} (NS) and \emph{Non-uniform \L{}ojasiewicz inequality} (N\L{}). The new definitions inspire new geometry-aware first-order methods that are able to converge to global optimality faster than the classical $\Omega(1/t^2)$ lower bounds. To illustrate the power of these geometry-aware methods and their corresponding non-uniform analysis, we consider two important problems in machine learning: policy gradient optimization in reinforcement learning (PG), and generalized linear model training in supervised learning (GLM). For PG, we find that normalizing the gradient ascent method can accelerate convergence to $O(e^{-t})$ while incurring less overhead than existing algorithms. For GLM, we show that geometry-aware normalized gradient descent can also achieve a linear convergence rate, which significantly improves the best known results. We additionally show that the proposed geometry-aware descent methods escape landscape plateaus faster than standard gradient descent. Experimental results are used to illustrate and complement the theoretical findings.
Joint Attention for Multi-Agent Coordination and Social Learning
Apr 15, 2021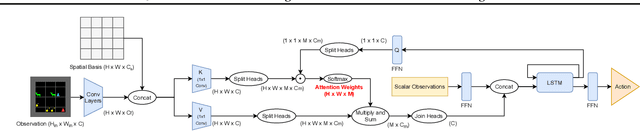
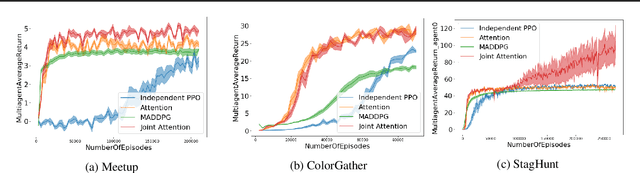
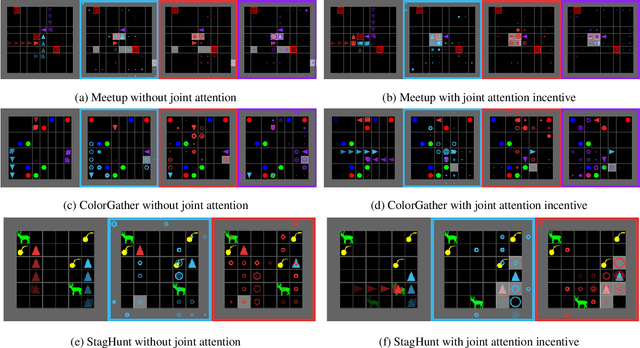
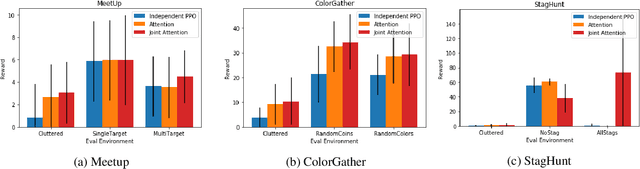
Joint attention - the ability to purposefully coordinate attention with another agent, and mutually attend to the same thing -- is a critical component of human social cognition. In this paper, we ask whether joint attention can be useful as a mechanism for improving multi-agent coordination and social learning. We first develop deep reinforcement learning (RL) agents with a recurrent visual attention architecture. We then train agents to minimize the difference between the attention weights that they apply to the environment at each timestep, and the attention of other agents. Our results show that this joint attention incentive improves agents' ability to solve difficult coordination tasks, by reducing the exponential cost of exploring the joint multi-agent action space. Joint attention leads to higher performance than a competitive centralized critic baseline across multiple environments. Further, we show that joint attention enhances agents' ability to learn from experts present in their environment, even when completing hard exploration tasks that do not require coordination. Taken together, these findings suggest that joint attention may be a useful inductive bias for multi-agent learning.
On the Optimality of Batch Policy Optimization Algorithms
Apr 06, 2021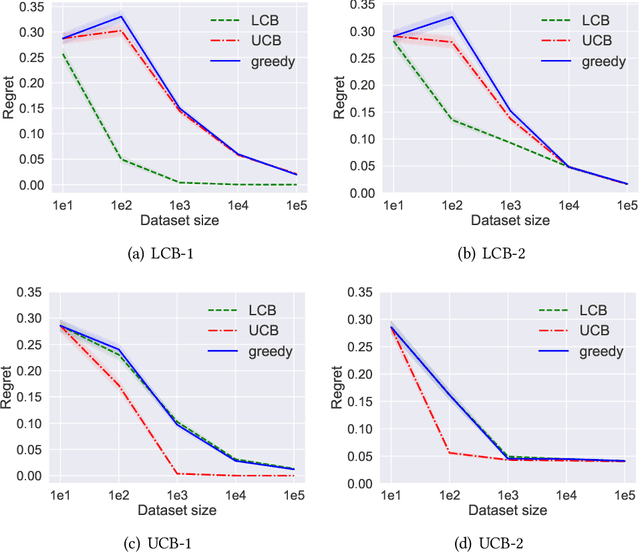
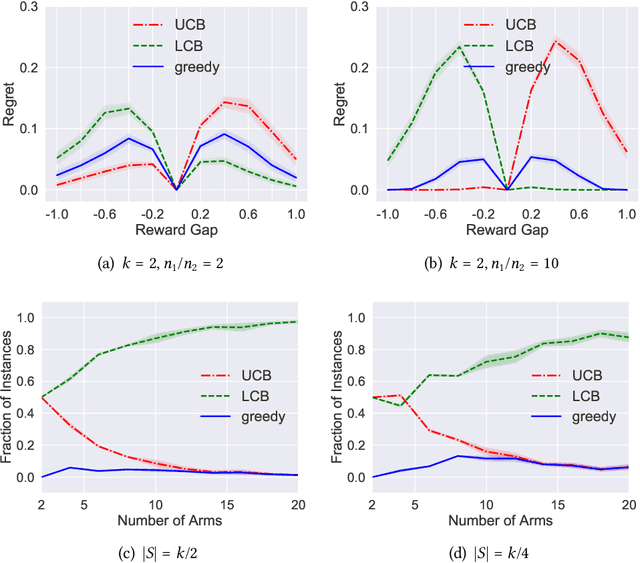
Batch policy optimization considers leveraging existing data for policy construction before interacting with an environment. Although interest in this problem has grown significantly in recent years, its theoretical foundations remain under-developed. To advance the understanding of this problem, we provide three results that characterize the limits and possibilities of batch policy optimization in the finite-armed stochastic bandit setting. First, we introduce a class of confidence-adjusted index algorithms that unifies optimistic and pessimistic principles in a common framework, which enables a general analysis. For this family, we show that any confidence-adjusted index algorithm is minimax optimal, whether it be optimistic, pessimistic or neutral. Our analysis reveals that instance-dependent optimality, commonly used to establish optimality of on-line stochastic bandit algorithms, cannot be achieved by any algorithm in the batch setting. In particular, for any algorithm that performs optimally in some environment, there exists another environment where the same algorithm suffers arbitrarily larger regret. Therefore, to establish a framework for distinguishing algorithms, we introduce a new weighted-minimax criterion that considers the inherent difficulty of optimal value prediction. We demonstrate how this criterion can be used to justify commonly used pessimistic principles for batch policy optimization.
Optimization Issues in KL-Constrained Approximate Policy Iteration
Feb 11, 2021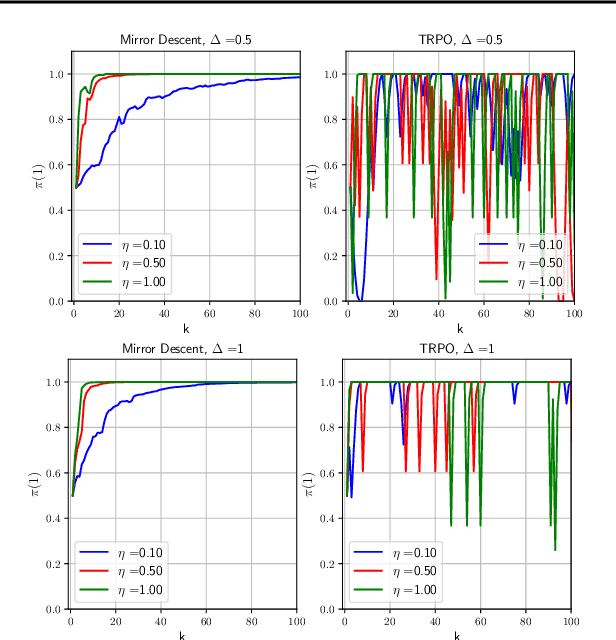
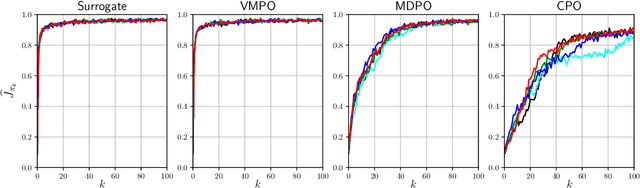
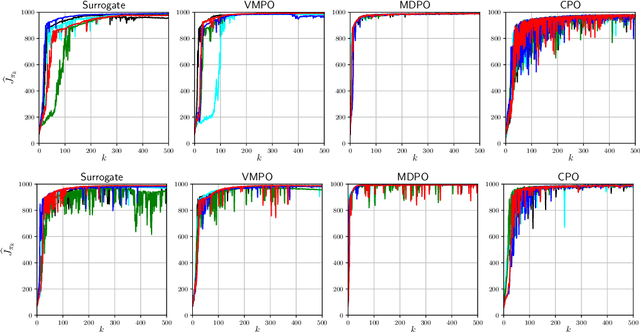
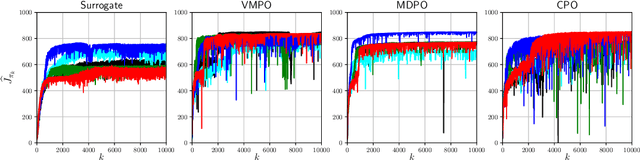
Many reinforcement learning algorithms can be seen as versions of approximate policy iteration (API). While standard API often performs poorly, it has been shown that learning can be stabilized by regularizing each policy update by the KL-divergence to the previous policy. Popular practical algorithms such as TRPO, MPO, and VMPO replace regularization by a constraint on KL-divergence of consecutive policies, arguing that this is easier to implement and tune. In this work, we study this implementation choice in more detail. We compare the use of KL divergence as a constraint vs. as a regularizer, and point out several optimization issues with the widely-used constrained approach. We show that the constrained algorithm is not guaranteed to converge even on simple problem instances where the constrained problem can be solved exactly, and in fact incurs linear expected regret. With approximate implementation using softmax policies, we show that regularization can improve the optimization landscape of the original objective. We demonstrate these issues empirically on several bandit and RL environments.
Offline Policy Selection under Uncertainty
Dec 12, 2020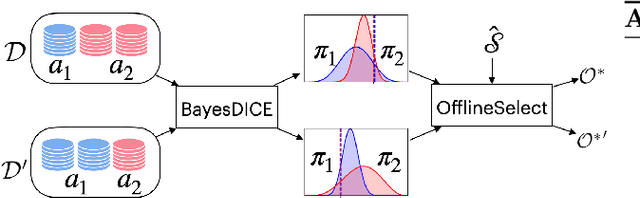
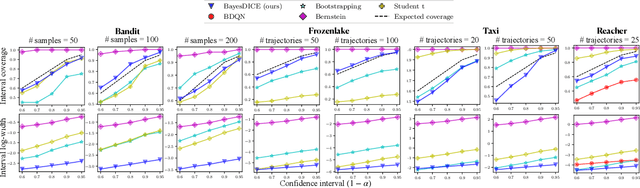
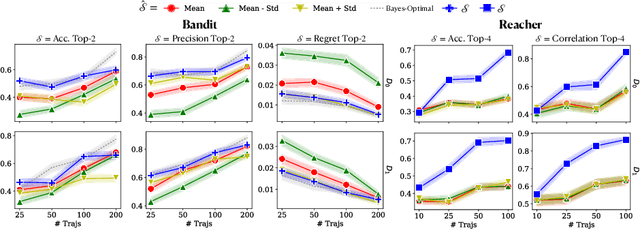
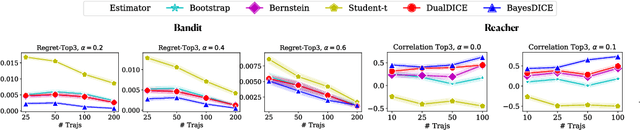
The presence of uncertainty in policy evaluation significantly complicates the process of policy ranking and selection in real-world settings. We formally consider offline policy selection as learning preferences over a set of policy prospects given a fixed experience dataset. While one can select or rank policies based on point estimates of their policy values or high-confidence intervals, access to the full distribution over one's belief of the policy value enables more flexible selection algorithms under a wider range of downstream evaluation metrics. We propose BayesDICE for estimating this belief distribution in terms of posteriors of distribution correction ratios derived from stochastic constraints (as opposed to explicit likelihood, which is not available). Empirically, BayesDICE is highly competitive to existing state-of-the-art approaches in confidence interval estimation. More importantly, we show how the belief distribution estimated by BayesDICE may be used to rank policies with respect to any arbitrary downstream policy selection metric, and we empirically demonstrate that this selection procedure significantly outperforms existing approaches, such as ranking policies according to mean or high-confidence lower bound value estimates.
Learning Discrete Energy-based Models via Auxiliary-variable Local Exploration
Nov 10, 2020
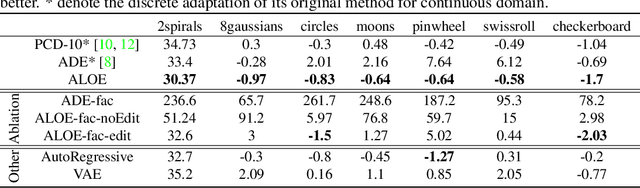
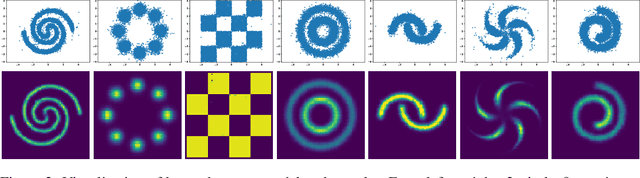

Discrete structures play an important role in applications like program language modeling and software engineering. Current approaches to predicting complex structures typically consider autoregressive models for their tractability, with some sacrifice in flexibility. Energy-based models (EBMs) on the other hand offer a more flexible and thus more powerful approach to modeling such distributions, but require partition function estimation. In this paper we propose ALOE, a new algorithm for learning conditional and unconditional EBMs for discrete structured data, where parameter gradients are estimated using a learned sampler that mimics local search. We show that the energy function and sampler can be trained efficiently via a new variational form of power iteration, achieving a better trade-off between flexibility and tractability. Experimentally, we show that learning local search leads to significant improvements in challenging application domains. Most notably, we present an energy model guided fuzzer for software testing that achieves comparable performance to well engineered fuzzing engines like libfuzzer.
CoinDICE: Off-Policy Confidence Interval Estimation
Oct 22, 2020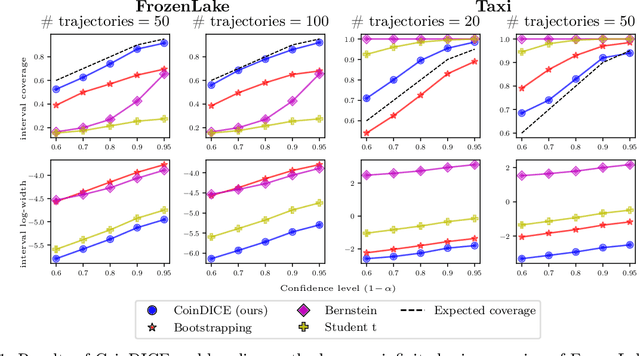
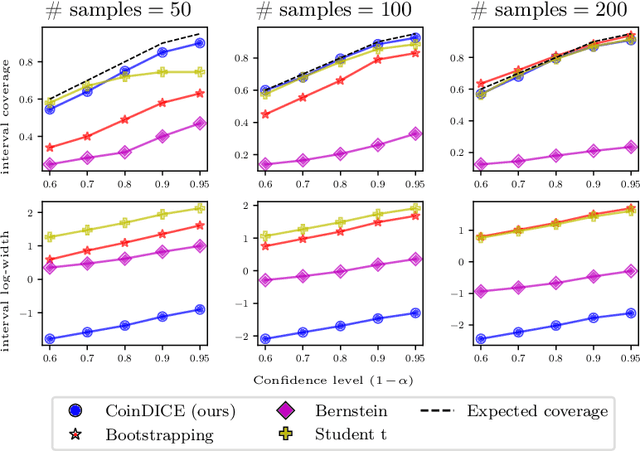
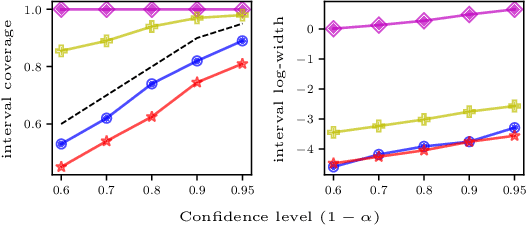
We study high-confidence behavior-agnostic off-policy evaluation in reinforcement learning, where the goal is to estimate a confidence interval on a target policy's value, given only access to a static experience dataset collected by unknown behavior policies. Starting from a function space embedding of the linear program formulation of the $Q$-function, we obtain an optimization problem with generalized estimating equation constraints. By applying the generalized empirical likelihood method to the resulting Lagrangian, we propose CoinDICE, a novel and efficient algorithm for computing confidence intervals. Theoretically, we prove the obtained confidence intervals are valid, in both asymptotic and finite-sample regimes. Empirically, we show in a variety of benchmarks that the confidence interval estimates are tighter and more accurate than existing methods.
Attention that does not Explain Away
Sep 29, 2020

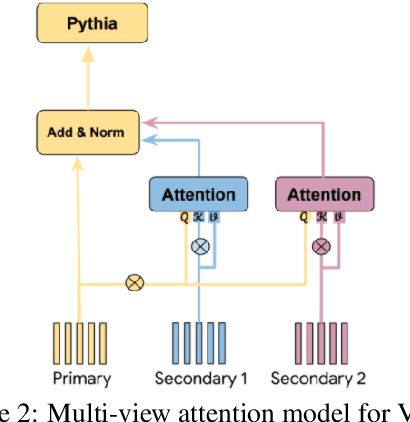

Models based on the Transformer architecture have achieved better accuracy than the ones based on competing architectures for a large set of tasks. A unique feature of the Transformer is its universal application of a self-attention mechanism, which allows for free information flow at arbitrary distances. Following a probabilistic view of the attention via the Gaussian mixture model, we find empirical evidence that the Transformer attention tends to "explain away" certain input neurons. To compensate for this, we propose a doubly-normalized attention scheme that is simple to implement and provides theoretical guarantees for avoiding the "explaining away" effect without introducing significant computational or memory cost. Empirically, we show that the new attention schemes result in improved performance on several well-known benchmarks.
EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
Jul 21, 2020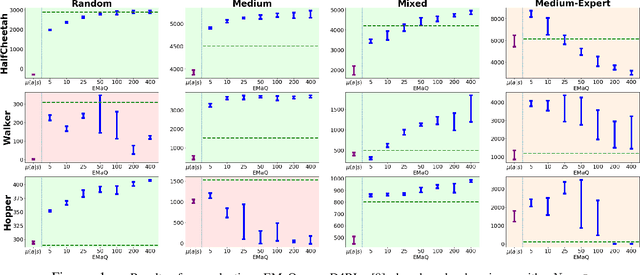
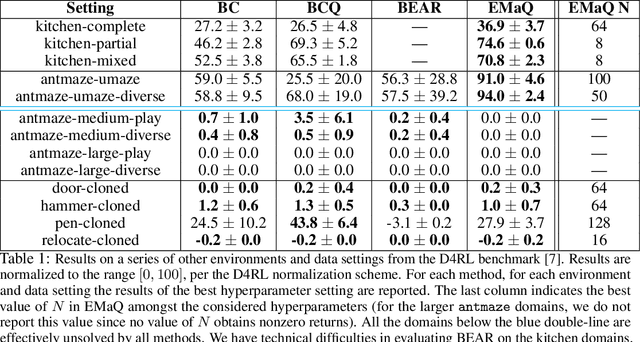
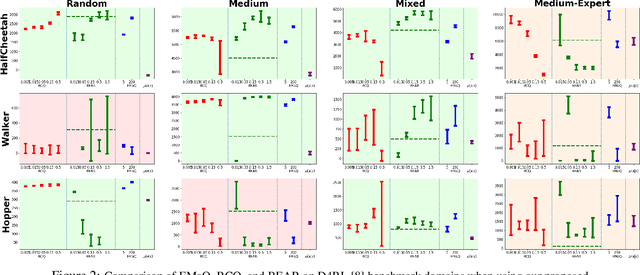
Off-policy reinforcement learning (RL) holds the promise of sample-efficient learning of decision-making policies by leveraging past experience. However, in the offline RL setting -- where a fixed collection of interactions are provided and no further interactions are allowed -- it has been shown that standard off-policy RL methods can significantly underperform. Recently proposed methods aim to address this shortcoming by regularizing learned policies to remain close to the given dataset of interactions. However, these methods involve several configurable components such as learning a separate policy network on top of a behavior cloning actor, and explicitly constraining action spaces through clipping or reward penalties. Striving for simultaneous simplicity and performance, in this work we present a novel backup operator, Expected-Max Q-Learning (EMaQ), which naturally restricts learned policies to remain within the support of the offline dataset \emph{without any explicit regularization}, while retaining desirable theoretical properties such as contraction. We demonstrate that EMaQ is competitive with Soft Actor Critic (SAC) in online RL, and surpasses SAC in the deployment-efficient setting. In the offline RL setting -- the main focus of this work -- through EMaQ we are able to make important observations regarding key components of offline RL, and the nature of standard benchmark tasks. Lastly but importantly, we observe that EMaQ achieves state-of-the-art performance with fewer moving parts such as one less function approximation, making it a strong, yet easy to implement baseline for future work.
Off-Policy Evaluation via the Regularized Lagrangian
Jul 07, 2020

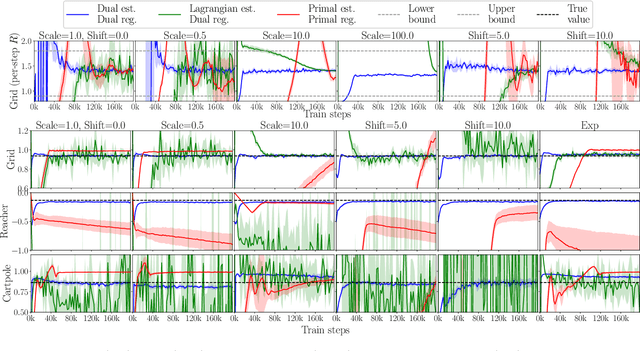
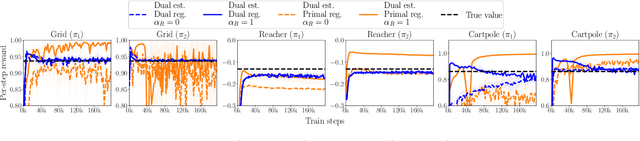
The recently proposed distribution correction estimation (DICE) family of estimators has advanced the state of the art in off-policy evaluation from behavior-agnostic data. While these estimators all perform some form of stationary distribution correction, they arise from different derivations and objective functions. In this paper, we unify these estimators as regularized Lagrangians of the same linear program. The unification allows us to expand the space of DICE estimators to new alternatives that demonstrate improved performance. More importantly, by analyzing the expanded space of estimators both mathematically and empirically we find that dual solutions offer greater flexibility in navigating the tradeoff between optimization stability and estimation bias, and generally provide superior estimates in practice.