 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Maximum A Posteriori Estimation on Unpaired Data for Motion Deblurring
Apr 26, 2022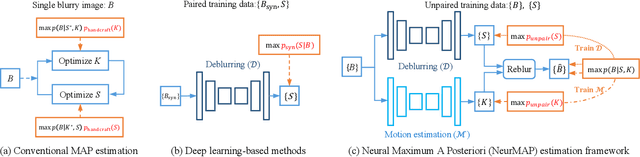
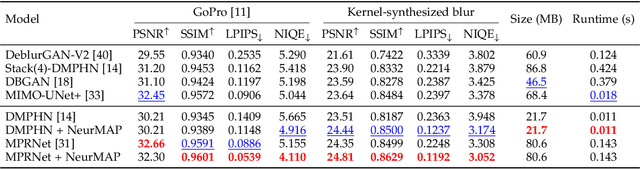

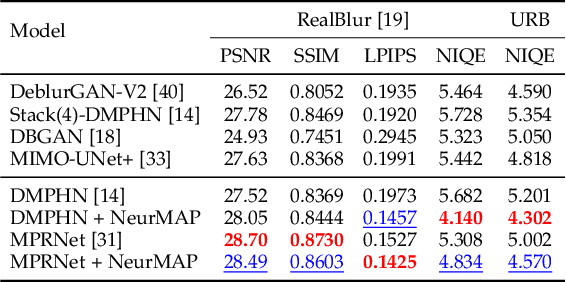
Real-world dynamic scene deblurring has long been a challenging task since paired blurry-sharp training data is unavailable. Conventional Maximum A Posteriori estimation and deep learning-based deblurring methods are restricted by handcrafted priors and synthetic blurry-sharp training pairs respectively, thereby failing to generalize to real dynamic blurriness. To this end, we propose a Neural Maximum A Posteriori (NeurMAP) estimation framework for training neural networks to recover blind motion information and sharp content from unpaired data. The proposed NeruMAP consists of a motion estimation network and a deblurring network which are trained jointly to model the (re)blurring process (i.e. likelihood function). Meanwhile, the motion estimation network is trained to explore the motion information in images by applying implicit dynamic motion prior, and in return enforces the deblurring network training (i.e. providing sharp image prior). The proposed NeurMAP is an orthogonal approach to existing deblurring neural networks, and is the first framework that enables training image deblurring networks on unpaired datasets. Experiments demonstrate our superiority on both quantitative metrics and visual quality over state-of-the-art methods. Codes are available on https://github.com/yjzhang96/NeurMAP-deblur.
BLISS: Robust Sequence-to-Sequence Learning via Self-Supervised Input Representation
Apr 24, 2022
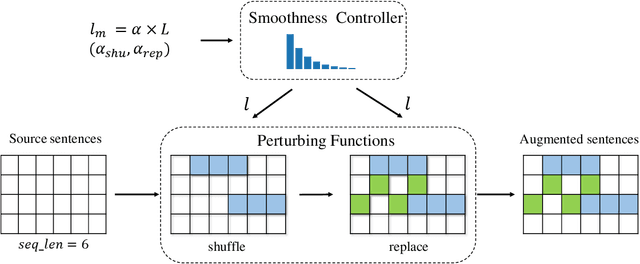
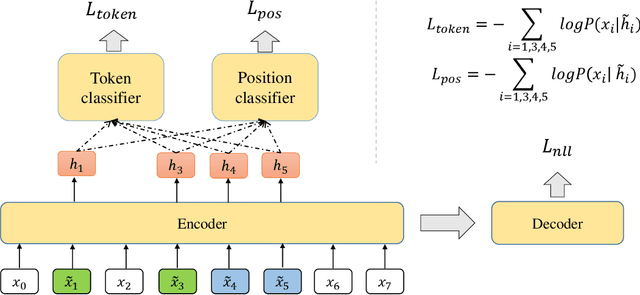
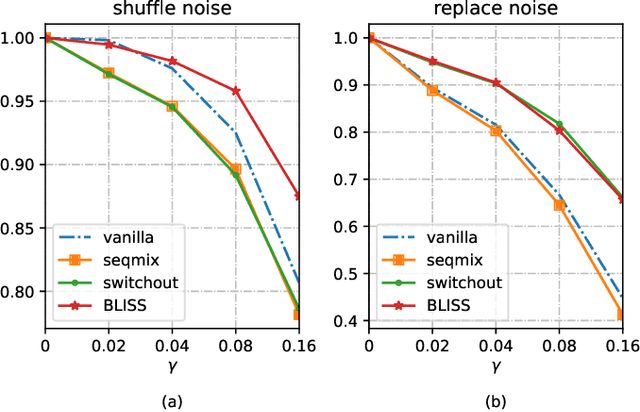
Data augmentations (DA) are the cores to achieving robust sequence-to-sequence learning on various natural language processing (NLP) tasks. However, most of the DA approaches force the decoder to make predictions conditioned on the perturbed input representation, underutilizing supervised information provided by perturbed input. In this work, we propose a framework-level robust sequence-to-sequence learning approach, named BLISS, via self-supervised input representation, which has the great potential to complement the data-level augmentation approaches. The key idea is to supervise the sequence-to-sequence framework with both the \textit{supervised} ("input$\rightarrow$output") and \textit{self-supervised} ("perturbed input$\rightarrow$input") information. We conduct comprehensive experiments to validate the effectiveness of BLISS on various tasks, including machine translation, grammatical error correction, and text summarization. The results show that BLISS outperforms significantly the vanilla Transformer and consistently works well across tasks than the other five contrastive baselines. Extensive analyses reveal that BLISS learns robust representations and rich linguistic knowledge, confirming our claim. Source code will be released upon publication.
Source-Free Domain Adaptation via Distribution Estimation
Apr 24, 2022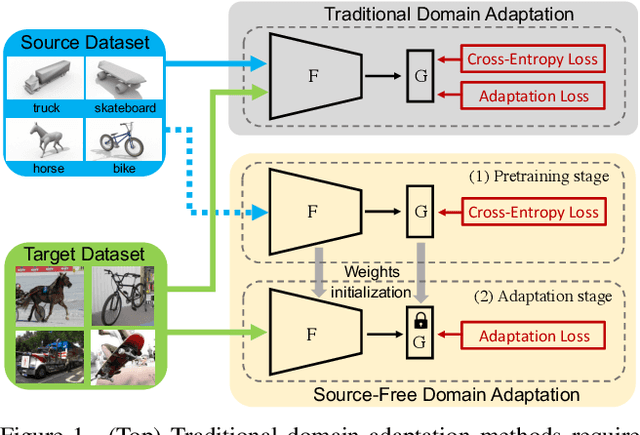
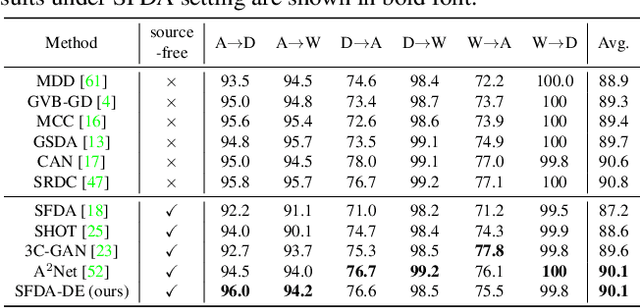
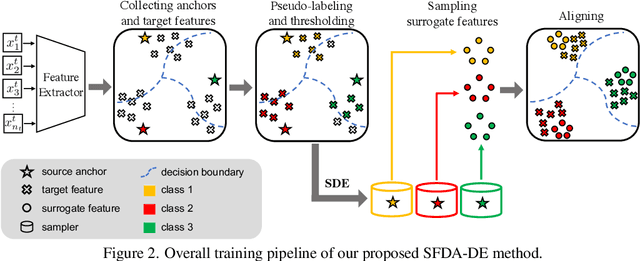
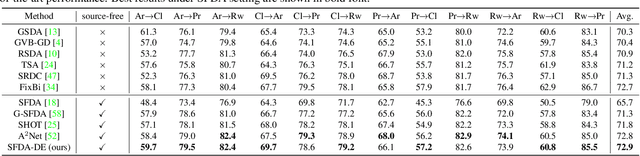
Domain Adaptation aims to transfer the knowledge learned from a labeled source domain to an unlabeled target domain whose data distributions are different. However, the training data in source domain required by most of the existing methods is usually unavailable in real-world applications due to privacy preserving policies. Recently, Source-Free Domain Adaptation (SFDA) has drawn much attention, which tries to tackle domain adaptation problem without using source data. In this work, we propose a novel framework called SFDA-DE to address SFDA task via source Distribution Estimation. Firstly, we produce robust pseudo-labels for target data with spherical k-means clustering, whose initial class centers are the weight vectors (anchors) learned by the classifier of pretrained model. Furthermore, we propose to estimate the class-conditioned feature distribution of source domain by exploiting target data and corresponding anchors. Finally, we sample surrogate features from the estimated distribution, which are then utilized to align two domains by minimizing a contrastive adaptation loss function. Extensive experiments show that the proposed method achieves state-of-the-art performance on multiple DA benchmarks, and even outperforms traditional DA methods which require plenty of source data.
A Model-Agnostic Data Manipulation Method for Persona-based Dialogue Generation
Apr 21, 2022
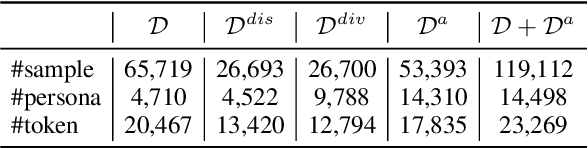
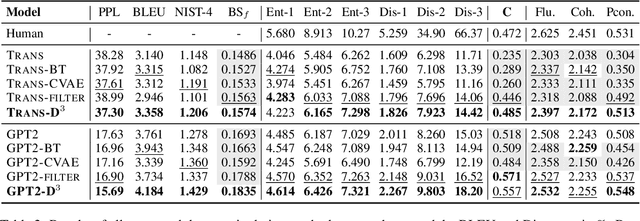
Towards building intelligent dialogue agents, there has been a growing interest in introducing explicit personas in generation models. However, with limited persona-based dialogue data at hand, it may be difficult to train a dialogue generation model well. We point out that the data challenges of this generation task lie in two aspects: first, it is expensive to scale up current persona-based dialogue datasets; second, each data sample in this task is more complex to learn with than conventional dialogue data. To alleviate the above data issues, we propose a data manipulation method, which is model-agnostic to be packed with any persona-based dialogue generation model to improve its performance. The original training samples will first be distilled and thus expected to be fitted more easily. Next, we show various effective ways that can diversify such easier distilled data. A given base model will then be trained via the constructed data curricula, i.e. first on augmented distilled samples and then on original ones. Experiments illustrate the superiority of our method with two strong base dialogue models (Transformer encoder-decoder and GPT2).
VSA: Learning Varied-Size Window Attention in Vision Transformers
Apr 18, 2022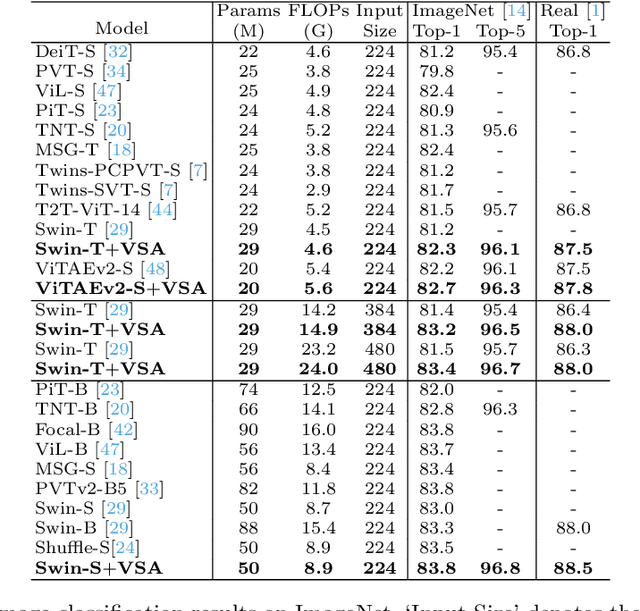
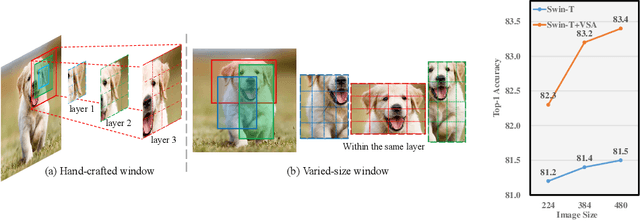
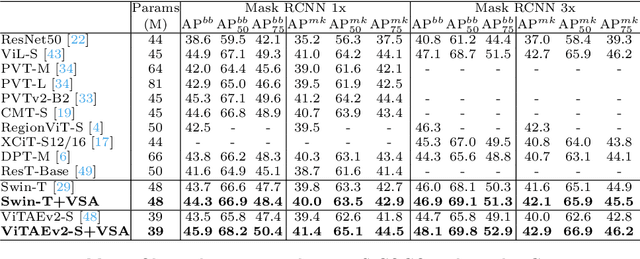
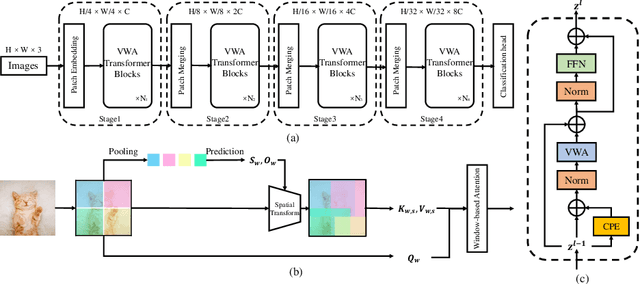
Attention within windows has been widely explored in vision transformers to balance the performance, computation complexity, and memory footprint. However, current models adopt a hand-crafted fixed-size window design, which restricts their capacity of modeling long-term dependencies and adapting to objects of different sizes. To address this drawback, we propose \textbf{V}aried-\textbf{S}ize Window \textbf{A}ttention (VSA) to learn adaptive window configurations from data. Specifically, based on the tokens within each default window, VSA employs a window regression module to predict the size and location of the target window, i.e., the attention area where the key and value tokens are sampled. By adopting VSA independently for each attention head, it can model long-term dependencies, capture rich context from diverse windows, and promote information exchange among overlapped windows. VSA is an easy-to-implement module that can replace the window attention in state-of-the-art representative models with minor modifications and negligible extra computational cost while improving their performance by a large margin, e.g., 1.1\% for Swin-T on ImageNet classification. In addition, the performance gain increases when using larger images for training and test. Experimental results on more downstream tasks, including object detection, instance segmentation, and semantic segmentation, further demonstrate the superiority of VSA over the vanilla window attention in dealing with objects of different sizes. The code will be released https://github.com/ViTAE-Transformer/ViTAE-VSA.
Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Apr 16, 2022
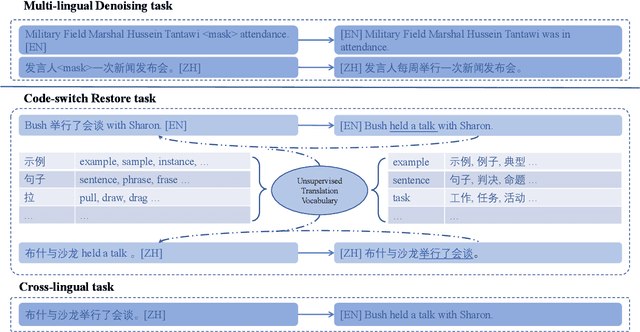
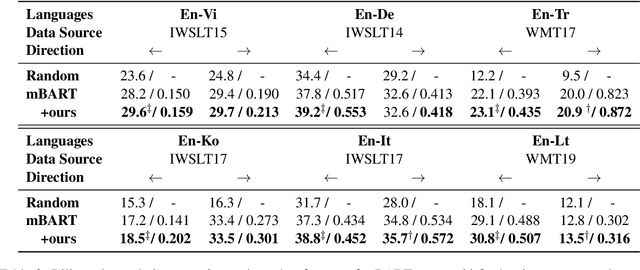
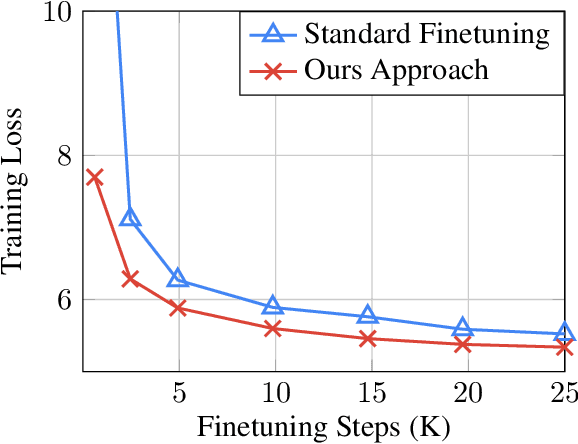
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.
A Contrastive Cross-Channel Data Augmentation Framework for Aspect-based Sentiment Analysis
Apr 16, 2022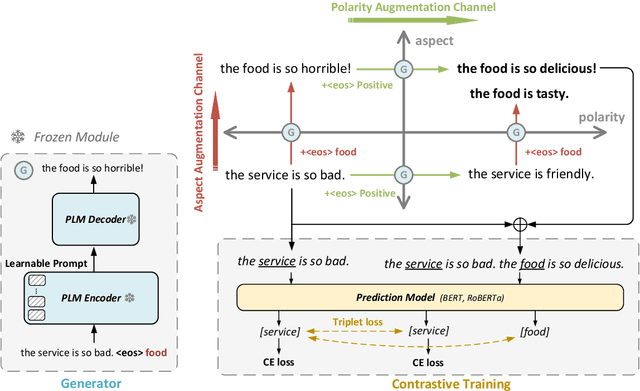


Aspect-Based Sentiment Analysis is a fine-grained sentiment analysis task, which focuses on detecting the sentiment polarity towards the aspect in a sentence. However, it is always sensitive to the multi-aspect challenge, where features of multiple aspects in a sentence will affect each other. To mitigate this issue, we design a novel training framework, called Contrastive Cross-Channel Data Augmentation (C3DA). A source sentence will be fed a domain-specific generator to obtain some synthetic sentences and is concatenated with these generated sentences to conduct supervised training and proposed contrastive training. To be specific, considering the limited ABSA labeled data, we also introduce some parameter-efficient approaches to complete sentences generation. This novel generation method consists of an Aspect Augmentation Channel (AAC) to generate aspect-specific sentences and a Polarity Augmentation (PAC) to generate polarity-inverted sentences. According to our extensive experiments, our C3DA framework can outperform those baselines without any augmentations by about 1\% on accuracy and Macro-F1.
Graph Pooling for Graph Neural Networks: Progress, Challenges, and Opportunities
Apr 15, 2022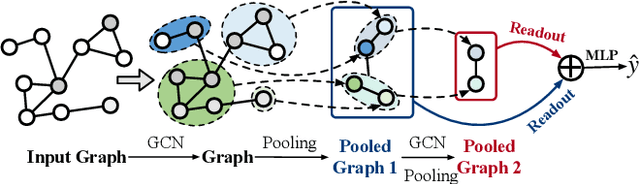

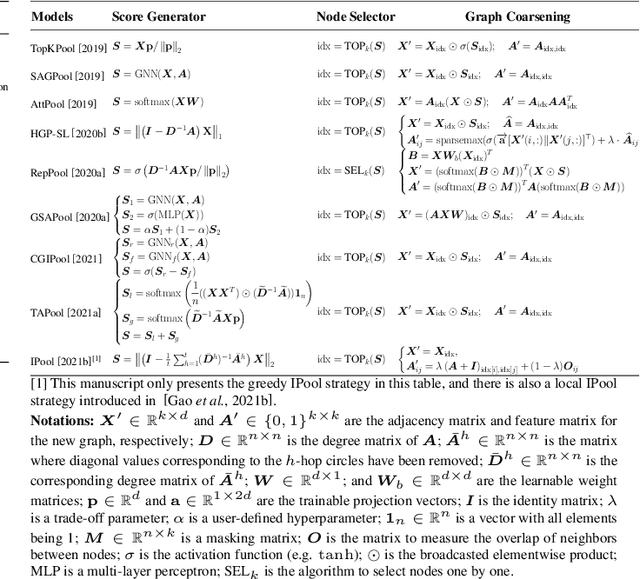
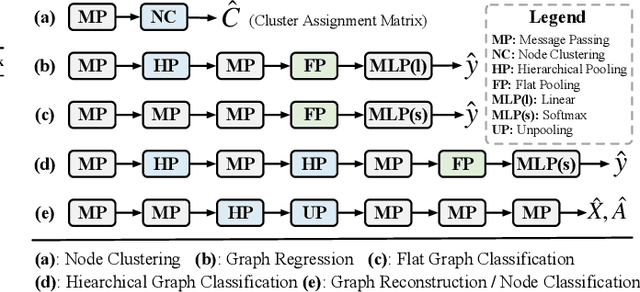
Graph neural networks have emerged as a leading architecture for many graph-level tasks such as graph classification and graph generation with a notable improvement. Among these tasks, graph pooling is an essential component of graph neural network architectures for obtaining a holistic graph-level representation of the entire graph. Although a great variety of methods have been proposed in this promising and fast-developing research field, to the best of our knowledge, little effort has been made to systematically summarize these methods. To set the stage for the development of future works, in this paper, we attempt to fill this gap by providing a broad review of recent methods on graph pooling. Specifically, 1) we first propose a taxonomy of existing graph pooling methods and provide a mathematical summary for each category; 2) next, we provide an overview of the libraries related to graph pooling, including the commonly used datasets, model architectures for downstream tasks, and open-source implementations; 3) then, we further outline in brief the applications that incorporate the idea of graph pooling in a number of domains; 4) and finally, we discuss some critical challenges faced by the current studies and share our insights on potential directions for improving graph pooling in the future.
Defensive Patches for Robust Recognition in the Physical World
Apr 13, 2022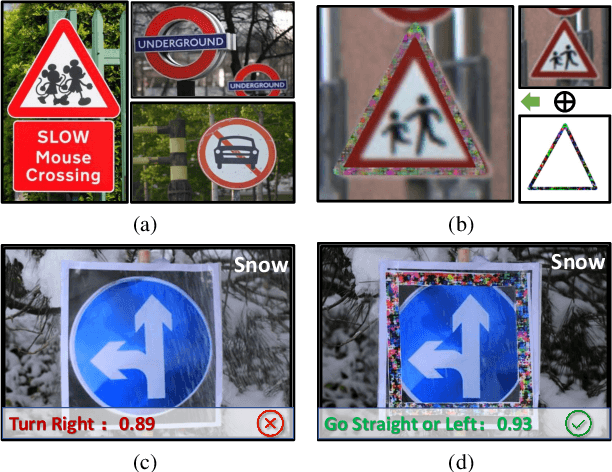
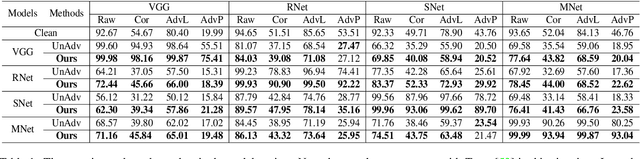
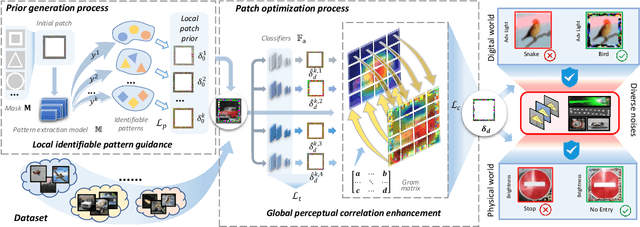
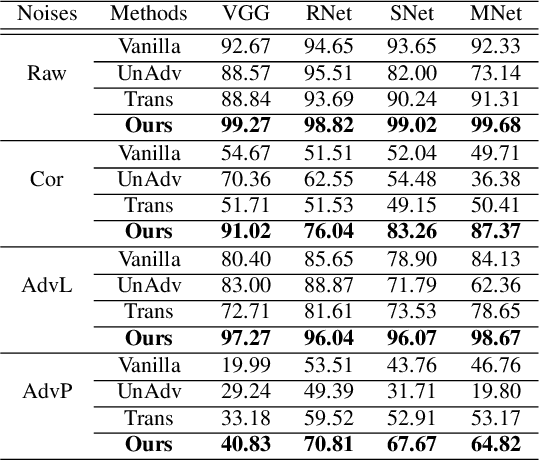
To operate in real-world high-stakes environments, deep learning systems have to endure noises that have been continuously thwarting their robustness. Data-end defense, which improves robustness by operations on input data instead of modifying models, has attracted intensive attention due to its feasibility in practice. However, previous data-end defenses show low generalization against diverse noises and weak transferability across multiple models. Motivated by the fact that robust recognition depends on both local and global features, we propose a defensive patch generation framework to address these problems by helping models better exploit these features. For the generalization against diverse noises, we inject class-specific identifiable patterns into a confined local patch prior, so that defensive patches could preserve more recognizable features towards specific classes, leading models for better recognition under noises. For the transferability across multiple models, we guide the defensive patches to capture more global feature correlations within a class, so that they could activate model-shared global perceptions and transfer better among models. Our defensive patches show great potentials to improve application robustness in practice by simply sticking them around target objects. Extensive experiments show that we outperform others by large margins (improve 20+\% accuracy for both adversarial and corruption robustness on average in the digital and physical world). Our codes are available at https://github.com/nlsde-safety-team/DefensivePatch
Panoptic-PartFormer: Learning a Unified Model for Panoptic Part Segmentation
Apr 10, 2022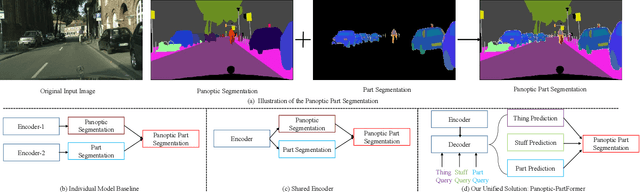

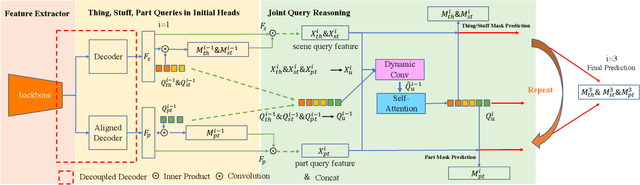
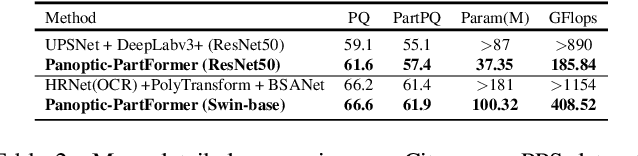
Panoptic Part Segmentation (PPS) aims to unify panoptic segmentation and part segmentation into one task. Previous work mainly utilizes separated approaches to handle thing, stuff, and part predictions individually without performing any shared computation and task association. In this work, we aim to unify these tasks at the architectural level, designing the first end-to-end unified method named Panoptic-PartFormer. In particular, motivated by the recent progress in Vision Transformer, we model things, stuff, and part as object queries and directly learn to optimize the all three predictions as unified mask prediction and classification problem. We design a decoupled decoder to generate part feature and thing/stuff feature respectively. Then we propose to utilize all the queries and corresponding features to perform reasoning jointly and iteratively. The final mask can be obtained via inner product between queries and the corresponding features. The extensive ablation studies and analysis prove the effectiveness of our framework. Our Panoptic-PartFormer achieves the new state-of-the-art results on both Cityscapes PPS and Pascal Context PPS datasets with at least 70% GFlops and 50% parameters decrease. In particular, we get 3.4% relative improvements with ResNet50 backbone and 10% improvements after adopting Swin Transformer on Pascal Context PPS dataset. To the best of our knowledge, we are the first to solve the PPS problem via \textit{a unified and end-to-end transformer model. Given its effectiveness and conceptual simplicity, we hope our Panoptic-PartFormer can serve as a good baseline and aid future unified research for PPS. Our code and models will be available at https://github.com/lxtGH/Panoptic-PartFormer.