 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Segmentation of Novel White Matter Tracts via Extensive Data Augmentation
Mar 13, 2023Deep learning based methods have achieved state-of-the-art performance for automated white matter (WM) tract segmentation. In these methods, the segmentation model needs to be trained with a large number of manually annotated scans, which can be accumulated throughout time. When novel WM tracts, i.e., tracts not included in the existing annotated WM tracts, are to be segmented, additional annotations of these novel WM tracts need to be collected. Since tract annotation is time-consuming and costly, it is desirable to make only a few annotations of novel WM tracts for training the segmentation model, and previous work has addressed this problem by transferring the knowledge learned for segmenting existing WM tracts to the segmentation of novel WM tracts. However, accurate segmentation of novel WM tracts can still be challenging in the one-shot setting, where only one scan is annotated for the novel WM tracts. In this work, we explore the problem of one-shot segmentation of novel WM tracts. Since in the one-shot setting the annotated training data is extremely scarce, based on the existing knowledge transfer framework, we propose to further perform extensive data augmentation for the single annotated scan, where synthetic annotated training data is produced. We have designed several different strategies that mask out regions in the single annotated scan for data augmentation. Our method was evaluated on public and in-house datasets. The experimental results show that our method improves the accuracy of one-shot segmentation of novel WM tracts.
Positive-unlabeled learning for binary and multi-class cell detection in histopathology images with incomplete annotations
Feb 16, 2023Cell detection in histopathology images is of great interest to clinical practice and research, and convolutional neural networks (CNNs) have achieved remarkable cell detection results. Typically, to train CNN-based cell detection models, every positive instance in the training images needs to be annotated, and instances that are not labeled as positive are considered negative samples. However, manual cell annotation is complicated due to the large number and diversity of cells, and it can be difficult to ensure the annotation of every positive instance. In many cases, only incomplete annotations are available, where some of the positive instances are annotated and the others are not, and the classification loss term for negative samples in typical network training becomes incorrect. In this work, to address this problem of incomplete annotations, we propose to reformulate the training of the detection network as a positive-unlabeled learning problem. Since the instances in unannotated regions can be either positive or negative, they have unknown labels. Using the samples with unknown labels and the positively labeled samples, we first derive an approximation of the classification loss term corresponding to negative samples for binary cell detection, and based on this approximation we further extend the proposed framework to multi-class cell detection. For evaluation, experiments were performed on four publicly available datasets. The experimental results show that our method improves the performance of cell detection in histopathology images given incomplete annotations for network training.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2022:027. arXiv admin note: text overlap with arXiv:2106.15918
A microstructure estimation Transformer inspired by sparse representation for diffusion MRI
May 13, 2022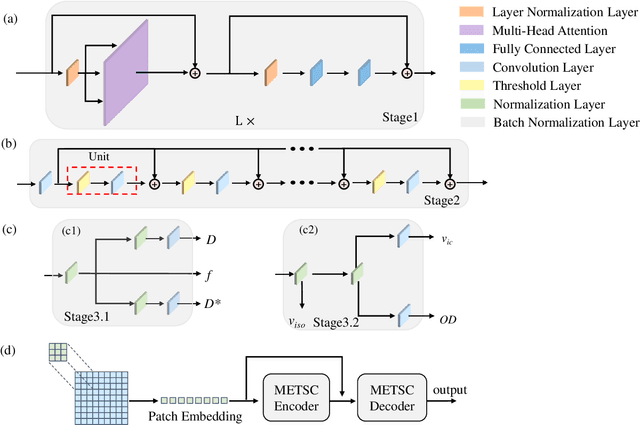
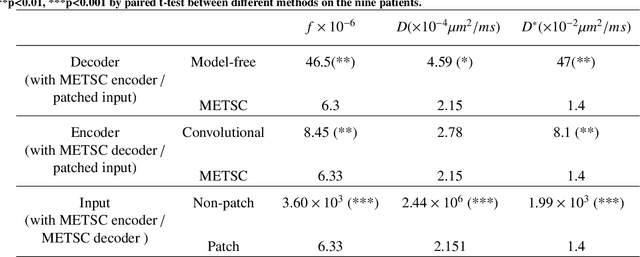
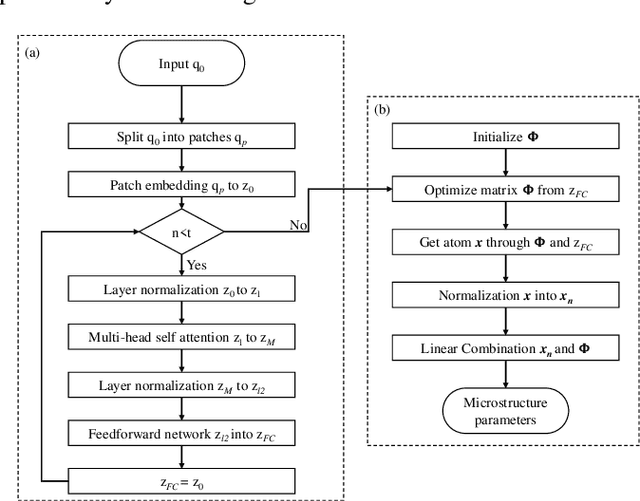

Diffusion magnetic resonance imaging (dMRI) is an important tool in characterizing tissue microstructure based on biophysical models, which are complex and highly non-linear. Resolving microstructures with optimization techniques is prone to estimation errors and requires dense sampling in the q-space. Deep learning based approaches have been proposed to overcome these limitations. Motivated by the superior performance of the Transformer, in this work, we present a learning-based framework based on Transformer, namely, a Microstructure Estimation Transformer with Sparse Coding (METSC) for dMRI-based microstructure estimation with downsampled q-space data. To take advantage of the Transformer while addressing its limitation in large training data requirements, we explicitly introduce an inductive bias - model bias into the Transformer using a sparse coding technique to facilitate the training process. Thus, the METSC is composed with three stages, an embedding stage, a sparse representation stage, and a mapping stage. The embedding stage is a Transformer-based structure that encodes the signal to ensure the voxel is represented effectively. In the sparse representation stage, a dictionary is constructed by solving a sparse reconstruction problem that unfolds the Iterative Hard Thresholding (IHT) process. The mapping stage is essentially a decoder that computes the microstructural parameters from the output of the second stage, based on the weighted sum of normalized dictionary coefficients where the weights are also learned. We tested our framework on two dMRI models with downsampled q-space data, including the intravoxel incoherent motion (IVIM) model and the neurite orientation dispersion and density imaging (NODDI) model. The proposed method achieved up to 11.25 folds of acceleration in scan time and outperformed the other state-of-the-art learning-based methods.
CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
Aug 17, 2021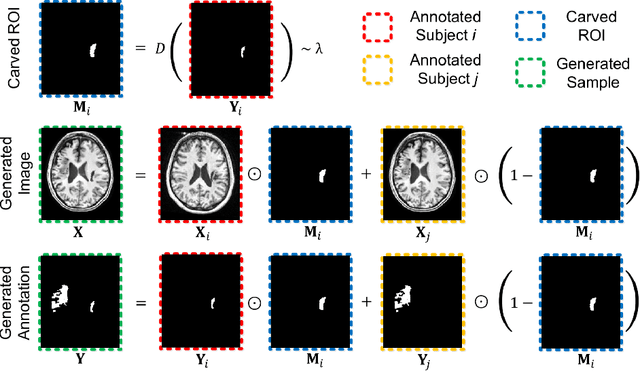

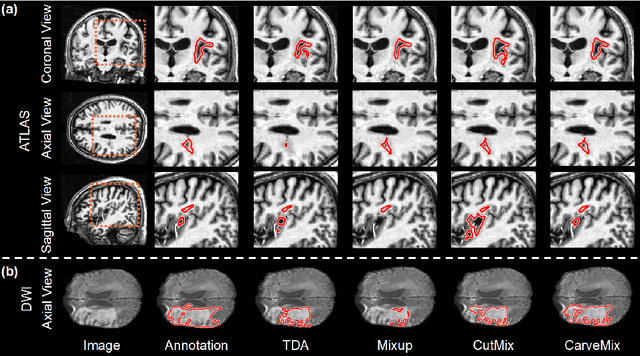
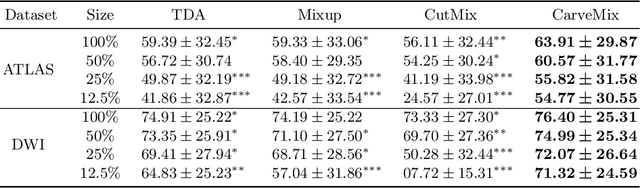
Brain lesion segmentation provides a valuable tool for clinical diagnosis, and convolutional neural networks (CNNs) have achieved unprecedented success in the task. Data augmentation is a widely used strategy that improves the training of CNNs, and the design of the augmentation method for brain lesion segmentation is still an open problem. In this work, we propose a simple data augmentation approach, dubbed as CarveMix, for CNN-based brain lesion segmentation. Like other "mix"-based methods, such as Mixup and CutMix, CarveMix stochastically combines two existing labeled images to generate new labeled samples. Yet, unlike these augmentation strategies based on image combination, CarveMix is lesion-aware, where the combination is performed with an attention on the lesions and a proper annotation is created for the generated image. Specifically, from one labeled image we carve a region of interest (ROI) according to the lesion location and geometry, and the size of the ROI is sampled from a probability distribution. The carved ROI then replaces the corresponding voxels in a second labeled image, and the annotation of the second image is replaced accordingly as well. In this way, we generate new labeled images for network training and the lesion information is preserved. To evaluate the proposed method, experiments were performed on two brain lesion datasets. The results show that our method improves the segmentation accuracy compared with other simple data augmentation approaches.
Positive-unlabeled Learning for Cell Detection in Histopathology Images with Incomplete Annotations
Jun 30, 2021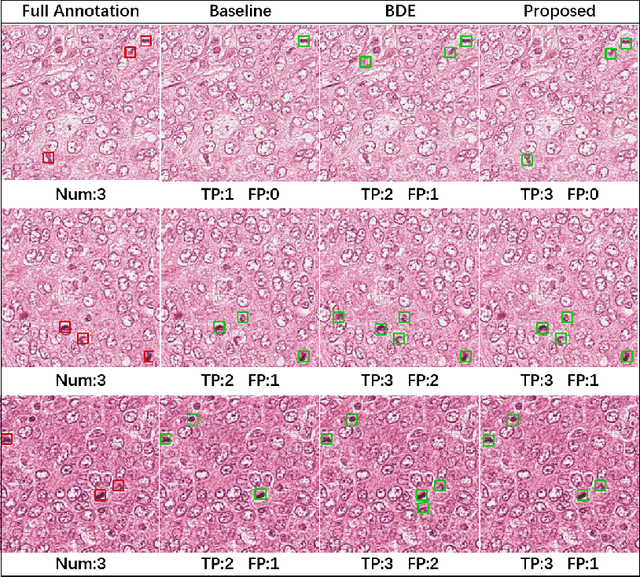

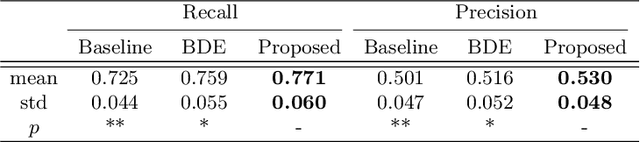
Cell detection in histopathology images is of great value in clinical practice. \textit{Convolutional neural networks} (CNNs) have been applied to cell detection to improve the detection accuracy, where cell annotations are required for network training. However, due to the variety and large number of cells, complete annotations that include every cell of interest in the training images can be challenging. Usually, incomplete annotations can be achieved, where positive labeling results are carefully examined to ensure their reliability but there can be other positive instances, i.e., cells of interest, that are not included in the annotations. This annotation strategy leads to a lack of knowledge about true negative samples. Most existing methods simply treat instances that are not labeled as positive as truly negative during network training, which can adversely affect the network performance. In this work, to address the problem of incomplete annotations, we formulate the training of detection networks as a positive-unlabeled learning problem. Specifically, the classification loss in network training is revised to take into account incomplete annotations, where the terms corresponding to negative samples are approximated with the true positive samples and the other samples of which the labels are unknown. To evaluate the proposed method, experiments were performed on a publicly available dataset for mitosis detection in breast cancer cells, and the experimental results show that our method improves the performance of cell detection given incomplete annotations for training.
Knowledge Transfer for Few-shot Segmentation of Novel White Matter Tracts
Jun 01, 2021



Convolutional neural networks (CNNs) have achieved stateof-the-art performance for white matter (WM) tract segmentation based on diffusion magnetic resonance imaging (dMRI). These CNNs require a large number of manual delineations of the WM tracts of interest for training, which are generally labor-intensive and costly. The expensive manual delineation can be a particular disadvantage when novel WM tracts, i.e., tracts that have not been included in existing manual delineations, are to be analyzed. To accurately segment novel WM tracts, it is desirable to transfer the knowledge learned about existing WM tracts, so that even with only a few delineations of the novel WM tracts, CNNs can learn adequately for the segmentation. In this paper, we explore the transfer of such knowledge to the segmentation of novel WM tracts in the few-shot setting. Although a classic fine-tuning strategy can be used for the purpose, the information in the last task-specific layer for segmenting existing WM tracts is completely discarded. We hypothesize that the weights of this last layer can bear valuable information for segmenting the novel WM tracts and thus completely discarding the information is not optimal. In particular, we assume that the novel WM tracts can correlate with existing WM tracts and the segmentation of novel WM tracts can be predicted with the logits of existing WM tracts. In this way, better initialization of the last layer than random initialization can be achieved for fine-tuning. Further, we show that a more adaptive use of the knowledge in the last layer for segmenting existing WM tracts can be conveniently achieved by simply inserting a warmup stage before classic fine-tuning. The proposed method was evaluated on a publicly available dMRI dataset, where we demonstrate the benefit of our method for few-shot segmentation of novel WM tracts.
Segmentation-based Method combined with Dynamic Programming for Brain Midline Delineation
Feb 27, 2020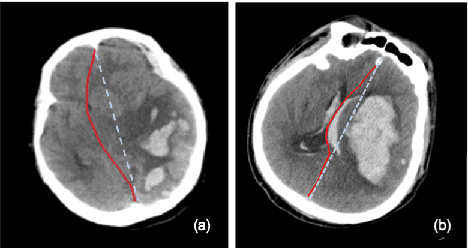

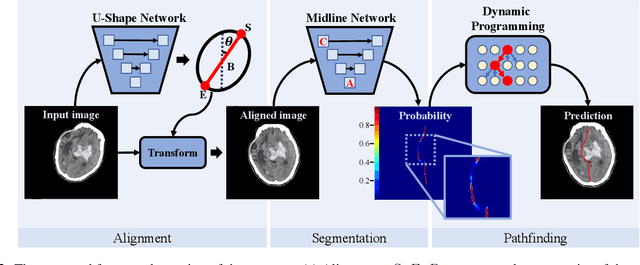
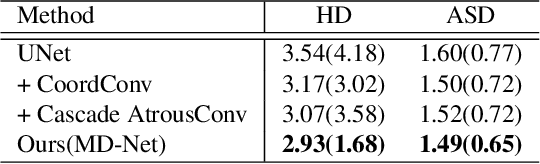
The midline related pathological image features are crucial for evaluating the severity of brain compression caused by stroke or traumatic brain injury (TBI). The automated midline delineation not only improves the assessment and clinical decision making for patients with stroke symptoms or head trauma but also reduces the time of diagnosis. Nevertheless, most of the previous methods model the midline by localizing the anatomical points, which are hard to detect or even missing in severe cases. In this paper, we formulate the brain midline delineation as a segmentation task and propose a three-stage framework. The proposed framework firstly aligns an input CT image into the standard space. Then, the aligned image is processed by a midline detection network (MD-Net) integrated with the CoordConv Layer and Cascade AtrousCconv Module to obtain the probability map. Finally, we formulate the optimal midline selection as a pathfinding problem to solve the problem of the discontinuity of midline delineation. Experimental results show that our proposed framework can achieve superior performance on one in-house dataset and one public dataset.
Knowledge Transfer between Datasets for Learning-based Tissue Microstructure Estimation
Oct 24, 2019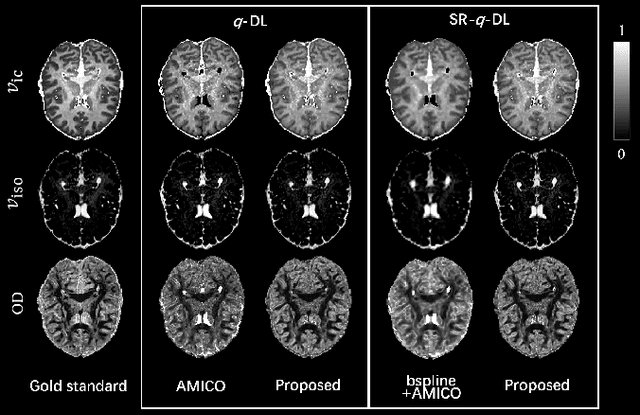
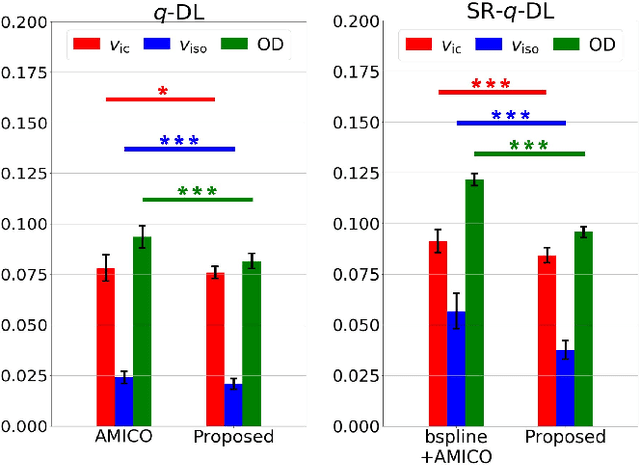
Learning-based approaches, especially those based on deep networks, have enabled high-quality estimation of tissue microstructure from low-quality diffusion magnetic resonance imaging (dMRI) scans, which are acquired with a limited number of diffusion gradients and a relatively poor spatial resolution. These learning-based approaches to tissue microstructure estimation require acquisitions of training dMRI scans with high-quality diffusion signals, which are densely sampled in the q-space and have a high spatial resolution. However, the acquisition of training scans may not be available for all datasets. Therefore, we explore knowledge transfer between different dMRI datasets so that learning-based tissue microstructure estimation can be applied for datasets where training scans are not acquired. Specifically, for a target dataset of interest, where only low-quality diffusion signals are acquired without training scans, we exploit the information in a source dMRI dataset acquired with high-quality diffusion signals. We interpolate the diffusion signals in the source dataset in the q-space using a dictionary-based signal representation, so that the interpolated signals match the acquisition scheme of the target dataset. Then, the interpolated signals are used together with the high-quality tissue microstructure computed from the source dataset to train deep networks that perform tissue microstructure estimation for the target dataset. Experiments were performed on brain dMRI scans with low-quality diffusion signals, where the benefit of the proposed strategy is demonstrated.
Semi-Supervised Brain Lesion Segmentation with an Adapted Mean Teacher Model
Mar 04, 2019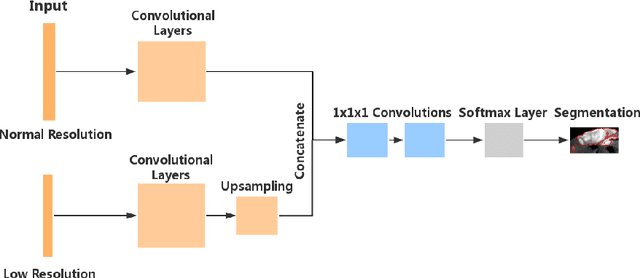
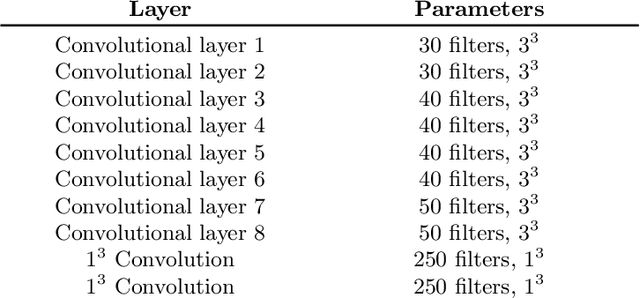
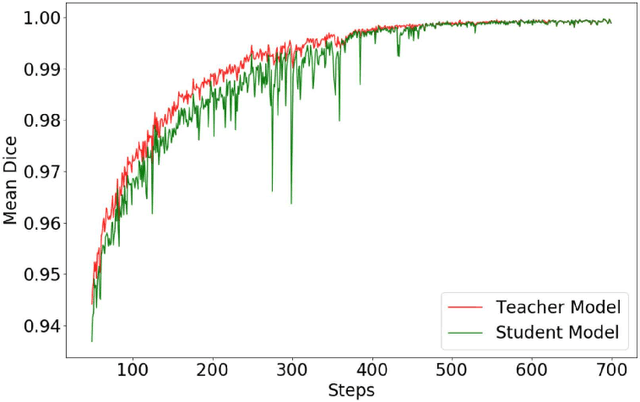

Automated brain lesion segmentation provides valuable information for the analysis and intervention of patients. In particular, methods based on convolutional neural networks (CNNs) have achieved state-of-the-art segmentation performance. However, CNNs usually require a decent amount of annotated data, which may be costly and time-consuming to obtain. Since unannotated data is generally abundant, it is desirable to use unannotated data to improve the segmentation performance for CNNs when limited annotated data is available. In this work, we propose a semi-supervised learning (SSL) approach to brain lesion segmentation, where unannotated data is incorporated into the training of CNNs. We adapt the mean teacher model, which is originally developed for SSL-based image classification, for brain lesion segmentation. Assuming that the network should produce consistent outputs for similar inputs, a loss of segmentation consistency is designed and integrated into a self-ensembling framework. Specifically, we build a student model and a teacher model, which share the same CNN architecture for segmentation. The student and teacher models are updated alternately. At each step, the student model learns from the teacher model by minimizing the weighted sum of the segmentation loss computed from annotated data and the segmentation consistency loss between the teacher and student models computed from unannotated data. Then, the teacher model is updated by combining the updated student model with the historical information of teacher models using an exponential moving average strategy. For demonstration, the proposed approach was evaluated on ischemic stroke lesion segmentation, where it improves stroke lesion segmentation with the incorporation of unannotated data.
Learning-based Ensemble Average Propagator Estimation
Jun 20, 2017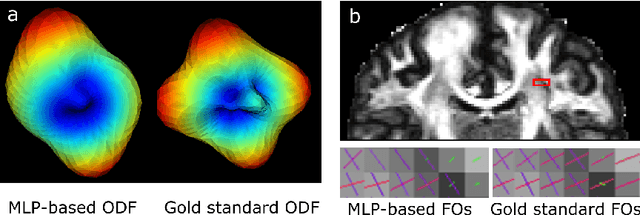
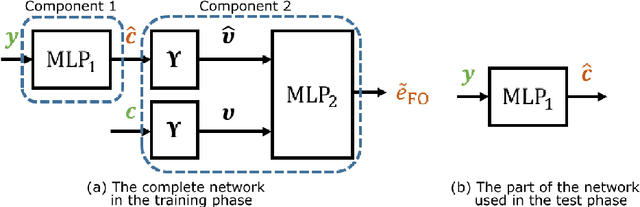
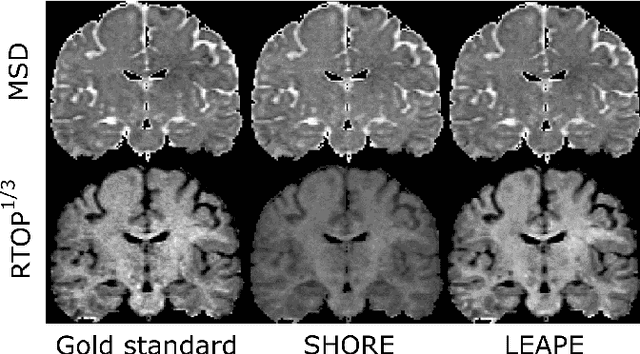
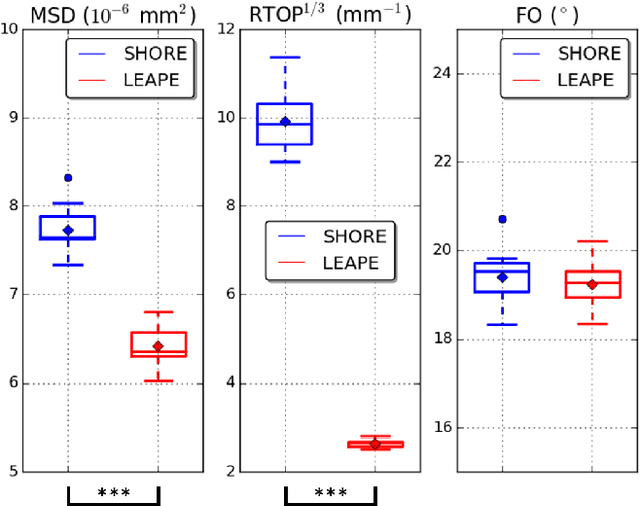
By capturing the anisotropic water diffusion in tissue, diffusion magnetic resonance imaging (dMRI) provides a unique tool for noninvasively probing the tissue microstructure and orientation in the human brain. The diffusion profile can be described by the ensemble average propagator (EAP), which is inferred from observed diffusion signals. However, accurate EAP estimation using the number of diffusion gradients that is clinically practical can be challenging. In this work, we propose a deep learning algorithm for EAP estimation, which is named learning-based ensemble average propagator estimation (LEAPE). The EAP is commonly represented by a basis and its associated coefficients, and here we choose the SHORE basis and design a deep network to estimate the coefficients. The network comprises two cascaded components. The first component is a multiple layer perceptron (MLP) that simultaneously predicts the unknown coefficients. However, typical training loss functions, such as mean squared errors, may not properly represent the geometry of the possibly non-Euclidean space of the coefficients, which in particular causes problems for the extraction of directional information from the EAP. Therefore, to regularize the training, in the second component we compute an auxiliary output of approximated fiber orientation (FO) errors with the aid of a second MLP that is trained separately. We performed experiments using dMRI data that resemble clinically achievable $q$-space sampling, and observed promising results compared with the conventional EAP estimation method.