 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration-Augmented Generation: A Plug-and-Play Framework for Private Knowledge Injection in Large Language Models
Jan 13, 2026In domains such as biomedicine, materials, and finance, high-stakes deployment of large language models (LLMs) requires injecting private, domain-specific knowledge that is proprietary, fast-evolving, and under-represented in public pretraining. However, the two dominant paradigms for private knowledge injection each have pronounced drawbacks: fine-tuning is expensive to iterate, and continual updates risk catastrophic forgetting and general-capability regression; retrieval-augmented generation (RAG) keeps the base model intact but is brittle in specialized private corpora due to chunk-induced evidence fragmentation, retrieval drift, and long-context pressure that yields query-dependent prompt inflation. Inspired by how multimodal LLMs align heterogeneous modalities into a shared semantic space, we propose Generation-Augmented Generation (GAG), which treats private expertise as an additional expert modality and injects it via a compact, representation-level interface aligned to the frozen base model, avoiding prompt-time evidence serialization while enabling plug-and-play specialization and scalable multi-domain composition with reliable selective activation. Across two private scientific QA benchmarks (immunology adjuvant and catalytic materials) and mixed-domain evaluations, GAG improves specialist performance over strong RAG baselines by 15.34% and 14.86% on the two benchmarks, respectively, while maintaining performance on six open general benchmarks and enabling near-oracle selective activation for scalable multi-domain deployment.
RzenEmbed: Towards Comprehensive Multimodal Retrieval
Oct 31, 2025The rapid advancement of Multimodal Large Language Models (MLLMs) has extended CLIP-based frameworks to produce powerful, universal embeddings for retrieval tasks. However, existing methods primarily focus on natural images, offering limited support for other crucial visual modalities such as videos and visual documents. To bridge this gap, we introduce RzenEmbed, a unified framework to learn embeddings across a diverse set of modalities, including text, images, videos, and visual documents. We employ a novel two-stage training strategy to learn discriminative representations. The first stage focuses on foundational text and multimodal retrieval. In the second stage, we introduce an improved InfoNCE loss, incorporating two key enhancements. Firstly, a hardness-weighted mechanism guides the model to prioritize challenging samples by assigning them higher weights within each batch. Secondly, we implement an approach to mitigate the impact of false negatives and alleviate data noise. This strategy not only enhances the model's discriminative power but also improves its instruction-following capabilities. We further boost performance with learnable temperature parameter and model souping. RzenEmbed sets a new state-of-the-art on the MMEB benchmark. It not only achieves the best overall score but also outperforms all prior work on the challenging video and visual document retrieval tasks. Our models are available in https://huggingface.co/qihoo360/RzenEmbed.
FG-CLIP: Fine-Grained Visual and Textual Alignment
May 08, 2025Contrastive Language-Image Pre-training (CLIP) excels in multimodal tasks such as image-text retrieval and zero-shot classification but struggles with fine-grained understanding due to its focus on coarse-grained short captions. To address this, we propose Fine-Grained CLIP (FG-CLIP), which enhances fine-grained understanding through three key innovations. First, we leverage large multimodal models to generate 1.6 billion long caption-image pairs for capturing global-level semantic details. Second, a high-quality dataset is constructed with 12 million images and 40 million region-specific bounding boxes aligned with detailed captions to ensure precise, context-rich representations. Third, 10 million hard fine-grained negative samples are incorporated to improve the model's ability to distinguish subtle semantic differences. Corresponding training methods are meticulously designed for these data. Extensive experiments demonstrate that FG-CLIP outperforms the original CLIP and other state-of-the-art methods across various downstream tasks, including fine-grained understanding, open-vocabulary object detection, image-text retrieval, and general multimodal benchmarks. These results highlight FG-CLIP's effectiveness in capturing fine-grained image details and improving overall model performance. The related data, code, and models are available at https://github.com/360CVGroup/FG-CLIP.
Prompt as Knowledge Bank: Boost Vision-language model via Structural Representation for zero-shot medical detection
Feb 22, 2025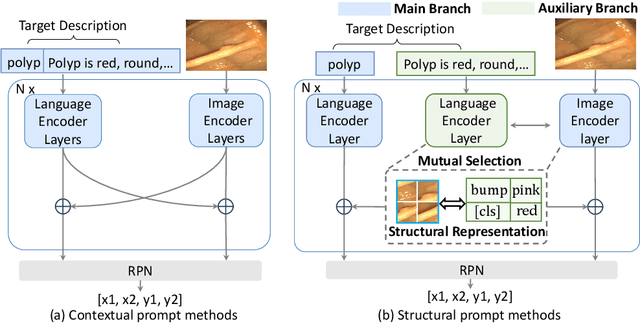
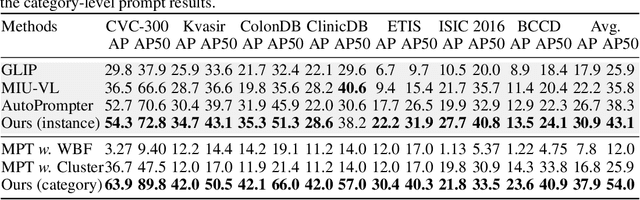
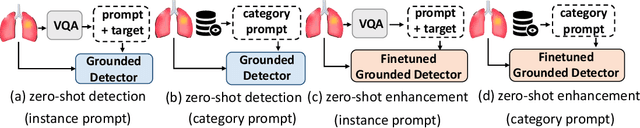
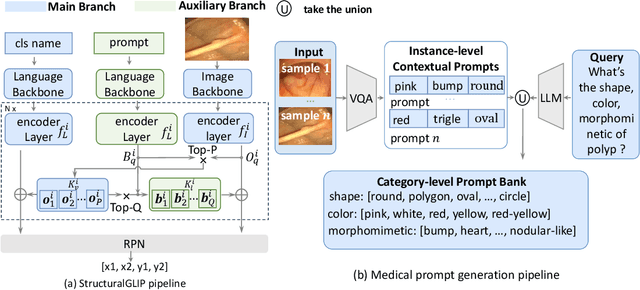
Zero-shot medical detection can further improve detection performance without relying on annotated medical images even upon the fine-tuned model, showing great clinical value. Recent studies leverage grounded vision-language models (GLIP) to achieve this by using detailed disease descriptions as prompts for the target disease name during the inference phase. However, these methods typically treat prompts as equivalent context to the target name, making it difficult to assign specific disease knowledge based on visual information, leading to a coarse alignment between images and target descriptions. In this paper, we propose StructuralGLIP, which introduces an auxiliary branch to encode prompts into a latent knowledge bank layer-by-layer, enabling more context-aware and fine-grained alignment. Specifically, in each layer, we select highly similar features from both the image representation and the knowledge bank, forming structural representations that capture nuanced relationships between image patches and target descriptions. These features are then fused across modalities to further enhance detection performance. Extensive experiments demonstrate that StructuralGLIP achieves a +4.1\% AP improvement over prior state-of-the-art methods across seven zero-shot medical detection benchmarks, and consistently improves fine-tuned models by +3.2\% AP on endoscopy image datasets.
IAA: Inner-Adaptor Architecture Empowers Frozen Large Language Model with Multimodal Capabilities
Aug 23, 2024



In the field of multimodal large language models (MLLMs), common methods typically involve unfreezing the language model during training to foster profound visual understanding. However, the fine-tuning of such models with vision-language data often leads to a diminution of their natural language processing (NLP) capabilities. To avoid this performance degradation, a straightforward solution is to freeze the language model while developing multimodal competencies. Unfortunately, previous works have not attained satisfactory outcomes. Building on the strategy of freezing the language model, we conduct thorough structural exploration and introduce the Inner-Adaptor Architecture (IAA). Specifically, the architecture incorporates multiple multimodal adaptors at varying depths within the large language model to facilitate direct interaction with the inherently text-oriented transformer layers, thereby enabling the frozen language model to acquire multimodal capabilities. Unlike previous approaches of freezing language models that require large-scale aligned data, our proposed architecture is able to achieve superior performance on small-scale datasets. We conduct extensive experiments to improve the general multimodal capabilities and visual grounding abilities of the MLLM. Our approach remarkably outperforms previous state-of-the-art methods across various vision-language benchmarks without sacrificing performance on NLP tasks. Code and models are available at https://github.com/360CVGroup/Inner-Adaptor-Architecture.
What Makes Good Open-Vocabulary Detector: A Disassembling Perspective
Sep 01, 2023



Open-vocabulary detection (OVD) is a new object detection paradigm, aiming to localize and recognize unseen objects defined by an unbounded vocabulary. This is challenging since traditional detectors can only learn from pre-defined categories and thus fail to detect and localize objects out of pre-defined vocabulary. To handle the challenge, OVD leverages pre-trained cross-modal VLM, such as CLIP, ALIGN, etc. Previous works mainly focus on the open vocabulary classification part, with less attention on the localization part. We argue that for a good OVD detector, both classification and localization should be parallelly studied for the novel object categories. We show in this work that improving localization as well as cross-modal classification complement each other, and compose a good OVD detector jointly. We analyze three families of OVD methods with different design emphases. We first propose a vanilla method,i.e., cropping a bounding box obtained by a localizer and resizing it into the CLIP. We next introduce another approach, which combines a standard two-stage object detector with CLIP. A two-stage object detector includes a visual backbone, a region proposal network (RPN), and a region of interest (RoI) head. We decouple RPN and ROI head (DRR) and use RoIAlign to extract meaningful features. In this case, it avoids resizing objects. To further accelerate the training time and reduce the model parameters, we couple RPN and ROI head (CRR) as the third approach. We conduct extensive experiments on these three types of approaches in different settings. On the OVD-COCO benchmark, DRR obtains the best performance and achieves 35.8 Novel AP$_{50}$, an absolute 2.8 gain over the previous state-of-the-art (SOTA). For OVD-LVIS, DRR surpasses the previous SOTA by 1.9 AP$_{50}$ in rare categories. We also provide an object detection dataset called PID and provide a baseline on PID.
Disjoint Masking with Joint Distillation for Efficient Masked Image Modeling
Dec 31, 2022



Masked image modeling (MIM) has shown great promise for self-supervised learning (SSL) yet been criticized for learning inefficiency. We believe the insufficient utilization of training signals should be responsible. To alleviate this issue, we introduce a conceptually simple yet learning-efficient MIM training scheme, termed Disjoint Masking with Joint Distillation (DMJD). For disjoint masking (DM), we sequentially sample multiple masked views per image in a mini-batch with the disjoint regulation to raise the usage of tokens for reconstruction in each image while keeping the masking rate of each view. For joint distillation (JD), we adopt a dual branch architecture to respectively predict invisible (masked) and visible (unmasked) tokens with superior learning targets. Rooting in orthogonal perspectives for training efficiency improvement, DM and JD cooperatively accelerate the training convergence yet not sacrificing the model generalization ability. Concretely, DM can train ViT with half of the effective training epochs (3.7 times less time-consuming) to report competitive performance. With JD, our DMJD clearly improves the linear probing classification accuracy over ConvMAE by 5.8%. On fine-grained downstream tasks like semantic segmentation, object detection, etc., our DMJD also presents superior generalization compared with state-of-the-art SSL methods. The code and model will be made public at https://github.com/mx-mark/DMJD.
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
May 08, 2022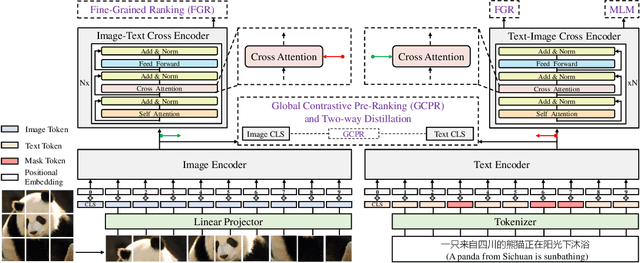
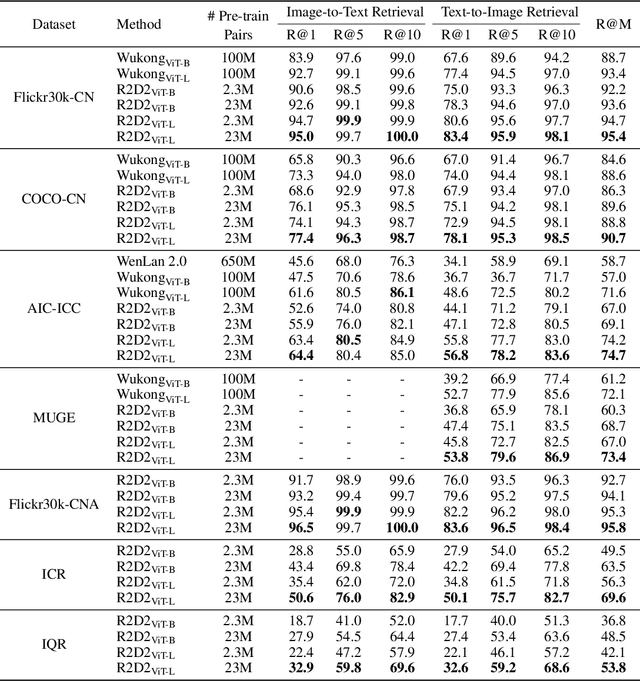

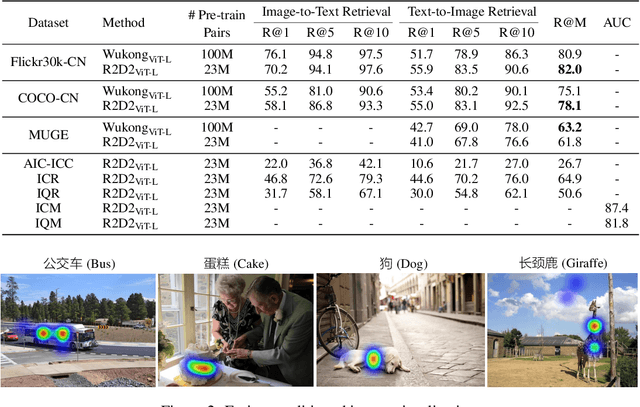
Vision-language pre-training (VLP) relying on large-scale pre-training datasets has shown premier performance on various downstream tasks. In this sense, a complete and fair benchmark (i.e., including large-scale pre-training datasets and a variety of downstream datasets) is essential for VLP. But how to construct such a benchmark in Chinese remains a critical problem. To this end, we develop a large-scale Chinese cross-modal benchmark called Zero for AI researchers to fairly compare VLP models. We release two pre-training datasets and five fine-tuning datasets for downstream tasks. Furthermore, we propose a novel pre-training framework of pre-Ranking + Ranking for cross-modal learning. Specifically, we apply global contrastive pre-ranking to learn the individual representations of images and Chinese texts, respectively. We then fuse the representations in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. To further enhance the capability of the model, we propose a two-way distillation strategy consisting of target-guided Distillation and feature-guided Distillation. For simplicity, we call our model R2D2. We achieve state-of-the-art performance on four public cross-modal datasets and our five downstream datasets. The datasets, models and codes will be made available.
Memory Attention Networks for Skeleton-based Action Recognition
May 03, 2018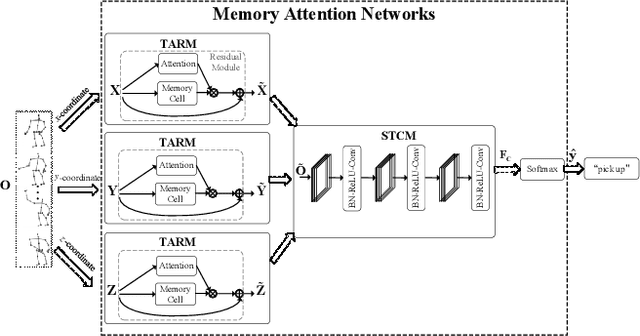
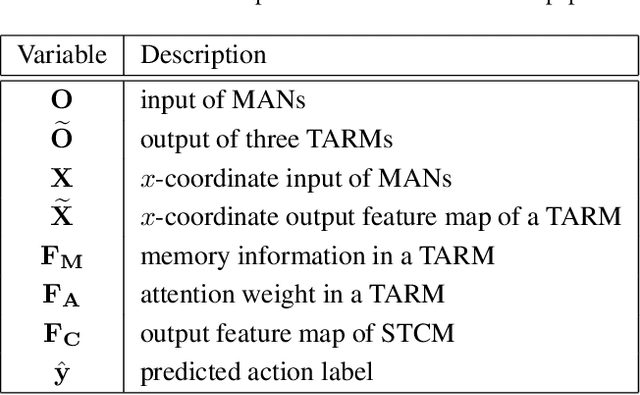
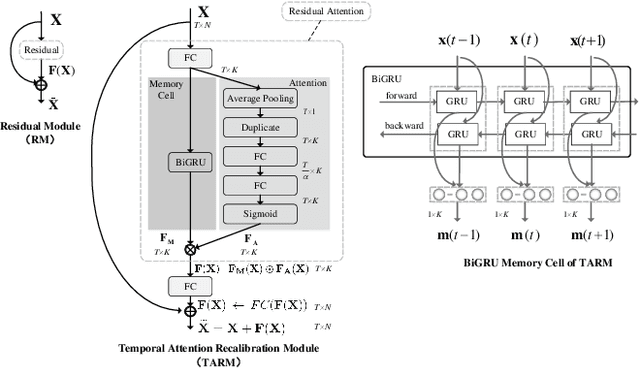
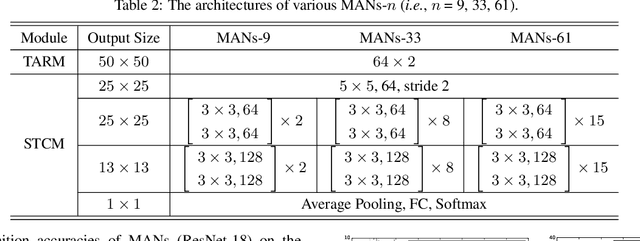
Skeleton-based action recognition task is entangled with complex spatio-temporal variations of skeleton joints, and remains challenging for Recurrent Neural Networks (RNNs). In this work, we propose a temporal-then-spatial recalibration scheme to alleviate such complex variations, resulting in an end-to-end Memory Attention Networks (MANs) which consist of a Temporal Attention Recalibration Module (TARM) and a Spatio-Temporal Convolution Module (STCM). Specifically, the TARM is deployed in a residual learning module that employs a novel attention learning network to recalibrate the temporal attention of frames in a skeleton sequence. The STCM treats the attention calibrated skeleton joint sequences as images and leverages the Convolution Neural Networks (CNNs) to further model the spatial and temporal information of skeleton data. These two modules (TARM and STCM) seamlessly form a single network architecture that can be trained in an end-to-end fashion. MANs significantly boost the performance of skeleton-based action recognition and achieve the best results on four challenging benchmark datasets: NTU RGB+D, HDM05, SYSU-3D and UT-Kinect.
Deep Fisher Discriminant Learning for Mobile Hand Gesture Recognition
Jul 12, 2017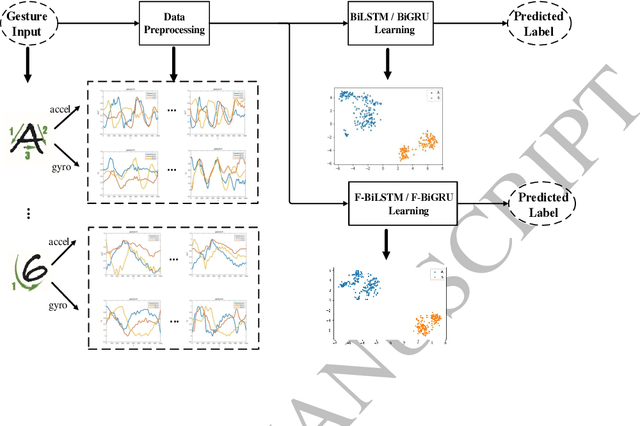
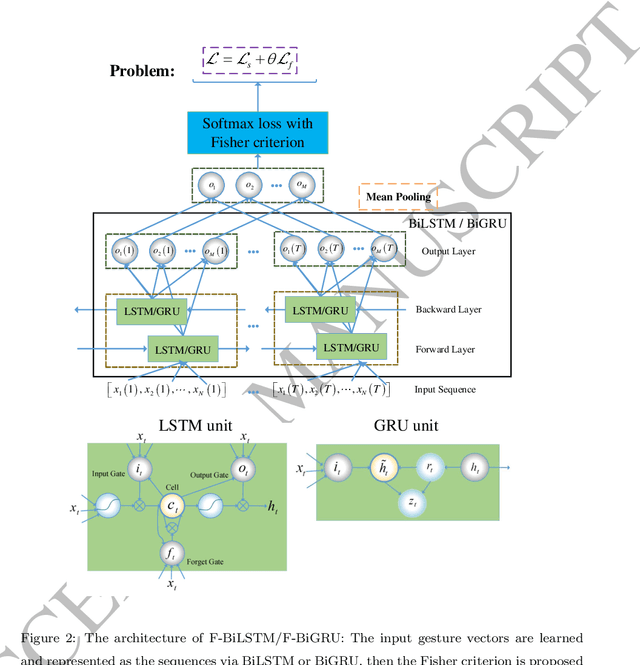

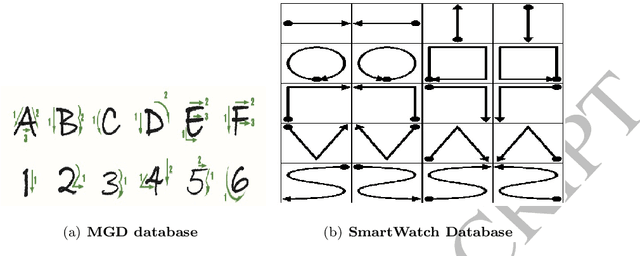
Gesture recognition is a challenging problem in the field of biometrics. In this paper, we integrate Fisher criterion into Bidirectional Long-Short Term Memory (BLSTM) network and Bidirectional Gated Recurrent Unit (BGRU),thus leading to two new deep models termed as F-BLSTM and F-BGRU. BothFisher discriminative deep models can effectively classify the gesture based on analyzing the acceleration and angular velocity data of the human gestures. Moreover, we collect a large Mobile Gesture Database (MGD) based on the accelerations and angular velocities containing 5547 sequences of 12 gestures. Extensive experiments are conducted to validate the superior performance of the proposed networks as compared to the state-of-the-art BLSTM and BGRU on MGD database and two benchmark databases (i.e. BUAA mobile gesture and SmartWatch gesture).