 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDamageArbiter: A CLIP-Enhanced Multimodal Arbitration Framework for Hurricane Damage Assessment from Street-View Imagery
Mar 16, 2026Analyzing street-view imagery with computer vision models for rapid, hyperlocal damage assessment is becoming popular and valuable in emergency response and recovery, but traditional models often act like black boxes, lacking interpretability and reliability. This study proposes a multimodal disagreement-driven Arbitration framework powered by Contrastive Language-Image Pre-training (CLIP) models, DamageArbiter, to improve the accuracy, interpretability, and robustness of damage estimation from street-view imagery. DamageArbiter leverages the complementary strengths of unimodal and multimodal models, employing a lightweight logistic regression meta-classifier to arbitrate cases of disagreement. Using 2,556 post-disaster street-view images, paired with both manually generated and large language model (LLM)-generated text descriptions, we systematically compared the performance of unimodal models (including image-only and text-only models), multimodal CLIP-based models, and DamageArbiter. Notably, DamageArbiter improved the accuracy from 74.33% (ViT-B/32, image-only) to 82.79%, surpassing the 80% accuracy threshold and achieving an absolute improvement of 8.46% compared to the strongest baseline model. Beyond improvements in overall accuracy, compared to visual models relying solely on images, DamageArbiter, through arbitration of discrepancies between unimodal and multimodal predictions, mitigates common overconfidence errors in visual models, especially in situations where disaster visual cues are ambiguous or subject to interference, reducing overconfidence but incorrect predictions. We further mapped and analyzed geo-referenced predictions and misclassifications to compare model performance across locations. Overall, this work advances street-view-based disaster assessment from coarse severity classification toward a more reliable and interpretable framework.
Predicting Healthcare System Visitation Flow by Integrating Hospital Attributes and Population Socioeconomics with Human Mobility Data
Jan 22, 2026Healthcare visitation patterns are influenced by a complex interplay of hospital attributes, population socioeconomics, and spatial factors. However, existing research often adopts a fragmented approach, examining these determinants in isolation. This study addresses this gap by integrating hospital capacities, occupancy rates, reputation, and popularity with population SES and spatial mobility patterns to predict visitation flows and analyze influencing factors. Utilizing four years of SafeGraph mobility data and user experience data from Google Maps Reviews, five flow prediction models, Naive Regression, Gradient Boosting, Multilayer Perceptrons (MLPs), Deep Gravity, and Heterogeneous Graph Neural Networks (HGNN),were trained and applied to simulate visitation flows in Houston, Texas, U.S. The Shapley additive explanation (SHAP) analysis and the Partial Dependence Plot (PDP) method were employed to examine the combined impacts of different factors on visitation patterns. The findings reveal that Deep Gravity outperformed other models. Hospital capacities, ICU occupancy rates, ratings, and popularity significantly influence visitation patterns, with their effects varying across different travel distances. Short-distance visits are primarily driven by convenience, whereas long-distance visits are influenced by hospital ratings. White-majority areas exhibited lower sensitivity to hospital ratings for short-distance visits, while Asian populations and those with higher education levels prioritized hospital rating in their visitation decisions. SES further influence these patterns, as areas with higher proportions of Hispanic, Black, under-18, and over-65 populations tend to have more frequent hospital visits, potentially reflecting greater healthcare needs or limited access to alternative medical services.
Toward building next-generation Geocoding systems: a systematic review
Mar 24, 2025



Geocoding systems are widely used in both scientific research for spatial analysis and everyday life through location-based services. The quality of geocoded data significantly impacts subsequent processes and applications, underscoring the need for next-generation systems. In response to this demand, this review first examines the evolving requirements for geocoding inputs and outputs across various scenarios these systems must address. It then provides a detailed analysis of how to construct such systems by breaking them down into key functional components and reviewing a broad spectrum of existing approaches, from traditional rule-based methods to advanced techniques in information retrieval, natural language processing, and large language models. Finally, we identify opportunities to improve next-generation geocoding systems in light of recent technological advances.
3D Medical Image Segmentation with Sparse Annotation via Cross-Teaching between 3D and 2D Networks
Jul 30, 2023



Medical image segmentation typically necessitates a large and precisely annotated dataset. However, obtaining pixel-wise annotation is a labor-intensive task that requires significant effort from domain experts, making it challenging to obtain in practical clinical scenarios. In such situations, reducing the amount of annotation required is a more practical approach. One feasible direction is sparse annotation, which involves annotating only a few slices, and has several advantages over traditional weak annotation methods such as bounding boxes and scribbles, as it preserves exact boundaries. However, learning from sparse annotation is challenging due to the scarcity of supervision signals. To address this issue, we propose a framework that can robustly learn from sparse annotation using the cross-teaching of both 3D and 2D networks. Considering the characteristic of these networks, we develop two pseudo label selection strategies, which are hard-soft confidence threshold and consistent label fusion. Our experimental results on the MMWHS dataset demonstrate that our method outperforms the state-of-the-art (SOTA) semi-supervised segmentation methods. Moreover, our approach achieves results that are comparable to the fully-supervised upper bound result.
Orthogonal Annotation Benefits Barely-supervised Medical Image Segmentation
Mar 23, 2023



Recent trends in semi-supervised learning have significantly boosted the performance of 3D semi-supervised medical image segmentation. Compared with 2D images, 3D medical volumes involve information from different directions, e.g., transverse, sagittal, and coronal planes, so as to naturally provide complementary views. These complementary views and the intrinsic similarity among adjacent 3D slices inspire us to develop a novel annotation way and its corresponding semi-supervised model for effective segmentation. Specifically, we firstly propose the orthogonal annotation by only labeling two orthogonal slices in a labeled volume, which significantly relieves the burden of annotation. Then, we perform registration to obtain the initial pseudo labels for sparsely labeled volumes. Subsequently, by introducing unlabeled volumes, we propose a dual-network paradigm named Dense-Sparse Co-training (DeSCO) that exploits dense pseudo labels in early stage and sparse labels in later stage and meanwhile forces consistent output of two networks. Experimental results on three benchmark datasets validated our effectiveness in performance and efficiency in annotation. For example, with only 10 annotated slices, our method reaches a Dice up to 86.93% on KiTS19 dataset.
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
May 08, 2022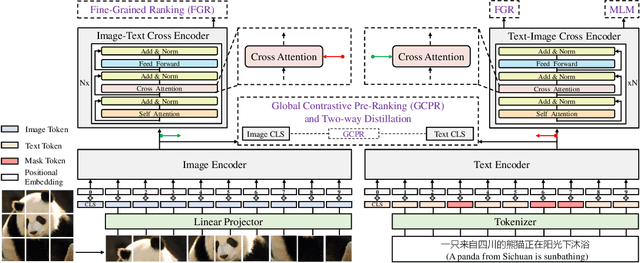
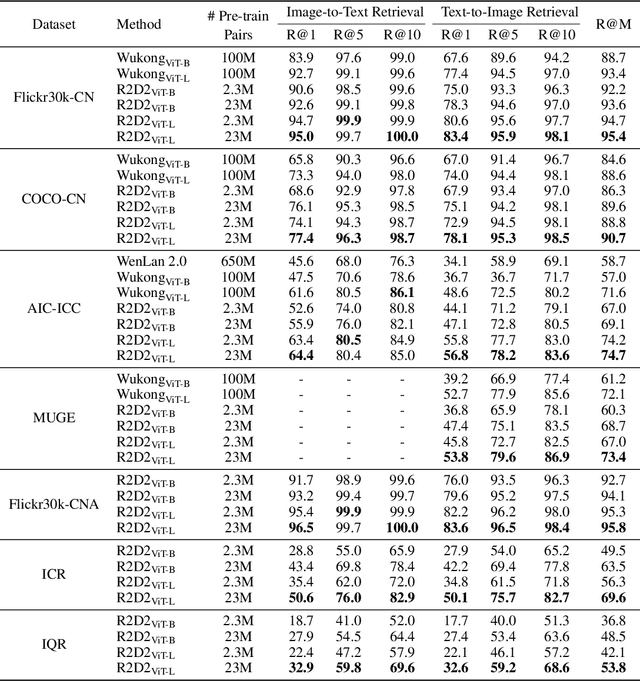

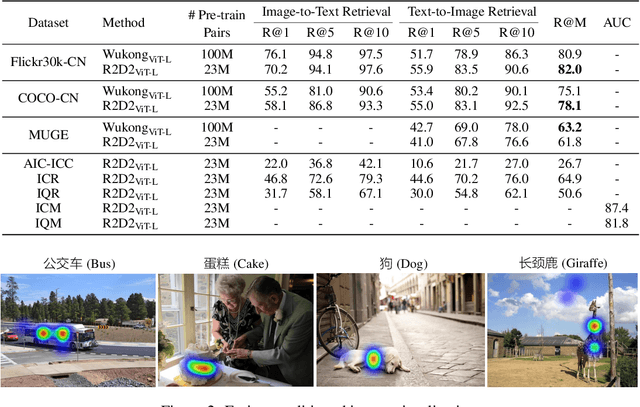
Vision-language pre-training (VLP) relying on large-scale pre-training datasets has shown premier performance on various downstream tasks. In this sense, a complete and fair benchmark (i.e., including large-scale pre-training datasets and a variety of downstream datasets) is essential for VLP. But how to construct such a benchmark in Chinese remains a critical problem. To this end, we develop a large-scale Chinese cross-modal benchmark called Zero for AI researchers to fairly compare VLP models. We release two pre-training datasets and five fine-tuning datasets for downstream tasks. Furthermore, we propose a novel pre-training framework of pre-Ranking + Ranking for cross-modal learning. Specifically, we apply global contrastive pre-ranking to learn the individual representations of images and Chinese texts, respectively. We then fuse the representations in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. To further enhance the capability of the model, we propose a two-way distillation strategy consisting of target-guided Distillation and feature-guided Distillation. For simplicity, we call our model R2D2. We achieve state-of-the-art performance on four public cross-modal datasets and our five downstream datasets. The datasets, models and codes will be made available.