 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRzenEmbed: Towards Comprehensive Multimodal Retrieval
Oct 31, 2025The rapid advancement of Multimodal Large Language Models (MLLMs) has extended CLIP-based frameworks to produce powerful, universal embeddings for retrieval tasks. However, existing methods primarily focus on natural images, offering limited support for other crucial visual modalities such as videos and visual documents. To bridge this gap, we introduce RzenEmbed, a unified framework to learn embeddings across a diverse set of modalities, including text, images, videos, and visual documents. We employ a novel two-stage training strategy to learn discriminative representations. The first stage focuses on foundational text and multimodal retrieval. In the second stage, we introduce an improved InfoNCE loss, incorporating two key enhancements. Firstly, a hardness-weighted mechanism guides the model to prioritize challenging samples by assigning them higher weights within each batch. Secondly, we implement an approach to mitigate the impact of false negatives and alleviate data noise. This strategy not only enhances the model's discriminative power but also improves its instruction-following capabilities. We further boost performance with learnable temperature parameter and model souping. RzenEmbed sets a new state-of-the-art on the MMEB benchmark. It not only achieves the best overall score but also outperforms all prior work on the challenging video and visual document retrieval tasks. Our models are available in https://huggingface.co/qihoo360/RzenEmbed.
Deform-GAN:An Unsupervised Learning Model for Deformable Registration
Feb 26, 2020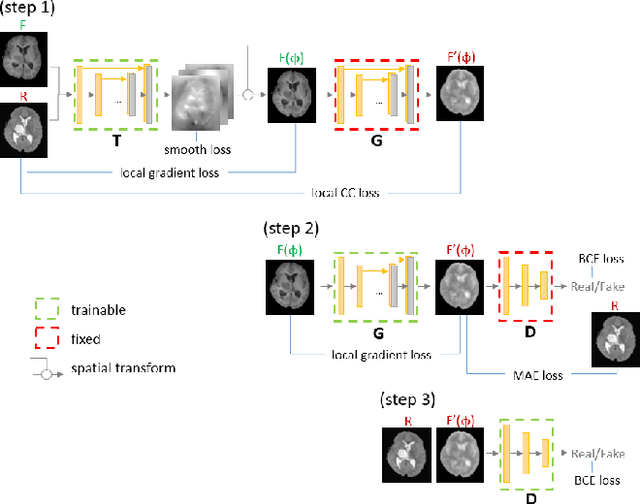
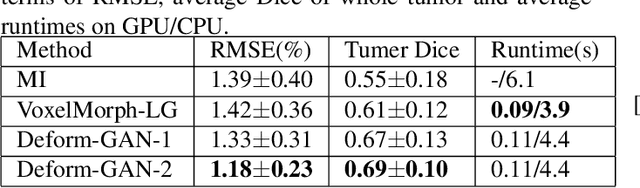
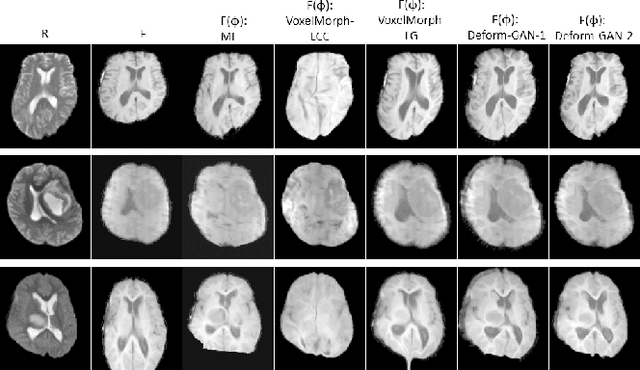
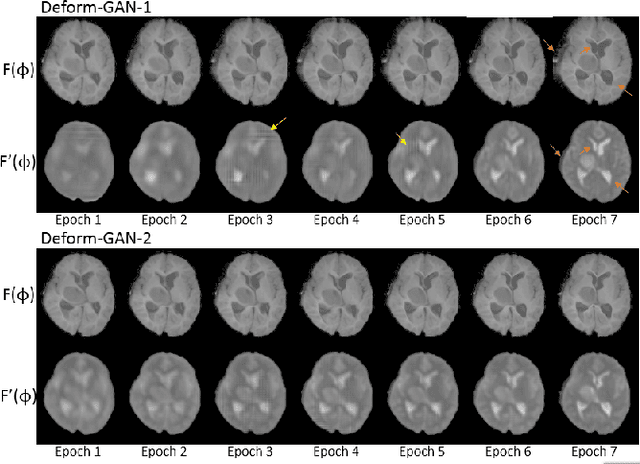
Deformable registration is one of the most challenging task in the field of medical image analysis, especially for the alignment between different sequences and modalities. In this paper, a non-rigid registration method is proposed for 3D medical images leveraging unsupervised learning. To the best of our knowledge, this is the first attempt to introduce gradient loss into deep-learning-based registration. The proposed gradient loss is robust across sequences and modals for large deformation. Besides, adversarial learning approach is used to transfer multi-modal similarity to mono-modal similarity and improve the precision. Neither ground-truth nor manual labeling is required during training. We evaluated our network on a 3D brain registration task comprehensively. The experiments demonstrate that the proposed method can cope with the data which has non-functional intensity relations, noise and blur. Our approach outperforms other methods especially in accuracy and speed.