 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Stack Filters to Build Minimum Viable CNNs
Aug 06, 2019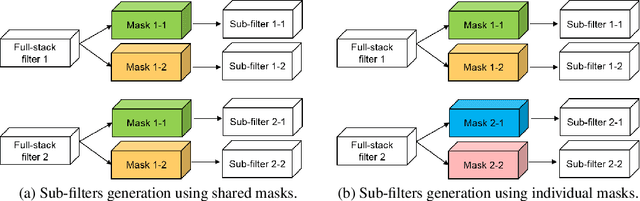
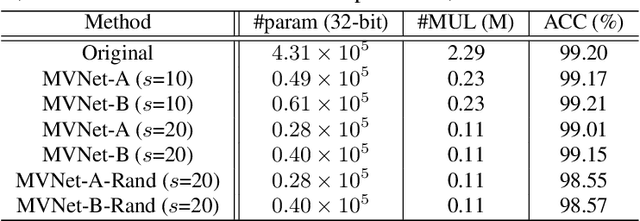
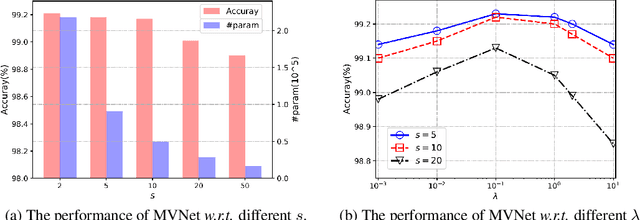
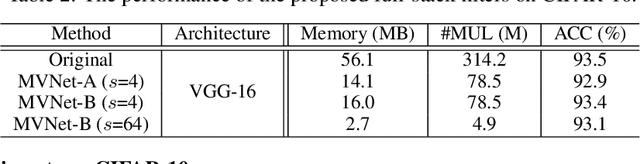
Deep convolutional neural networks (CNNs) are usually over-parameterized, which cannot be easily deployed on edge devices such as mobile phones and smart cameras. Existing works used to decrease the number or size of requested convolution filters for a minimum viable CNN on edge devices. In contrast, this paper introduces filters that are full-stack and can be used to generate many more sub-filters. Weights of these sub-filters are inherited from full-stack filters with the help of different binary masks. Orthogonal constraints are applied over binary masks to decrease their correlation and promote the diversity of generated sub-filters. To preserve the same volume of output feature maps, we can naturally reduce the number of established filters by only maintaining a few full-stack filters and a set of binary masks. We also conduct theoretical analysis on the memory cost and an efficient implementation is introduced for the convolution of the proposed filters. Experiments on several benchmark datasets and CNN models demonstrate that the proposed method is able to construct minimum viable convolution networks of comparable performance.
Learning Instance-wise Sparsity for Accelerating Deep Models
Jul 27, 2019
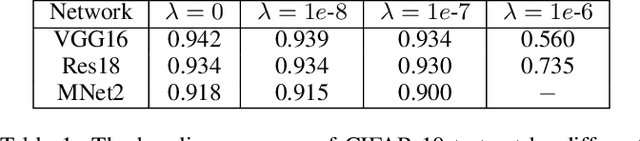
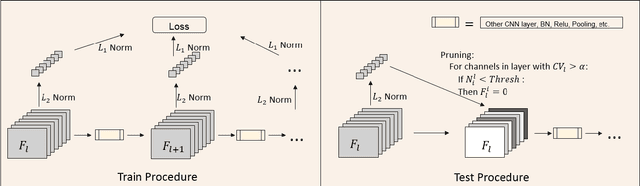
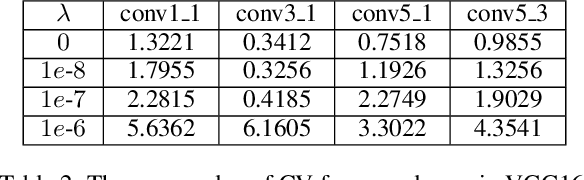
Exploring deep convolutional neural networks of high efficiency and low memory usage is very essential for a wide variety of machine learning tasks. Most of existing approaches used to accelerate deep models by manipulating parameters or filters without data, e.g., pruning and decomposition. In contrast, we study this problem from a different perspective by respecting the difference between data. An instance-wise feature pruning is developed by identifying informative features for different instances. Specifically, by investigating a feature decay regularization, we expect intermediate feature maps of each instance in deep neural networks to be sparse while preserving the overall network performance. During online inference, subtle features of input images extracted by intermediate layers of a well-trained neural network can be eliminated to accelerate the subsequent calculations. We further take coefficient of variation as a measure to select the layers that are appropriate for acceleration. Extensive experiments conducted on benchmark datasets and networks demonstrate the effectiveness of the proposed method.
Attribute Aware Pooling for Pedestrian Attribute Recognition
Jul 27, 2019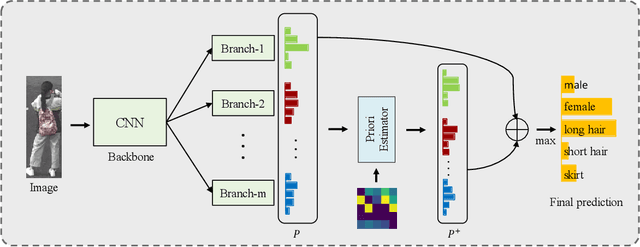
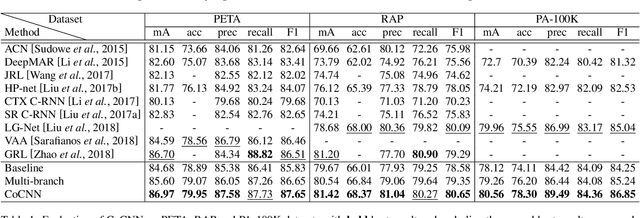
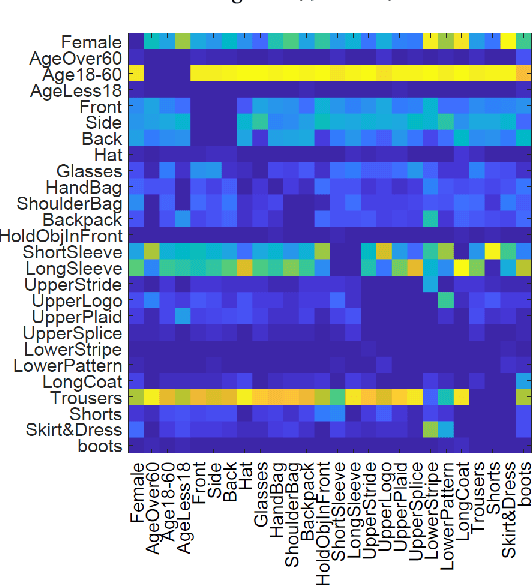
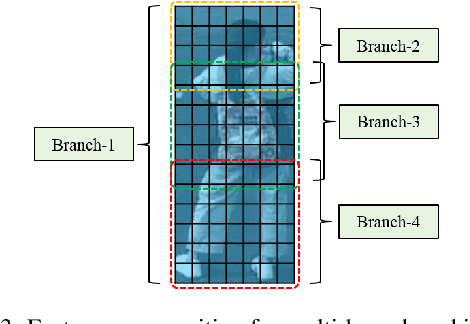
This paper expands the strength of deep convolutional neural networks (CNNs) to the pedestrian attribute recognition problem by devising a novel attribute aware pooling algorithm. Existing vanilla CNNs cannot be straightforwardly applied to handle multi-attribute data because of the larger label space as well as the attribute entanglement and correlations. We tackle these challenges that hampers the development of CNNs for multi-attribute classification by fully exploiting the correlation between different attributes. The multi-branch architecture is adopted for fucusing on attributes at different regions. Besides the prediction based on each branch itself, context information of each branch are employed for decision as well. The attribute aware pooling is developed to integrate both kinds of information. Therefore, attributes which are indistinct or tangled with others can be accurately recognized by exploiting the context information. Experiments on benchmark datasets demonstrate that the proposed pooling method appropriately explores and exploits the correlations between attributes for the pedestrian attribute recognition.
Co-Evolutionary Compression for Unpaired Image Translation
Jul 25, 2019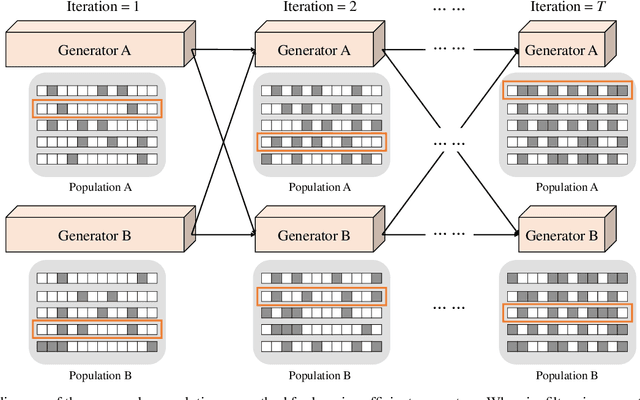
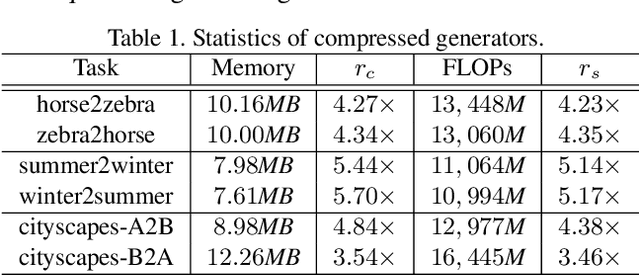

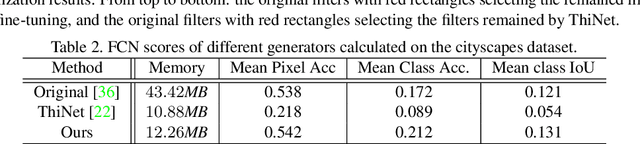
Generative adversarial networks (GANs) have been successfully used for considerable computer vision tasks, especially the image-to-image translation. However, generators in these networks are of complicated architectures with large number of parameters and huge computational complexities. Existing methods are mainly designed for compressing and speeding-up deep neural networks in the classification task, and cannot be directly applied on GANs for image translation, due to their different objectives and training procedures. To this end, we develop a novel co-evolutionary approach for reducing their memory usage and FLOPs simultaneously. In practice, generators for two image domains are encoded as two populations and synergistically optimized for investigating the most important convolution filters iteratively. Fitness of each individual is calculated using the number of parameters, a discriminator-aware regularization, and the cycle consistency. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of the proposed method for obtaining compact and effective generators.
Deep Fitting Degree Scoring Network for Monocular 3D Object Detection
Apr 26, 2019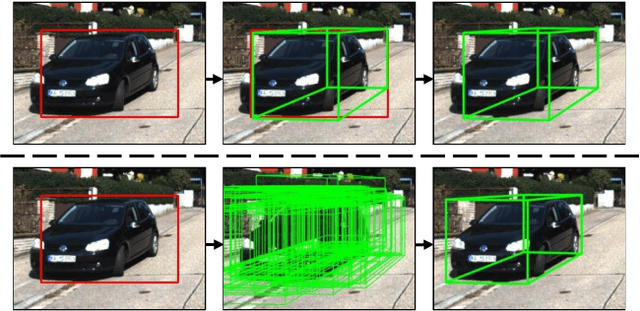
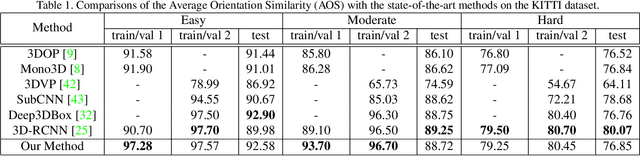
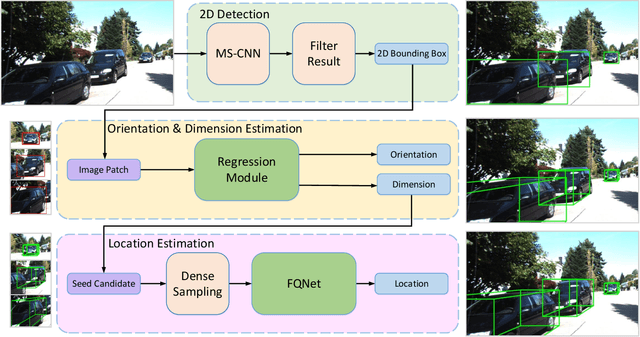
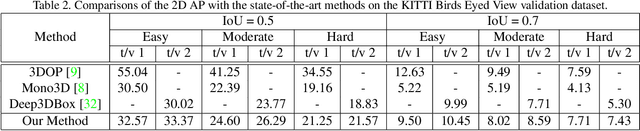
In this paper, we propose to learn a deep fitting degree scoring network for monocular 3D object detection, which aims to score fitting degree between proposals and object conclusively. Different from most existing monocular frameworks which use tight constraint to get 3D location, our approach achieves high-precision localization through measuring the visual fitting degree between the projected 3D proposals and the object. We first regress the dimension and orientation of the object using an anchor-based method so that a suitable 3D proposal can be constructed. We propose FQNet, which can infer the 3D IoU between the 3D proposals and the object solely based on 2D cues. Therefore, during the detection process, we sample a large number of candidates in the 3D space and project these 3D bounding boxes on 2D image individually. The best candidate can be picked out by simply exploring the spatial overlap between proposals and the object, in the form of the output 3D IoU score of FQNet. Experiments on the KITTI dataset demonstrate the effectiveness of our framework.
BridgeNet: A Continuity-Aware Probabilistic Network for Age Estimation
Apr 06, 2019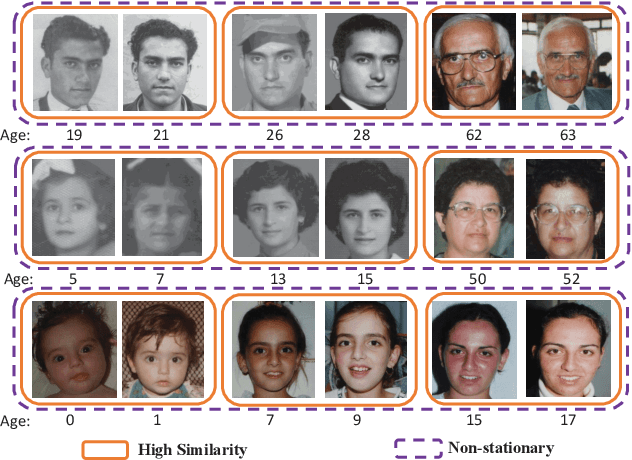
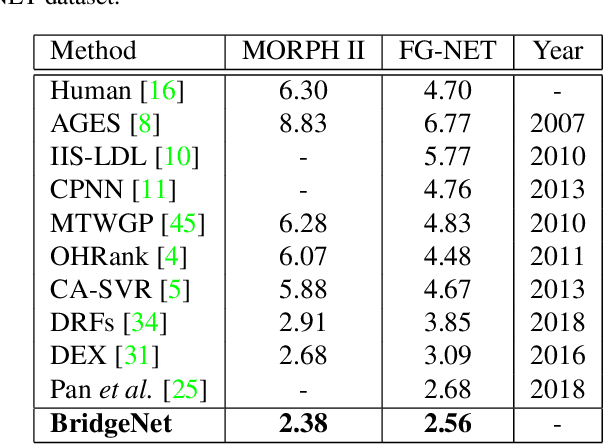
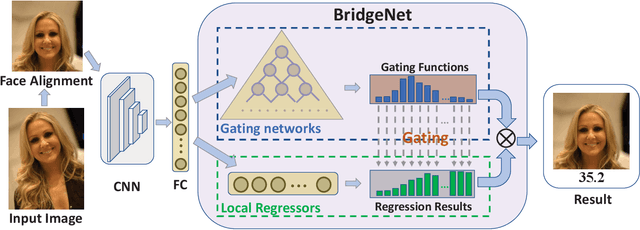
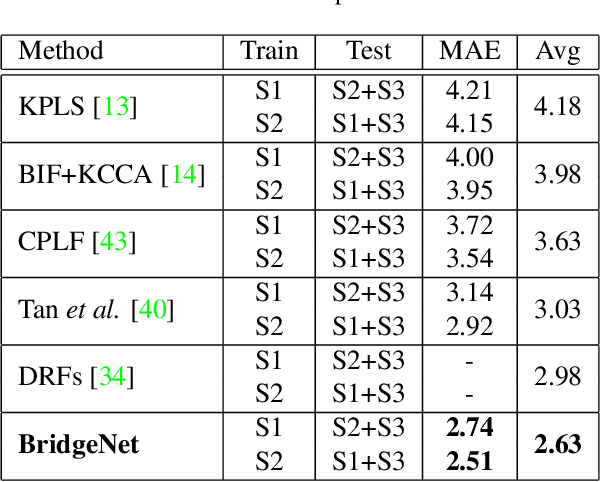
Age estimation is an important yet very challenging problem in computer vision. Existing methods for age estimation usually apply a divide-and-conquer strategy to deal with heterogeneous data caused by the non-stationary aging process. However, the facial aging process is also a continuous process, and the continuity relationship between different components has not been effectively exploited. In this paper, we propose BridgeNet for age estimation, which aims to mine the continuous relation between age labels effectively. The proposed BridgeNet consists of local regressors and gating networks. Local regressors partition the data space into multiple overlapping subspaces to tackle heterogeneous data and gating networks learn continuity aware weights for the results of local regressors by employing the proposed bridge-tree structure, which introduces bridge connections into tree models to enforce the similarity between neighbor nodes. Moreover, these two components of BridgeNet can be jointly learned in an end-to-end way. We show experimental results on the MORPH II, FG-NET and Chalearn LAP 2015 datasets and find that BridgeNet outperforms the state-of-the-art methods.
Data-Free Learning of Student Networks
Apr 02, 2019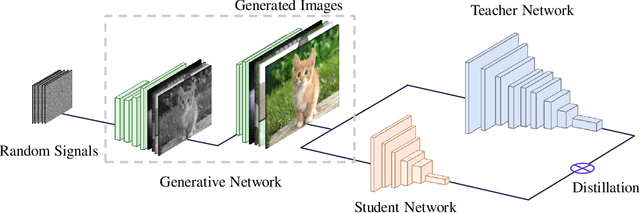
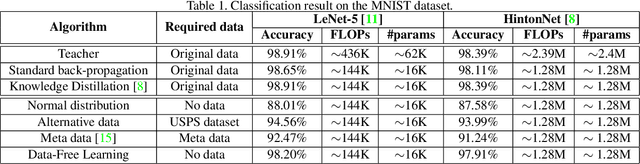

Learning portable neural networks is very essential for computer vision for the purpose that pre-trained heavy deep models can be well applied on edge devices such as mobile phones and micro sensors. Most existing deep neural network compression and speed-up methods are very effective for training compact deep models, when we can directly access the training dataset. However, training data for the given deep network are often unavailable due to some practice problems (e.g. privacy, legal issue, and transmission), and the architecture of the given network are also unknown except some interfaces. To this end, we propose a novel framework for training efficient deep neural networks by exploiting generative adversarial networks (GANs). To be specific, the pre-trained teacher networks are regarded as a fixed discriminator and the generator is utilized for derivating training samples which can obtain the maximum response on the discriminator. Then, an efficient network with smaller model size and computational complexity is trained using the generated data and the teacher network, simultaneously. Efficient student networks learned using the proposed Data-Free Learning (DFL) method achieve 92.22% and 74.47% accuracies without any training data on the CIFAR-10 and CIFAR-100 datasets, respectively. Meanwhile, our student network obtains an 80.56% accuracy on the CelebA benchmark.
Clustering with Transitive Distance and K-Means Duality
Nov 22, 2007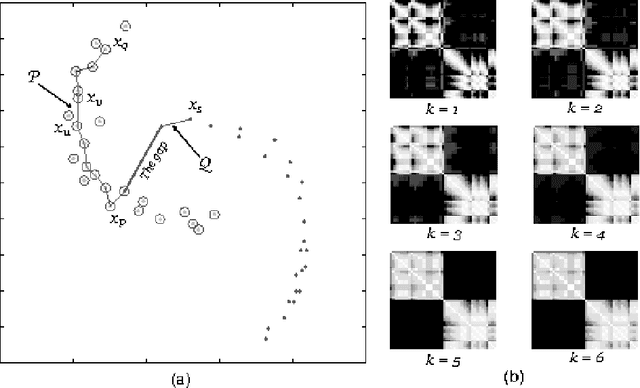

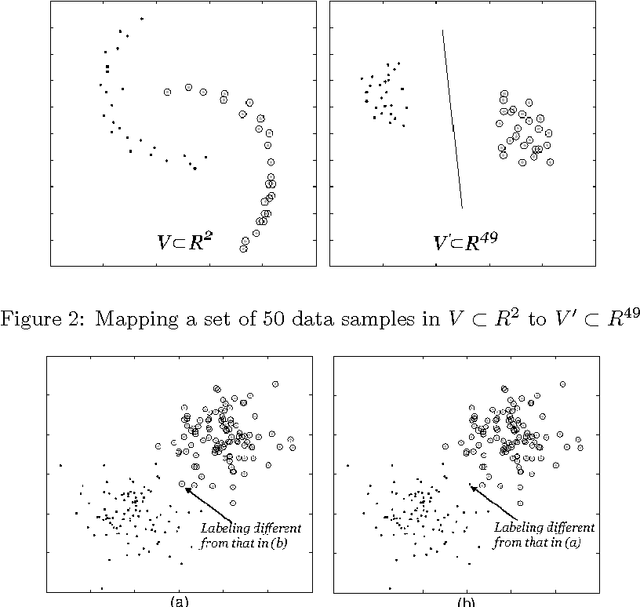
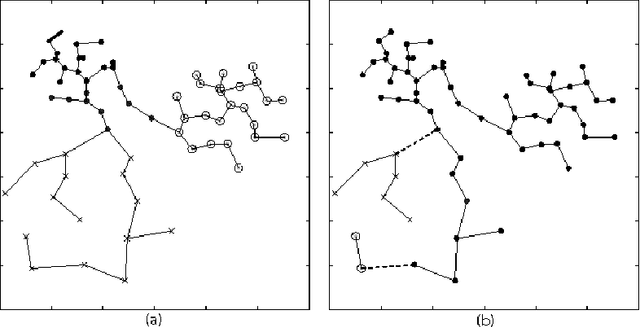
Recent spectral clustering methods are a propular and powerful technique for data clustering. These methods need to solve the eigenproblem whose computational complexity is $O(n^3)$, where $n$ is the number of data samples. In this paper, a non-eigenproblem based clustering method is proposed to deal with the clustering problem. Its performance is comparable to the spectral clustering algorithms but it is more efficient with computational complexity $O(n^2)$. We show that with a transitive distance and an observed property, called K-means duality, our algorithm can be used to handle data sets with complex cluster shapes, multi-scale clusters, and noise. Moreover, no parameters except the number of clusters need to be set in our algorithm.