 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentative Graph Neural Network
Aug 12, 2020Non-local operation is widely explored to model the long-range dependencies. However, the redundant computation in this operation leads to a prohibitive complexity. In this paper, we present a Representative Graph (RepGraph) layer to dynamically sample a few representative features, which dramatically reduces redundancy. Instead of propagating the messages from all positions, our RepGraph layer computes the response of one node merely with a few representative nodes. The locations of representative nodes come from a learned spatial offset matrix. The RepGraph layer is flexible to integrate into many visual architectures and combine with other operations. With the application of semantic segmentation, without any bells and whistles, our RepGraph network can compete or perform favourably against the state-of-the-art methods on three challenging benchmarks: ADE20K, Cityscapes, and PASCAL-Context datasets. In the task of object detection, our RepGraph layer can also improve the performance on the COCO dataset compared to the non-local operation. Code is available at https://git.io/RepGraph.
* Accepted to ECCV 2020. Code is available at https://git.io/RepGraph
FATNN: Fast and Accurate Ternary Neural Networks
Aug 12, 2020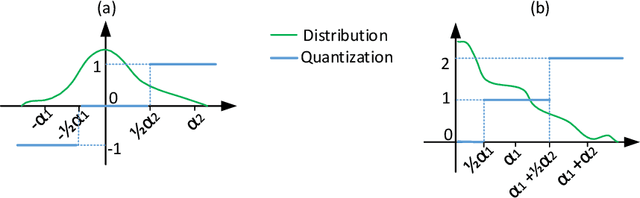

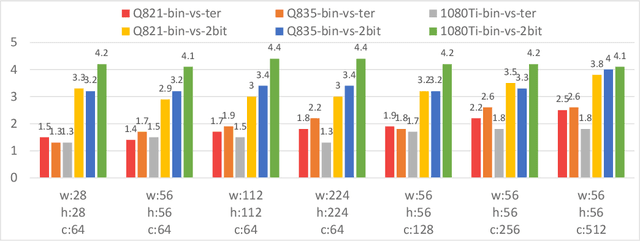

Ternary Neural Networks (TNNs) have received much attention due to being potentially orders of magnitude faster in inference, as well as more power efficient, than full-precision counterparts. However, 2 bits are required to encode the ternary representation with only 3 quantization levels leveraged. As a result, conventional TNNs have similar memory consumption and speed compared with the standard 2-bit models, but have worse representational capability. Moreover, there is still a significant gap in accuracy between TNNs and full-precision networks, hampering their deployment to real applications. To tackle these two challenges, in this work, we first show that, under some mild constraints, the computational complexity of ternary inner product can be reduced by 2x. Second, to mitigate the performance gap, we elaborately design an implementation-dependent ternary quantization algorithm. The proposed framework is termed Fast and Accurate Ternary Neural Networks (FATNN). Experiments on image classification demonstrate that our FATNN surpasses the state-of-the-arts by a significant margin in accuracy. More importantly, speedup evaluation comparing with various precisions is analyzed on several platforms, which serves as a strong benchmark for further research.
Pairwise Relation Learning for Semi-supervised Gland Segmentation
Aug 06, 2020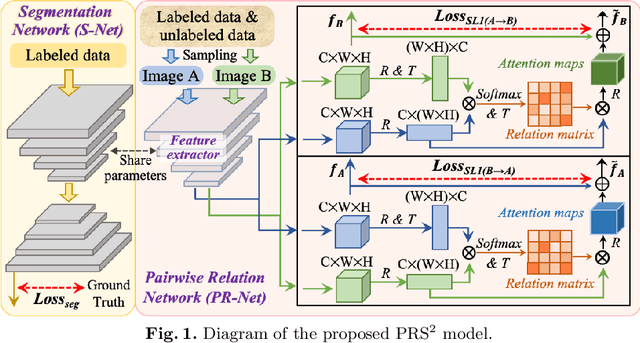
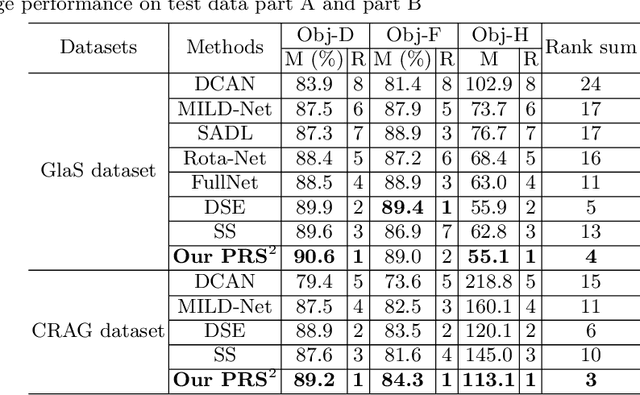
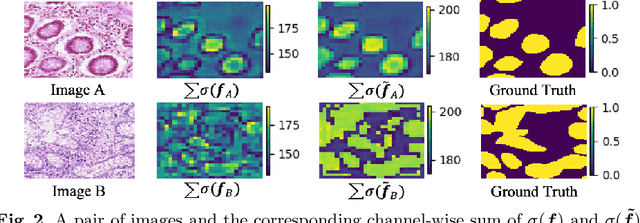
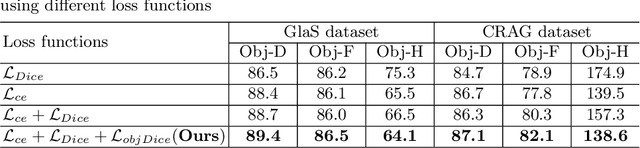
Accurate and automated gland segmentation on histology tissue images is an essential but challenging task in the computer-aided diagnosis of adenocarcinoma. Despite their prevalence, deep learning models always require a myriad number of densely annotated training images, which are difficult to obtain due to extensive labor and associated expert costs related to histology image annotations. In this paper, we propose the pairwise relation-based semi-supervised (PRS^2) model for gland segmentation on histology images. This model consists of a segmentation network (S-Net) and a pairwise relation network (PR-Net). The S-Net is trained on labeled data for segmentation, and PR-Net is trained on both labeled and unlabeled data in an unsupervised way to enhance its image representation ability via exploiting the semantic consistency between each pair of images in the feature space. Since both networks share their encoders, the image representation ability learned by PR-Net can be transferred to S-Net to improve its segmentation performance. We also design the object-level Dice loss to address the issues caused by touching glands and combine it with other two loss functions for S-Net. We evaluated our model against five recent methods on the GlaS dataset and three recent methods on the CRAG dataset. Our results not only demonstrate the effectiveness of the proposed PR-Net and object-level Dice loss, but also indicate that our PRS^2 model achieves the state-of-the-art gland segmentation performance on both benchmarks.
AE TextSpotter: Learning Visual and Linguistic Representation for Ambiguous Text Spotting
Aug 05, 2020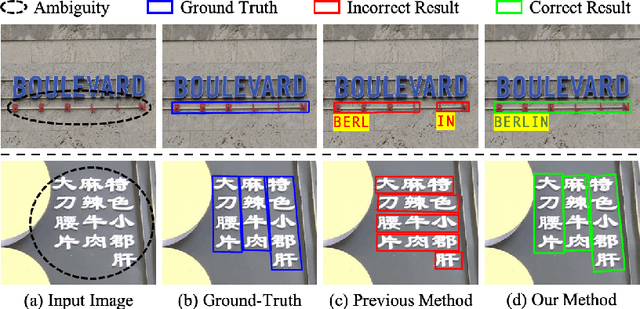
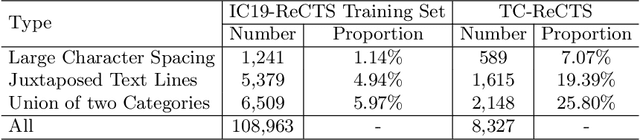

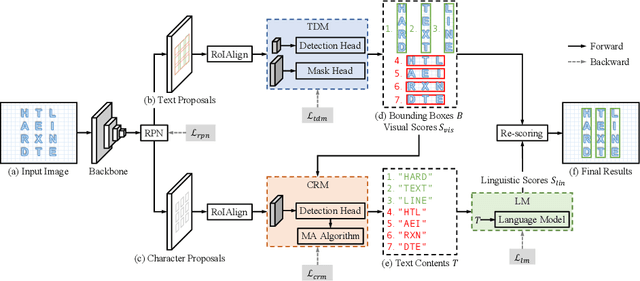
Scene text spotting aims to detect and recognize the entire word or sentence with multiple characters in natural images. It is still challenging because ambiguity often occurs when the spacing between characters is large or the characters are evenly spread in multiple rows and columns, making many visually plausible groupings of the characters (e.g. "BERLIN" is incorrectly detected as "BERL" and "IN" in Fig. 1(c)). Unlike previous works that merely employed visual features for text detection, this work proposes a novel text spotter, named Ambiguity Eliminating Text Spotter (AE TextSpotter), which learns both visual and linguistic features to significantly reduce ambiguity in text detection. The proposed AE TextSpotter has three important benefits. 1) The linguistic representation is learned together with the visual representation in a framework. To our knowledge, it is the first time to improve text detection by using a language model. 2) A carefully designed language module is utilized to reduce the detection confidence of incorrect text lines, making them easily pruned in the detection stage. 3) Extensive experiments show that AE TextSpotter outperforms other state-of-the-art methods by a large margin. For example, we carefully select a validation set of extremely ambiguous samples from the IC19-ReCTS dataset, where our approach surpasses other methods by more than 4%. The image list and evaluation scripts of the validation set have been released at https://github.com/whai362/TDA-ReCTS.
AQD: Towards Accurate Quantized Object Detection
Aug 03, 2020
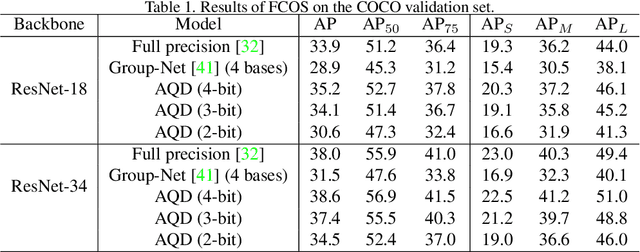
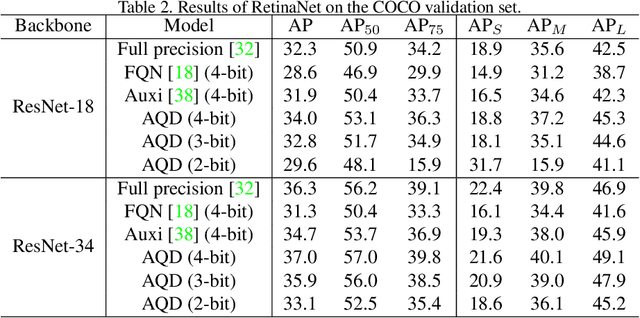

Network quantization aims to lower the bitwidth of weights and activations and hence reduce the model size and accelerate the inference of deep networks. Even though existing quantization methods have achieved promising performance on image classification, applying aggressively low bitwidth quantization on object detection while preserving the performance is still a challenge. In this paper, we demonstrate that the poor performance of the quantized network on object detection comes from the inaccurate batch statistics of batch normalization. To solve this, we propose an accurate quantized object detection (AQD) method. Specifically, we propose to employ multi-level batch normalization (multi-level BN) to estimate the batch statistics of each detection head separately. We further propose a learned interval quantization method to improve how the quantizer itself is configured. To evaluate the performance of the proposed methods, we apply AQD to two one-stage detectors (i.e., RetinaNet and FCOS). Experimental results on COCO show that our methods achieve near-lossless performance compared with the full-precision model by using extremely low bitwidth regimes such as 3-bit. In particular, we even outperform the full-precision counterpart by a large margin with a 4-bit detector, which is of great practical value.
Improving Generative Adversarial Networks with Local Coordinate Coding
Jul 28, 2020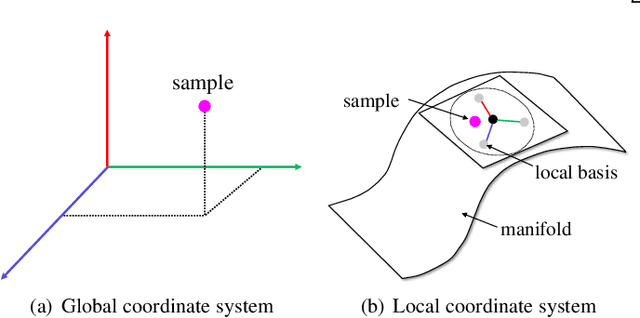
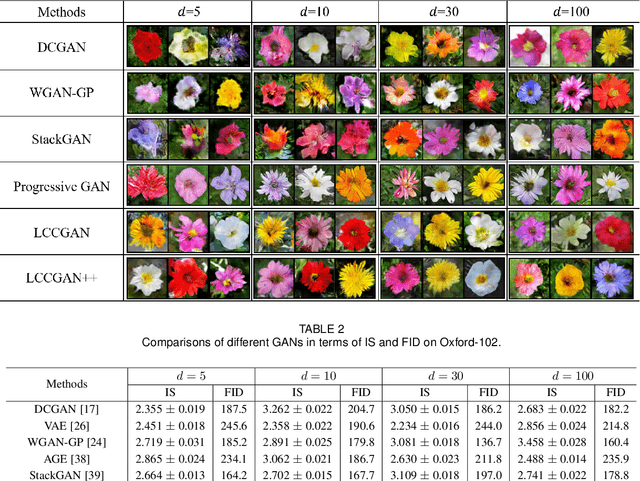
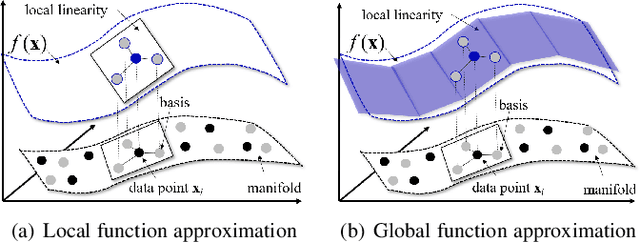
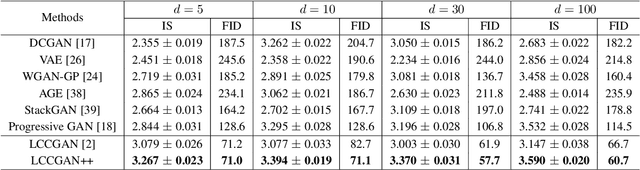
Generative adversarial networks (GANs) have shown remarkable success in generating realistic data from some predefined prior distribution (e.g., Gaussian noises). However, such prior distribution is often independent of real data and thus may lose semantic information (e.g., geometric structure or content in images) of data. In practice, the semantic information might be represented by some latent distribution learned from data. However, such latent distribution may incur difficulties in data sampling for GANs. In this paper, rather than sampling from the predefined prior distribution, we propose an LCCGAN model with local coordinate coding (LCC) to improve the performance of generating data. First, we propose an LCC sampling method in LCCGAN to sample meaningful points from the latent manifold. With the LCC sampling method, we can exploit the local information on the latent manifold and thus produce new data with promising quality. Second, we propose an improved version, namely LCCGAN++, by introducing a higher-order term in the generator approximation. This term is able to achieve better approximation and thus further improve the performance. More critically, we derive the generalization bound for both LCCGAN and LCCGAN++ and prove that a low-dimensional input is sufficient to achieve good generalization performance. Extensive experiments on four benchmark datasets demonstrate the superiority of the proposed method over existing GANs.
Soft Expert Reward Learning for Vision-and-Language Navigation
Jul 21, 2020
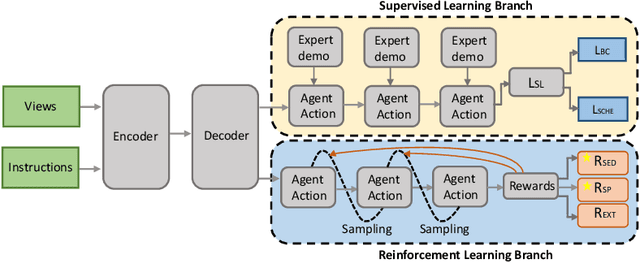
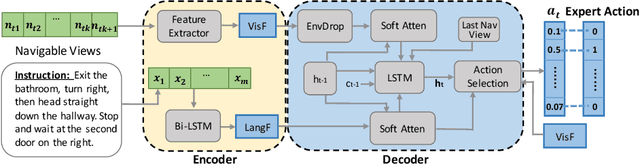
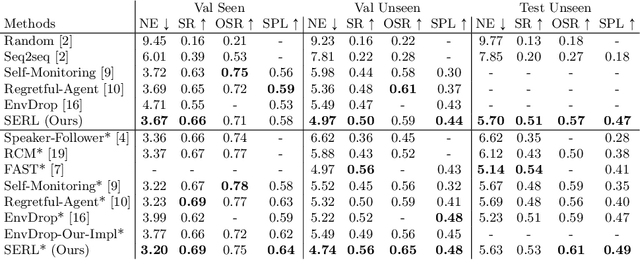
Vision-and-Language Navigation (VLN) requires an agent to find a specified spot in an unseen environment by following natural language instructions. Dominant methods based on supervised learning clone expert's behaviours and thus perform better on seen environments, while showing restricted performance on unseen ones. Reinforcement Learning (RL) based models show better generalisation ability but have issues as well, requiring large amount of manual reward engineering is one of which. In this paper, we introduce a Soft Expert Reward Learning (SERL) model to overcome the reward engineering designing and generalisation problems of the VLN task. Our proposed method consists of two complementary components: Soft Expert Distillation (SED) module encourages agents to behave like an expert as much as possible, but in a soft fashion; Self Perceiving (SP) module targets at pushing the agent towards the final destination as fast as possible. Empirically, we evaluate our model on the VLN seen, unseen and test splits and the model outperforms the state-of-the-art methods on most of the evaluation metrics.
Weighing Counts: Sequential Crowd Counting by Reinforcement Learning
Jul 16, 2020
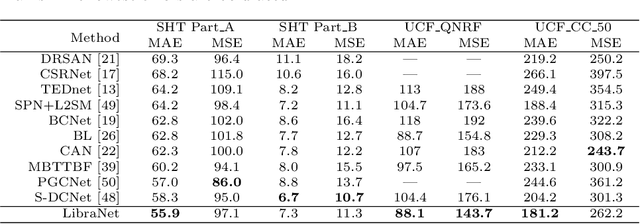
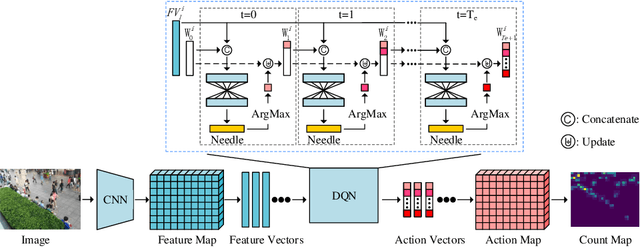
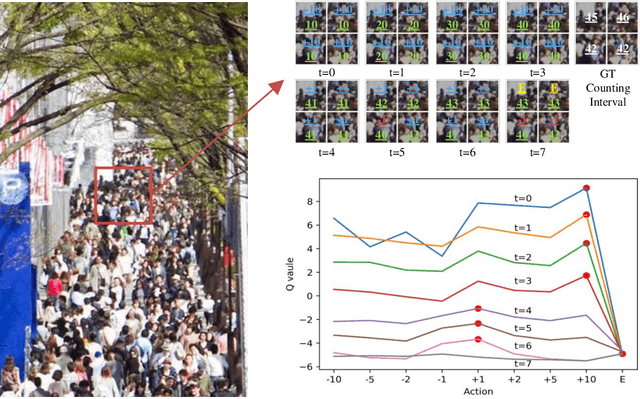
We formulate counting as a sequential decision problem and present a novel crowd counting model solvable by deep reinforcement learning. In contrast to existing counting models that directly output count values, we divide one-step estimation into a sequence of much easier and more tractable sub-decision problems. Such sequential decision nature corresponds exactly to a physical process in reality scale weighing. Inspired by scale weighing, we propose a novel 'counting scale' termed LibraNet where the count value is analogized by weight. By virtually placing a crowd image on one side of a scale, LibraNet (agent) sequentially learns to place appropriate weights on the other side to match the crowd count. At each step, LibraNet chooses one weight (action) from the weight box (the pre-defined action pool) according to the current crowd image features and weights placed on the scale pan (state). LibraNet is required to learn to balance the scale according to the feedback of the needle (Q values). We show that LibraNet exactly implements scale weighing by visualizing the decision process how LibraNet chooses actions. Extensive experiments demonstrate the effectiveness of our design choices and report state-of-the-art results on a few crowd counting benchmarks. We also demonstrate good cross-dataset generalization of LibraNet. Code and models are made available at: https://git.io/libranet
Deep Learning for Anomaly Detection: A Review
Jul 08, 2020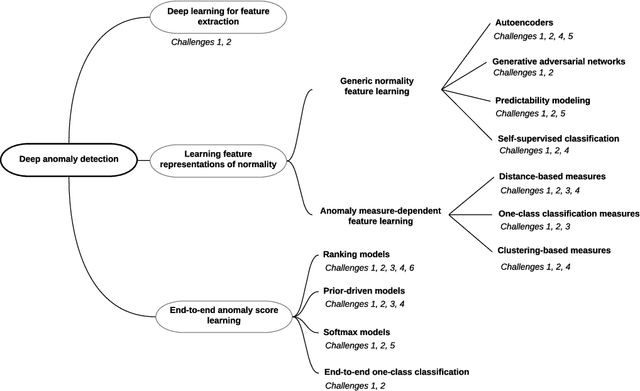
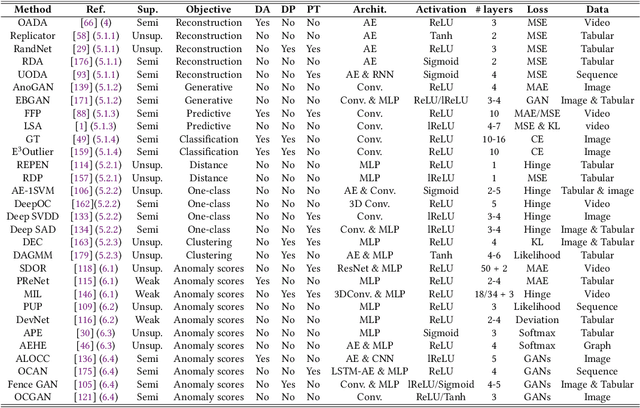
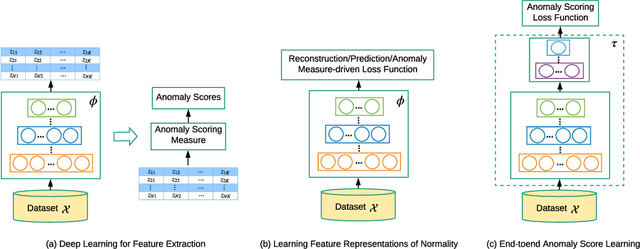
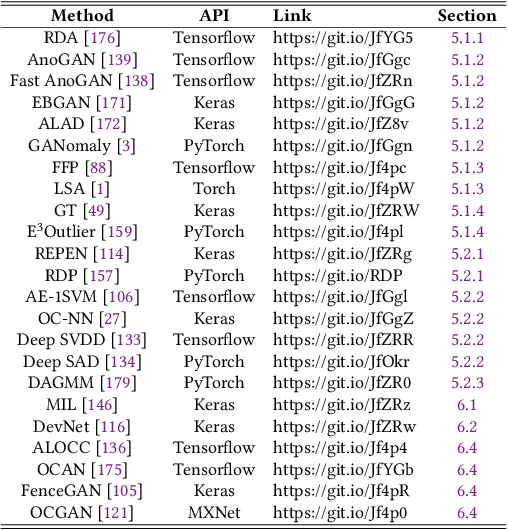
Anomaly detection, a.k.a. outlier detection, has been a lasting yet active research area in various research communities for several decades. There are still some unique problem complexities and challenges that require advanced approaches. In recent years, deep learning enabled anomaly detection, i.e., deep anomaly detection, has emerged as a critical direction. This paper reviews the research of deep anomaly detection with a comprehensive taxonomy of detection methods, covering advancements in three high-level categories and 11 fine-grained categories of the methods. We review their key intuitions, objective functions, underlying assumptions, advantages and disadvantages, and discuss how they address the aforementioned challenges. We further discuss a set of possible future opportunities and new perspectives on addressing the challenges.
FCOS: A simple and strong anchor-free object detector
Jun 14, 2020

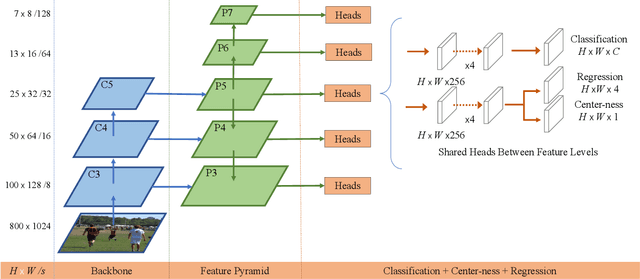
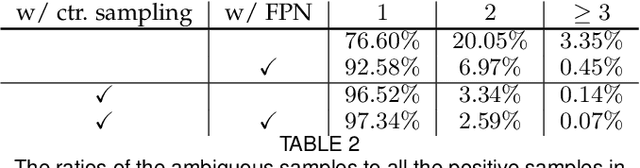
In computer vision, object detection is one of most important tasks, which underpins a few instance-level recognition tasks and many downstream applications. Recently one-stage methods have gained much attention over two-stage approaches due to their simpler design and competitive performance. Here we propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to other dense prediction problems such as semantic segmentation. Almost all state-of-the-art object detectors such as RetinaNet, SSD, YOLOv3, and Faster R-CNN rely on pre-defined anchor boxes. In contrast, our proposed detector FCOS is anchor box free, as well as proposal free. By eliminating the pre-defined set of anchor boxes, FCOS completely avoids the complicated computation related to anchor boxes such as calculating the intersection over union (IoU) scores during training. More importantly, we also avoid all hyper-parameters related to anchor boxes, which are often sensitive to the final detection performance. With the only post-processing non-maximum suppression (NMS), we demonstrate a much simpler and flexible detection framework achieving improved detection accuracy. We hope that the proposed FCOS framework can serve as a simple and strong alternative for many other instance-level tasks. Code and pre-trained models are available at: https://git.io/AdelaiDet