 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Open Set to Closed Set: Supervised Spatial Divide-and-Conquer for Object Counting
Paper and Code
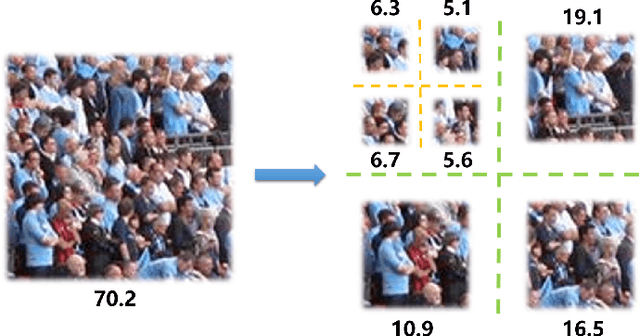

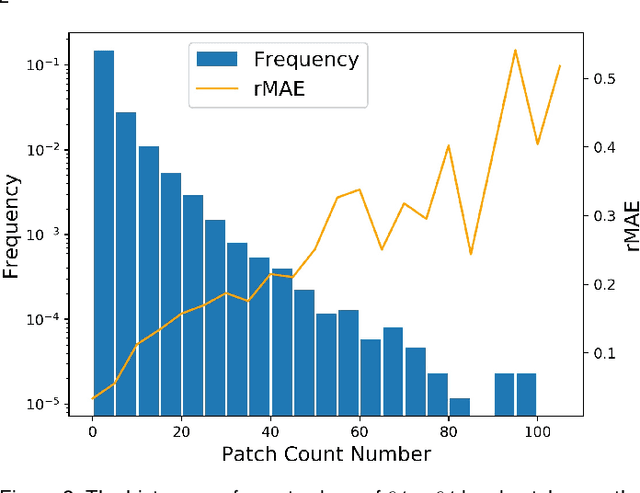
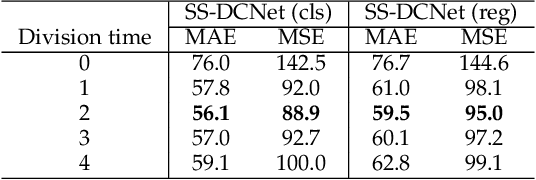
Visual counting, a task that aims to estimate the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in [0, inf) in theory. However, collected data and labeled instances are limited in reality, which means that only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are prone to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting has an interesting and exclusive property---spatially decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. We therefore introduce the idea of spatial divide-and-conquer (S-DC) that transforms open-set counting into a closed-set problem. This idea is implemented by a novel Supervised Spatial Divide-and-Conquer Network (SS-DCNet). Thus, SS-DCNet can only learn from a closed set but generalize well to open-set scenarios via S-DC. SS-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. We provide theoretical analyses as well as a controlled experiment on toy data, demonstrating why closed-set modeling makes sense. Extensive experiments show that SS-DCNet achieves the state-of-the-art performance. Code and models are available at: https://tinyurl.com/SS-DCNet.