 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTx-LLM: A Large Language Model for Therapeutics
Jun 10, 2024



Developing therapeutics is a lengthy and expensive process that requires the satisfaction of many different criteria, and AI models capable of expediting the process would be invaluable. However, the majority of current AI approaches address only a narrowly defined set of tasks, often circumscribed within a particular domain. To bridge this gap, we introduce Tx-LLM, a generalist large language model (LLM) fine-tuned from PaLM-2 which encodes knowledge about diverse therapeutic modalities. Tx-LLM is trained using a collection of 709 datasets that target 66 tasks spanning various stages of the drug discovery pipeline. Using a single set of weights, Tx-LLM simultaneously processes a wide variety of chemical or biological entities(small molecules, proteins, nucleic acids, cell lines, diseases) interleaved with free-text, allowing it to predict a broad range of associated properties, achieving competitive with state-of-the-art (SOTA) performance on 43 out of 66 tasks and exceeding SOTA on 22. Among these, Tx-LLM is particularly powerful and exceeds best-in-class performance on average for tasks combining molecular SMILES representations with text such as cell line names or disease names, likely due to context learned during pretraining. We observe evidence of positive transfer between tasks with diverse drug types (e.g.,tasks involving small molecules and tasks involving proteins), and we study the impact of model size, domain finetuning, and prompting strategies on performance. We believe Tx-LLM represents an important step towards LLMs encoding biochemical knowledge and could have a future role as an end-to-end tool across the drug discovery development pipeline.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
Towards Conversational Diagnostic AI
Jan 11, 2024At the heart of medicine lies the physician-patient dialogue, where skillful history-taking paves the way for accurate diagnosis, effective management, and enduring trust. Artificial Intelligence (AI) systems capable of diagnostic dialogue could increase accessibility, consistency, and quality of care. However, approximating clinicians' expertise is an outstanding grand challenge. Here, we introduce AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts. We designed a framework for evaluating clinically-meaningful axes of performance including history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy. We compared AMIE's performance to that of primary care physicians (PCPs) in a randomized, double-blind crossover study of text-based consultations with validated patient actors in the style of an Objective Structured Clinical Examination (OSCE). The study included 149 case scenarios from clinical providers in Canada, the UK, and India, 20 PCPs for comparison with AMIE, and evaluations by specialist physicians and patient actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 28 of 32 axes according to specialist physicians and 24 of 26 axes according to patient actors. Our research has several limitations and should be interpreted with appropriate caution. Clinicians were limited to unfamiliar synchronous text-chat which permits large-scale LLM-patient interactions but is not representative of usual clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.
Towards Accurate Differential Diagnosis with Large Language Models
Nov 30, 2023



An accurate differential diagnosis (DDx) is a cornerstone of medical care, often reached through an iterative process of interpretation that combines clinical history, physical examination, investigations and procedures. Interactive interfaces powered by Large Language Models (LLMs) present new opportunities to both assist and automate aspects of this process. In this study, we introduce an LLM optimized for diagnostic reasoning, and evaluate its ability to generate a DDx alone or as an aid to clinicians. 20 clinicians evaluated 302 challenging, real-world medical cases sourced from the New England Journal of Medicine (NEJM) case reports. Each case report was read by two clinicians, who were randomized to one of two assistive conditions: either assistance from search engines and standard medical resources, or LLM assistance in addition to these tools. All clinicians provided a baseline, unassisted DDx prior to using the respective assistive tools. Our LLM for DDx exhibited standalone performance that exceeded that of unassisted clinicians (top-10 accuracy 59.1% vs 33.6%, [p = 0.04]). Comparing the two assisted study arms, the DDx quality score was higher for clinicians assisted by our LLM (top-10 accuracy 51.7%) compared to clinicians without its assistance (36.1%) (McNemar's Test: 45.7, p < 0.01) and clinicians with search (44.4%) (4.75, p = 0.03). Further, clinicians assisted by our LLM arrived at more comprehensive differential lists than those without its assistance. Our study suggests that our LLM for DDx has potential to improve clinicians' diagnostic reasoning and accuracy in challenging cases, meriting further real-world evaluation for its ability to empower physicians and widen patients' access to specialist-level expertise.
Towards Generalist Biomedical AI
Jul 26, 2023



Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
Using generative AI to investigate medical imagery models and datasets
Jun 01, 2023



AI models have shown promise in many medical imaging tasks. However, our ability to explain what signals these models have learned is severely lacking. Explanations are needed in order to increase the trust in AI-based models, and could enable novel scientific discovery by uncovering signals in the data that are not yet known to experts. In this paper, we present a method for automatic visual explanations leveraging team-based expertise by generating hypotheses of what visual signals in the images are correlated with the task. We propose the following 4 steps: (i) Train a classifier to perform a given task (ii) Train a classifier guided StyleGAN-based image generator (StylEx) (iii) Automatically detect and visualize the top visual attributes that the classifier is sensitive towards (iv) Formulate hypotheses for the underlying mechanisms, to stimulate future research. Specifically, we present the discovered attributes to an interdisciplinary panel of experts so that hypotheses can account for social and structural determinants of health. We demonstrate results on eight prediction tasks across three medical imaging modalities: retinal fundus photographs, external eye photographs, and chest radiographs. We showcase examples of attributes that capture clinically known features, confounders that arise from factors beyond physiological mechanisms, and reveal a number of physiologically plausible novel attributes. Our approach has the potential to enable researchers to better understand, improve their assessment, and extract new knowledge from AI-based models. Importantly, we highlight that attributes generated by our framework can capture phenomena beyond physiology or pathophysiology, reflecting the real world nature of healthcare delivery and socio-cultural factors. Finally, we intend to release code to enable researchers to train their own StylEx models and analyze their predictive tasks.
Towards Expert-Level Medical Question Answering with Large Language Models
May 16, 2023



Recent artificial intelligence (AI) systems have reached milestones in "grand challenges" ranging from Go to protein-folding. The capability to retrieve medical knowledge, reason over it, and answer medical questions comparably to physicians has long been viewed as one such grand challenge. Large language models (LLMs) have catalyzed significant progress in medical question answering; Med-PaLM was the first model to exceed a "passing" score in US Medical Licensing Examination (USMLE) style questions with a score of 67.2% on the MedQA dataset. However, this and other prior work suggested significant room for improvement, especially when models' answers were compared to clinicians' answers. Here we present Med-PaLM 2, which bridges these gaps by leveraging a combination of base LLM improvements (PaLM 2), medical domain finetuning, and prompting strategies including a novel ensemble refinement approach. Med-PaLM 2 scored up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19% and setting a new state-of-the-art. We also observed performance approaching or exceeding state-of-the-art across MedMCQA, PubMedQA, and MMLU clinical topics datasets. We performed detailed human evaluations on long-form questions along multiple axes relevant to clinical applications. In pairwise comparative ranking of 1066 consumer medical questions, physicians preferred Med-PaLM 2 answers to those produced by physicians on eight of nine axes pertaining to clinical utility (p < 0.001). We also observed significant improvements compared to Med-PaLM on every evaluation axis (p < 0.001) on newly introduced datasets of 240 long-form "adversarial" questions to probe LLM limitations. While further studies are necessary to validate the efficacy of these models in real-world settings, these results highlight rapid progress towards physician-level performance in medical question answering.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Discovering novel systemic biomarkers in photos of the external eye
Jul 19, 2022
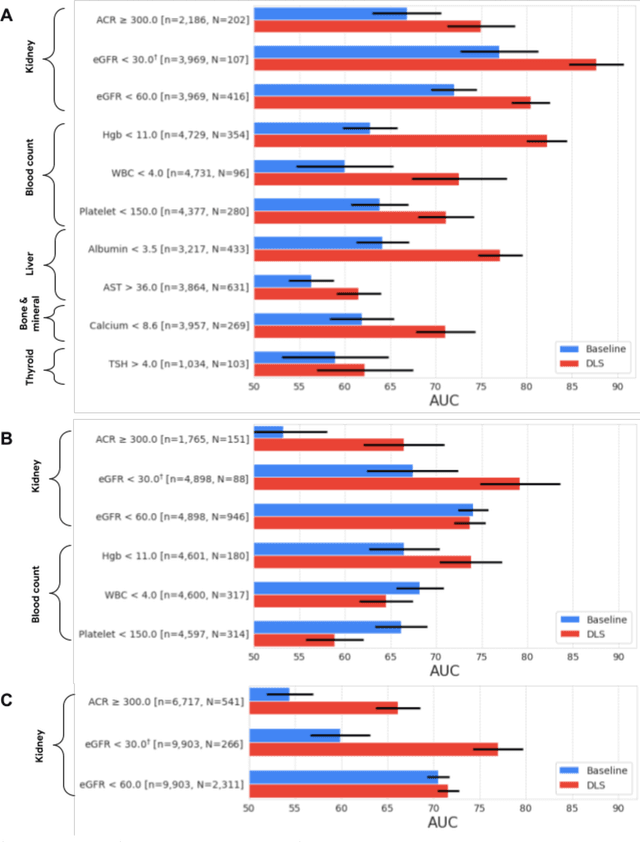
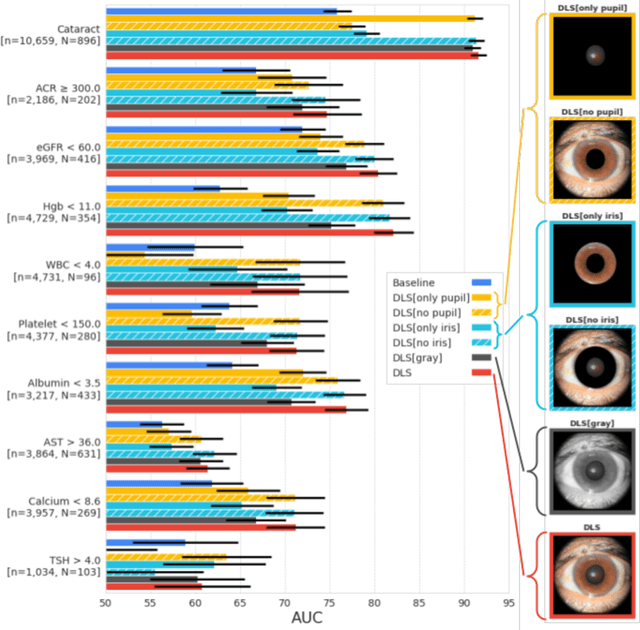
External eye photos were recently shown to reveal signs of diabetic retinal disease and elevated HbA1c. In this paper, we evaluate if external eye photos contain information about additional systemic medical conditions. We developed a deep learning system (DLS) that takes external eye photos as input and predicts multiple systemic parameters, such as those related to the liver (albumin, AST); kidney (eGFR estimated using the race-free 2021 CKD-EPI creatinine equation, the urine ACR); bone & mineral (calcium); thyroid (TSH); and blood count (Hgb, WBC, platelets). Development leveraged 151,237 images from 49,015 patients with diabetes undergoing diabetic eye screening in 11 sites across Los Angeles county, CA. Evaluation focused on 9 pre-specified systemic parameters and leveraged 3 validation sets (A, B, C) spanning 28,869 patients with and without diabetes undergoing eye screening in 3 independent sites in Los Angeles County, CA, and the greater Atlanta area, GA. We compared against baseline models incorporating available clinicodemographic variables (e.g. age, sex, race/ethnicity, years with diabetes). Relative to the baseline, the DLS achieved statistically significant superior performance at detecting AST>36, calcium<8.6, eGFR<60, Hgb<11, platelets<150, ACR>=300, and WBC<4 on validation set A (a patient population similar to the development sets), where the AUC of DLS exceeded that of the baseline by 5.2-19.4%. On validation sets B and C, with substantial patient population differences compared to the development sets, the DLS outperformed the baseline for ACR>=300 and Hgb<11 by 7.3-13.2%. Our findings provide further evidence that external eye photos contain important biomarkers of systemic health spanning multiple organ systems. Further work is needed to investigate whether and how these biomarkers can be translated into clinical impact.