 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Graph Algorithms to Pretrain Graph Completion Transformers
Oct 14, 2022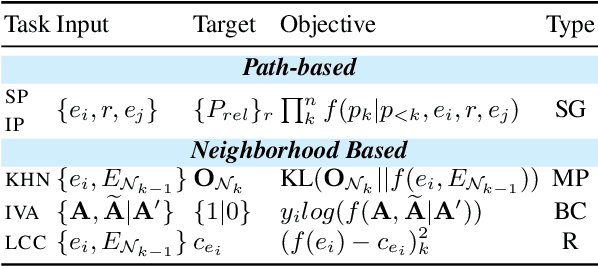


Recent work on Graph Neural Networks has demonstrated that self-supervised pretraining can further enhance performance on downstream graph, link, and node classification tasks. However, the efficacy of pretraining tasks has not been fully investigated for downstream large knowledge graph completion tasks. Using a contextualized knowledge graph embedding approach, we investigate five different pretraining signals, constructed using several graph algorithms and no external data, as well as their combination. We leverage the versatility of our Transformer-based model to explore graph structure generation pretraining tasks, typically inapplicable to most graph embedding methods. We further propose a new path-finding algorithm guided by information gain and find that it is the best-performing pretraining task across three downstream knowledge graph completion datasets. In a multitask setting that combines all pretraining tasks, our method surpasses some of the latest and strong performing knowledge graph embedding methods on all metrics for FB15K-237, on MRR and Hit@1 for WN18RR and on MRR and hit@10 for JF17K (a knowledge hypergraph dataset).
SMPL-IK: Learned Morphology-Aware Inverse Kinematics for AI Driven Artistic Workflows
Aug 16, 2022
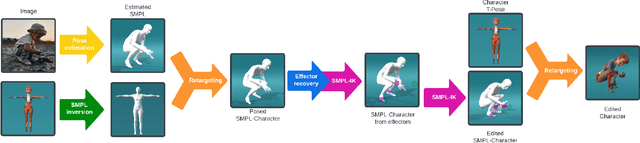


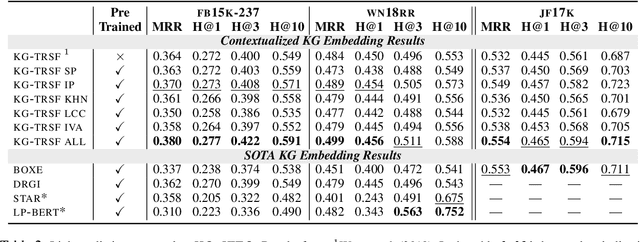
Inverse Kinematics (IK) systems are often rigid with respect to their input character, thus requiring user intervention to be adapted to new skeletons. In this paper we aim at creating a flexible, learned IK solver applicable to a wide variety of human morphologies. We extend a state-of-the-art machine learning IK solver to operate on the well known Skinned Multi-Person Linear model (SMPL). We call our model SMPL-IK, and show that when integrated into real-time 3D software, this extended system opens up opportunities for defining novel AI-assisted animation workflows. For example, pose authoring can be made more flexible with SMPL-IK by allowing users to modify gender and body shape while posing a character. Additionally, when chained with existing pose estimation algorithms, SMPL-IK accelerates posing by allowing users to bootstrap 3D scenes from 2D images while allowing for further editing. Finally, we propose a novel SMPL Shape Inversion mechanism (SMPL-SI) to map arbitrary humanoid characters to the SMPL space, allowing artists to leverage SMPL-IK on custom characters. In addition to qualitative demos showing proposed tools, we present quantitative SMPL-IK baselines on the H36M and AMASS datasets.
Improving Meta-Learning Generalization with Activation-Based Early-Stopping
Aug 03, 2022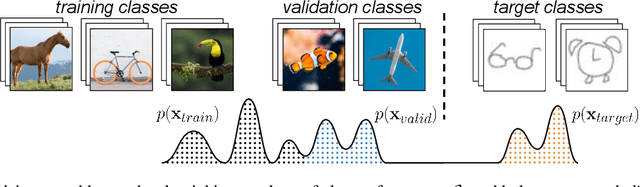

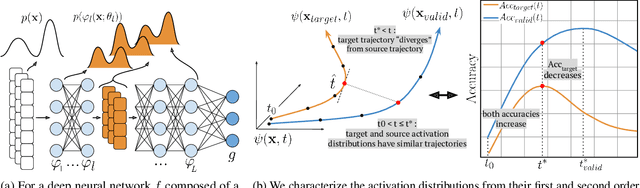
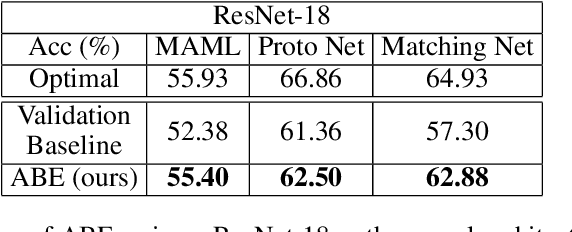
Meta-Learning algorithms for few-shot learning aim to train neural networks capable of generalizing to novel tasks using only a few examples. Early-stopping is critical for performance, halting model training when it reaches optimal generalization to the new task distribution. Early-stopping mechanisms in Meta-Learning typically rely on measuring the model performance on labeled examples from a meta-validation set drawn from the training (source) dataset. This is problematic in few-shot transfer learning settings, where the meta-test set comes from a different target dataset (OOD) and can potentially have a large distributional shift with the meta-validation set. In this work, we propose Activation Based Early-stopping (ABE), an alternative to using validation-based early-stopping for meta-learning. Specifically, we analyze the evolution, during meta-training, of the neural activations at each hidden layer, on a small set of unlabelled support examples from a single task of the target tasks distribution, as this constitutes a minimal and justifiably accessible information from the target problem. Our experiments show that simple, label agnostic statistics on the activations offer an effective way to estimate how the target generalization evolves over time. At each hidden layer, we characterize the activation distributions, from their first and second order moments, then further summarized along the feature dimensions, resulting in a compact yet intuitive characterization in a four-dimensional space. Detecting when, throughout training time, and at which layer, the target activation trajectory diverges from the activation trajectory of the source data, allows us to perform early-stopping and improve generalization in a large array of few-shot transfer learning settings, across different algorithms, source and target datasets.
MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation
May 30, 2022
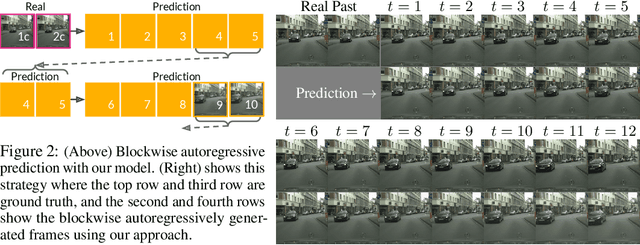
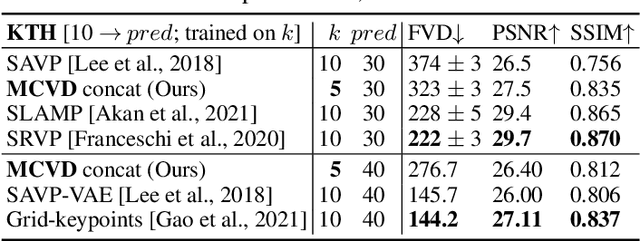
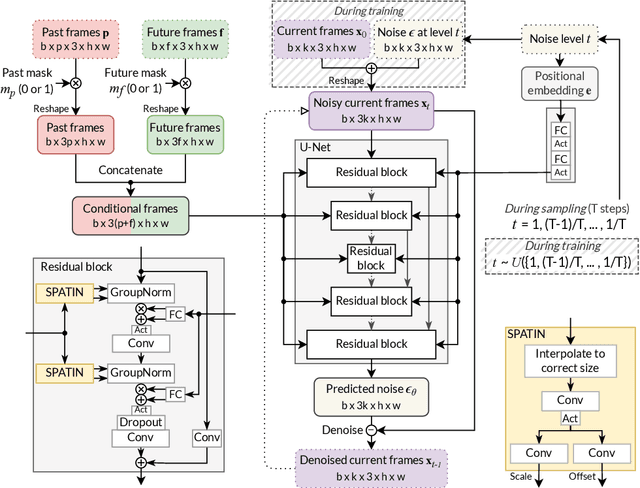
Video prediction is a challenging task. The quality of video frames from current state-of-the-art (SOTA) generative models tends to be poor and generalization beyond the training data is difficult. Furthermore, existing prediction frameworks are typically not capable of simultaneously handling other video-related tasks such as unconditional generation or interpolation. In this work, we devise a general-purpose framework called Masked Conditional Video Diffusion (MCVD) for all of these video synthesis tasks using a probabilistic conditional score-based denoising diffusion model, conditioned on past and/or future frames. We train the model in a manner where we randomly and independently mask all the past frames or all the future frames. This novel but straightforward setup allows us to train a single model that is capable of executing a broad range of video tasks, specifically: future/past prediction -- when only future/past frames are masked; unconditional generation -- when both past and future frames are masked; and interpolation -- when neither past nor future frames are masked. Our experiments show that this approach can generate high-quality frames for diverse types of videos. Our MCVD models are built from simple non-recurrent 2D-convolutional architectures, conditioning on blocks of frames and generating blocks of frames. We generate videos of arbitrary lengths autoregressively in a block-wise manner. Our approach yields SOTA results across standard video prediction and interpolation benchmarks, with computation times for training models measured in 1-12 days using $\le$ 4 GPUs. Project page: https://mask-cond-video-diffusion.github.io ; Code : https://github.com/voletiv/mcvd-pytorch
Challenges in leveraging GANs for few-shot data augmentation
Mar 30, 2022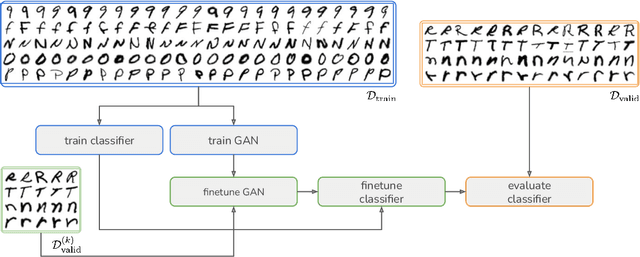
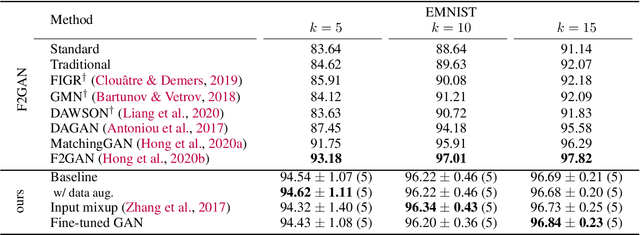
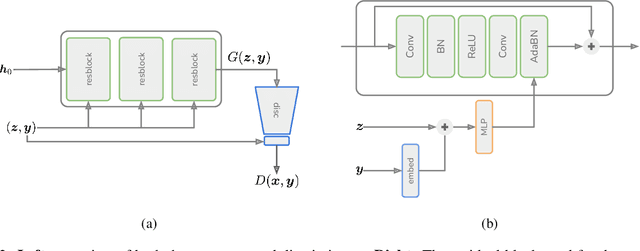

In this paper, we explore the use of GAN-based few-shot data augmentation as a method to improve few-shot classification performance. We perform an exploration into how a GAN can be fine-tuned for such a task (one of which is in a class-incremental manner), as well as a rigorous empirical investigation into how well these models can perform to improve few-shot classification. We identify issues related to the difficulty of training such generative models under a purely supervised regime with very few examples, as well as issues regarding the evaluation protocols of existing works. We also find that in this regime, classification accuracy is highly sensitive to how the classes of the dataset are randomly split. Therefore, we propose a semi-supervised fine-tuning approach as a more pragmatic way forward to address these problems.
Direct Behavior Specification via Constrained Reinforcement Learning
Jan 19, 2022
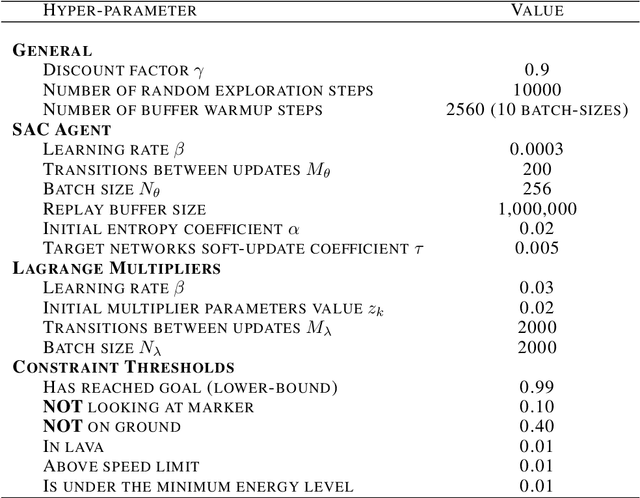
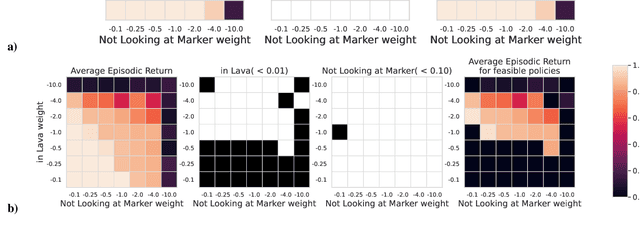

The standard formulation of Reinforcement Learning lacks a practical way of specifying what are admissible and forbidden behaviors. Most often, practitioners go about the task of behavior specification by manually engineering the reward function, a counter-intuitive process that requires several iterations and is prone to reward hacking by the agent. In this work, we argue that constrained RL, which has almost exclusively been used for safe RL, also has the potential to significantly reduce the amount of work spent for reward specification in applied RL projects. To this end, we propose to specify behavioral preferences in the CMDP framework and to use Lagrangian methods to automatically weigh each of these behavioral constraints. Specifically, we investigate how CMDPs can be adapted to solve goal-based tasks while adhering to several constraints simultaneously. We evaluate this framework on a set of continuous control tasks relevant to the application of Reinforcement Learning for NPC design in video games.
Does entity abstraction help generative Transformers reason?
Jan 05, 2022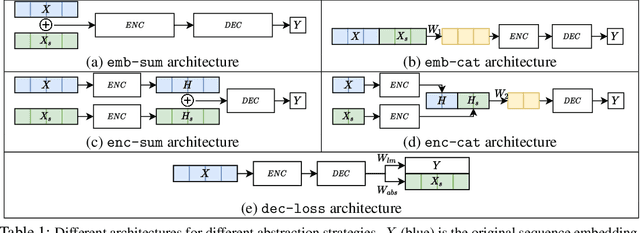

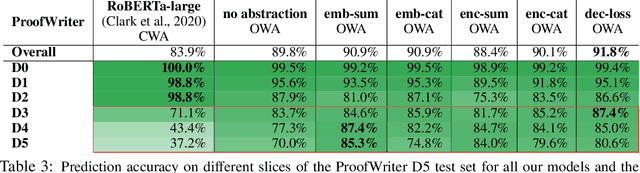
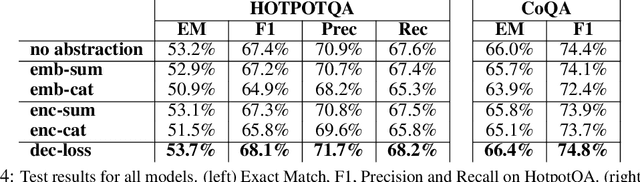
Pre-trained language models (LMs) often struggle to reason logically or generalize in a compositional fashion. Recent work suggests that incorporating external entity knowledge can improve LMs' abilities to reason and generalize. However, the effect of explicitly providing entity abstraction remains unclear, especially with recent studies suggesting that pre-trained LMs already encode some of that knowledge in their parameters. We study the utility of incorporating entity type abstractions into pre-trained Transformers and test these methods on four NLP tasks requiring different forms of logical reasoning: (1) compositional language understanding with text-based relational reasoning (CLUTRR), (2) abductive reasoning (ProofWriter), (3) multi-hop question answering (HotpotQA), and (4) conversational question answering (CoQA). We propose and empirically explore three ways to add such abstraction: (i) as additional input embeddings, (ii) as a separate sequence to encode, and (iii) as an auxiliary prediction task for the model. Overall, our analysis demonstrates that models with abstract entity knowledge performs better than without it. However, our experiments also show that the benefits strongly depend on the technique used and the task at hand. The best abstraction aware models achieved an overall accuracy of 88.8% and 91.8% compared to the baseline model achieving 62.3% and 89.8% on CLUTRR and ProofWriter respectively. In addition, abstraction-aware models showed improved compositional generalization in both interpolation and extrapolation settings. However, for HotpotQA and CoQA, we find that F1 scores improve by only 0.5% on average. Our results suggest that the benefit of explicit abstraction is significant in formally defined logical reasoning settings requiring many reasoning hops, but point to the notion that it is less beneficial for NLP tasks having less formal logical structure.
Learning to Guide and to Be Guided in the Architect-Builder Problem
Dec 19, 2021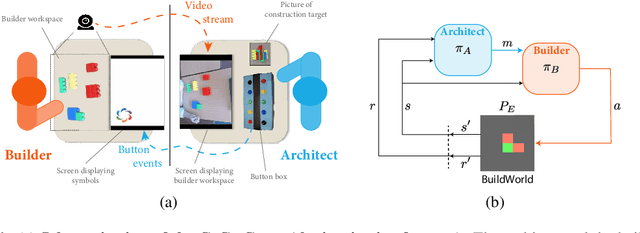
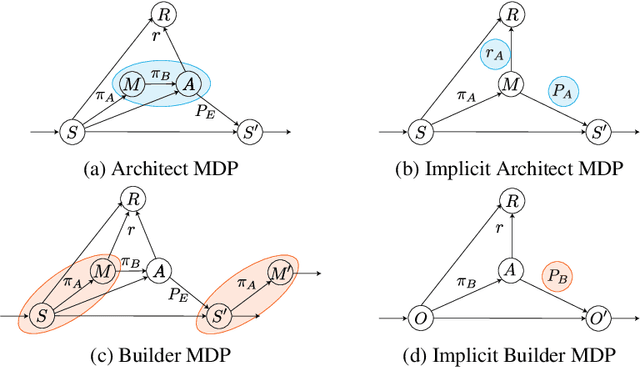
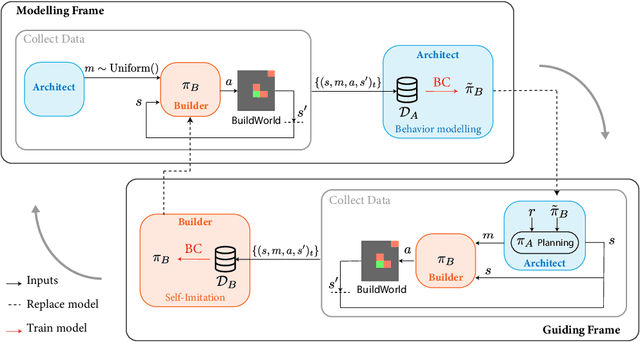
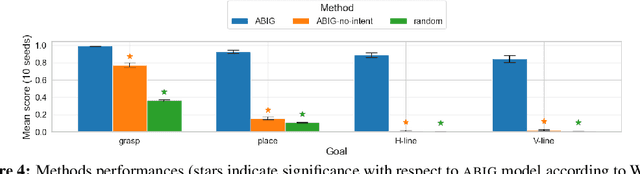
We are interested in interactive agents that learn to coordinate, namely, a $builder$ -- which performs actions but ignores the goal of the task -- and an $architect$ which guides the builder towards the goal of the task. We define and explore a formal setting where artificial agents are equipped with mechanisms that allow them to simultaneously learn a task while at the same time evolving a shared communication protocol. The field of Experimental Semiotics has shown the extent of human proficiency at learning from a priori unknown instructions meanings. Therefore, we take inspiration from it and present the Architect-Builder Problem (ABP): an asymmetrical setting in which an architect must learn to guide a builder towards constructing a specific structure. The architect knows the target structure but cannot act in the environment and can only send arbitrary messages to the builder. The builder on the other hand can act in the environment but has no knowledge about the task at hand and must learn to solve it relying only on the messages sent by the architect. Crucially, the meaning of messages is initially not defined nor shared between the agents but must be negotiated throughout learning. Under these constraints, we propose Architect-Builder Iterated Guiding (ABIG), a solution to the Architect-Builder Problem where the architect leverages a learned model of the builder to guide it while the builder uses self-imitation learning to reinforce its guided behavior. We analyze the key learning mechanisms of ABIG and test it in a 2-dimensional instantiation of the ABP where tasks involve grasping cubes, placing them at a given location, or building various shapes. In this environment, ABIG results in a low-level, high-frequency, guiding communication protocol that not only enables an architect-builder pair to solve the task at hand, but that can also generalize to unseen tasks.
From Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence
Oct 28, 2021
Machine learning has long since become a keystone technology, accelerating science and applications in a broad range of domains. Consequently, the notion of applying learning methods to a particular problem set has become an established and valuable modus operandi to advance a particular field. In this article we argue that such an approach does not straightforwardly extended to robotics -- or to embodied intelligence more generally: systems which engage in a purposeful exchange of energy and information with a physical environment. In particular, the purview of embodied intelligent agents extends significantly beyond the typical considerations of main-stream machine learning approaches, which typically (i) do not consider operation under conditions significantly different from those encountered during training; (ii) do not consider the often substantial, long-lasting and potentially safety-critical nature of interactions during learning and deployment; (iii) do not require ready adaptation to novel tasks while at the same time (iv) effectively and efficiently curating and extending their models of the world through targeted and deliberate actions. In reality, therefore, these limitations result in learning-based systems which suffer from many of the same operational shortcomings as more traditional, engineering-based approaches when deployed on a robot outside a well defined, and often narrow operating envelope. Contrary to viewing embodied intelligence as another application domain for machine learning, here we argue that it is in fact a key driver for the advancement of machine learning technology. In this article our goal is to highlight challenges and opportunities that are specific to embodied intelligence and to propose research directions which may significantly advance the state-of-the-art in robot learning.
Simple Video Generation using Neural ODEs
Sep 07, 2021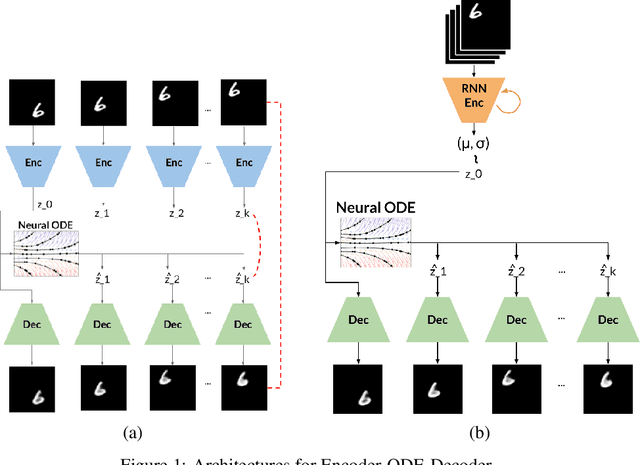
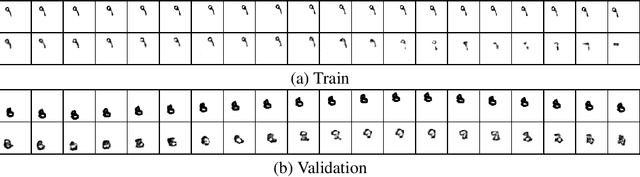
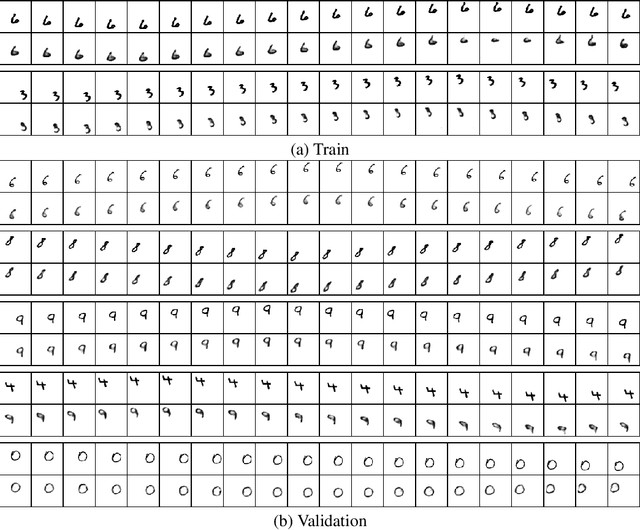
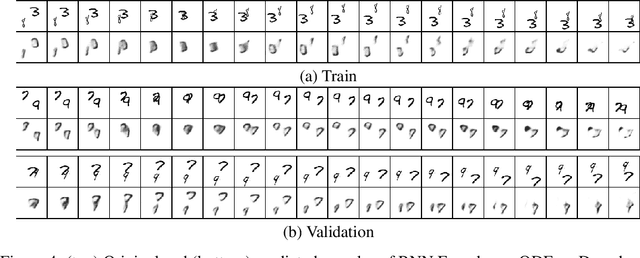
Despite having been studied to a great extent, the task of conditional generation of sequences of frames, or videos, remains extremely challenging. It is a common belief that a key step towards solving this task resides in modelling accurately both spatial and temporal information in video signals. A promising direction to do so has been to learn latent variable models that predict the future in latent space and project back to pixels, as suggested in recent literature. Following this line of work and building on top of a family of models introduced in prior work, Neural ODE, we investigate an approach that models time-continuous dynamics over a continuous latent space with a differential equation with respect to time. The intuition behind this approach is that these trajectories in latent space could then be extrapolated to generate video frames beyond the time steps for which the model is trained. We show that our approach yields promising results in the task of future frame prediction on the Moving MNIST dataset with 1 and 2 digits.
* 8 pages, 4 figures, NeurIPS 2019 workshop