 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitePT: Lighter Yet Stronger Point Transformer
Dec 15, 2025



Modern neural architectures for 3D point cloud processing contain both convolutional layers and attention blocks, but the best way to assemble them remains unclear. We analyse the role of different computational blocks in 3D point cloud networks and find an intuitive behaviour: convolution is adequate to extract low-level geometry at high-resolution in early layers, where attention is expensive without bringing any benefits; attention captures high-level semantics and context in low-resolution, deep layers more efficiently. Guided by this design principle, we propose a new, improved 3D point cloud backbone that employs convolutions in early stages and switches to attention for deeper layers. To avoid the loss of spatial layout information when discarding redundant convolution layers, we introduce a novel, training-free 3D positional encoding, PointROPE. The resulting LitePT model has $3.6\times$ fewer parameters, runs $2\times$ faster, and uses $2\times$ less memory than the state-of-the-art Point Transformer V3, but nonetheless matches or even outperforms it on a range of tasks and datasets. Code and models are available at: https://github.com/prs-eth/LitePT.
VFMF: World Modeling by Forecasting Vision Foundation Model Features
Dec 12, 2025



Forecasting from partial observations is central to world modeling. Many recent methods represent the world through images, and reduce forecasting to stochastic video generation. Although such methods excel at realism and visual fidelity, predicting pixels is computationally intensive and not directly useful in many applications, as it requires translating RGB into signals useful for decision making. An alternative approach uses features from vision foundation models (VFMs) as world representations, performing deterministic regression to predict future world states. These features can be directly translated into actionable signals such as semantic segmentation and depth, while remaining computationally efficient. However, deterministic regression averages over multiple plausible futures, undermining forecast accuracy by failing to capture uncertainty. To address this crucial limitation, we introduce a generative forecaster that performs autoregressive flow matching in VFM feature space. Our key insight is that generative modeling in this space requires encoding VFM features into a compact latent space suitable for diffusion. We show that this latent space preserves information more effectively than previously used PCA-based alternatives, both for forecasting and other applications, such as image generation. Our latent predictions can be easily decoded into multiple useful and interpretable output modalities: semantic segmentation, depth, surface normals, and even RGB. With matched architecture and compute, our method produces sharper and more accurate predictions than regression across all modalities. Our results suggest that stochastic conditional generation of VFM features offers a promising and scalable foundation for future world models.
Particulate: Feed-Forward 3D Object Articulation
Dec 12, 2025We present Particulate, a feed-forward approach that, given a single static 3D mesh of an everyday object, directly infers all attributes of the underlying articulated structure, including its 3D parts, kinematic structure, and motion constraints. At its core is a transformer network, Part Articulation Transformer, which processes a point cloud of the input mesh using a flexible and scalable architecture to predict all the aforementioned attributes with native multi-joint support. We train the network end-to-end on a diverse collection of articulated 3D assets from public datasets. During inference, Particulate lifts the network's feed-forward prediction to the input mesh, yielding a fully articulated 3D model in seconds, much faster than prior approaches that require per-object optimization. Particulate can also accurately infer the articulated structure of AI-generated 3D assets, enabling full-fledged extraction of articulated 3D objects from a single (real or synthetic) image when combined with an off-the-shelf image-to-3D generator. We further introduce a new challenging benchmark for 3D articulation estimation curated from high-quality public 3D assets, and redesign the evaluation protocol to be more consistent with human preferences. Quantitative and qualitative results show that Particulate significantly outperforms state-of-the-art approaches.
On Geometric Understanding and Learned Data Priors in VGGT
Dec 12, 2025The Visual Geometry Grounded Transformer (VGGT) is a 3D foundation model that infers camera geometry and scene structure in a single feed-forward pass. Trained in a supervised, single-step fashion on large datasets, VGGT raises a key question: does it build upon geometric concepts like traditional multi-view methods, or does it rely primarily on learned appearance-based data-driven priors? In this work, we conduct a systematic analysis of VGGT's internal mechanisms to uncover whether geometric understanding emerges within its representations. By probing intermediate features, analyzing attention patterns, and performing interventions, we examine how the model implements its functionality. Our findings reveal that VGGT implicitly performs correspondence matching within its global attention layers and encodes epipolar geometry, despite being trained without explicit geometric constraints. We further investigate VGGT's dependence on its learned data priors. Using spatial input masking and perturbation experiments, we assess its robustness to occlusions, appearance variations, and camera configurations, comparing it with classical multi-stage pipelines. Together, these insights highlight how VGGT internalizes geometric structure while using learned data-driven priors.
Epipolar Geometry Improves Video Generation Models
Oct 24, 2025Video generation models have progressed tremendously through large latent diffusion transformers trained with rectified flow techniques. Yet these models still struggle with geometric inconsistencies, unstable motion, and visual artifacts that break the illusion of realistic 3D scenes. 3D-consistent video generation could significantly impact numerous downstream applications in generation and reconstruction tasks. We explore how epipolar geometry constraints improve modern video diffusion models. Despite massive training data, these models fail to capture fundamental geometric principles underlying visual content. We align diffusion models using pairwise epipolar geometry constraints via preference-based optimization, directly addressing unstable camera trajectories and geometric artifacts through mathematically principled geometric enforcement. Our approach efficiently enforces geometric principles without requiring end-to-end differentiability. Evaluation demonstrates that classical geometric constraints provide more stable optimization signals than modern learned metrics, which produce noisy targets that compromise alignment quality. Training on static scenes with dynamic cameras ensures high-quality measurements while the model generalizes effectively to diverse dynamic content. By bridging data-driven deep learning with classical geometric computer vision, we present a practical method for generating spatially consistent videos without compromising visual quality.
S3OD: Towards Generalizable Salient Object Detection with Synthetic Data
Oct 24, 2025Salient object detection exemplifies data-bounded tasks where expensive pixel-precise annotations force separate model training for related subtasks like DIS and HR-SOD. We present a method that dramatically improves generalization through large-scale synthetic data generation and ambiguity-aware architecture. We introduce S3OD, a dataset of over 139,000 high-resolution images created through our multi-modal diffusion pipeline that extracts labels from diffusion and DINO-v3 features. The iterative generation framework prioritizes challenging categories based on model performance. We propose a streamlined multi-mask decoder that naturally handles the inherent ambiguity in salient object detection by predicting multiple valid interpretations. Models trained solely on synthetic data achieve 20-50% error reduction in cross-dataset generalization, while fine-tuned versions reach state-of-the-art performance across DIS and HR-SOD benchmarks.
Articulate3D: Zero-Shot Text-Driven 3D Object Posing
Aug 26, 2025We propose a training-free method, Articulate3D, to pose a 3D asset through language control. Despite advances in vision and language models, this task remains surprisingly challenging. To achieve this goal, we decompose the problem into two steps. We modify a powerful image-generator to create target images conditioned on the input image and a text instruction. We then align the mesh to the target images through a multi-view pose optimisation step. In detail, we introduce a self-attention rewiring mechanism (RSActrl) that decouples the source structure from pose within an image generative model, allowing it to maintain a consistent structure across varying poses. We observed that differentiable rendering is an unreliable signal for articulation optimisation; instead, we use keypoints to establish correspondences between input and target images. The effectiveness of Articulate3D is demonstrated across a diverse range of 3D objects and free-form text prompts, successfully manipulating poses while maintaining the original identity of the mesh. Quantitative evaluations and a comparative user study, in which our method was preferred over 85\% of the time, confirm its superiority over existing approaches. Project page:https://odeb1.github.io/articulate3d_page_deb/
AnimalClue: Recognizing Animals by their Traces
Jul 27, 2025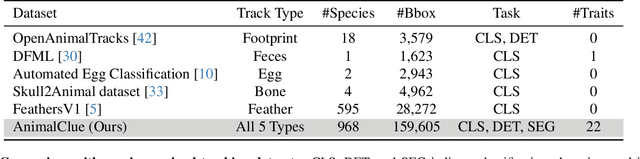

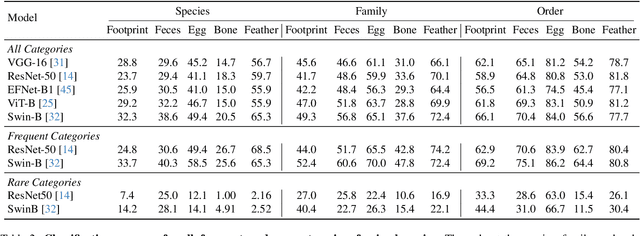
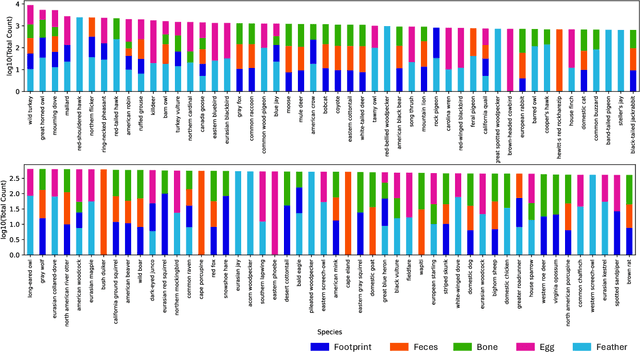
Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. Our dataset and code are available at https://dahlian00.github.io/AnimalCluePage/
CNS-Bench: Benchmarking Image Classifier Robustness Under Continuous Nuisance Shifts
Jul 23, 2025An important challenge when using computer vision models in the real world is to evaluate their performance in potential out-of-distribution (OOD) scenarios. While simple synthetic corruptions are commonly applied to test OOD robustness, they often fail to capture nuisance shifts that occur in the real world. Recently, diffusion models have been applied to generate realistic images for benchmarking, but they are restricted to binary nuisance shifts. In this work, we introduce CNS-Bench, a Continuous Nuisance Shift Benchmark to quantify OOD robustness of image classifiers for continuous and realistic generative nuisance shifts. CNS-Bench allows generating a wide range of individual nuisance shifts in continuous severities by applying LoRA adapters to diffusion models. To address failure cases, we propose a filtering mechanism that outperforms previous methods, thereby enabling reliable benchmarking with generative models. With the proposed benchmark, we perform a large-scale study to evaluate the robustness of more than 40 classifiers under various nuisance shifts. Through carefully designed comparisons and analyses, we find that model rankings can change for varying shifts and shift scales, which cannot be captured when applying common binary shifts. Additionally, we show that evaluating the model performance on a continuous scale allows the identification of model failure points, providing a more nuanced understanding of model robustness. Project page including code and data: https://genintel.github.io/CNS.
Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion
Jul 08, 2025



Semantic scene completion (SSC) aims to infer both the 3D geometry and semantics of a scene from single images. In contrast to prior work on SSC that heavily relies on expensive ground-truth annotations, we approach SSC in an unsupervised setting. Our novel method, SceneDINO, adapts techniques from self-supervised representation learning and 2D unsupervised scene understanding to SSC. Our training exclusively utilizes multi-view consistency self-supervision without any form of semantic or geometric ground truth. Given a single input image, SceneDINO infers the 3D geometry and expressive 3D DINO features in a feed-forward manner. Through a novel 3D feature distillation approach, we obtain unsupervised 3D semantics. In both 3D and 2D unsupervised scene understanding, SceneDINO reaches state-of-the-art segmentation accuracy. Linear probing our 3D features matches the segmentation accuracy of a current supervised SSC approach. Additionally, we showcase the domain generalization and multi-view consistency of SceneDINO, taking the first steps towards a strong foundation for single image 3D scene understanding.